
1. Введение
В этом практическом занятии вы научитесь использовать AlloyDB AI, комбинируя векторный поиск с встраиваниями Vertex AI. Это занятие является частью серии практических занятий, посвященных возможностям AlloyDB AI. Подробнее можно узнать на странице AlloyDB AI в документации.

Предварительные требования
- Базовое понимание Google Cloud и консоли.
- Базовые навыки работы с командной строкой и оболочкой Google Sheets.
Что вы узнаете
- Как развернуть кластер AlloyDB и основной экземпляр
- Как подключиться к AlloyDB из виртуальной машины Google Compute Engine
- Как создать базу данных и включить AlloyDB AI
- Как загрузить данные в базу данных
- Как использовать AlloyDB Studio
- Как использовать модель встраивания Vertex AI в AlloyDB
- Как использовать Vertex AI Studio
- Как улучшить результаты, используя генеративную модель Vertex AI
- Как повысить производительность с помощью векторного индекса
Что вам понадобится
- Аккаунт Google Cloud и проект Google Cloud
- Веб-браузер, например Chrome.
2. Настройка и требования
Настройка проекта
- Войдите в консоль Google Cloud . Если у вас еще нет учетной записи Gmail или Google Workspace, вам необходимо ее создать .
Используйте личный аккаунт вместо рабочего или учебного.
- Создайте новый проект или используйте существующий. Чтобы создать новый проект в консоли Google Cloud, в заголовке нажмите кнопку «Выбрать проект», после чего откроется всплывающее окно.

В окне «Выберите проект» нажмите кнопку «Новый проект», после чего откроется диалоговое окно для создания нового проекта.

В диалоговом окне введите желаемое название проекта и выберите местоположение.
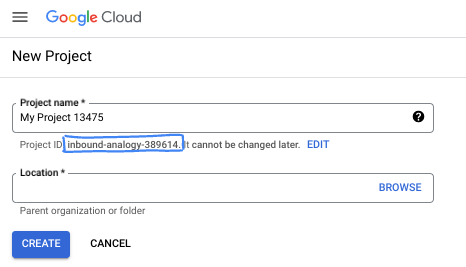
- Название проекта — это отображаемое имя участников данного проекта. Название проекта не используется API Google и может быть изменено в любое время.
- Идентификатор проекта (Project ID) уникален для всех проектов Google Cloud и является неизменяемым (его нельзя изменить после установки). Консоль Google Cloud автоматически генерирует уникальный идентификатор, но вы можете настроить его. Если вам не нравится сгенерированный идентификатор, вы можете сгенерировать другой случайный или указать свой собственный, чтобы проверить его доступность. В большинстве практических заданий вам потребуется указать идентификатор вашего проекта, который обычно обозначается заполнителем PROJECT_ID.
- К вашему сведению, существует третье значение — номер проекта , которое используется некоторыми API. Подробнее обо всех трех значениях можно узнать в документации .
Включить выставление счетов
Для включения оплаты у вас есть два варианта. Вы можете использовать свой личный платежный аккаунт или обменять средства, выполнив следующие шаги.
Обменяйте 5 долларов США на кредиты Google Cloud (по желанию)
Для проведения этого мастер-класса вам потребуется платежный аккаунт с достаточным балансом. Если вы планируете использовать собственную платежную систему, этот шаг можно пропустить.
- Перейдите по этой ссылке и войдите в систему, используя личный аккаунт Google.
- Вы увидите что-то подобное:

- Нажмите кнопку «НАЖМИТЕ ЗДЕСЬ ДЛЯ ДОСТУПА К ВАШИМ КРЕДИТАМ» . Это переведет вас на страницу настройки вашего платежного профиля. Если вам будет предложено зарегистрироваться для бесплатного пробного периода, нажмите «Отмена» и продолжите привязку платежной системы.

- Нажмите «Подтвердить». Теперь вы подключены к пробному платёжному аккаунту Google Cloud Platform.

Создайте личный платежный аккаунт.
Если вы настроили оплату с использованием кредитов Google Cloud, этот шаг можно пропустить.
Чтобы настроить личный платежный аккаунт, перейдите сюда, чтобы включить оплату в облачной консоли.
Несколько замечаний:
- Выполнение этой лабораторной работы должно обойтись менее чем в 3 доллара США в виде облачных ресурсов.
- В конце этой лабораторной работы вы можете выполнить действия по удалению ресурсов, чтобы избежать дальнейших списаний средств.
- Новые пользователи могут воспользоваться бесплатной пробной версией стоимостью 300 долларов США .
Запустить Cloud Shell
Хотя Google Cloud можно управлять удаленно с ноутбука, в этом практическом занятии вы будете использовать Google Cloud Shell — среду командной строки, работающую в облаке.
В консоли Google Cloud нажмите на значок Cloud Shell на панели инструментов в правом верхнем углу:
В качестве альтернативы вы можете нажать G, а затем S. Эта последовательность активирует Cloud Shell, если вы находитесь в консоли Google Cloud, или воспользуйтесь этой ссылкой .
Подготовка и подключение к среде займут всего несколько минут. После завершения вы должны увидеть что-то подобное:

Эта виртуальная машина содержит все необходимые инструменты разработки. Она предоставляет постоянный домашний каталог объемом 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Вся работа в этом практическом задании может выполняться в браузере. Вам не нужно ничего устанавливать.
3. Прежде чем начать
Включить API
Выход:
Для использования AlloyDB , Compute Engine , сетевых сервисов и Vertex AI необходимо включить соответствующие API в вашем проекте Google Cloud.
Включение API
В терминале Cloud Shell убедитесь, что идентификатор вашего проекта указан правильно:
gcloud config set project [YOUR-PROJECT-ID]
Установите переменную среды PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Включите все необходимые API:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Ожидаемый результат
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Представляем API.
- API AlloyDB (
alloydb.googleapis.com) позволяет создавать, управлять и масштабировать кластеры AlloyDB для PostgreSQL. Он предоставляет полностью управляемый, совместимый с PostgreSQL сервис баз данных, разработанный для ресурсоемких корпоративных транзакционных и аналитических задач. - API Compute Engine (
compute.googleapis.com) позволяет создавать и управлять виртуальными машинами (ВМ), постоянными дисками и сетевыми настройками. Он предоставляет базовую инфраструктуру как услугу (IaaS), необходимую для запуска ваших рабочих нагрузок и размещения базовой инфраструктуры для множества управляемых сервисов. - API Cloud Resource Manager (
cloudresourcemanager.googleapis.com) позволяет программно управлять метаданными и конфигурацией вашего проекта Google Cloud. Он позволяет организовывать ресурсы, управлять политиками управления идентификацией и доступом (IAM) и проверять разрешения в иерархии проекта. - API для настройки сетевого взаимодействия сервисов (
servicenetworking.googleapis.com) позволяет автоматизировать настройку частного подключения между вашей виртуальной частной сетью (VPC) и управляемыми сервисами Google. Он необходим для установления частного IP-доступа для таких сервисов, как AlloyDB, чтобы они могли безопасно взаимодействовать с другими вашими ресурсами. - API Vertex AI (
aiplatform.googleapis.com) позволяет вашим приложениям создавать, развертывать и масштабировать модели машинного обучения. Он предоставляет единый интерфейс для всех сервисов искусственного интеллекта Google Cloud, включая доступ к моделям генеративного ИИ (например, Gemini) и обучению пользовательских моделей.
При желании вы можете настроить свой регион по умолчанию для использования моделей встраивания Vertex AI. Подробнее о доступных регионах для Vertex AI можно прочитать здесь. В примере мы используем регион us-central1.
gcloud config set compute/region us-central1
4. Развертывание AlloyDB
Перед созданием кластера AlloyDB нам необходим доступный диапазон частных IP-адресов в нашей VPC, который будет использоваться будущим экземпляром AlloyDB. Если его нет, нам нужно его создать, назначить для использования внутренними сервисами Google, после чего мы сможем создать кластер и экземпляр.
Создать частный диапазон IP-адресов
Нам необходимо настроить параметры доступа к частным сервисам (Private Service Access, VPC) в нашей VPC для AlloyDB. Предполагается, что в проекте используется «стандартная» сеть VPC, и она будет применяться для всех действий.
Создайте диапазон частных IP-адресов:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Создайте частное соединение, используя выделенный диапазон IP-адресов:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
Создание кластера AlloyDB
В этом разделе мы создаём кластер AlloyDB в регионе us-central1.
Задайте пароль для пользователя postgres. Вы можете задать собственный пароль или использовать функцию генерации случайных чисел.
export PGPASSWORD=`openssl rand -hex 12`
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
Запишите пароль от PostgreSQL для дальнейшего использования.
echo $PGPASSWORD
Этот пароль понадобится вам в будущем для подключения к экземпляру под учетной записью postgres. Я рекомендую записать его или скопировать куда-нибудь, чтобы иметь возможность использовать позже.
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723
Создайте кластер для бесплатной пробной версии
Если вы раньше не использовали AlloyDB, вы можете создать бесплатный пробный кластер:
Определите регион и имя кластера AlloyDB. Мы будем использовать регион us-central1 и имя кластера alloydb-aip-01:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Выполните команду для создания кластера:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Ожидаемый вывод в консоль:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Создайте основной экземпляр AlloyDB для нашего кластера в той же сессии Cloud Shell. Если вы отключены, вам потребуется заново определить переменные среды для региона и имени кластера.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
Создание кластера AlloyDB Standard
Если это не первый ваш кластер AlloyDB в проекте, перейдите к созданию стандартного кластера.
Определите регион и имя кластера AlloyDB. Мы будем использовать регион us-central1 и имя кластера alloydb-aip-01:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Выполните команду для создания кластера:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Ожидаемый вывод в консоль:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Создайте основной экземпляр AlloyDB для нашего кластера в той же сессии Cloud Shell. Если вы отключены, вам потребуется заново определить переменные среды для региона и имени кластера.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. Подключитесь к AlloyDB
AlloyDB развертывается с использованием только частного соединения, поэтому для работы с базой данных нам необходима виртуальная машина с установленным клиентом PostgreSQL.
Развертывание виртуальной машины GCE
Создайте виртуальную машину GCE в том же регионе и VPC, что и кластер AlloyDB.
В оболочке Cloud Shell выполните:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE \
--create-disk=auto-delete=yes,boot=yes,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" --format="value(name)") \
--scopes=https://www.googleapis.com/auth/cloud-platform
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-402417)$ export ZONE=us-central1-a
student@cloudshell:~ (test-project-402417)$ export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE \
--create-disk=auto-delete=yes,boot=yes,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" --format="value(name)") \
--scopes=https://www.googleapis.com/auth/cloud-platform
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/zones/us-central1-a/instances/instance-1].
NAME: instance-1
ZONE: us-central1-a
MACHINE_TYPE: n1-standard-1
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.2
EXTERNAL_IP: 34.71.192.233
STATUS: RUNNING
Установите клиент PostgreSQL.
Установите клиентское программное обеспечение PostgreSQL на развернутую виртуальную машину.
Подключитесь к виртуальной машине:
gcloud compute ssh instance-1 --zone=us-central1-a
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-402417)$ gcloud compute ssh instance-1 --zone=us-central1-a Updating project ssh metadata...working..Updated [https://www.googleapis.com/compute/v1/projects/test-project-402417]. Updating project ssh metadata...done. Waiting for SSH key to propagate. Warning: Permanently added 'compute.5110295539541121102' (ECDSA) to the list of known hosts. Linux instance-1.us-central1-a.c.gleb-test-short-001-418811.internal 6.1.0-18-cloud-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.76-1 (2024-02-01) x86_64 The programs included with the Debian GNU/Linux system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. student@instance-1:~$
Установите программное обеспечение, запускаемое командой внутри виртуальной машины:
sudo apt-get update
sudo apt-get install --yes postgresql-client
Ожидаемый вывод в консоль:
student@instance-1:~$ sudo apt-get update sudo apt-get install --yes postgresql-client Get:1 https://packages.cloud.google.com/apt google-compute-engine-bullseye-stable InRelease [5146 B] Get:2 https://packages.cloud.google.com/apt cloud-sdk-bullseye InRelease [6406 B] Hit:3 https://deb.debian.org/debian bullseye InRelease Get:4 https://deb.debian.org/debian-security bullseye-security InRelease [48.4 kB] Get:5 https://packages.cloud.google.com/apt google-compute-engine-bullseye-stable/main amd64 Packages [1930 B] Get:6 https://deb.debian.org/debian bullseye-updates InRelease [44.1 kB] Get:7 https://deb.debian.org/debian bullseye-backports InRelease [49.0 kB] ...redacted... update-alternatives: using /usr/share/postgresql/13/man/man1/psql.1.gz to provide /usr/share/man/man1/psql.1.gz (psql.1.gz) in auto mode Setting up postgresql-client (13+225) ... Processing triggers for man-db (2.9.4-2) ... Processing triggers for libc-bin (2.31-13+deb11u7) ...
Подключитесь к экземпляру
Подключитесь к основному экземпляру с виртуальной машины, используя psql.
В той же вкладке Cloud Shell, где открыта SSH-сессия к вашей виртуальной машине instance-1.
Используйте указанное значение пароля AlloyDB (PGPASSWORD) и идентификатор кластера AlloyDB для подключения к AlloyDB с виртуальной машины GCE:
export PGPASSWORD=<Noted password>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export INSTANCE_IP=$(gcloud alloydb instances describe $ADBCLUSTER-pr --cluster=$ADBCLUSTER --region=$REGION --format="value(ipAddress)")
psql "host=$INSTANCE_IP user=postgres sslmode=require"
Ожидаемый вывод в консоль:
student@instance-1:~$ export PGPASSWORD=CQhOi5OygD4ps6ty student@instance-1:~$ ADBCLUSTER=alloydb-aip-01 student@instance-1:~$ REGION=us-central1 student@instance-1:~$ INSTANCE_IP=$(gcloud alloydb instances describe $ADBCLUSTER-pr --cluster=$ADBCLUSTER --region=$REGION --format="value(ipAddress)") gleb@instance-1:~$ psql "host=$INSTANCE_IP user=postgres sslmode=require" psql (15.6 (Debian 15.6-0+deb12u1), server 15.5) SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off) Type "help" for help. postgres=>
Закройте сессию psql:
exit
6. Подготовка базы данных
Нам необходимо создать базу данных, включить интеграцию с Vertex AI, создать объекты базы данных и импортировать данные.
Предоставьте необходимые разрешения AlloyDB
Добавьте разрешения Vertex AI для агента службы AlloyDB.
Откройте еще одну вкладку Cloud Shell, используя знак "+" вверху.
В новой вкладке облачной оболочки выполните:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Закройте вкладку, выполнив одну из команд, указанных на вкладке, например, «Выход»:
exit
Создать базу данных
Быстрый старт создания базы данных.
В сессии виртуальной машины GCE выполните:
Создать базу данных:
psql "host=$INSTANCE_IP user=postgres" -c "CREATE DATABASE quickstart_db"
Ожидаемый вывод в консоль:
student@instance-1:~$ psql "host=$INSTANCE_IP user=postgres" -c "CREATE DATABASE quickstart_db" CREATE DATABASE student@instance-1:~$
Включите интеграцию Vertex AI
Включите интеграцию Vertex AI и расширения pgvector в базе данных.
В виртуальной машине GCE выполните:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE"
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS vector"
Ожидаемый вывод в консоль:
student@instance-1:~$ psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE" psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS vector" CREATE EXTENSION CREATE EXTENSION student@instance-1:~$
Импорт данных
Загрузите подготовленные данные и импортируйте их в новую базу данных.
В виртуальной машине GCE выполните:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_products from stdin csv header"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_inventory from stdin csv header"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_stores from stdin csv header"
Ожидаемый вывод в консоль:
student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_products from stdin csv header" COPY 941 student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_inventory from stdin csv header" COPY 263861 student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_stores from stdin csv header" COPY 4654 student@instance-1:~$
7. Вычислите векторные представления.
После импорта данных мы получили информацию о товарах в таблице cymbal_products, данные об инвентаре, показывающие количество доступных товаров в каждом магазине, в таблице cymbal_inventory и список магазинов в таблице cymbal_stores. Нам нужно рассчитать векторные данные на основе описаний наших товаров, и для этого мы будем использовать функцию встраивания . Используя эту функцию, мы будем применять интеграцию с Vertex AI для расчета векторных данных на основе описаний наших товаров и добавления их в таблицу. Подробнее об используемой технологии можно прочитать в документации .
Создать эмбеддинг для нескольких строк несложно, но как сделать это эффективно, если их тысячи? Здесь я покажу, как создавать и управлять эмбеддингами для больших таблиц. Вы также можете узнать больше о различных вариантах и методах в руководстве .
Включить быструю генерацию встраиваний
Подключитесь к базе данных с помощью psql с вашей виртуальной машины, используя IP-адрес экземпляра AlloyDB и пароль от PostgreSQL:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Проверьте версию расширения google_ml_integration.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Версия должна быть 1.5.2 или выше. Вот пример вывода:
quickstart_db=> SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration'; extversion ------------ 1.5.2 (1 row)
По умолчанию должна быть установлена версия 1.5.2 или выше, но если в вашем экземпляре отображается более старая версия, вероятно, её необходимо обновить. Проверьте, не отключено ли техническое обслуживание для данного экземпляра.
Затем нам нужно проверить флаг базы данных. Нам необходимо включить флаг google_ml_integration.enable_faster_embedding_generation. В той же сессии psql проверьте значение этого флага.
show google_ml_integration.enable_faster_embedding_generation;
Если флаг находится в правильном положении, ожидаемый результат будет выглядеть следующим образом:
quickstart_db=> show google_ml_integration.enable_faster_embedding_generation; google_ml_integration.enable_faster_embedding_generation ---------------------------------------------------------- on (1 row)
Но если отображается "выключено", то нам нужно обновить экземпляр. Это можно сделать с помощью веб-консоли или команды gcloud, как описано в документации . Здесь я покажу, как это сделать с помощью команды gcloud:
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags google_ml_integration.enable_faster_embedding_generation=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Это может занять несколько минут, но в конечном итоге значение флага должно переключиться в положение «включено». После этого вы можете перейти к следующим шагам.
Создать столбец для встраивания
Подключитесь к базе данных с помощью psql и создайте виртуальный столбец с векторными данными, используя функцию встраивания в таблице cymbal_products. Функция встраивания возвращает векторные данные от Vertex AI на основе данных, предоставленных из столбца product_description.
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
В сессии psql после подключения к базе данных выполните:
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768);
Эта команда создаст виртуальный столбец и заполнит его векторными данными.
Ожидаемый вывод в консоль:
quickstart_db=> ALTER TABLE cymbal_products ADD COLUMN embedding vector(768); ALTER TABLE quickstart_db=>
Теперь мы можем генерировать эмбеддинги, используя пакеты по 50 строк в каждом. Вы можете поэкспериментировать с разными размерами пакетов и посмотреть, изменится ли время выполнения. В той же сессии psql выполните:
Включите таймер, чтобы измерить, сколько времени это займет:
\timing
Выполните команду:
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'embedding',
batch_size => 50
);
А вот вывод в консоль, показанный менее чем за 2 секунды во время генерации встраивания:
quickstart_db=> CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'embedding',
batch_size => 50
);
NOTICE: Initialize embedding completed successfully for table cymbal_products
CALL
Time: 1458.704 ms (00:01.459)
quickstart_db=>
По умолчанию эмбеддинги не обновляются, если обновляется соответствующий столбец product_description или вставляется совершенно новая строка. Но это можно сделать, определив параметр incremental_refresh_mode . Давайте создадим столбец " product_embeddings " и сделаем его автоматически обновляемым.
ALTER TABLE cymbal_products ADD COLUMN product_embedding vector(768);
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'product_embedding',
batch_size => 50,
incremental_refresh_mode => 'transactional'
);
А теперь давайте добавим новую строку в таблицу.
INSERT INTO "cymbal_products" ("uniq_id", "crawl_timestamp", "product_url", "product_name", "product_description", "list_price", "sale_price", "brand", "item_number", "gtin", "package_size", "category", "postal_code", "available", "product_embedding", "embedding") VALUES ('fd604542e04b470f9e6348e640cff794', NOW(), 'https://example.com/new_product', 'New Cymbal Product', 'This is a new cymbal product description.', 199.99, 149.99, 'Example Brand', 'EB123', '1234567890', 'Single', 'Cymbals', '12345', TRUE, NULL, NULL);
Мы можем сравнить различия в столбцах, используя следующий запрос:
SELECT uniq_id,embedding, (product_embedding::real[])[1:5] as product_embedding FROM cymbal_products WHERE uniq_id='fd604542e04b470f9e6348e640cff794';
В выходных данных видно, что, хотя столбец embedding остается пустым, столбец product_embedding автоматически обновляется.
quickstart_db=> SELECT uniq_id,embedding, (product_embedding::real[])[1:5] as product_embedding FROM cymbal_products WHERE uniq_id='fd604542e04b470f9e6348e640cff794';
uniq_id | embedding | product_embedding
----------------------------------+-----------+---------------------------------------------------------------
fd604542e04b470f9e6348e640cff794 | | {0.015003494,-0.005349732,-0.059790313,-0.0087091,-0.0271452}
(1 row)
Time: 3.295 ms
8. Выполните поиск сходства.
Теперь мы можем выполнить поиск, используя поиск по сходству на основе векторных значений, рассчитанных для описаний, и векторного значения, полученного для нашего запроса.
SQL-запрос можно выполнить из того же интерфейса командной строки psql или, в качестве альтернативы, из AlloyDB Studio. Любой многострочный и сложный вывод может выглядеть лучше в AlloyDB Studio.
Подключитесь к AlloyDB Studio
В следующих главах все команды SQL, требующие подключения к базе данных, можно выполнить альтернативным способом в AlloyDB Studio. Для выполнения команды необходимо открыть веб-консоль вашего кластера AlloyDB, щелкнув по основному экземпляру.

Затем нажмите на AlloyDB Studio слева:

Выберите базу данных quickstart_db, пользователя postgres и введите пароль, указанный при создании кластера. Затем нажмите кнопку «Аутентифицировать».

Откроется интерфейс AlloyDB Studio. Чтобы выполнить команды в базе данных, щелкните вкладку "Редактор 1" справа.

Открывается интерфейс, в котором можно выполнять команды SQL.

Если вы предпочитаете использовать psql из командной строки, то воспользуйтесь альтернативным способом и подключитесь к базе данных из SSH-сессии вашей виртуальной машины, как описано в предыдущих главах.
Выполните поиск сходства из psql
Если соединение с базой данных прервалось, подключитесь к ней снова, используя psql или AlloyDB Studio.
Подключитесь к базе данных:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Выполните запрос, чтобы получить список доступных товаров, наиболее точно соответствующих запросу клиента. Запрос, который мы собираемся передать в Vertex AI для получения векторного значения, звучит примерно так: «Какие фруктовые деревья хорошо растут здесь?»
Вот запрос, который вы можете выполнить, чтобы выбрать первые 10 элементов, наиболее подходящих для нашего запроса:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
А вот ожидаемый результат:
quickstart_db=> SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
product_name | description | sale_price | zip_code | distance
-------------------------+----------------------------------------------------------------------------------+------------+----------+---------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.43922018972266397
Meyer Lemon Tree | Meyer Lemon trees are California's favorite lemon tree! Grow your own lemons by | 34 | 93230 | 0.4685112926118228
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.4835677149651668
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.4947204525907498
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5054166905547247
California Black Walnut | This is a beautiful walnut tree that can grow to be over 80 feet tall. It is a d | 100.00 | 93230 | 0.5084219510932597
California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.5140519790508755
Coast Live Oak | This is a beautiful oak tree that can grow to be over 100 feet tall. It is an ev | 500.00 | 93230 | 0.5143126438081371
Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.5174774727252058
Madrone | This is a beautiful madrona tree that can grow to be over 80 feet tall. It is an | 50.00 | 93230 | 0.5227400803389093
9. Улучшить отклик
Вы можете улучшить ответ клиентскому приложению, используя результат запроса, и подготовить осмысленный вывод, используя предоставленные результаты запроса в качестве части подсказки для языковой модели генеративного фонда Vertex AI.
Для достижения этой цели мы планируем сгенерировать JSON с результатами векторного поиска, а затем использовать этот сгенерированный JSON в качестве дополнения к запросу на текстовую модель LLM в Vertex AI для создания осмысленного выходного результата. На первом этапе мы генерируем JSON, затем тестируем его в Vertex AI Studio, а на последнем этапе включаем его в SQL-запрос, который можно использовать в приложении.
Сгенерировать выходные данные в формате JSON.
Измените запрос так, чтобы он генерировал выходные данные в формате JSON и возвращал только одну строку для передачи в Vertex AI.
Вот пример запроса:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
А вот ожидаемый JSON-код в выходных данных:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Запустите командную строку в Vertex AI Studio.
Мы можем использовать сгенерированный JSON для предоставления его в качестве части текстовой модели подсказки для генеративного ИИ в Vertex AI Studio.
Откройте Vertex AI Studio в облачной консоли.
Возможно, вас попросят согласиться с условиями использования, если вы раньше не пользовались этим сервисом. Нажмите кнопку «Согласиться и продолжить».
Напишите свой запрос в интерфейсе.

Возможно, система запросит включение дополнительных API, но вы можете проигнорировать этот запрос. Нам не нужны дополнительные API для завершения лабораторной работы.
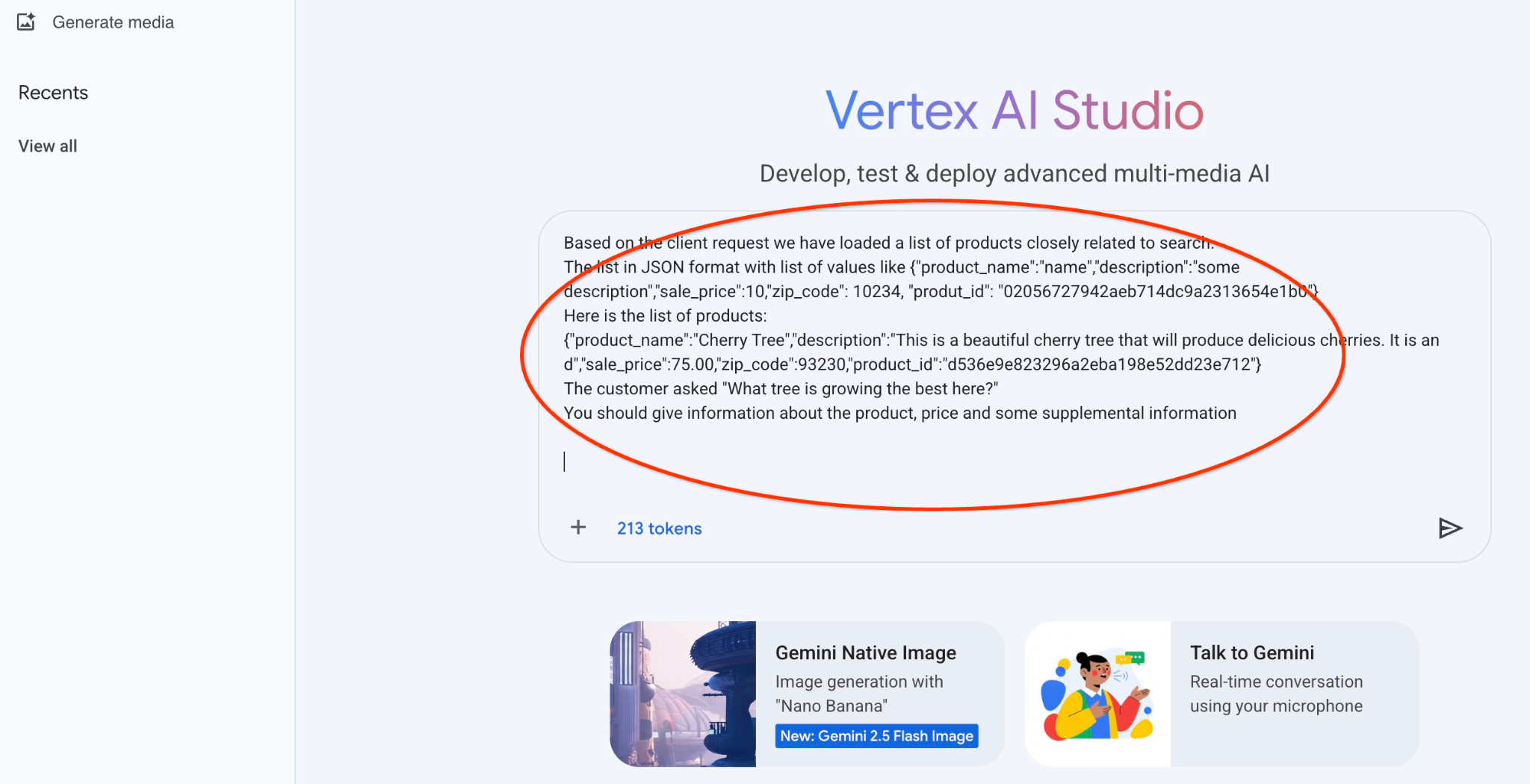
Вот запрос, который мы будем использовать с JSON-выводом из предыдущего запроса о деревьях:
Вы — дружелюбный консультант, помогающий подобрать продукт, соответствующий потребностям клиента.
По просьбе клиента мы загрузили список товаров, тесно связанных с поисковой оптимизацией.
Список в формате JSON, содержащий значения следующего вида: {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Вот список товаров:
{"product_name":"Вишневое дерево","description":"Это красивое вишневое дерево, которое будет давать вкусные вишни. Это","sale_price":75.00","zip_code":93230","product_id":"d536e9e823296a2eba198e52dd23e712"}
Покупатель спросил: «Какое дерево здесь лучше всего растёт?»
Вам следует предоставить информацию о товаре, цене и некоторые дополнительные сведения.
А вот результат, полученный при запуске запроса с нашими JSON-значениями и использованием модели gemini-2.5-flash-light:

Ниже приведён ответ, полученный нами из модели в этом примере. Обратите внимание, что ваш ответ может отличаться из-за изменений модели и параметров с течением времени:
Исходя из имеющегося ассортимента, вот что я могу рассказать вам о "Вишневом дереве":
Продукт: Вишневое дерево
Цена: 75,00 долларов США
Описание: Это прекрасное вишневое дерево, которое будет давать вкусные ягоды.
Чтобы определить, какое дерево «лучше всего растет здесь», мне потребуется дополнительная информация. Есть ли у вас в списке другие деревья, которые мы могли бы сравнить, или вас интересует какой-то конкретный аспект «лучшего роста» (например, самый быстрый рост, наибольшее плодоношение, морозостойкость в вашем климате)?
Запустите командную строку в PSQL.
Мы можем использовать интеграцию AlloyDB AI с Vertex AI, чтобы получить тот же ответ от генеративной модели, используя SQL непосредственно в базе данных. Но для использования модели gemini-1.5-flash нам необходимо сначала ее зарегистрировать.
Проверьте расширение google_ml_integration. Оно должно иметь версию 1.4.2 или новее.
Подключитесь к базе данных quickstart_db из psql , как было показано ранее (или используйте AlloyDB Studio), и выполните следующую команду:
SELECT extversion from pg_extension where extname='google_ml_integration';
Проверьте флаг базы данных google_ml_integration.enable_model_support.
show google_ml_integration.enable_model_support;
Ожидаемый результат работы сессии psql: "on":
postgres=> show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
Если отображается "off", то необходимо установить флаг базы данных google_ml_integration.enable_model_support в значение "on". Для этого можно использовать веб-консоль AlloyDB или выполнить следующую команду gcloud.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags google_ml_integration.enable_faster_embedding_generation=on,google_ml_integration.enable_model_support=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Выполнение команды в фоновом режиме занимает примерно 1-3 минуты. После этого вы можете снова проверить флаг.
Для нашего запроса нам нужны две модели. Первая — это уже используемая модель text-embedding-005 , а вторая — одна из стандартных моделей Google Gemini.
Начнём с модели встраивания текста. Для регистрации модели выполните следующий код в psql или AlloyDB Studio:
CALL
google_ml.create_model(
model_id => 'text-embedding-005',
model_provider => 'google',
model_qualified_name => 'text-embedding-005',
model_type => 'text_embedding',
model_auth_type => 'alloydb_service_agent_iam',
model_in_transform_fn => 'google_ml.vertexai_text_embedding_input_transform',
model_out_transform_fn => 'google_ml.vertexai_text_embedding_output_transform');
Следующая модель, которую нам нужно зарегистрировать, — gemini-2.0-flash-001 , которая будет использоваться для генерации удобного для пользователя вывода.
CALL
google_ml.create_model(
model_id => 'gemini-2.5-flash',
model_request_url => 'publishers/google/models/gemini-2.5-flash:streamGenerateContent',
model_provider => 'google',
model_auth_type => 'alloydb_service_agent_iam');
Вы всегда можете проверить список зарегистрированных моделей, выбрав информацию в представлении google_ml.model_info_view.
select model_id,model_type from google_ml.model_info_view;
Вот пример выходных данных.
quickstart_db=> select model_id,model_type from google_ml.model_info_view;
model_id | model_type
-------------------------+----------------
textembedding-gecko | text_embedding
textembedding-gecko@001 | text_embedding
text-embedding-005 | text_embedding
gemini-2.5-flash | generic
(4 rows)
Теперь мы можем использовать сгенерированный JSON-код в подзапросе, чтобы передать его в качестве части запроса для модели генерации текста с помощью SQL.
В сессии psql или AlloyDB Studio выполните запрос к базе данных.
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005',
'What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1),
prompt AS (
SELECT
'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:' || json_agg(trees) || 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information' AS prompt_text
FROM
trees),
response AS (
SELECT
json_array_elements(google_ml.predict_row( model_id =>'gemini-2.5-flash',
request_body => json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text',
prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT
string_agg(resp::text,
' ')
FROM
response;
Вот ожидаемый результат. Ваш результат может отличаться в зависимости от версии модели и параметров.
"Hello there! I can certainly help you with finding a great fruit tree for your area.\n\nBased on what grows well, we have a wonderful **Cherry Tree** that could be a perfect fit!\n\nThis beautiful cherry tree is an excellent choice for producing delicious cherries right in your garden. It's an deciduous tree that typically" " grows to about 15 feet tall. Beyond its fruit, it offers lovely aesthetics with dark green leaves in the summer that transition to a beautiful red in the fall, making it great for shade and privacy too.\n\nCherry trees generally prefer a cool, moist climate and sandy soil, and they are best suited for USDA Zones" " 4-9. Given the zip code you're inquiring about (93230), which is typically in USDA Zone 9, this Cherry Tree should thrive wonderfully!\n\nYou can get this magnificent tree for just **$75.00**.\n\nLet me know if you have any other questions!" "
10. Создать векторный индекс
Наш набор данных довольно мал, и время отклика в основном зависит от взаимодействия с моделями ИИ. Но когда у вас миллионы векторов, часть, отвечающая за векторный поиск, может занимать значительную часть времени отклика и создавать высокую нагрузку на систему. Чтобы улучшить ситуацию, мы можем построить индекс на основе наших векторов.
Создать индекс ScaNN
Для построения индекса SCANN нам необходимо включить еще одно расширение. Расширение alloydb_scann предоставляет интерфейс для работы с векторным индексом типа ANN, использующим алгоритм Google ScaNN.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Ожидаемый результат:
quickstart_db=> CREATE EXTENSION IF NOT EXISTS alloydb_scann; CREATE EXTENSION Time: 27.468 ms quickstart_db=>
Индекс можно создать в ручном (MANUAL) или автоматическом (AUTO) режиме. Ручной режим включен по умолчанию, и вы можете создать индекс и поддерживать его так же, как и любой другой индекс. Но если вы включите автоматический режим, вы сможете создать индекс, который не потребует от вас никакого обслуживания. Подробно обо всех параметрах можно прочитать в документации , а здесь я покажу, как включить автоматический режим и создать индекс. В нашем случае у нас недостаточно строк для создания индекса в автоматическом режиме, поэтому мы создадим его в ручном режиме.
В следующем примере я оставляю большинство параметров по умолчанию и указываю только количество разделов (num_leaves) для индекса:
CREATE INDEX cymbal_products_embeddings_scann ON cymbal_products
USING scann (embedding cosine)
WITH (num_leaves=31, max_num_levels = 2);
О настройке параметров индекса можно прочитать в документации .
Ожидаемый результат:
quickstart_db=> CREATE INDEX cymbal_products_embeddings_scann ON cymbal_products USING scann (embedding cosine) WITH (num_leaves=31, max_num_levels = 2); CREATE INDEX quickstart_db=>
Сравните ответ
Теперь мы можем выполнить запрос векторного поиска в режиме EXPLAIN и проверить, был ли использован индекс.
EXPLAIN (analyze)
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Ожидаемый результат (отредактировано для ясности):
... Aggregate (cost=16.59..16.60 rows=1 width=32) (actual time=2.875..2.877 rows=1 loops=1) -> Subquery Scan on trees (cost=8.42..16.59 rows=1 width=142) (actual time=2.860..2.862 rows=1 loops=1) -> Limit (cost=8.42..16.58 rows=1 width=158) (actual time=2.855..2.856 rows=1 loops=1) -> Nested Loop (cost=8.42..6489.19 rows=794 width=158) (actual time=2.854..2.855 rows=1 loops=1) -> Nested Loop (cost=8.13..6466.99 rows=794 width=938) (actual time=2.742..2.743 rows=1 loops=1) -> Index Scan using cymbal_products_embeddings_scann on cymbal_products cp (cost=7.71..111.99 rows=876 width=934) (actual time=2.724..2.724 rows=1 loops=1) Order By: (embedding <=> '[0.008864171,0.03693164,-0.024245683,-0.00355923,0.0055611245,0.015985578,...<redacted>...5685,-0.03914233,-0.018452475,0.00826032,-0.07372604]'::vector) -> Index Scan using walmart_inventory_pkey on cymbal_inventory ci (cost=0.42..7.26 rows=1 width=37) (actual time=0.015..0.015 rows=1 loops=1) Index Cond: ((store_id = 1583) AND (uniq_id = (cp.uniq_id)::text)) ...
Из выходных данных ясно видно, что запрос использовал "Index Scan using cymbal_products_embeddings_scann on cymbal_products".
А если мы выполним запрос без оператора explain:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Ожидаемый результат:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Мы видим, что результатом является то же самое вишневое дерево, которое было вверху нашего поиска без индекса. Иногда это может быть не так, и ответ может вернуть не то же самое дерево, а какие-то другие деревья из верхней части списка. Таким образом, индекс обеспечивает производительность, но при этом остается достаточно точным для получения хороших результатов.
Вы можете попробовать различные индексы, доступные для векторов, а также ознакомиться с дополнительными лабораторными работами и примерами интеграции с Langchain на странице документации .
11. Очистка окружающей среды
После завершения лабораторной работы удалите экземпляры AlloyDB и кластер.
Удалите кластер AlloyDB и все его экземпляры.
Если вы использовали пробную версию AlloyDB, не удаляйте пробный кластер, если планируете тестировать другие тестовые среды и ресурсы с его помощью. Вы не сможете создать другой пробный кластер в том же проекте.
Кластер уничтожается с помощью опции force, которая также удаляет все экземпляры, принадлежащие кластеру.
В облачной оболочке укажите переменные проекта и среды на случай, если соединение было разорвано и все предыдущие настройки были потеряны:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Удалите кластер:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Удалить резервные копии AlloyDB
Удалите все резервные копии AlloyDB для кластера:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
Теперь мы можем уничтожить нашу виртуальную машину.
Удалить виртуальную машину GCE
В оболочке Cloud Shell выполните:
export GCEVM=instance-1
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Ожидаемый вывод в консоль:
student@cloudshell:~ (test-project-001-402417)$ export GCEVM=instance-1
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Deleted
12. Поздравляем!
Поздравляем с завершением практического занятия!
Данная лабораторная работа является частью учебного курса "Готовый к внедрению ИИ в производство с использованием Google Cloud".
- Изучите полный учебный план , чтобы преодолеть разрыв между прототипом и серийным производством.
- Делитесь своими успехами, используя хэштег
#ProductionReadyAI.
Что мы рассмотрели
- Как развернуть кластер AlloyDB и основной экземпляр
- Как подключиться к AlloyDB из виртуальной машины Google Compute Engine
- Как создать базу данных и включить AlloyDB AI
- Как загрузить данные в базу данных
- Как использовать AlloyDB Studio
- Как использовать модель встраивания Vertex AI в AlloyDB
- Как использовать Vertex AI Studio
- Как улучшить результаты, используя генеративную модель Vertex AI
- Как повысить производительность с помощью векторного индекса
13. Опрос
Выход: