
1. 소개
BigQuery는 확장성과 비용 효율성이 뛰어난 서버리스 데이터 웨어하우스입니다. BigQuery로 데이터를 이동하기만 하면 됩니다. 힘든 작업은 Google에서 처리하므로 비즈니스 운영과 같은 중요한 일에 집중할 수 있습니다. 비즈니스 요구사항을 기준으로 다른 사용자에게 데이터를 보거나 쿼리할 수 있는 권한을 부여하는 등 프로젝트 및 데이터에 대한 액세스를 제어할 수 있습니다.
이 실습에서는 BigQuery의 분석 가능성을 알아봅니다. Google Cloud Storage 버킷에서 데이터 세트를 가져오고 소매 금융 데이터 세트를 사용하여 BigQuery UI를 파악하는 방법을 알아봅니다. 또한 이 실습에서는 스프레드시트로 쿼리 결과를 내보내고, 쿼리 기록에서 쿼리를 보고 실행하고, 쿼리 성능을 보고, 다른 팀과 부서에서 사용할 테이블 뷰를 만드는 등 일상적인 분석을 훨씬 쉽게 만들어 주는 BigQuery의 주요 기능을 알아보겠습니다.
학습할 내용
이 실습에서는 다음 작업을 수행하는 방법을 알아봅니다.
- BigQuery에 새 데이터 로드
- BigQuery UI에 익숙해지기
- BigQuery에서 쿼리 실행
- 쿼리 성능 보기
- BigQuery에서 뷰 만들기
- 다른 사용자와 데이터 세트를 안전하게 공유
2. 소개: BigQuery UI 이해
이 섹션에서는 BigQuery UI를 탐색하고, 사용 가능한 데이터 세트를 확인하고, 간단한 쿼리를 실행하는 방법을 알아봅니다.
BQ UI 로드
- Google Cloud Platform 콘솔 상단에 있는 검색창에 'BigQuery'를 입력합니다.
- 옵션 목록에서 BigQuery를 선택합니다. BigQuery 로고(돋보기)가 있는 옵션을 선택해야 합니다.
데이터 세트 보기 및 쿼리 실행

- 리소스 섹션의 왼쪽 창에서 BigQuery 프로젝트를 클릭합니다.
bq_demo를 클릭하여 해당 데이터 세트의 테이블을 확인합니다.- '검색어 입력' 상자에 '카드'를 입력하면 이름에 '카드'가 포함된 테이블과 데이터 세트 목록이 표시됩니다.
- 검색 결과 목록에서 'card_transactions' 테이블을 선택합니다.

card_transactions창 아래의 세부정보 탭을 클릭하여 이 테이블의 메타데이터를 확인합니다.- 미리보기 탭을 클릭하여 테이블 미리보기를 확인합니다.
[경쟁력 있는 대화 주제 ]: Google 데이터 카탈로그와의 통합을 통해 BigQuery 메타데이터를 데이터 레이크 또는 운영 데이터 소스와 같은 다른 데이터 소스와 함께 관리할 수 있습니다. Google Cloud는 관계형 데이터 웨어하우스일 뿐만 아니라 전체 분석 데이터 플랫폼이라는 것을 보여주는 한 가지 예입니다.
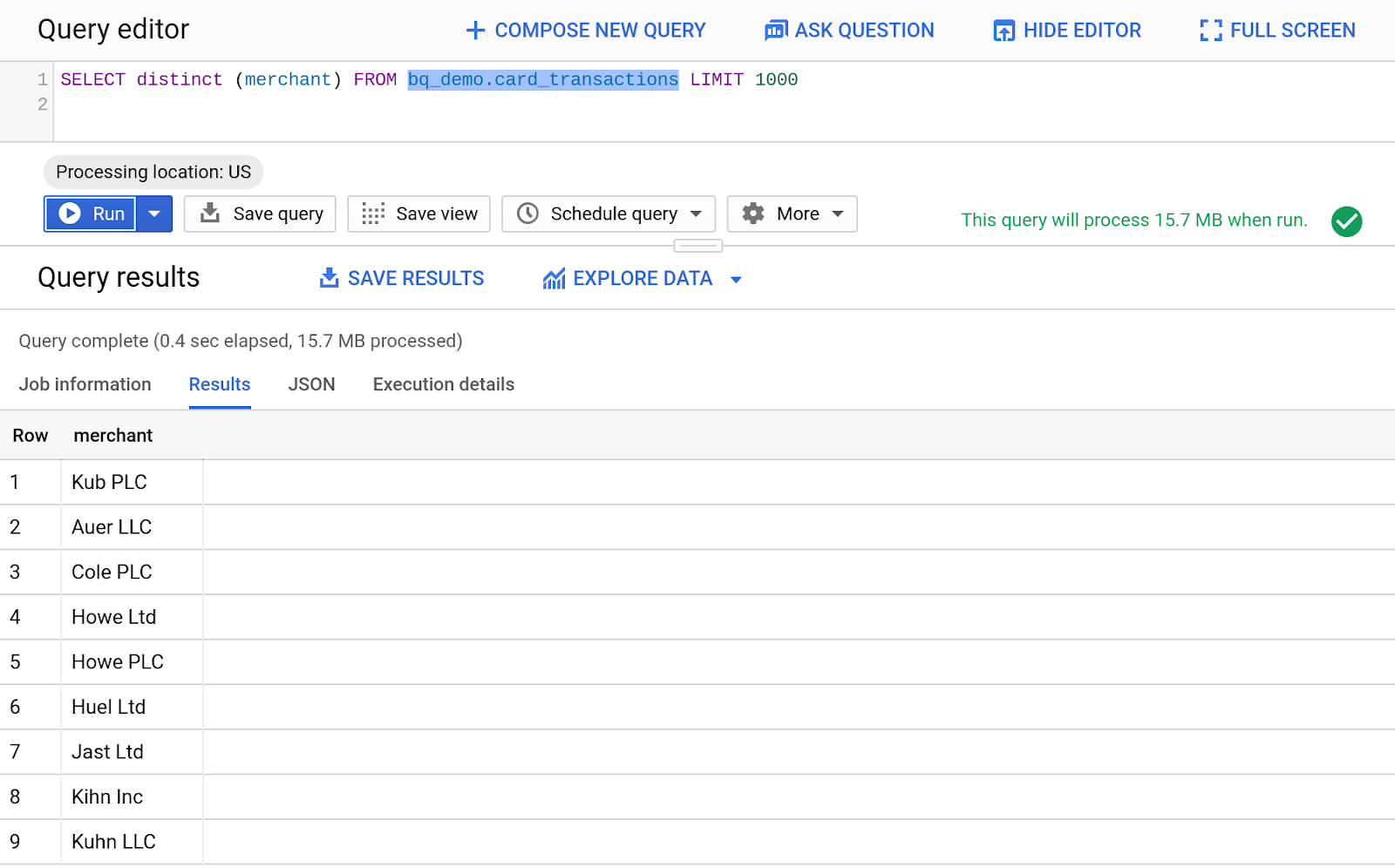
- 돋보기 아이콘을 클릭하여 'card_transactions' 테이블을 쿼리합니다. 자동 생성된 텍스트가 BigQuery 쿼리 편집기에 채워집니다.
- 아래 코드를 입력하여 Card_Transactions 테이블의 고유한 판매자를 표시하세요.
SELECT distinct (merchant) FROM bq_demo.card_transactions LIMIT 1000
- 실행 버튼을 클릭하여 쿼리를 실행합니다.
3. 데이터 세트 만들기 및 뷰 공유
데이터 및 거버넌스를 공유하는 것이 중요하며, BQ UI에서 직관적으로 수행할 수 있습니다. 이 섹션에서는 새 데이터 세트를 만들고, 뷰로 채우고, 데이터 세트를 공유하는 방법을 알아봅니다.
쿼리 기록 보기
- GCP Console의 왼쪽 창에서 '쿼리 기록'을 클릭합니다.
- 쿼리 기록 창에서 새로고침을 클릭합니다.
- 쿼리 맨 오른쪽에 있는 다운로드 이미지/화살표를 클릭하여 쿼리 결과를 확인합니다.

새 데이터 세트 만들기
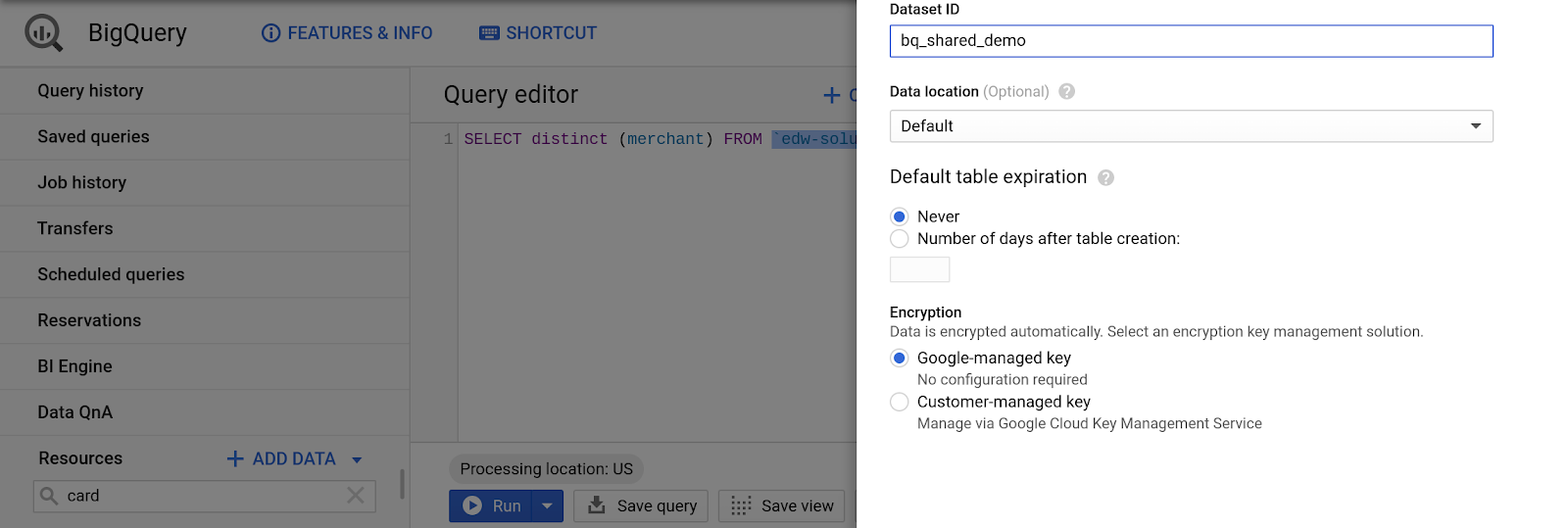
- BigQuery UI의 리소스 창에서 [프로젝트 이름] 을 선택합니다.
- 프로젝트 정보 창에서 '새 데이터 세트 만들기'를 선택합니다.
- 데이터 세트 ID의 경우:
bq_demo_shared
- 다른 필드는 모두 기본값으로 둡니다.
- '데이터 세트 만들기'를 클릭합니다.

뷰 만들기
[경쟁력 있는 대화 주제 ]: BigQuery는 ANSI SQL을 완전히 준수하며 간단한 다중 테이블 조인과 복잡한 다중 테이블 조인, 다양한 분석 함수를 모두 지원합니다. 마이그레이션 프로세스를 간소화하기 위해 기존 데이터 웨어하우스에서 사용되는 일반적인 SQL 데이터 유형 및 함수에 대한 지원을 지속적으로 출시했습니다.
- 쿼리 편집기 창 상단에서 '새 쿼리 작성'을 선택합니다.
- 쿼리 편집기에 다음 코드를 삽입합니다.
WITH revenue_by_month AS (
SELECT
card.type AS card_type,
FORMAT_DATE('%Y-%m', trans_date) as revenue_date,
SUM(amount) as revenue
FROM bq_demo.card_transactions
JOIN bq_demo.card ON card_transactions.cc_number = card.card_number
WHERE trans_date DATE_ADD(CURRENT_DATE, INTERVAL -1 YEAR)
GROUP BY card_type, revenue_date
)
SELECT
card_type,
revenue_date,
revenue as monthly_rev,
revenue - LAG(revenue) OVER (ORDER BY card_type, revenue_date ASC) as rev_change
FROM revenue_by_month
ORDER BY card_type, revenue_date ASC;
- '뷰 저장'을 클릭합니다.
- 프로젝트 이름에 현재 프로젝트를 선택합니다.
- 새로 만든 데이터 세트를 선택합니다.
bq_demo_shared
- 테이블 이름:
rev_change_by_card_type
- 저장을 클릭합니다.

뷰 및 데이터 세트 공유
- BigQuery UI의 왼쪽 리소스 창에서 'bq_demo_shared' 데이터 세트를 선택합니다.
- 데이터 세트 정보 창에서 '데이터 세트 공유'를 클릭합니다.
- 이메일 주소를 입력하세요.
- 역할 드롭다운 메뉴에서 'BigQuery 데이터 뷰어'를 선택합니다.
- '추가'를 클릭하세요.
- 완료를 클릭합니다.

Google Sheets에서 데이터 탐색하기
[경쟁력 있는 대화 주제 ]: 경쟁업체와 비교했을 때 BigQuery의 또 다른 이점은 BI Engine입니다. BI Engine을 사용하면 인메모리 캐싱 엔진을 통해 BI 유형 요약 쿼리가 1초 이내에 반환되도록 할 수 있습니다. 이 기능은 현재 Google 데이터 스튜디오에서 지원되며 곧 BigQuery의 모든 쿼리를 가속화하는 데 사용할 수 있게 됩니다.
예를 들면 다음과 같습니다.
Snowflake는 대시보드 및 데이터 시각화를 위해 서드 파티 BI 도구를 사용하는 반면 GCP는 연결된 시트, 데이터 스튜디오, Looker를 비롯한 다양한 통합 BI 도구를 제공합니다.
- BigQuery UI의 왼쪽 리소스 창에서 'rev_change_by_card_type' 보기를 선택합니다.
- 돋보기를 클릭하여 뷰를 쿼리합니다.

- 유형:
SELECT *
FROM bq_demo_shared.rev_change_by_card_type
- '실행'을 클릭합니다.
- 결과 창에서 '내보내기' 아이콘 클릭
- 'Sheets로 데이터 탐색'을 선택합니다.

- '분석 시작'을 클릭합니다.
- '피벗 테이블'을 선택합니다.
- '새 시트'를 선택합니다.
- '만들기' 클릭
- Sheets 창 오른쪽에 있는 피벗 테이블 편집기의 행 섹션에 'revenue_date'를 추가합니다.
- 피벗 테이블 편집기의 열 섹션에 'card_type'을 추가합니다.
- 피벗 테이블 편집기의 열 섹션에 'monthly_rev' 추가
- 적용을 클릭합니다.

- Sheets UI의 상단 리본으로 이동하여 '차트 삽입'을 선택합니다.
4. 설정: 데이터 통합
이 섹션에서는 새 테이블을 만들고 Google Cloud에서 제공하는 여러 공개 데이터 세트 중 하나에 조인을 실행하는 방법을 알아봅니다.
[경쟁 관련 주요 요점]:
BigQuery는 수년 동안 공유 데이터 세트를 지원해 왔습니다. 모든 프로젝트의 고객은 공개 데이터 세트와 공유된 다른 프로젝트의 데이터 세트를 모두 쿼리할 수 있습니다.
BigQuery는 외부 테이블을 사용하여 GCS의 데이터 레이크를 지원할 수 있습니다. 일괄 로드 외에도 BigQuery는 초당 수백 MB 이상의 속도로 데이터베이스에 데이터를 스트리밍하는 기능을 지원합니다. Snowflake는 스트리밍 데이터를 지원하지 않습니다.
새 테이블로 데이터 가져오기
- 리소스 창에서 bq_demo 데이터 세트를 선택합니다.
- 데이터 세트 정보 창에서 '테이블 만들기'를 선택합니다.
- 소스에서 Google Cloud Storage 선택
- 파일 경로 텍스트 상자에서 다음을 수행합니다.
gs://retail-banking-looker/district
- 파일 형식으로 CSV 선택
- 테이블 이름에 'district'를 입력합니다.
- '스키마 자동 감지' 체크박스를 선택합니다.
- 테이블 만들기를 클릭합니다.
공개 데이터 세트 쿼리
- 쿼리 편집기에서 다음 쿼리를 입력합니다.
SELECT
CAST(geo_id as STRING) AS zip_code,
total_pop,
median_age,
households,
income_per_capita,
housing_units,
vacant_housing_units_for_sale,
ROUND(SAFE_DIVIDE(employed_pop, pop_16_over),4) AS rate_employment,
ROUND(SAFE_DIVIDE(bachelors_degree_or_higher_25_64, pop_25_64),4) AS rate_bachelors_degree_or_higher_25_64
FROM
`bigquery-public-data.census_bureau_acs.zip_codes_2017_5yr`;
- '실행'을 클릭합니다.
- 결과 보기

- 이제 이 공개 데이터를 다른 쿼리와 결합합니다. 쿼리 편집기에 다음 SQL 코드를 입력합니다.
WITH customer_counts AS (
select regexp_extract(address, "[0-9][0-9][0-9][0-9][0-9]") as zip_code,
count(*) as num_clients
FROM bq_demo.client
GROUP BY zip_code
)
SELECT
CAST(geo_id as STRING) AS zip_code,
total_pop,
median_age,
households,
income_per_capita,
ROUND(SAFE_DIVIDE(employed_pop, pop_16_over),4) AS rate_employment,
num_clients
FROM
`bigquery-public-data.census_bureau_acs.zip_codes_2017_5yr`
JOIN customer_counts on zip_code = geo_id
ORDER BY num_clients DESC
- '실행'을 클릭합니다.
- 결과 보기

5. 용량 관리
슬롯 및 예약 작업
BQ는 필요에 맞는 다양한 가격 모델을 제공합니다. 대부분의 대규모 고객은 예약된 용량으로 예측 가능한 가격을 책정하기 위해 주로 정액제를 활용합니다. 기준 용량을 초과하는 버스팅의 경우 BQ는 플렉스 슬롯을 제공합니다. 이를 통해 실행 중인 쿼리에 영향을 주지 않고 즉시 추가 용량으로 확장한 후 자동으로 다시 축소할 수 있습니다. BQ에는 실행한 쿼리에 대해서만 비용을 지불할 수 있는 바이트 스캔 모델도 있습니다.
[경쟁력 있는 이야기: 일부 경쟁업체는 고객이 조직의 각 워크로드에 가상 웨어하우스를 할당해야 하는 고정 용량 모델에서만 작동합니다. BigQuery를 쉽게 시작할 수 있는 저렴한 쿼리당 모델 외에도 유휴 용량을 일련의 워크로드 간에 공유할 수 있는 정액제 용량 가격 책정 모델을 지원합니다.]
- 예약 탭으로 이동합니다.
- '슬롯 구매'를 클릭합니다.
- 기간으로 '유연'을 선택합니다.
- 500개의 슬롯을 선택합니다.
- 구매를 확인합니다.
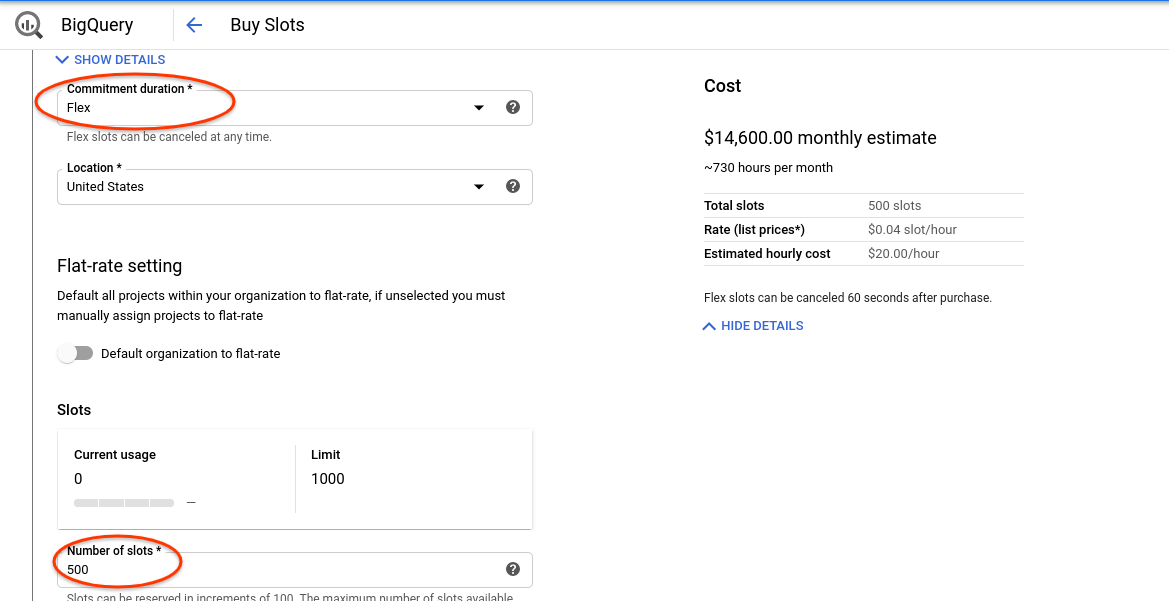
- 슬롯 약정 보기를 클릭합니다.
- '예약 만들기'를 클릭합니다.
- 예약 이름이 'demo'인 사용자
- 위치로 미국 선택
- 슬롯에 500을 입력합니다 (모든 슬롯 사용 가능).
- '과제'를 클릭합니다.
- 조직 프로젝트의 현재 프로젝트 선택
- 예약 ID에 'demo'를 선택합니다.
- 만들기를 클릭합니다.'