
1. はじめに
BigQuery は、サーバーレスでスケーラビリティと費用対効果に優れたデータ ウェアハウスです。データを BigQuery に読み込むだけで、残りの処理は Google 側で行います。ユーザーは、ビジネスの運営という重要な業務に集中できます。他のユーザーにデータの表示やクエリを許可するなど、ビジネスニーズに基づいてプロジェクトとデータへのアクセスを制御できます。
このラボでは、BigQuery の分析の可能性について説明します。Google Cloud Storage バケットからデータセットをインポートする方法を学習し、小売銀行データセットを使用して BigQuery UI の概要を把握します。また、このラボでは、クエリ結果をスプレッドシートにエクスポートする、クエリ履歴からクエリを表示して実行する、クエリのパフォーマンスを表示する、他のチームや部門で使用するテーブルビューを作成するなど、日々の分析を大幅に簡素化する BigQuery の主要な機能を見つける方法についても説明します。
学習内容
このラボでは、次のタスクの実行方法について学びます。
- 新しいデータを BigQuery に読み込む
- BigQuery UI について
- BigQuery でのクエリの実行
- クエリのパフォーマンスを表示する
- BigQuery でのビューの作成
- データセットを他のユーザーと安全に共有する
2. はじめに: BigQuery UI について
このセクションでは、BigQuery UI の操作方法、使用可能なデータセットの表示方法、簡単なクエリの実行方法について説明します。
BQ UI の読み込み
- Google Cloud Platform Console の上部にある [BigQuery] と入力します。
- オプション リストから [BigQuery] を選択します。BigQuery のロゴ(虫眼鏡)が付いているオプションを選択してください。
データセットの表示とクエリの実行

- 左側のペインの [リソース] で、BigQuery プロジェクトをクリックします。
bq_demoをクリックして、そのデータセット内のテーブルを表示します。- 検索ボックスに「card」と入力すると、名前に「card」が含まれるテーブルとデータセットのリストが表示されます。
- 検索結果リストから「card_transactions」テーブルを選択します。

card_transactionsペインの [詳細] タブをクリックして、このテーブルのメタデータを表示します。- [プレビュー] タブをクリックして、テーブルのプレビューを表示します。
[競合他社との差別化ポイント]: Google Data Catalog との統合により、BigQuery メタデータをデータレイクやオペレーショナル データソースなどの他のデータソースとともに管理できます。これは、Google Cloud がリレーショナル データ ウェアハウスだけでなく、分析データ プラットフォーム全体であることを示す一例です。
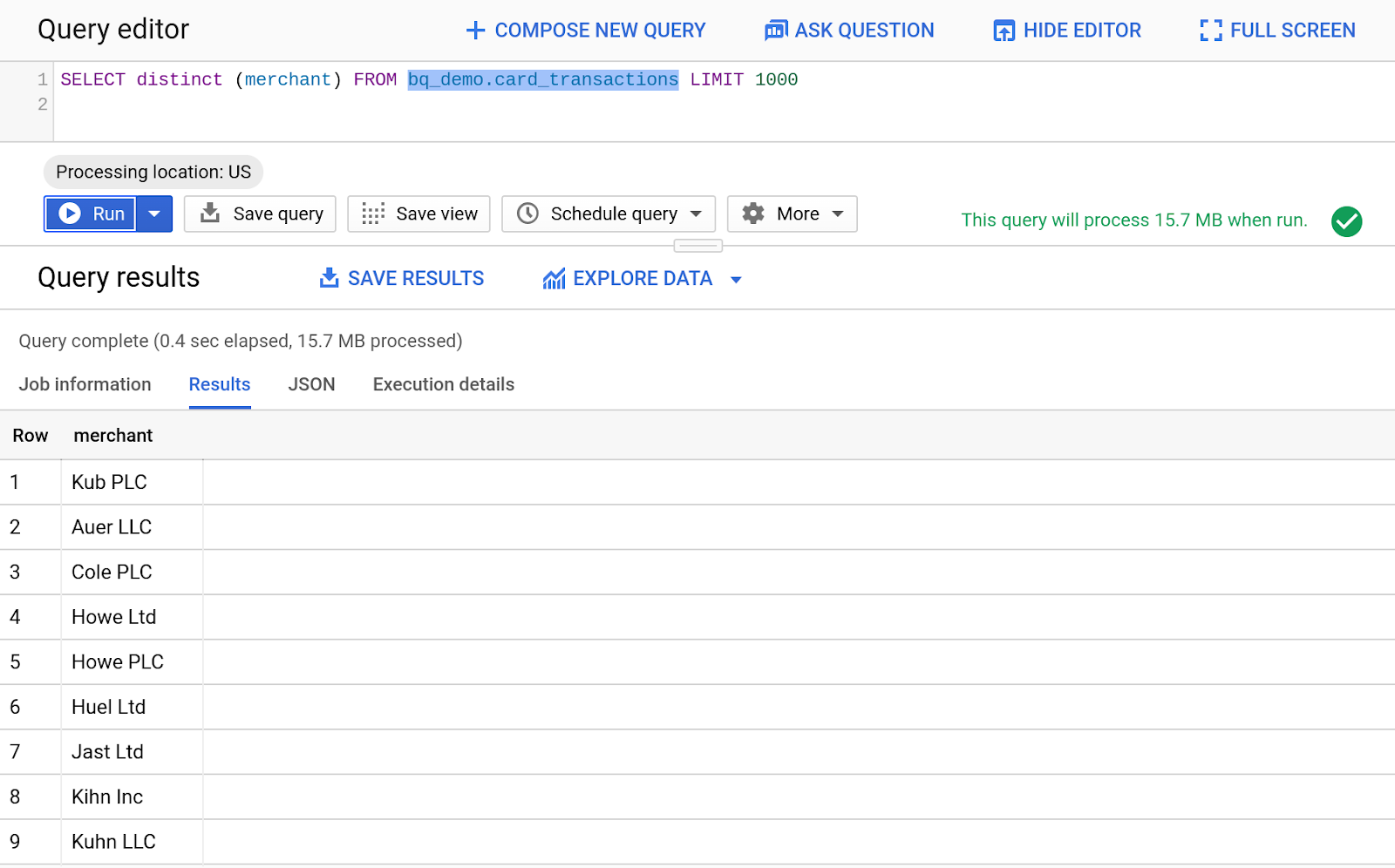
- 虫メガネ アイコンをクリックして、card_transactions テーブルをクエリします。自動生成されたテキストが BigQuery クエリ エディタに入力されます。
- 次のコードを入力して、Card_Transactions テーブルから個別の販売者を表示します。
SELECT distinct (merchant) FROM bq_demo.card_transactions LIMIT 1000
- [実行] ボタンをクリックしてクエリを実行します。
3. データセットの作成とビューの共有
データの共有とガバナンスは重要です。これは BQ UI で直感的に行うことができます。このセクションでは、新しいデータセットを作成し、ビューでデータを入力して、そのデータセットを共有する方法について説明します。
クエリ履歴を表示する
- GCP Console の左側のペインで [クエリ履歴] をクリックします
- [クエリ履歴] ペインで更新をクリックする
- クエリの右端にある画像のダウンロード/矢印をクリックして、クエリの結果を表示します。
新しいデータセットを作成する
- BigQuery UI のリソース ペインで [プロジェクト名] を選択します。
- プロジェクト情報ペインで [新しいデータセットを作成] を選択する
- データセット ID の場合:
bq_demo_shared
- 他のフィールドはすべてデフォルトのままにします。
- [データセットを作成] をクリックします。


ビューの作成
[競合他社との差別化ポイント]: BigQuery は ANSI SQL に完全に準拠しており、単純な結合と複雑な結合の両方と、豊富な分析関数をサポートしています。移行プロセスを容易にするため、従来のデータ ウェアハウスで使用される一般的な SQL データ型と関数のサポートを継続的に強化しています。
- クエリエディタ ペインの上部で [クエリを新規作成] を選択します。
- クエリエディタに次のコードを挿入します。
WITH revenue_by_month AS (
SELECT
card.type AS card_type,
FORMAT_DATE('%Y-%m', trans_date) as revenue_date,
SUM(amount) as revenue
FROM bq_demo.card_transactions
JOIN bq_demo.card ON card_transactions.cc_number = card.card_number
WHERE trans_date DATE_ADD(CURRENT_DATE, INTERVAL -1 YEAR)
GROUP BY card_type, revenue_date
)
SELECT
card_type,
revenue_date,
revenue as monthly_rev,
revenue - LAG(revenue) OVER (ORDER BY card_type, revenue_date ASC) as rev_change
FROM revenue_by_month
ORDER BY card_type, revenue_date ASC;
- [ビューを保存] をクリックします。
- [プロジェクト名] で現在のプロジェクトを選択します。
- 新しく作成したデータセットを選択します。
bq_demo_shared
- [Table Name](テーブル名):
rev_change_by_card_type
- [保存] をクリックします。

ビューとデータセットの共有
- BigQuery UI の左側のリソース ペインで、「bq_demo_shared」データセットを選択します。
- データセット情報ペインで [データセットを共有] をクリックします。
- メールアドレスを入力する
- [ロール] プルダウン メニューから [BigQuery データ閲覧者] を選択します
- [追加] をクリックします。
- [完了] をクリックします。

スプレッドシートでのデータ探索
[競合他社との比較におけるセールスポイント]: 競合他社と比較した BigQuery のもう 1 つのメリットは、BI Engine です。BI Engine を使用すると、インメモリ キャッシュ エンジンを介して、BI タイプの概要クエリを 1 秒未満で返すことができます。この機能は現在 Google データポータルでサポートされていますが、まもなく BigQuery のすべてのクエリを高速化できるようになります。
例:
Snowflake はダッシュボードとデータの可視化にサードパーティの BI ツールを使用しますが、GCP はコネクテッド シート、データポータル、Looker などの統合 BI ツールを幅広く提供しています。
- BigQuery UI の左側のリソース ペインで、「rev_change_by_card_type」ビューを選択します。
- 虫メガネをクリックしてビューをクエリします。

- タイプ:
SELECT *
FROM bq_demo_shared.rev_change_by_card_type
- [実行] をクリックします。
- [結果] ペインの [エクスポート] アイコンをクリックします。
- [スプレッドシートでデータを分析] を選択します。

- [分析を開始] をクリックします。
- [ピボット テーブル] を選択します。
- [新しいシート] を選択します。
- [作成] をクリック
- スプレッドシート ウィンドウの右側にあるピボット テーブル エディタの [行] セクションに「revenue_date」を追加します。
- ピボット テーブル エディタの [列] セクションに「card_type」を追加します。
- ピボット テーブル エディタの [列] セクションに「monthly_rev」を追加します。
- [適用] をクリックします。
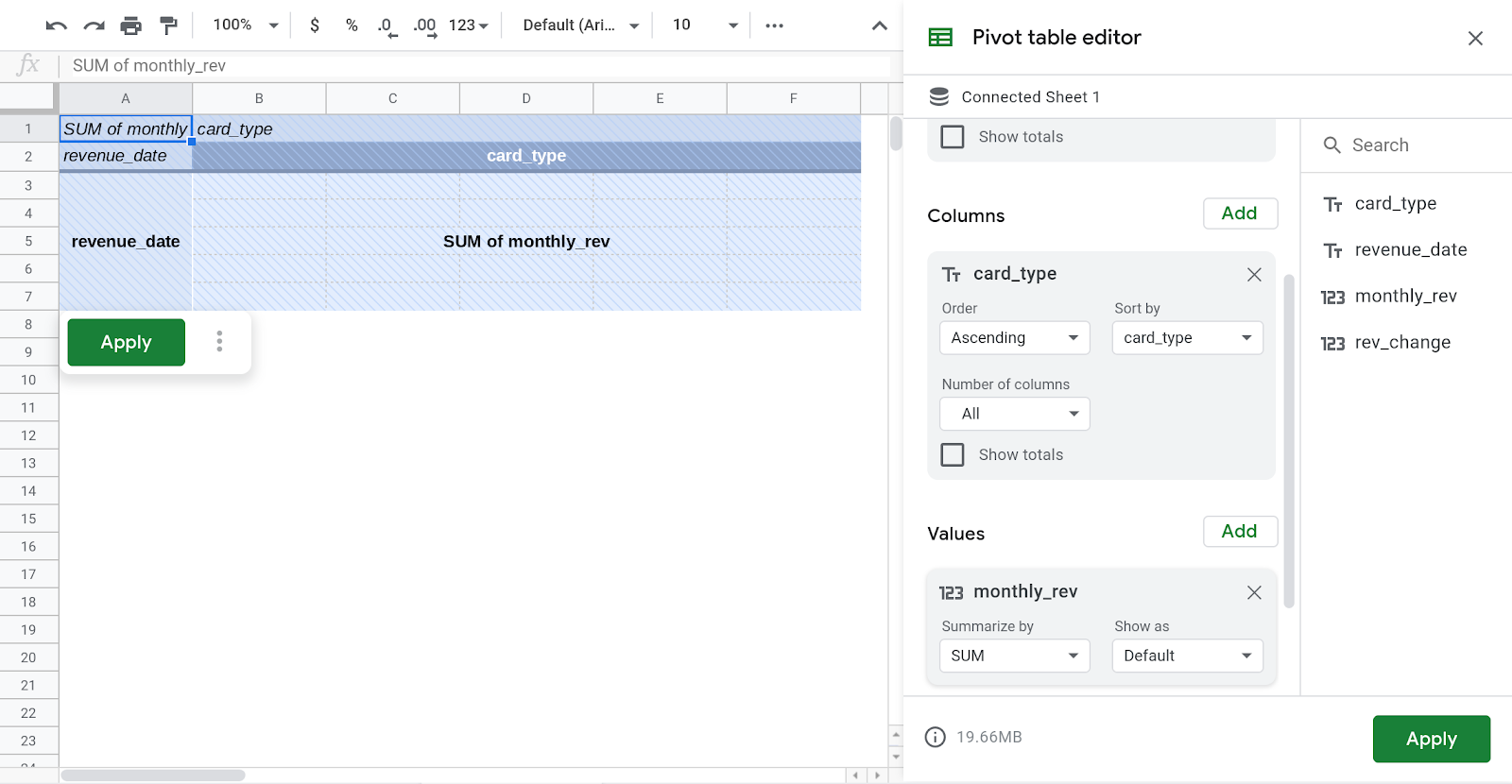
- スプレッドシートの UI の上部にあるリボンに移動し、[グラフを挿入] を選択します。
4. 設定: データ統合
このセクションでは、新しいテーブルを作成し、Google Cloud で利用可能な多くの一般公開データセットの 1 つで JOIN を実行する方法について説明します。
[競合他社に関する話のポイント]:
BigQuery は、長年にわたって共有データセットをサポートしてきました。どのプロジェクトのユーザーも、一般公開データセットと、共有されている他のプロジェクトのデータセットの両方をクエリできます。
BigQuery は、外部テーブルを使用して GCS のデータレイクをサポートできます。BigQuery は、一括読み込みに加えて、1 秒あたり数百 MB 以上の速度でデータをデータベースにストリーミングする機能もサポートしています。Snowflake はストリーミング データをサポートしていません。
新しいテーブルにデータをインポートする
- リソース ペインで bq_demo データセットを選択します。
- データセット情報ペインで [テーブルを作成] を選択します。
- [ソース] で [Google Cloud Storage] を選択する
- ファイルパスのテキスト ボックスで次の操作を行います。
gs://retail-banking-looker/district
- ファイル形式で CSV を選択する
- [テーブル名] に「district」と入力します。
- [スキーマの自動検出] のチェックボックスをオンにします。
- [テーブルを作成] をクリックします
一般公開データセットのクエリ
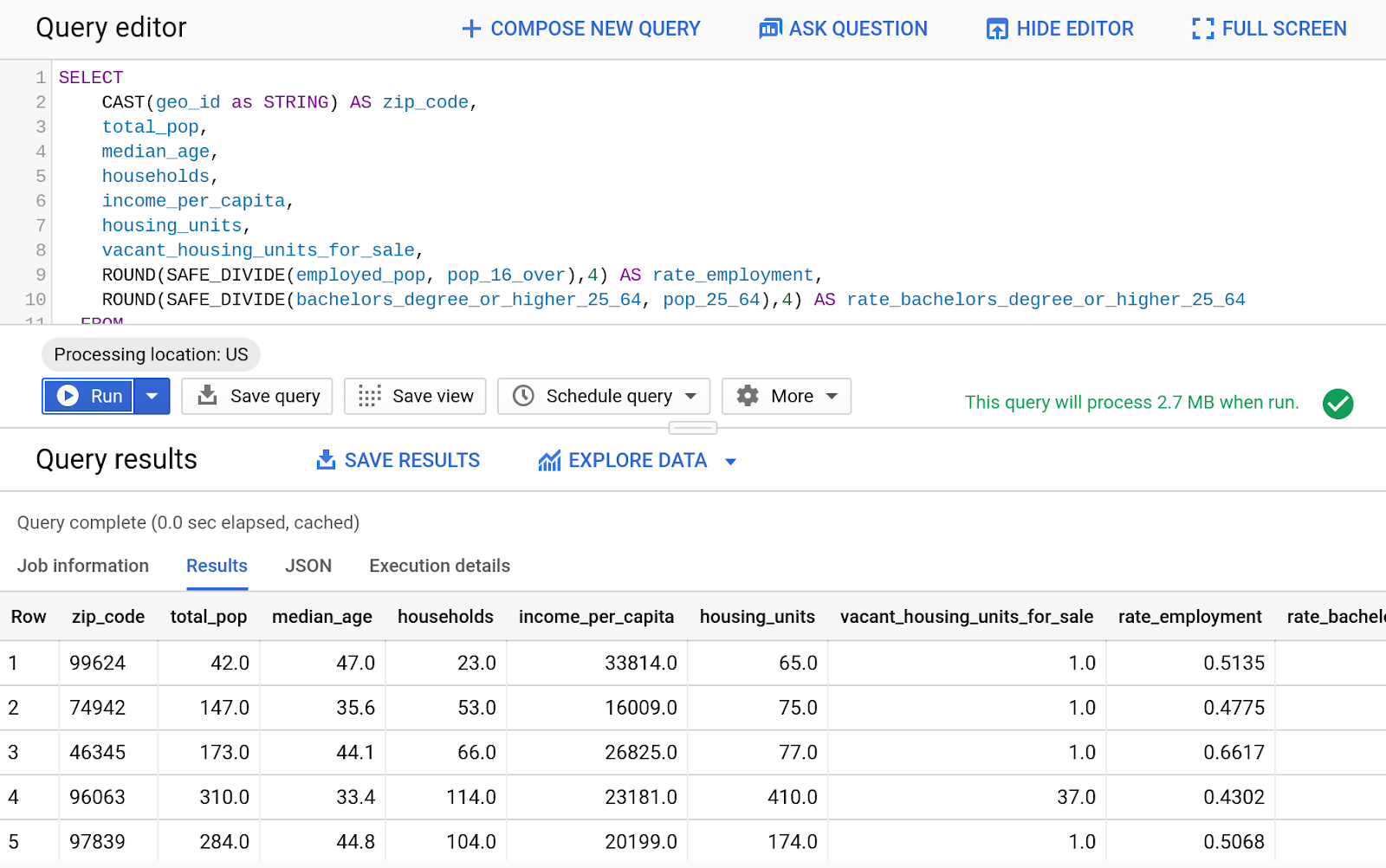
- クエリエディタで、次のクエリを入力します。
SELECT
CAST(geo_id as STRING) AS zip_code,
total_pop,
median_age,
households,
income_per_capita,
housing_units,
vacant_housing_units_for_sale,
ROUND(SAFE_DIVIDE(employed_pop, pop_16_over),4) AS rate_employment,
ROUND(SAFE_DIVIDE(bachelors_degree_or_higher_25_64, pop_25_64),4) AS rate_bachelors_degree_or_higher_25_64
FROM
`bigquery-public-data.census_bureau_acs.zip_codes_2017_5yr`;
- [実行] をクリックします。
- 結果を表示する
- 次に、この一般公開データを別のクエリと結合します。クエリエディタに次の SQL コードを入力します。
WITH customer_counts AS (
select regexp_extract(address, "[0-9][0-9][0-9][0-9][0-9]") as zip_code,
count(*) as num_clients
FROM bq_demo.client
GROUP BY zip_code
)
SELECT
CAST(geo_id as STRING) AS zip_code,
total_pop,
median_age,
households,
income_per_capita,
ROUND(SAFE_DIVIDE(employed_pop, pop_16_over),4) AS rate_employment,
num_clients
FROM
`bigquery-public-data.census_bureau_acs.zip_codes_2017_5yr`
JOIN customer_counts on zip_code = geo_id
ORDER BY num_clients DESC
- [実行] をクリックします。
- 結果を表示する

5. 容量管理
スロットと予約の操作
BQ には、ニーズに合わせて選べる複数の料金モデルが用意されています。ほとんどの大規模なお客様は、予約済み容量による予測可能な料金設定のために、主に定額料金を利用しています。ベースライン容量を超えるバーストの場合、BQ はフレキシブル スロットを提供します。これにより、実行中のクエリに影響を与えることなく、追加容量をオンザフライで拡張し、自動的に縮小できます。BQ にはバイトスキャン モデルもあり、実行したクエリに対してのみ料金が発生します。
[競合他社との差別化ポイント: 一部の競合他社は、固定容量モデルのみを採用しています。このモデルでは、組織内の各ワークロードに仮想ウェアハウスを割り当てる必要があります。BigQuery を簡単に始めることができる低コストのクエリ単位モデルに加えて、アイドル状態の容量をワークロードのセット間で共有できる定額容量料金モデルもサポートしています。]
- [予約] タブに移動します。
- [スロットを購入] をクリックします。
- 期間として [Flex] を選択します。
- 500 スロットを選択します。
- 購入を確認します。
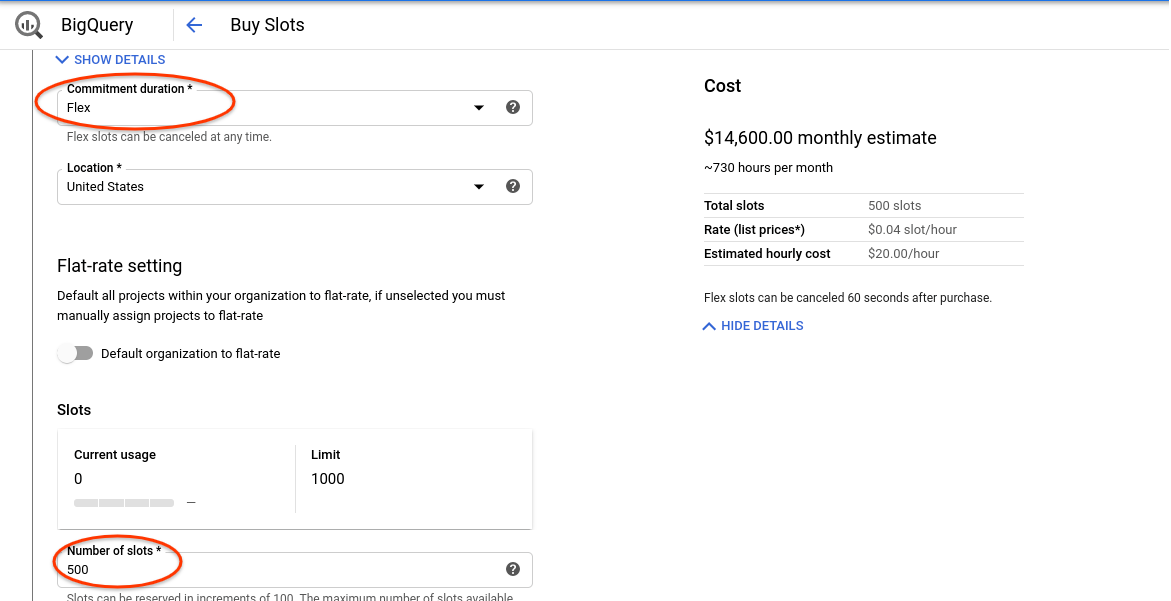
- [スロット コミットメントを表示] をクリックします。
- [予約を作成] をクリックします。
- 予約名としてユーザー「demo」
- ロケーションとして米国を選択
- スロットに 500 と入力します(すべて利用可能)。
- [割り当て] をクリックします
- 組織プロジェクトに現在のプロジェクトを選択
- 予約 ID に「demo」を選択する
- [作成] をクリックします。」