
1. Введение
Обзор
В этой лабораторной работе вы изучите многомодальный рабочий процесс анализа данных в BigQuery , построенный на примере рынка недвижимости. Вы начнете с исходного набора данных, содержащего объявления о продаже домов и их изображения, обогатите эти данные с помощью ИИ для извлечения визуальных признаков, построите модель кластеризации для выявления различных сегментов рынка и, наконец, создадите мощный инструмент визуального поиска с использованием векторных представлений.
Вы сравните этот SQL-ориентированный рабочий процесс с современным генеративным подходом в области искусственного интеллекта, используя Data Science Agent для автоматического создания модели кластеризации на основе Python из простого текстового запроса.
Что вы узнаете
- Подготовьте исходный набор данных объявлений о продаже недвижимости для анализа с помощью инженерии признаков.
- Обогатите объявления , используя функции искусственного интеллекта BigQuery для анализа фотографий домов и выявления ключевых визуальных особенностей.
- Создайте и оцените модель K-средних с помощью BigQuery Machine Learning (BQML) для сегментации объектов недвижимости на отдельные кластеры.
- Автоматизируйте создание моделей , используя Data Science Agent для генерации кластерной модели с помощью Python.
- Создайте векторные представления для изображений домов, чтобы обеспечить работу инструмента визуального поиска, позволяющего находить похожие дома по текстовым или графическим запросам.
Предварительные требования
Перед началом лабораторной работы вам необходимо ознакомиться со следующим:
- Основы программирования на SQL и Python.
- Запуск кода Python в блокноте Jupyter.
2. Прежде чем начать
Создайте проект в Google Cloud.
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud .

- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
Включите API с помощью Cloud Shell
Cloud Shell — это среда командной строки, работающая в Google Cloud и поставляемая с предустановленными необходимыми инструментами.
- В верхней части консоли Google Cloud нажмите кнопку «Активировать Cloud Shell» :

- После подключения к Cloud Shell выполните следующую команду для проверки аутентификации в Cloud Shell:
gcloud auth list
- Выполните следующую команду, чтобы убедиться, что ваш проект настроен для использования с gcloud:
gcloud config list project
- Если ваш проект не задан, используйте следующую команду для его установки:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project $PROJECT_ID
Включить API
- Выполните эту команду, чтобы включить все необходимые API и сервисы:
gcloud services enable bigquery.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
aiplatform.googleapis.com
- После успешного выполнения команды вы должны увидеть сообщение, похожее на показанное ниже:
Operation "operations/..." finished successfully.
- Выйти из Cloud Shell.
3. Откройте лабораторный блокнот в BigQuery Studio.
Навигация по пользовательскому интерфейсу:
- В консоли Google Cloud перейдите в меню «Навигация» > «BigQuery» .
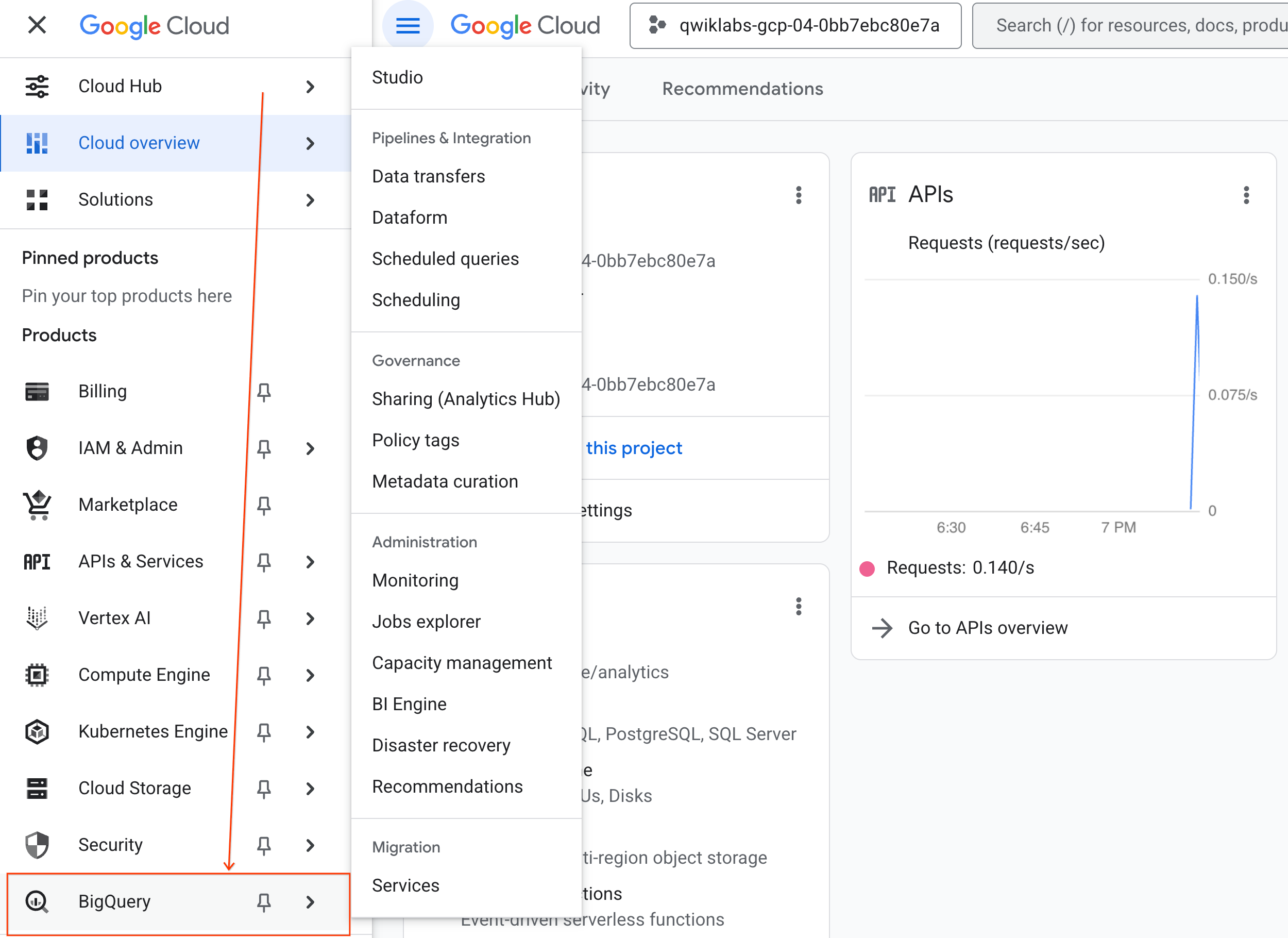
- В панели BigQuery Studio щелкните стрелку раскрывающегося списка, наведите курсор на пункт «Блокнот» и выберите «Загрузить» .
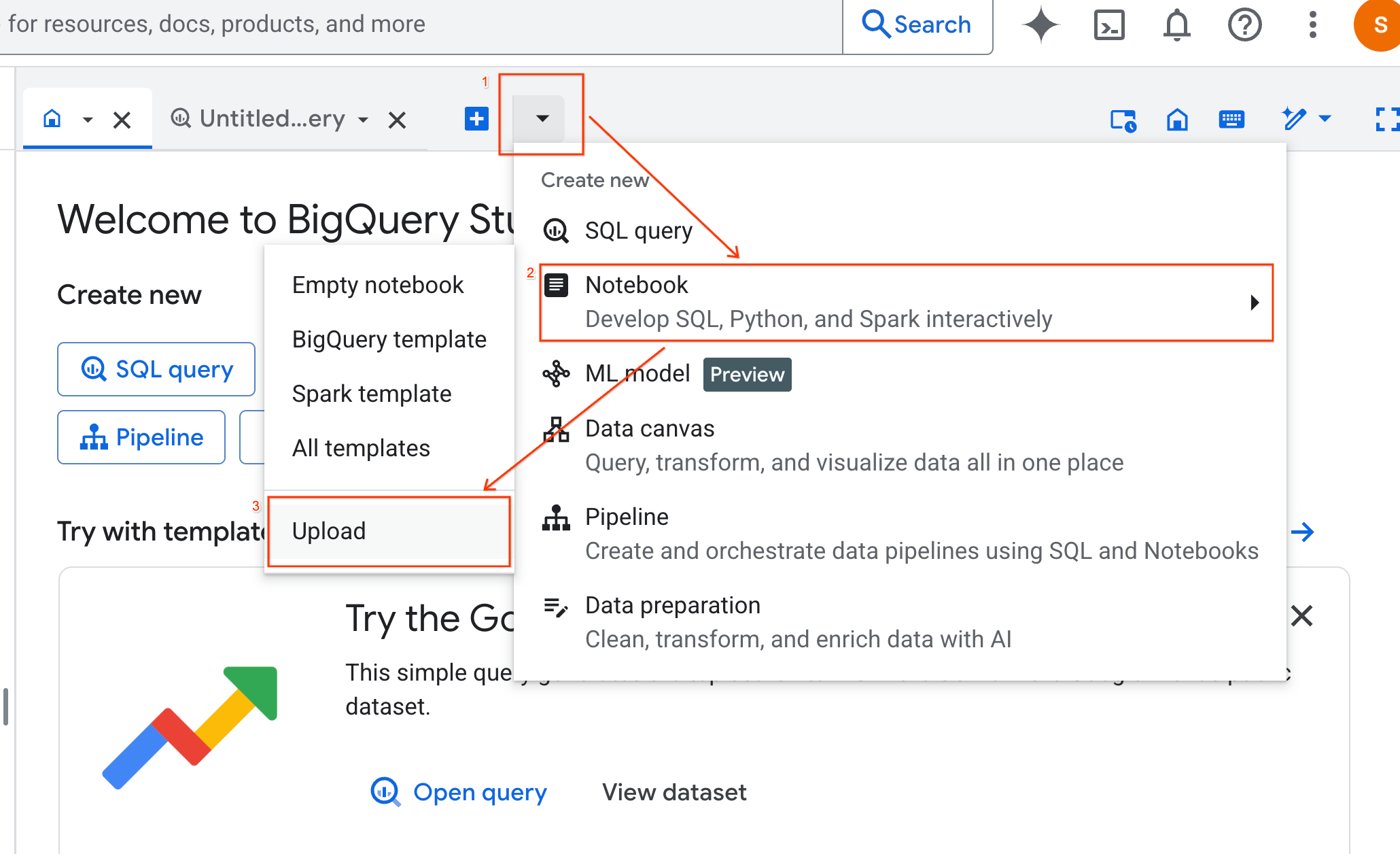
- Выберите переключатель «URL» и введите следующий URL-адрес:
https://github.com/GoogleCloudPlatform/generative-ai/blob/main/gemini/use-cases/applying-llms-to-data/ai-assisted-data-science/ai-assisted-data-science.ipynb
- Установите регион на
us-central1и нажмите «Загрузить» .

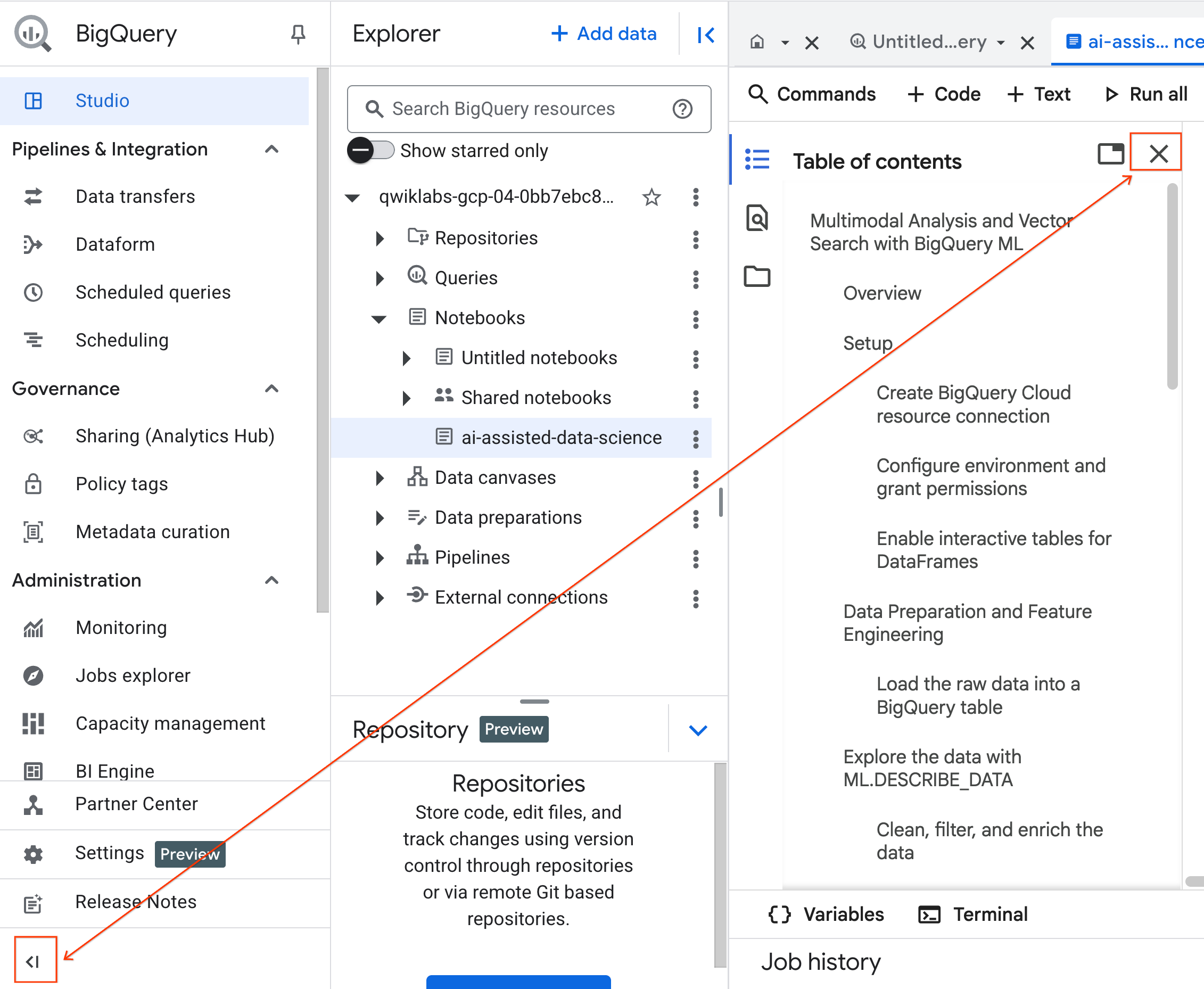
- Чтобы открыть блокнот, щелкните стрелку раскрывающегося списка в панели Проводника , содержащей идентификатор вашего проекта. Затем щелкните раскрывающийся список «Блокноты» . Щелкните блокнот
ai-assisted-data-science.

- (Необязательно) Сверните меню навигации BigQuery и оглавление блокнота, чтобы освободить больше места.
4. Подключитесь к среде выполнения и запустите код настройки.
- Нажмите «Подключиться» . Если появится всплывающее окно, авторизуйте Colab Enterprise, указав свою учетную запись. Ваш блокнот автоматически подключится к среде выполнения. Это может занять несколько минут.

- После установки среды выполнения вы увидите следующее:

- Внутри блокнота прокрутите до раздела «Настройка» . Нажмите кнопку «Запустить» рядом со скрытыми ячейками. Это создаст несколько ресурсов, необходимых для лабораторной работы в вашем проекте. Этот процесс может занять минуту. Пока что можете проверить ячейки в разделе «Настройка» , воспользуйтесь этой возможностью.

5. Подготовка данных и разработка признаков
В этом разделе вы пройдете первый важный шаг в любом проекте по анализу данных: подготовку данных. Вы начнете с создания набора данных BigQuery для организации вашей работы, а затем загрузите необработанные данные о недвижимости/жилье из CSV-файла в Cloud Storage в новую таблицу.
Затем вы преобразуете эти исходные данные в очищенную таблицу с новыми признаками. Это включает в себя фильтрацию объявлений, создание нового признака property_age и подготовку данных изображений для мультимодального анализа.
6. Мультимодальное обогащение с использованием функций искусственного интеллекта.
Теперь вы сможете обогатить свои данные, используя возможности генеративного ИИ. В этом разделе вы воспользуетесь встроенными функциями ИИ BigQuery для анализа изображений каждого объявления о продаже дома.
Подключив BigQuery к модели Gemini , вы можете извлекать из изображений новые ценные характеристики (например, находится ли недвижимость рядом с водой и краткое описание дома) непосредственно с помощью SQL.
7. Обучение модели с использованием кластеризации методом K-средних.
Имея на руках обогащенный набор данных, вы готовы создать модель машинного обучения. Ваша цель — сегментировать объявления о продаже домов на отдельные группы, и для этого вы обучаете модель кластеризации методом K-средних непосредственно в BigQuery, используя BigQuery Machine Learning (BQML). В рамках этого единственного шага вы также регистрируете модель в реестре моделей Vertex AI , делая ее мгновенно доступной в более широкой экосистеме MLOps в Google Cloud.
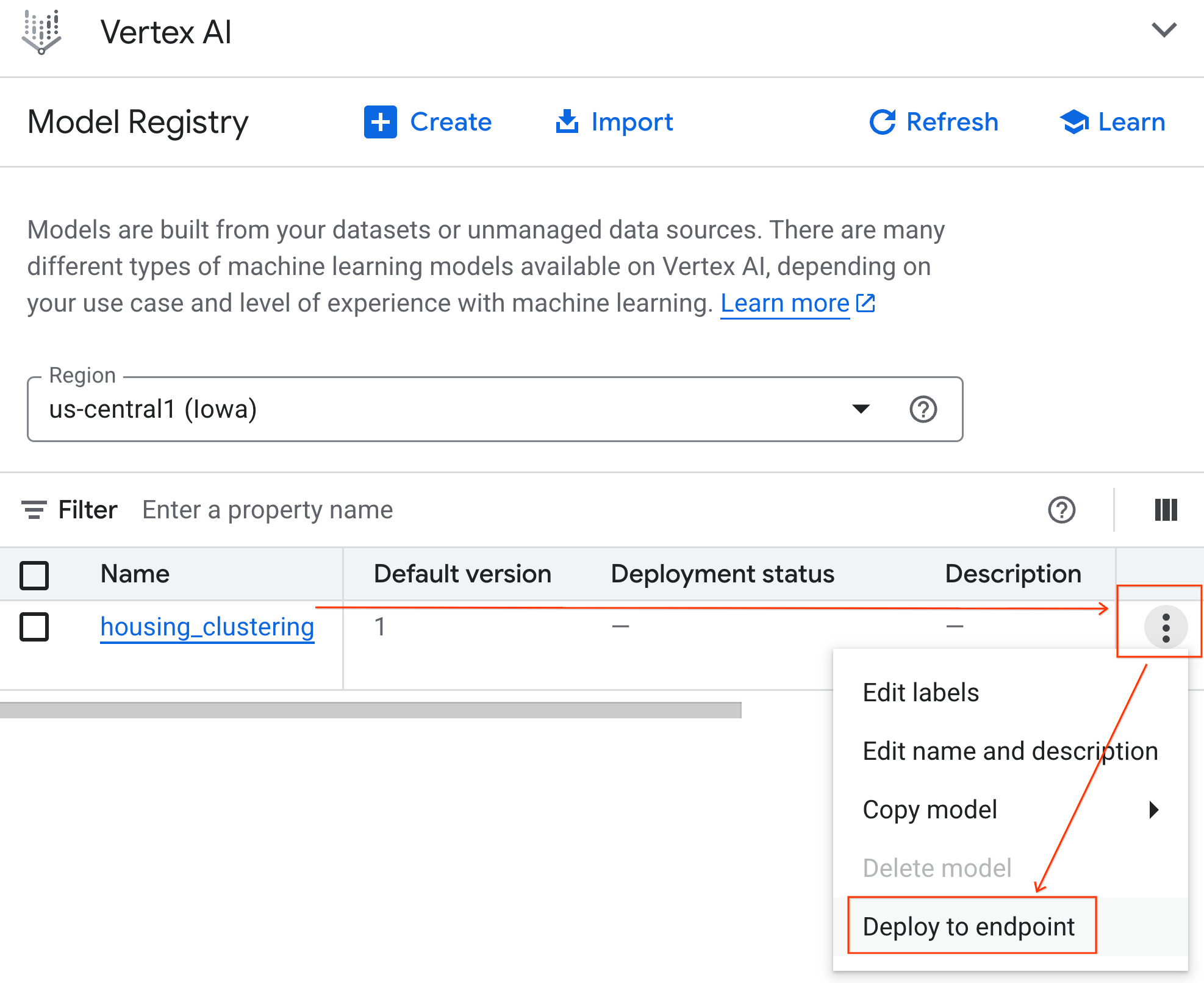
Чтобы убедиться в успешной регистрации вашей модели, вы можете найти её в реестре моделей Vertex AI, выполнив следующие действия:
- В консоли Google Cloud нажмите на меню навигации (☰) в верхнем левом углу.
- Прокрутите страницу до раздела Vertex AI и нажмите «Реестр моделей» . Теперь вы увидите свою модель BQML в списке вместе со всеми остальными вашими пользовательскими моделями.

- В списке моделей найдите модель с именем housing_clustering . Следующий шаг – развертывание модели на конечной точке , что сделает её доступной для прогнозирования в реальном времени за пределами среды BigQuery.
После изучения реестра моделей вы можете вернуться к своему блокноту Colab в BigQuery, выполнив следующие шаги:
- В меню навигации (☰) перейдите в раздел BigQuery > Studio .
- Разверните меню в панели «Проводник» , чтобы найти свою записную книжку и открыть её.
8. Оценка модели и прогнозирование
После обучения модели следующим шагом является анализ созданных ею кластеров. Здесь вы используете функции машинного обучения BigQuery, такие как ML.EVALUATE и ML.CENTROIDS для анализа качества модели и определяющих характеристик каждого сегмента.
Затем вы используете ML.PREDICT для присвоения каждому дому кластера. Выполнив этот запрос с помощью команды %%bigquery df , вы сохраняете результаты в DataFrame pandas с именем df . Это делает данные немедленно доступными для последующих шагов Python. Это подчеркивает совместимость между SQL и Python в Colab Enterprise.
9. Визуализация и интерпретация кластеров.
Теперь, когда ваши прогнозы загружены в DataFrame, вы можете создавать визуализации, чтобы оживить данные. В этом разделе вы будете использовать популярные библиотеки Python, такие как Matplotlib, для изучения различий между сегментами жилья.
Вы будете создавать диаграммы размаха и столбчатые диаграммы для визуального сравнения ключевых характеристик, таких как цена и возраст недвижимости, что позволит легко сформировать интуитивно понятное представление о каждой группе объектов.
10. Создание описаний кластеров с помощью моделей Gemini.
Хотя числовые центроиды и диаграммы обладают мощными возможностями, генеративный ИИ позволяет пойти еще дальше и создать подробные качественные портреты для каждого сегмента рынка жилья. Это помогает понять не только то, что представляют собой кластеры, но и кого они представляют.
В этом разделе вы сначала суммируете средние статистические данные для каждого кластера, такие как цена и площадь. Затем вы передадите эти данные в запрос для модели Gemini. После этого вы дадите модели указание действовать как профессионал в сфере недвижимости и сгенерировать подробное резюме, включая ключевые характеристики и целевого покупателя для каждого сегмента. В результате вы получите набор четких, понятных для человека описаний, которые сделают кластеры сразу понятными и пригодными для практического применения маркетинговой командой.
Вы можете свободно изменять задание по своему усмотрению и экспериментировать с результатами!
11. Автоматизация моделирования с помощью агента анализа данных.
Теперь вы познакомитесь с мощным альтернативным рабочим процессом. Вместо написания кода вручную вы будете использовать встроенный агент Data Science Agent для автоматического создания полного рабочего процесса кластеризации на основе одного запроса на естественном языке.
Выполните следующие шаги, чтобы создать и запустить модель с помощью агента:
- В панели BigQuery Studio щелкните стрелку раскрывающегося списка, наведите курсор на пункт «Блокнот» и выберите «Пустой блокнот» . Это гарантирует, что код агента не будет конфликтовать с вашим исходным лабораторным блокнотом.

- Интерфейс чата Data Science Agent открывается в нижней части блокнота. Нажмите кнопку « Переместить на панель» , чтобы закрепить чат справа.

- Начните вводить
@listing_multimodalв панели чата и щелкните по таблице. Это явно устанавливает таблицуlistings_multimodalв качестве контекстной.

- Скопируйте приведенный ниже текст и введите его в окно чата с агентом. Затем нажмите «Отправить» , чтобы отправить текст агенту.
Use the selected table to generate a k-means clustering model with 3 clusters for housing listings. Then, help me understand the characteristics of each cluster so I can market to them as a real estate professional. Use Python.

- Агент обдумает и разработает план. Если вас устраивает этот план, нажмите «Принять и запустить» . Агент сгенерирует код на Python в одной или нескольких новых ячейках.
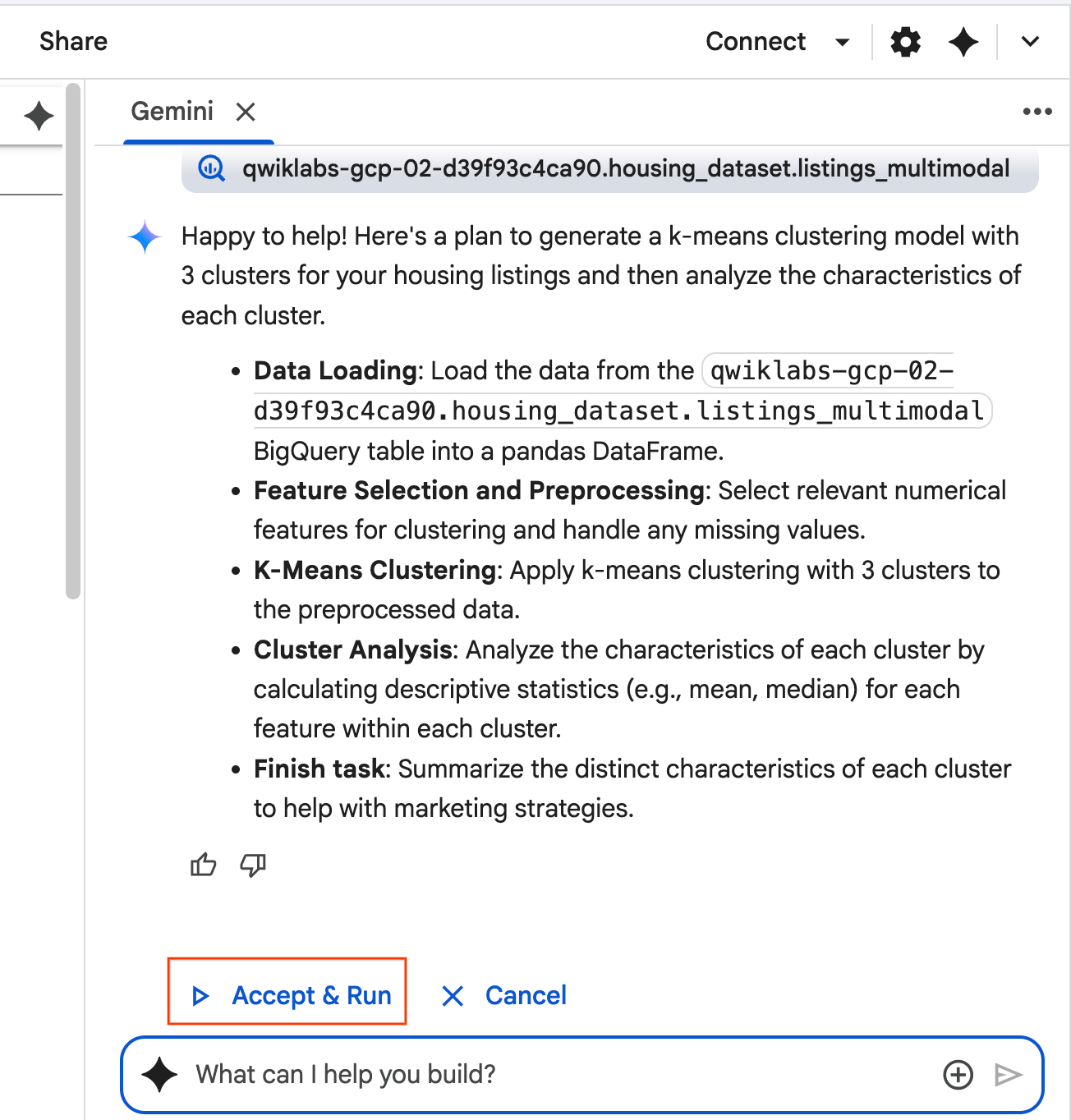
- Агент запрашивает подтверждение и выполнение каждого сгенерированного блока кода. Это позволяет контролировать процесс вручную. Вы можете просмотреть или отредактировать код и продолжить выполнение каждого шага, пока не завершите его.

- После завершения просто закройте эту новую вкладку блокнота и вернитесь к исходной вкладке
ai-assisted-data-science.ipynbчтобы продолжить выполнение заключительной части лабораторной работы.
12. Мультимодальный поиск с использованием вложений и векторного поиска
В этом заключительном разделе вы реализуете многомодальный поиск непосредственно в BigQuery. Это позволяет выполнять интуитивно понятный поиск, например, находить дома по текстовому описанию или дома, похожие на изображение в примере.
Процесс начинается с преобразования каждого изображения дома в числовое представление, называемое эмбеддингом . Эмбеддинг отражает семантическое значение изображения, позволяя находить похожие объекты путем сравнения их числовых векторов.
Для генерации этих векторов для всех ваших объявлений вы будете использовать модель multimodalembedding . После создания векторного индекса для ускорения поиска вы выполните два типа поиска сходства: текст-изображение (поиск домов, соответствующих описанию) и изображение-изображение (поиск домов, похожих на пример изображения).
Всю эту работу вы выполните в BigQuery, используя такие функции, как ML.GENERATE_EMBEDDING для генерации эмбеддингов или VECTOR_SEARCH для поиска сходства.
13. Уборка
Чтобы очистить все ресурсы Google Cloud, используемые в этом проекте, вы можете удалить проект Google Cloud .
В качестве альтернативы вы можете удалить отдельные созданные вами ресурсы, выполнив следующий код в новой ячейке вашего блокнота:
# Delete the BigQuery tables
!bq rm --table -f housing_dataset.listings
!bq rm --table -f housing_dataset.listings_multimodal
!bq rm --table -f housing_dataset.home_embeddings
# Delete the remote model
!bq rm --model -f housing_dataset.gemini
!bq rm --model -f housing_dataset.kmeans_clustering_model
!bq rm --model -f housing_dataset.multimodal_embedding_model
# Delete the remote connection
!bq rm --connection --project_id=$PROJECT_ID --location=us ai_connection
# Delete the BigQuery dataset
!bq rm -r -f $PROJECT_ID:housing_dataset
Наконец, вы можете удалить сам блокнот:
- В панели «Проводник» BigQuery Studio разверните свой проект и узел «Блокноты» .
- Нажмите на три вертикальные точки рядом с блокнотом
ai-assisted-data-science. - Выберите «Удалить» .
14. Поздравляем!
Поздравляем с завершением Codelab!
Что мы рассмотрели
- Подготовьте исходный набор данных объявлений о продаже недвижимости для анализа с помощью инженерии признаков.
- Обогатите объявления , используя функции искусственного интеллекта BigQuery для анализа фотографий домов и выявления ключевых визуальных особенностей.
- Создайте и оцените модель K-средних с помощью BigQuery Machine Learning (BQML) для сегментации объектов недвижимости на отдельные кластеры.
- Автоматизируйте создание моделей , используя Data Science Agent для генерации кластерной модели с помощью Python.
- Создайте векторные представления для изображений домов, чтобы обеспечить работу инструмента визуального поиска, позволяющего находить похожие дома по текстовым или графическим запросам.