
इस कोडलैब (कोड बनाना सीखने के लिए ट्यूटोरियल) के बारे में जानकारी
1. खास जानकारी
इस कोड लैब में, आपको Gemini का इस्तेमाल करने वाले LangChain ऐप्लिकेशन को डिप्लॉय करने का तरीका पता चलेगा. इससे आपको Cloud Run के रिलीज़ नोट के बारे में सवाल पूछने में मदद मिलेगी.
यहां ऐप्लिकेशन के काम करने के तरीके का एक उदाहरण दिया गया है: "क्या मैं Cloud Run में वॉल्यूम के तौर पर Cloud Storage बकेट को माउंट कर सकता/सकती हूं?", इसके जवाब में ऐप्लिकेशन "हां, 19 जनवरी, 2024 से" या इससे मिलता-जुलता सवाल पूछता है.
सही जवाब देने के लिए, ऐप्लिकेशन सबसे पहले सवाल से मिलते-जुलते Cloud Run के रिलीज़ नोट ढूंढता है. इसके बाद, वह Gemini को सवाल और रिलीज़ नोट, दोनों के बारे में बताता है. (इस पैटर्न को आम तौर पर आरएजी कहा जाता है.) यहां ऐप्लिकेशन का आर्किटेक्चर दिखाने वाला डायग्राम दिया गया है:
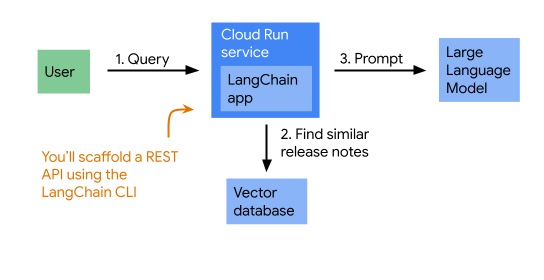
2. सेटअप और ज़रूरी शर्तें
सबसे पहले, यह पक्का करें कि आपका डेवलपमेंट एनवायरमेंट सही तरीके से सेट अप किया गया हो.
- ऐप्लिकेशन के लिए जिन संसाधनों की ज़रूरत पड़ती है उन्हें डिप्लॉय करने के लिए, आपको Google Cloud प्रोजेक्ट की ज़रूरत होगी.
- ऐप्लिकेशन को डिप्लॉय करने के लिए, यह ज़रूरी है कि आपकी लोकल मशीन पर gcloud इंस्टॉल हो, पुष्टि हो गई हो, और प्रोजेक्ट का इस्तेमाल करने के लिए कॉन्फ़िगर किया गया हो.
gcloud auth logingcloud config set project
- हमारा सुझाव है कि आप ऐप्लिकेशन को अपनी लोकल मशीन पर चलाएं. इसके लिए, आपको यह पक्का करना होगा कि आपके ऐप्लिकेशन के डिफ़ॉल्ट क्रेडेंशियल सही तरीके से सेट अप किए गए हों. इनमें कोटा प्रोजेक्ट सेट करना भी शामिल है.
gcloud auth application-default logingcloud auth application-default set-quota-project
- आपको यह सॉफ़्टवेयर भी इंस्टॉल करना होगा:
- Python (3.11 या इसके बाद का वर्शन ज़रूरी है)
- LangChain सीएलआई
- डिपेंडेंसी मैनेज करने के लिए कविता
- अलग-अलग वर्चुअल एनवायरमेंट में LangChain CLI और poetry को इंस्टॉल और चलाने के लिए pipx
सिलसिलेवार तरीके से निर्देश देने के लिए ज़रूरी टूल इंस्टॉल करने के लिए, यहां एक ब्लॉग दिया गया है.
क्लाउड वर्कस्टेशन
लोकल मशीन के बजाय, Google Cloud पर Cloud Workstations का भी इस्तेमाल किया जा सकता है. ध्यान दें कि अप्रैल 2024 से, यह Python के 3.11 से पहले के वर्शन पर काम करता है. इसलिए, शुरू करने से पहले आपको Python को अपग्रेड करना पड़ सकता है.
Cloud API चालू करें
सबसे पहले, यह पक्का करने के लिए यह कमांड चलाएं कि आपने इस्तेमाल करने के लिए सही Google Cloud प्रोजेक्ट कॉन्फ़िगर किया है:
gcloud config list project
अगर सही प्रोजेक्ट नहीं दिख रहा है, तो इसे इस निर्देश की मदद से सेट किया जा सकता है:
gcloud config set project <PROJECT_ID>
अब इन एपीआई को चालू करें:
gcloud services enable \ bigquery.googleapis.com \ sqladmin.googleapis.com \ aiplatform.googleapis.com \ cloudresourcemanager.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ run.googleapis.com \ secretmanager.googleapis.com
एक क्षेत्र चुनें
Google Cloud दुनिया भर में कई जगहों पर उपलब्ध है. आपको इस लैब के लिए इस्तेमाल किए जाने वाले संसाधनों को डिप्लॉय करने के लिए, कोई एक जगह चुननी होगी. अपने शेल में, क्षेत्र को एनवायरमेंट वैरिएबल के तौर पर सेट करें. बाद के निर्देश इस वैरिएबल का इस्तेमाल करते हैं:
export REGION=us-central1
3. वेक्टर डेटाबेस इंस्टेंस बनाना
इस ऐप्लिकेशन का एक अहम हिस्सा, रिलीज़ नोट को वापस लाना है, जो उपयोगकर्ता के सवाल से जुड़े हों. इसे और बेहतर बनाने के लिए, अगर Cloud Storage के बारे में कोई सवाल पूछा जा रहा है, तो प्रॉम्प्ट में यह रिलीज़ नोट जोड़ें:
शब्दों के हिसाब से मिलते-जुलते रिलीज़ नोट ढूंढने के लिए, टेक्स्ट एम्बेड करने की सुविधा और वेक्टर डेटाबेस का इस्तेमाल किया जा सकता है.
हम आपको दिखाएंगे कि Cloud SQL पर, वेक्टर डेटाबेस के तौर पर PostgreSQL का इस्तेमाल कैसे किया जा सकता है. नया Cloud SQL इंस्टेंस बनाने में कुछ समय लगता है. इसलिए, अब हम इसे बनाना शुरू करते हैं.
gcloud sql instances create sql-instance \ --database-version POSTGRES_14 \ --tier db-f1-micro \ --region $REGION
इस निर्देश को चलने दिया जा सकता है और अगले चरण पूरे किए जा सकते हैं. आपको किसी समय डेटाबेस बनाना होगा और उपयोगकर्ता जोड़ना होगा. हालांकि, अभी स्पिनर को देखते हुए समय बर्बाद न करें.
PostgreSQL एक रिलेशनल डेटाबेस सर्वर है. Cloud SQL के हर नए इंस्टेंस में, pgvector एक्सटेंशन डिफ़ॉल्ट रूप से इंस्टॉल होता है. इसका मतलब है कि इसका इस्तेमाल वेक्टर डेटाबेस के तौर पर भी किया जा सकता है.
4. LangChain ऐप्लिकेशन को स्कैफ़ोल्ड करना
जारी रखने के लिए, आपके पास LangChain CLI इंस्टॉल होना चाहिए. साथ ही, डिपेंडेंसी मैनेज करने के लिए poetry भी होनी चाहिए. pipx का इस्तेमाल करके, उन्हें इंस्टॉल करने का तरीका यहां बताया गया है:
pipx install langchain-cli poetry
नीचे दिए गए निर्देश का इस्तेमाल करके, LangChain ऐप्लिकेशन को स्केल करें. जब कहा जाए, तब run-rag फ़ोल्डर को नाम दें और Enter दबाकर पैकेज इंस्टॉल करना छोड़ें:
langchain app new
run-rag डायरेक्ट्री में जाएं और डिपेंडेंसी इंस्टॉल करें
poetry install
आपने अभी-अभी एक LangServe ऐप्लिकेशन बनाया है. langServe, फ़ास्टएपीआई को LangChain चेन के इर्द-गिर्द रैप करता है. इसमें पहले से मौजूद एक प्लैटफ़ॉर्म होता है. इसकी मदद से, प्रॉम्प्ट भेजना और नतीजों की जांच करना आसान हो जाता है. इसमें, बीच के सभी चरणों की जानकारी भी शामिल होती है. हमारा सुझाव है कि आप अपने एडिटर में run-rag फ़ोल्डर खोलें और देखें कि उसमें क्या है.
5. इंडेक्स करने का जॉब बनाना
वेब ऐप्लिकेशन को एक साथ जोड़ने से पहले, यह पक्का कर लें कि Cloud Run के रिलीज़ नोट, Cloud SQL डेटाबेस में इंडेक्स किए गए हों. इस सेक्शन में, आपको इंडेक्स करने का ऐसा जॉब बनाना होगा जो ये काम करता हो:
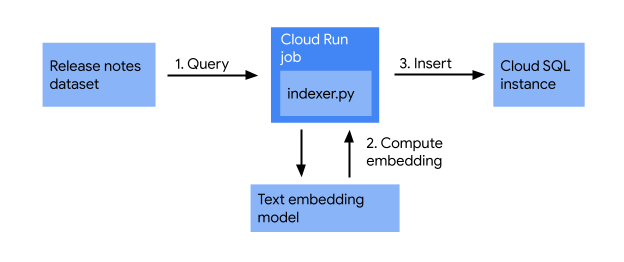
इंडेक्स करने का जॉब, रिलीज़ नोट लेता है और टेक्स्ट एम्बेड करने वाले मॉडल का इस्तेमाल करके, उन्हें वेक्टर में बदलता है. साथ ही, उन्हें वेक्टर डेटाबेस में सेव करता है. इसकी मदद से, मिलते-जुलते मतलब के आधार पर, मिलते-जुलते प्रॉडक्ट की जानकारी आसानी से खोजी जा सकती है.
run-rag/app फ़ोल्डर में, यहां दिए गए कॉन्टेंट के साथ indexer.py फ़ाइल बनाएं:
import os
from google.cloud.sql.connector import Connector
import pg8000
from langchain_community.vectorstores.pgvector import PGVector
from langchain_google_vertexai import VertexAIEmbeddings
from google.cloud import bigquery
# Retrieve all Cloud Run release notes from BigQuery
client = bigquery.Client()
query = """
SELECT
CONCAT(FORMAT_DATE("%B %d, %Y", published_at), ": ", description) AS release_note
FROM `bigquery-public-data.google_cloud_release_notes.release_notes`
WHERE product_name= "Cloud Run"
ORDER BY published_at DESC
"""
rows = client.query(query)
print(f"Number of release notes retrieved: {rows.result().total_rows}")
# Set up a PGVector instance
connector = Connector()
def getconn() -> pg8000.dbapi.Connection:
conn: pg8000.dbapi.Connection = connector.connect(
os.getenv("DB_INSTANCE_NAME", ""),
"pg8000",
user=os.getenv("DB_USER", ""),
password=os.getenv("DB_PASS", ""),
db=os.getenv("DB_NAME", ""),
)
return conn
store = PGVector(
connection_string="postgresql+pg8000://",
use_jsonb=True,
engine_args=dict(
creator=getconn,
),
embedding_function=VertexAIEmbeddings(
model_name="textembedding-gecko@003"
),
pre_delete_collection=True
)
# Save all release notes into the Cloud SQL database
texts = list(row["release_note"] for row in rows)
ids = store.add_texts(texts)
print(f"Done saving: {len(ids)} release notes")
ज़रूरी डिपेंडेंसी जोड़ें:
poetry add \ "cloud-sql-python-connector[pg8000]" \ langchain-google-vertexai==1.0.5 \ langchain-community==0.2.5 \ pgvector
डेटाबेस और उपयोगकर्ता बनाना
Cloud SQL इंस्टेंस sql-instance पर एक डेटाबेस release-notes बनाएं:
gcloud sql databases create release-notes --instance sql-instance
app नाम का डेटाबेस उपयोगकर्ता बनाएं:
gcloud sql users create app --instance sql-instance --password "myprecious"
इंडेक्स करने की जॉब को डिप्लॉय और चलाना
अब जॉब को डिप्लॉय करें और चलाएं:
DB_INSTANCE_NAME=$(gcloud sql instances describe sql-instance --format="value(connectionName)") gcloud run jobs deploy indexer \ --source . \ --command python \ --args app/indexer.py \ --set-env-vars=DB_INSTANCE_NAME=$DB_INSTANCE_NAME \ --set-env-vars=DB_USER=app \ --set-env-vars=DB_NAME=release-notes \ --set-env-vars=DB_PASS=myprecious \ --region=$REGION \ --execute-now
यह एक लंबा निर्देश है. आइए, देखते हैं कि क्या हो रहा है:
पहला निर्देश, कनेक्शन का नाम (project:region:instance के तौर पर फ़ॉर्मैट किया गया यूनीक आईडी) वापस लाता है और उसे एनवायरमेंट वैरिएबल DB_INSTANCE_NAME के तौर पर सेट करता है.
दूसरा कमांड, Cloud Run जॉब को डिप्लॉय करता है. फ़्लैग के बारे में यहां बताया गया है:
--source .: इससे पता चलता है कि जॉब का सोर्स कोड, मौजूदा वर्किंग डायरेक्ट्री (वह डायरेक्ट्री जहां से कमांड चलाया जा रहा है) में है.--command python: कंटेनर में चलाने के लिए निर्देश सेट करता है. इस मामले में, Python को चलाना है.--args app/indexer.py: Python निर्देश में आर्ग्युमेंट को देता है. यह इसे ऐप्लिकेशन डायरेक्ट्री में स्क्रिप्ट indexer.py चलाने के लिए कहता है.--set-env-vars: ऐसे एनवायरमेंट वैरिएबल सेट करता है जिन्हें Python स्क्रिप्ट, प्रोसेस के दौरान ऐक्सेस कर सकती है.--region=$REGION: उस क्षेत्र के बारे में बताता है जहां जॉब डिप्लॉय किया जाना चाहिए.--execute-now: Cloud Run को डिप्लॉय होने के तुरंत बाद, काम शुरू करने के लिए कहता है.
टास्क के पूरा होने की पुष्टि करने के लिए, ये काम किए जा सकते हैं:
- वेब कंसोल के ज़रिए काम के लागू होने के लॉग पढ़ें. इसे "सेव किया गया: xxx रिलीज़ नोट" रिपोर्ट में दिखना चाहिए (जहां xxx, सेव किए गए रिलीज़ नोट की संख्या है).
- इसके अलावा, वेब कंसोल में Cloud SQL इंस्टेंस पर भी जाया जा सकता है. साथ ही,
langchain_pg_embeddingटेबल में रिकॉर्ड की संख्या के बारे में क्वेरी करने के लिए, Cloud SQL Studio का इस्तेमाल किया जा सकता है.
6. वेब ऐप्लिकेशन लिखना
अपने एडिटर में फ़ाइल app/server.py खोलें. आपको एक लाइन दिखेगी, जिसमें यह जानकारी होगी:
# Edit this to add the chain you want to add
उस टिप्पणी को नीचे दिए गए स्निपेट से बदलें:
# (1) Initialize VectorStore
connector = Connector()
def getconn() -> pg8000.dbapi.Connection:
conn: pg8000.dbapi.Connection = connector.connect(
os.getenv("DB_INSTANCE_NAME", ""),
"pg8000",
user=os.getenv("DB_USER", ""),
password=os.getenv("DB_PASS", ""),
db=os.getenv("DB_NAME", ""),
)
return conn
vectorstore = PGVector(
connection_string="postgresql+pg8000://",
use_jsonb=True,
engine_args=dict(
creator=getconn,
),
embedding_function=VertexAIEmbeddings(
model_name="textembedding-gecko@003"
)
)
# (2) Build retriever
def concatenate_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
notes_retriever = vectorstore.as_retriever() | concatenate_docs
# (3) Create prompt template
prompt_template = PromptTemplate.from_template(
"""You are a Cloud Run expert answering questions.
Use the retrieved release notes to answer questions
Give a concise answer, and if you are unsure of the answer, just say so.
Release notes: {notes}
Here is your question: {query}
Your answer: """)
# (4) Initialize LLM
llm = VertexAI(
model_name="gemini-1.0-pro-001",
temperature=0.2,
max_output_tokens=100,
top_k=40,
top_p=0.95
)
# (5) Chain everything together
chain = (
RunnableParallel({
"notes": notes_retriever,
"query": RunnablePassthrough()
})
| prompt_template
| llm
| StrOutputParser()
)
आपको ये इंपोर्ट भी जोड़ने होंगे:
import pg8000
import os
from google.cloud.sql.connector import Connector
from langchain_google_vertexai import VertexAI
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_community.vectorstores.pgvector import PGVector
आखिर में, "NotImplemented" वाली लाइन को बदलकर:
# add_routes(app, NotImplemented)
add_routes(app, chain)
7. वेब ऐप्लिकेशन को Cloud Run पर डिप्लॉय करें
run-rag डायरेक्ट्री से, ऐप्लिकेशन को Cloud Run पर डिप्लॉय करने के लिए, नीचे दिए गए कमांड का इस्तेमाल करें:
DB_INSTANCE_NAME=$(gcloud sql instances describe sql-instance --format="value(connectionName)") gcloud run deploy run-rag \ --source . \ --set-env-vars=DB_INSTANCE_NAME=$DB_INSTANCE_NAME \ --set-env-vars=DB_USER=app \ --set-env-vars=DB_NAME=release-notes \ --set-env-vars=DB_PASS=myprecious \ --region=$REGION \ --allow-unauthenticated
यह निर्देश ये काम करता है:
- सोर्स कोड को Cloud Build में अपलोड करना
- डॉकर बिल्ड चलाएं.
- इससे बनने वाले कंटेनर इमेज को Artifact Registry में भेजें.
- कंटेनर इमेज का इस्तेमाल करके Cloud Run सेवा बनाएं.
कमांड पूरा होने पर, यह run.app डोमेन पर एचटीटीपीएस यूआरएल की सूची दिखाता है. यह आपकी नई Cloud Run सेवा का सार्वजनिक यूआरएल है
8. प्लैटफ़ॉर्म के बारे में जानकारी
Cloud Run सेवा का यूआरएल खोलें और /playground पर जाएं. इससे एक टेक्स्ट फ़ील्ड खुल जाता है. Cloud Run के प्रॉडक्ट की जानकारी के बारे में सवाल पूछने के लिए, इसका इस्तेमाल करें. उदाहरण के लिए:
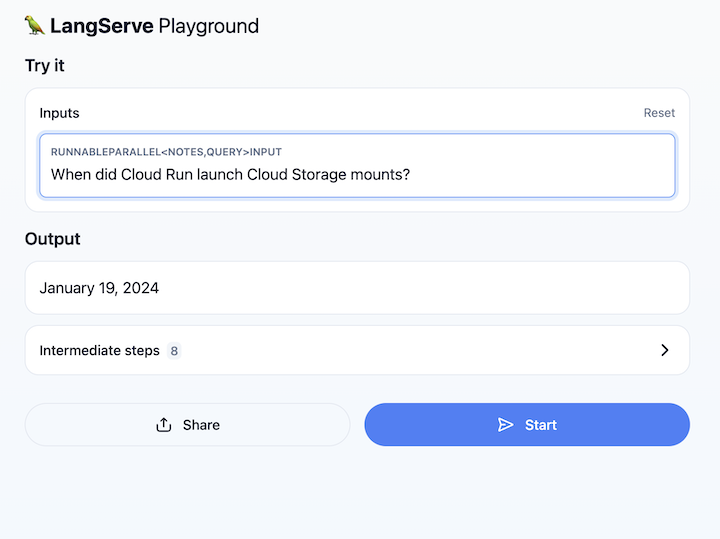
9. बधाई हो
आपने Cloud Run पर LangChain ऐप्लिकेशन बनाया और डिप्लॉय किया है. बहुत खूब!
यहां मुख्य कॉन्सेप्ट दिए गए हैं:
- Retrieval ऑगमेंटेड जनरेशन (RAG) ऐप्लिकेशन बनाने के लिए, LangChain फ़्रेमवर्क का इस्तेमाल करना.
- Cloud SQL पर PostgreSQL को, pgवेक्टर के साथ वेक्टर डेटाबेस के तौर पर इस्तेमाल करना, जो Cloud SQL पर डिफ़ॉल्ट रूप से इंस्टॉल होता है.
- Cloud Run जॉब के तौर पर और वेब ऐप्लिकेशन को Cloud Run सेवा के तौर पर, इंडेक्स करने के लिए लंबे समय तक चलने वाले जॉब को चलाएं.
- LangServe की मदद से फ़ास्टएपीआई ऐप्लिकेशन में LangChain चेन रैप करें. इससे आपके RAG ऐप्लिकेशन के साथ आसानी से इंटरैक्ट करने में मदद करने वाला इंटरफ़ेस मिलता है.
व्यवस्थित करें
इस ट्यूटोरियल में इस्तेमाल किए गए संसाधनों के लिए, आपके Google Cloud Platform खाते पर लगने वाले शुल्क से बचने के लिए:
- Cloud Console में, 'संसाधन मैनेज करें' पेज पर जाएं.
- प्रोजेक्ट की सूची में, अपना प्रोजेक्ट चुनें. इसके बाद, 'मिटाएं' पर क्लिक करें.
- डायलॉग बॉक्स में, प्रोजेक्ट का आईडी टाइप करें. इसके बाद, प्रोजेक्ट मिटाने के लिए 'बंद करें' पर क्लिक करें.
अगर आपको प्रोजेक्ट बनाए रखना है, तो इन संसाधनों को मिटाना न भूलें:
- Cloud SQL इंस्टेंस
- Cloud Run सेवा
- क्लाउड रन जॉब