
1. ভূমিকা
এই কোডল্যাবে আপনি শিখবেন কিভাবে ভেক্টর সার্চ এবং ভার্টেক্স এআই এম্বেডিং একত্রিত করে অ্যালয়ডিবি এআই ব্যবহার করতে হয়। এই ল্যাবটি অ্যালয়ডিবি এআই বৈশিষ্ট্যগুলির জন্য নিবেদিত একটি ল্যাব সংগ্রহের অংশ। আপনি ডকুমেন্টেশনে অ্যালয়ডিবি এআই পৃষ্ঠায় আরও পড়তে পারেন।

পূর্বশর্ত
- গুগল ক্লাউড, কনসোল সম্পর্কে প্রাথমিক ধারণা
- কমান্ড লাইন ইন্টারফেস এবং গুগল শেলের মৌলিক দক্ষতা
তুমি কি শিখবে
- AlloyDB ক্লাস্টার এবং প্রাথমিক উদাহরণ কীভাবে স্থাপন করবেন
- গুগল কম্পিউট ইঞ্জিন ভিএম থেকে অ্যালয়ডিবিতে কীভাবে সংযোগ করবেন
- কিভাবে ডাটাবেস তৈরি করবেন এবং AlloyDB AI সক্রিয় করবেন
- ডাটাবেসে ডেটা কীভাবে লোড করবেন
- AlloyDB স্টুডিও কীভাবে ব্যবহার করবেন
- AlloyDB-তে Vertex AI এমবেডিং মডেল কীভাবে ব্যবহার করবেন
- ভার্টেক্স এআই স্টুডিও কীভাবে ব্যবহার করবেন
- ভার্টেক্স এআই জেনারেটিভ মডেল ব্যবহার করে ফলাফল কীভাবে সমৃদ্ধ করা যায়
- ভেক্টর সূচক ব্যবহার করে কর্মক্ষমতা কীভাবে উন্নত করা যায়
তোমার যা লাগবে
- একটি গুগল ক্লাউড অ্যাকাউন্ট এবং গুগল ক্লাউড প্রকল্প
- ক্রোমের মতো একটি ওয়েব ব্রাউজার
2. সেটআপ এবং প্রয়োজনীয়তা
প্রকল্প সেটআপ
- গুগল ক্লাউড কনসোলে সাইন-ইন করুন। যদি আপনার ইতিমধ্যেই একটি জিমেইল বা গুগল ওয়ার্কস্পেস অ্যাকাউন্ট না থাকে, তাহলে আপনাকে অবশ্যই একটি তৈরি করতে হবে।
কর্মক্ষেত্র বা স্কুল অ্যাকাউন্টের পরিবর্তে ব্যক্তিগত অ্যাকাউন্ট ব্যবহার করুন।
- একটি নতুন প্রকল্প তৈরি করুন অথবা বিদ্যমান একটি পুনরায় ব্যবহার করুন। গুগল ক্লাউড কনসোলে একটি নতুন প্রকল্প তৈরি করতে, হেডারে, একটি প্রকল্প নির্বাচন করুন বোতামে ক্লিক করুন যা একটি পপআপ উইন্ডো খুলবে।

"একটি প্রকল্প নির্বাচন করুন" উইন্ডোতে "নতুন প্রকল্প" বোতামটি টিপুন যা নতুন প্রকল্পের জন্য একটি ডায়ালগ বক্স খুলবে।
ডায়ালগ বক্সে আপনার পছন্দের প্রকল্পের নাম লিখুন এবং অবস্থানটি নির্বাচন করুন।
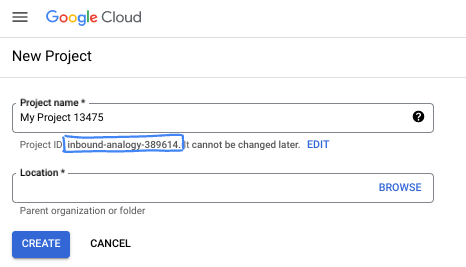
- এই প্রকল্পের অংশগ্রহণকারীদের জন্য প্রজেক্টের নামটি প্রদর্শন করা হবে। প্রোজেক্টের নামটি গুগল এপিআই দ্বারা ব্যবহৃত হয় না এবং এটি যেকোনো সময় পরিবর্তন করা যেতে পারে।
- সমস্ত Google ক্লাউড প্রোজেক্টে প্রোজেক্ট আইডি অনন্য এবং অপরিবর্তনীয় (সেট করার পরে এটি পরিবর্তন করা যাবে না)। Google ক্লাউড কনসোল স্বয়ংক্রিয়ভাবে একটি অনন্য আইডি তৈরি করে, তবে আপনি এটি কাস্টমাইজ করতে পারেন। যদি আপনি জেনারেট করা আইডি পছন্দ না করেন, তাহলে আপনি অন্য একটি র্যান্ডম আইডি তৈরি করতে পারেন অথবা এর উপলব্ধতা পরীক্ষা করার জন্য আপনার নিজস্ব আইডি প্রদান করতে পারেন। বেশিরভাগ কোডল্যাবে, আপনাকে আপনার প্রোজেক্ট আইডি উল্লেখ করতে হবে, যা সাধারণত PROJECT_ID প্লেসহোল্ডার দিয়ে চিহ্নিত করা হয়।
- আপনার তথ্যের জন্য, তৃতীয় একটি মান আছে, একটি Project Number , যা কিছু API ব্যবহার করে। ডকুমেন্টেশনে এই তিনটি মান সম্পর্কে আরও জানুন।
বিলিং সক্ষম করুন
বিলিং সক্ষম করার জন্য, আপনার কাছে দুটি বিকল্প আছে। আপনি হয় আপনার ব্যক্তিগত বিলিং অ্যাকাউন্ট ব্যবহার করতে পারেন অথবা নিম্নলিখিত পদক্ষেপগুলি অনুসরণ করে ক্রেডিট রিডিম করতে পারেন।
$৫ গুগল ক্লাউড ক্রেডিট রিডিম করুন (ঐচ্ছিক)
এই কর্মশালাটি পরিচালনা করার জন্য, আপনার কিছু ক্রেডিট সহ একটি বিলিং অ্যাকাউন্ট প্রয়োজন। আপনি যদি নিজের বিলিং ব্যবহার করার পরিকল্পনা করেন, তাহলে আপনি এই ধাপটি এড়িয়ে যেতে পারেন।
- এই লিঙ্কে ক্লিক করুন এবং একটি ব্যক্তিগত গুগল অ্যাকাউন্ট দিয়ে সাইন ইন করুন।
- তুমি এরকম কিছু দেখতে পাবে:

- আপনার ক্রেডিট অ্যাক্সেস করতে এখানে ক্লিক করুন বোতামটি ক্লিক করুন। এটি আপনাকে আপনার বিলিং প্রোফাইল সেট আপ করার জন্য একটি পৃষ্ঠায় নিয়ে যাবে। যদি আপনাকে একটি বিনামূল্যে ট্রায়াল সাইন আপ স্ক্রিন দেখানো হয়, তাহলে বাতিল করুন ক্লিক করুন এবং বিলিং লিঙ্ক করতে থাকুন।

- আপনি এখন একটি Google Cloud Platform ট্রায়াল বিলিং অ্যাকাউন্টের সাথে সংযুক্ত আছেন কিনা তা নিশ্চিত করুন-এ ক্লিক করুন।

একটি ব্যক্তিগত বিলিং অ্যাকাউন্ট সেট আপ করুন
আপনি যদি গুগল ক্লাউড ক্রেডিট ব্যবহার করে বিলিং সেট আপ করেন, তাহলে আপনি এই ধাপটি এড়িয়ে যেতে পারেন।
একটি ব্যক্তিগত বিলিং অ্যাকাউন্ট সেট আপ করতে, ক্লাউড কনসোলে বিলিং সক্ষম করতে এখানে যান ।
কিছু নোট:
- এই ল্যাবটি সম্পূর্ণ করতে ক্লাউড রিসোর্সে $3 USD এর কম খরচ হবে।
- আরও চার্জ এড়াতে আপনি এই ল্যাবের শেষে রিসোর্স মুছে ফেলার ধাপগুলি অনুসরণ করতে পারেন।
- নতুন ব্যবহারকারীরা $300 USD বিনামূল্যে ট্রায়ালের জন্য যোগ্য।
ক্লাউড শেল শুরু করুন
যদিও গুগল ক্লাউড আপনার ল্যাপটপ থেকে দূরবর্তীভাবে পরিচালিত হতে পারে, এই কোডল্যাবে আপনি গুগল ক্লাউড শেল ব্যবহার করবেন, যা ক্লাউডে চলমান একটি কমান্ড লাইন পরিবেশ।
গুগল ক্লাউড কনসোল থেকে, উপরের ডানদিকের টুলবারে ক্লাউড শেল আইকনে ক্লিক করুন:
অথবা আপনি G তারপর S টিপতে পারেন। আপনি যদি Google Cloud Console-এর মধ্যে থাকেন অথবা এই লিঙ্কটি ব্যবহার করেন তবে এই ক্রমটি Cloud Shell সক্রিয় করবে।
পরিবেশের সাথে সংযোগ স্থাপন এবং সংযোগ স্থাপন করতে মাত্র কয়েক মুহূর্ত সময় লাগবে। এটি সম্পন্ন হলে, আপনি এরকম কিছু দেখতে পাবেন:

এই ভার্চুয়াল মেশিনটিতে আপনার প্রয়োজনীয় সকল ডেভেলপমেন্ট টুল রয়েছে। এটি একটি স্থায়ী ৫ জিবি হোম ডিরেক্টরি অফার করে এবং গুগল ক্লাউডে চলে, যা নেটওয়ার্ক কর্মক্ষমতা এবং প্রমাণীকরণকে ব্যাপকভাবে উন্নত করে। এই কোডল্যাবে আপনার সমস্ত কাজ একটি ব্রাউজারেই করা যেতে পারে। আপনাকে কিছু ইনস্টল করার প্রয়োজন নেই।
৩. শুরু করার আগে
API সক্ষম করুন
আউটপুট:
AlloyDB , Compute Engine , Networking পরিষেবা এবং Vertex AI ব্যবহার করার জন্য, আপনার Google Cloud Project-এ তাদের নিজ নিজ API গুলি সক্ষম করতে হবে।
API গুলি সক্রিয় করা হচ্ছে
টার্মিনালে ক্লাউড শেলের ভিতরে, নিশ্চিত করুন যে আপনার প্রোজেক্ট আইডি সেটআপ করা আছে:
gcloud config set project [YOUR-PROJECT-ID]
পরিবেশ পরিবর্তনশীল PROJECT_ID সেট করুন:
PROJECT_ID=$(gcloud config get-value project)
সমস্ত প্রয়োজনীয় API সক্রিয় করুন:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
প্রত্যাশিত আউটপুট
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
API গুলির সাথে পরিচয় করিয়ে দেওয়া হচ্ছে
- AlloyDB API (
alloydb.googleapis.com) আপনাকে PostgreSQL ক্লাস্টারের জন্য AlloyDB তৈরি, পরিচালনা এবং স্কেল করার অনুমতি দেয়। এটি একটি সম্পূর্ণরূপে পরিচালিত, PostgreSQL-সামঞ্জস্যপূর্ণ ডাটাবেস পরিষেবা প্রদান করে যা এন্টারপ্রাইজ লেনদেন এবং বিশ্লেষণাত্মক কাজের চাপের জন্য ডিজাইন করা হয়েছে। - কম্পিউট ইঞ্জিন API (
compute.googleapis.com) আপনাকে ভার্চুয়াল মেশিন (VM), স্থায়ী ডিস্ক এবং নেটওয়ার্ক সেটিংস তৈরি এবং পরিচালনা করতে দেয়। এটি আপনার কাজের চাপ চালানোর জন্য এবং অনেক পরিচালিত পরিষেবার জন্য অন্তর্নিহিত অবকাঠামো হোস্ট করার জন্য প্রয়োজনীয় মূল অবকাঠামো-অ্যাজ-এ-সার্ভিস (IaaS) ভিত্তি প্রদান করে। - ক্লাউড রিসোর্স ম্যানেজার API (
cloudresourcemanager.googleapis.com) আপনাকে আপনার গুগল ক্লাউড প্রকল্পের মেটাডেটা এবং কনফিগারেশন প্রোগ্রাম্যাটিকভাবে পরিচালনা করতে দেয়। এটি আপনাকে সংস্থানগুলি সংগঠিত করতে, পরিচয় এবং অ্যাক্সেস ম্যানেজমেন্ট (IAM) নীতিগুলি পরিচালনা করতে এবং প্রকল্পের শ্রেণিবিন্যাস জুড়ে অনুমতিগুলি যাচাই করতে সক্ষম করে। - সার্ভিস নেটওয়ার্কিং API (
servicenetworking.googleapis.com) আপনাকে আপনার ভার্চুয়াল প্রাইভেট ক্লাউড (VPC) নেটওয়ার্ক এবং গুগলের পরিচালিত পরিষেবাগুলির মধ্যে ব্যক্তিগত সংযোগের সেটআপ স্বয়ংক্রিয় করতে দেয়। AlloyDB এর মতো পরিষেবাগুলির জন্য ব্যক্তিগত IP অ্যাক্সেস স্থাপন করা বিশেষভাবে প্রয়োজন যাতে তারা আপনার অন্যান্য সংস্থানগুলির সাথে নিরাপদে যোগাযোগ করতে পারে। - Vertex AI API (
aiplatform.googleapis.com) আপনার অ্যাপ্লিকেশনগুলিকে মেশিন লার্নিং মডেল তৈরি, স্থাপন এবং স্কেল করতে সক্ষম করে। এটি Google ক্লাউডের সমস্ত AI পরিষেবার জন্য একীভূত ইন্টারফেস প্রদান করে, যার মধ্যে রয়েছে জেনারেটিভ AI মডেলগুলিতে অ্যাক্সেস (যেমন জেমিনি) এবং কাস্টম মডেল প্রশিক্ষণ।
ঐচ্ছিকভাবে, আপনি Vertex AI এম্বেডিং মডেলগুলি ব্যবহার করার জন্য আপনার ডিফল্ট অঞ্চলটি কনফিগার করতে পারেন। Vertex AI এর জন্য উপলব্ধ অবস্থানগুলি সম্পর্কে আরও পড়ুন। উদাহরণে আমরা us-central1 অঞ্চলটি ব্যবহার করছি।
gcloud config set compute/region us-central1
৪. অ্যালয়ডিবি স্থাপন করুন
AlloyDB ক্লাস্টার তৈরি করার আগে আমাদের VPC-তে একটি প্রাইভেট IP রেঞ্জ থাকা দরকার যা ভবিষ্যতের AlloyDB ইনস্ট্যান্স ব্যবহার করবে। যদি আমাদের কাছে এটি না থাকে তবে আমাদের এটি তৈরি করতে হবে, এটি অভ্যন্তরীণ Google পরিষেবাগুলির দ্বারা ব্যবহারের জন্য বরাদ্দ করতে হবে এবং তারপরে আমরা ক্লাস্টার এবং ইনস্ট্যান্স তৈরি করতে সক্ষম হব।
ব্যক্তিগত আইপি পরিসর তৈরি করুন
AlloyDB-এর জন্য আমাদের VPC-তে Private Service Access কনফিগারেশন কনফিগার করতে হবে। এখানে ধরে নেওয়া হচ্ছে যে আমাদের প্রকল্পে "ডিফল্ট" VPC নেটওয়ার্ক রয়েছে এবং এটি সমস্ত কাজের জন্য ব্যবহার করা হবে।
ব্যক্তিগত আইপি পরিসর তৈরি করুন:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
বরাদ্দকৃত আইপি পরিসর ব্যবহার করে ব্যক্তিগত সংযোগ তৈরি করুন:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
প্রত্যাশিত কনসোল আউটপুট:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
AlloyDB ক্লাস্টার তৈরি করুন
এই বিভাগে আমরা us-central1 অঞ্চলে একটি AlloyDB ক্লাস্টার তৈরি করছি।
পোস্টগ্রেস ব্যবহারকারীর জন্য পাসওয়ার্ড নির্ধারণ করুন। আপনি নিজের পাসওয়ার্ড নির্ধারণ করতে পারেন অথবা একটি র্যান্ডম ফাংশন ব্যবহার করে একটি তৈরি করতে পারেন।
export PGPASSWORD=`openssl rand -hex 12`
প্রত্যাশিত কনসোল আউটপুট:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
ভবিষ্যতে ব্যবহারের জন্য PostgreSQL পাসওয়ার্ডটি নোট করুন।
echo $PGPASSWORD
পোস্টগ্রেস ব্যবহারকারী হিসেবে ইনস্ট্যান্সের সাথে সংযোগ স্থাপনের জন্য ভবিষ্যতে আপনার সেই পাসওয়ার্ডটির প্রয়োজন হবে। আমি এটি লিখে রাখার বা কোথাও কপি করার পরামর্শ দিচ্ছি যাতে পরে ব্যবহার করা যায়।
প্রত্যাশিত কনসোল আউটপুট:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723
একটি বিনামূল্যের ট্রায়াল ক্লাস্টার তৈরি করুন
যদি আপনি আগে AlloyDB ব্যবহার না করে থাকেন, তাহলে একটি বিনামূল্যের ট্রায়াল ক্লাস্টার তৈরি করতে পারেন:
অঞ্চল এবং AlloyDB ক্লাস্টারের নাম নির্ধারণ করুন। আমরা us-central1 region এবং alloydb-aip-01 কে ক্লাস্টারের নাম হিসেবে ব্যবহার করব:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
ক্লাস্টার তৈরি করতে কমান্ড চালান:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
প্রত্যাশিত কনসোল আউটপুট:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
একই ক্লাউড শেল সেশনে আমাদের ক্লাস্টারের জন্য একটি AlloyDB প্রাথমিক উদাহরণ তৈরি করুন। যদি আপনার সংযোগ বিচ্ছিন্ন থাকে তবে আপনাকে আবার অঞ্চল এবং ক্লাস্টারের নাম পরিবেশ ভেরিয়েবল সংজ্ঞায়িত করতে হবে।
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
প্রত্যাশিত কনসোল আউটপুট:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
AlloyDB স্ট্যান্ডার্ড ক্লাস্টার তৈরি করুন
যদি এটি প্রকল্পে আপনার প্রথম AlloyDB ক্লাস্টার না হয়, তাহলে একটি স্ট্যান্ডার্ড ক্লাস্টার তৈরির সাথে এগিয়ে যান।
অঞ্চল এবং AlloyDB ক্লাস্টারের নাম নির্ধারণ করুন। আমরা us-central1 region এবং alloydb-aip-01 কে ক্লাস্টারের নাম হিসেবে ব্যবহার করব:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
ক্লাস্টার তৈরি করতে কমান্ড চালান:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
প্রত্যাশিত কনসোল আউটপুট:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
একই ক্লাউড শেল সেশনে আমাদের ক্লাস্টারের জন্য একটি AlloyDB প্রাথমিক উদাহরণ তৈরি করুন। যদি আপনার সংযোগ বিচ্ছিন্ন থাকে তবে আপনাকে আবার অঞ্চল এবং ক্লাস্টারের নাম পরিবেশ ভেরিয়েবল সংজ্ঞায়িত করতে হবে।
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
প্রত্যাশিত কনসোল আউটপুট:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
৫. AlloyDB এর সাথে সংযোগ করুন
AlloyDB একটি প্রাইভেট-ওনলি সংযোগ ব্যবহার করে স্থাপন করা হয়েছে, তাই ডাটাবেসের সাথে কাজ করার জন্য আমাদের PostgreSQL ক্লায়েন্ট সহ একটি VM ইনস্টল করা প্রয়োজন।
GCE VM স্থাপন করুন
AlloyDB ক্লাস্টারের মতো একই অঞ্চলে এবং VPC-তে একটি GCE VM তৈরি করুন।
ক্লাউড শেলে কার্যকর করুন:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE \
--create-disk=auto-delete=yes,boot=yes,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" --format="value(name)") \
--scopes=https://www.googleapis.com/auth/cloud-platform
প্রত্যাশিত কনসোল আউটপুট:
student@cloudshell:~ (test-project-402417)$ export ZONE=us-central1-a
student@cloudshell:~ (test-project-402417)$ export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE \
--create-disk=auto-delete=yes,boot=yes,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" --format="value(name)") \
--scopes=https://www.googleapis.com/auth/cloud-platform
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/zones/us-central1-a/instances/instance-1].
NAME: instance-1
ZONE: us-central1-a
MACHINE_TYPE: n1-standard-1
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.2
EXTERNAL_IP: 34.71.192.233
STATUS: RUNNING
পোস্টগ্রেস ক্লায়েন্ট ইনস্টল করুন
স্থাপন করা VM-এ PostgreSQL ক্লায়েন্ট সফ্টওয়্যার ইনস্টল করুন
VM-এর সাথে সংযোগ করুন:
gcloud compute ssh instance-1 --zone=us-central1-a
প্রত্যাশিত কনসোল আউটপুট:
student@cloudshell:~ (test-project-402417)$ gcloud compute ssh instance-1 --zone=us-central1-a Updating project ssh metadata...working..Updated [https://www.googleapis.com/compute/v1/projects/test-project-402417]. Updating project ssh metadata...done. Waiting for SSH key to propagate. Warning: Permanently added 'compute.5110295539541121102' (ECDSA) to the list of known hosts. Linux instance-1.us-central1-a.c.gleb-test-short-001-418811.internal 6.1.0-18-cloud-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.76-1 (2024-02-01) x86_64 The programs included with the Debian GNU/Linux system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. student@instance-1:~$
VM-এর ভিতরে সফটওয়্যার রানিং কমান্ডটি ইনস্টল করুন:
sudo apt-get update
sudo apt-get install --yes postgresql-client
প্রত্যাশিত কনসোল আউটপুট:
student@instance-1:~$ sudo apt-get update sudo apt-get install --yes postgresql-client Get:1 https://packages.cloud.google.com/apt google-compute-engine-bullseye-stable InRelease [5146 B] Get:2 https://packages.cloud.google.com/apt cloud-sdk-bullseye InRelease [6406 B] Hit:3 https://deb.debian.org/debian bullseye InRelease Get:4 https://deb.debian.org/debian-security bullseye-security InRelease [48.4 kB] Get:5 https://packages.cloud.google.com/apt google-compute-engine-bullseye-stable/main amd64 Packages [1930 B] Get:6 https://deb.debian.org/debian bullseye-updates InRelease [44.1 kB] Get:7 https://deb.debian.org/debian bullseye-backports InRelease [49.0 kB] ...redacted... update-alternatives: using /usr/share/postgresql/13/man/man1/psql.1.gz to provide /usr/share/man/man1/psql.1.gz (psql.1.gz) in auto mode Setting up postgresql-client (13+225) ... Processing triggers for man-db (2.9.4-2) ... Processing triggers for libc-bin (2.31-13+deb11u7) ...
ইনস্ট্যান্সের সাথে সংযোগ করুন
psql ব্যবহার করে VM থেকে প্রাথমিক ইনস্ট্যান্সের সাথে সংযোগ করুন।
আপনার ইনস্ট্যান্স-১ ভিএম-এ খোলা SSH সেশনের সাথে একই ক্লাউড শেল ট্যাবে।
GCE VM থেকে AlloyDB-তে সংযোগ করতে উল্লেখিত AlloyDB পাসওয়ার্ড (PGPASSWORD) মান এবং AlloyDB ক্লাস্টার আইডি ব্যবহার করুন:
export PGPASSWORD=<Noted password>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export INSTANCE_IP=$(gcloud alloydb instances describe $ADBCLUSTER-pr --cluster=$ADBCLUSTER --region=$REGION --format="value(ipAddress)")
psql "host=$INSTANCE_IP user=postgres sslmode=require"
প্রত্যাশিত কনসোল আউটপুট:
student@instance-1:~$ export PGPASSWORD=CQhOi5OygD4ps6ty student@instance-1:~$ ADBCLUSTER=alloydb-aip-01 student@instance-1:~$ REGION=us-central1 student@instance-1:~$ INSTANCE_IP=$(gcloud alloydb instances describe $ADBCLUSTER-pr --cluster=$ADBCLUSTER --region=$REGION --format="value(ipAddress)") gleb@instance-1:~$ psql "host=$INSTANCE_IP user=postgres sslmode=require" psql (15.6 (Debian 15.6-0+deb12u1), server 15.5) SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off) Type "help" for help. postgres=>
পিএসকিউএল সেশন বন্ধ করুন:
exit
৬. ডাটাবেস প্রস্তুত করুন
আমাদের একটি ডাটাবেস তৈরি করতে হবে, ভার্টেক্স এআই ইন্টিগ্রেশন সক্ষম করতে হবে, ডাটাবেস অবজেক্ট তৈরি করতে হবে এবং ডেটা আমদানি করতে হবে।
AlloyDB-কে প্রয়োজনীয় অনুমতি প্রদান করুন
AlloyDB পরিষেবা এজেন্টে Vertex AI অনুমতি যোগ করুন।
উপরে "+" চিহ্ন ব্যবহার করে আরেকটি ক্লাউড শেল ট্যাব খুলুন।
নতুন ক্লাউড শেল ট্যাবে এক্সিকিউট করুন:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
প্রত্যাশিত কনসোল আউটপুট:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
ট্যাবে "exit" এক্সিকিউশন কমান্ডের মাধ্যমে ট্যাবটি বন্ধ করুন:
exit
ডাটাবেস তৈরি করুন
ডাটাবেস কুইকস্টার্ট তৈরি করুন।
GCE VM সেশনে এক্সিকিউট করুন:
ডাটাবেস তৈরি করুন:
psql "host=$INSTANCE_IP user=postgres" -c "CREATE DATABASE quickstart_db"
প্রত্যাশিত কনসোল আউটপুট:
student@instance-1:~$ psql "host=$INSTANCE_IP user=postgres" -c "CREATE DATABASE quickstart_db" CREATE DATABASE student@instance-1:~$
ভার্টেক্স এআই ইন্টিগ্রেশন সক্ষম করুন
ডাটাবেসে Vertex AI ইন্টিগ্রেশন এবং pgvector এক্সটেনশন সক্রিয় করুন।
GCE VM-এ এক্সিকিউট করুন:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE"
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS vector"
প্রত্যাশিত কনসোল আউটপুট:
student@instance-1:~$ psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE" psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS vector" CREATE EXTENSION CREATE EXTENSION student@instance-1:~$
ডেটা আমদানি করুন
প্রস্তুতকৃত তথ্য ডাউনলোড করুন এবং নতুন ডাটাবেসে আমদানি করুন।
GCE VM-এ এক্সিকিউট করুন:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_products from stdin csv header"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_inventory from stdin csv header"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_stores from stdin csv header"
প্রত্যাশিত কনসোল আউটপুট:
student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_products from stdin csv header" COPY 941 student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_inventory from stdin csv header" COPY 263861 student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_stores from stdin csv header" COPY 4654 student@instance-1:~$
৭. এম্বেডিং গণনা করুন
ডেটা আমদানি করার পর আমরা cymbal_products টেবিলে আমাদের পণ্যের ডেটা পেয়েছি, cymbal_inventory টেবিলে প্রতিটি দোকানে উপলব্ধ পণ্যের সংখ্যা দেখানো ইনভেন্টরি এবং cymbal_stores টেবিলে স্টোরের তালিকা। আমাদের পণ্যের বর্ণনার উপর ভিত্তি করে ভেক্টর ডেটা গণনা করতে হবে এবং আমরা এর জন্য ফাংশন এম্বেডিং ব্যবহার করতে যাচ্ছি। ফাংশনটি ব্যবহার করে আমরা Vertex AI ইন্টিগ্রেশন ব্যবহার করে আমাদের পণ্যের বর্ণনার উপর ভিত্তি করে ভেক্টর ডেটা গণনা করব এবং এটি টেবিলে যুক্ত করব। ব্যবহৃত প্রযুক্তি সম্পর্কে আরও তথ্য ডকুমেন্টেশনে পড়তে পারেন।
কয়েকটি সারির জন্য এটি তৈরি করা সহজ কিন্তু হাজার হাজার থাকলে কীভাবে এটি কার্যকর করা যায়? এখানে আমি দেখাবো কিভাবে বড় টেবিলের জন্য এম্বেডিং তৈরি এবং পরিচালনা করতে হয়। আপনি গাইডে বিভিন্ন বিকল্প এবং কৌশল সম্পর্কে আরও পড়তে পারেন।
দ্রুত এম্বেডিং জেনারেশন সক্ষম করুন
AlloyDB ইনস্ট্যান্স আইপি এবং পোস্টগ্রেস পাসওয়ার্ড ব্যবহার করে আপনার VM থেকে psql ব্যবহার করে ডাটাবেসের সাথে সংযোগ করুন:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
google_ml_integration এক্সটেনশনের সংস্করণ যাচাই করুন।
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
ভার্সনটি ১.৫.২ বা তার বেশি হওয়া উচিত। আউটপুটের উদাহরণ এখানে দেওয়া হল:
quickstart_db=> SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration'; extversion ------------ 1.5.2 (1 row)
ডিফল্ট ভার্সনটি ১.৫.২ বা তার বেশি হওয়া উচিত, কিন্তু যদি আপনার ইনস্ট্যান্সে পুরনো ভার্সন দেখায়, তাহলে সম্ভবত এটি আপডেট করার প্রয়োজন। ইনস্ট্যান্সের জন্য রক্ষণাবেক্ষণ অক্ষম করা আছে কিনা তা পরীক্ষা করুন।
তারপর আমাদের ডাটাবেস ফ্ল্যাগটি যাচাই করতে হবে। আমাদের google_ml_integration.enable_faster_embedding_generation ফ্ল্যাগটি চালু করতে হবে। একই psql সেশনে ফ্ল্যাগটির মান পরীক্ষা করুন।
show google_ml_integration.enable_faster_embedding_generation;
যদি পতাকাটি সঠিক অবস্থানে থাকে তাহলে প্রত্যাশিত আউটপুটটি এরকম দেখাবে:
quickstart_db=> show google_ml_integration.enable_faster_embedding_generation; google_ml_integration.enable_faster_embedding_generation ---------------------------------------------------------- on (1 row)
কিন্তু যদি এটি "off" দেখায় তাহলে আমাদের ইনস্ট্যান্সটি আপডেট করতে হবে। আপনি ওয়েব কনসোল অথবা gcloud কমান্ড ব্যবহার করে এটি করতে পারেন যেমনটি ডকুমেন্টেশনে বর্ণিত আছে। এখানে আমি gcloud কমান্ড ব্যবহার করে এটি কীভাবে করবেন তা দেখাবো:
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags google_ml_integration.enable_faster_embedding_generation=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
এটি কয়েক মিনিট সময় নিতে পারে কিন্তু অবশেষে পতাকা মান "চালু" করা উচিত। এর পরে আপনি পরবর্তী পদক্ষেপগুলি নিয়ে এগিয়ে যেতে পারেন।
এম্বেডিং কলাম তৈরি করুন
psql ব্যবহার করে ডাটাবেসের সাথে সংযোগ স্থাপন করুন এবং cymbal_products টেবিলে এম্বেডিং ফাংশন ব্যবহার করে ভেক্টর ডেটা দিয়ে একটি ভার্চুয়াল কলাম তৈরি করুন। এম্বেডিং ফাংশনটি product_description কলাম থেকে সরবরাহিত ডেটার উপর ভিত্তি করে Vertex AI থেকে ভেক্টর ডেটা ফেরত দেয়।
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
ডাটাবেসের সাথে সংযোগ স্থাপনের পর psql সেশনে এক্সিকিউট করুন:
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768);
কমান্ডটি ভার্চুয়াল কলাম তৈরি করবে এবং ভেক্টর ডেটা দিয়ে এটি পূরণ করবে।
প্রত্যাশিত কনসোল আউটপুট:
quickstart_db=> ALTER TABLE cymbal_products ADD COLUMN embedding vector(768); ALTER TABLE quickstart_db=>
এখন আমরা ৫০টি করে সারি বিশিষ্ট ব্যাচ ব্যবহার করে এম্বেডিং তৈরি করতে পারি। আপনি বিভিন্ন ব্যাচের আকার নিয়ে পরীক্ষা-নিরীক্ষা করতে পারেন এবং দেখতে পারেন যে এটি কার্যকর করার সময় পরিবর্তন করে কিনা। একই psql সেশনে কার্যকর করুন:
কত সময় লাগবে তা পরিমাপ করার জন্য সময় সক্ষম করুন:
\timing
কমান্ডটি চালান:
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'embedding',
batch_size => 50
);
এবং এম্বেডিং জেনারেশনের জন্য কনসোল আউটপুট 2 সেকেন্ডেরও কম সময় দেখানো হয়েছে:
quickstart_db=> CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'embedding',
batch_size => 50
);
NOTICE: Initialize embedding completed successfully for table cymbal_products
CALL
Time: 1458.704 ms (00:01.459)
quickstart_db=>
ডিফল্টরূপে, যদি সংশ্লিষ্ট product_description কলামটি আপডেট করা হয় অথবা একটি সম্পূর্ণ নতুন সারি সন্নিবেশ করা হয়, তাহলে এম্বেডিংগুলি রিফ্রেশ হবে না। তবে আপনি incremental_refresh_mode প্যারামিটার সংজ্ঞায়িত করে এটি করতে পারেন। আসুন " product_embeddings " নামে একটি কলাম তৈরি করি এবং এটি স্বয়ংক্রিয়ভাবে আপডেটযোগ্য করে তুলি।
ALTER TABLE cymbal_products ADD COLUMN product_embedding vector(768);
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'product_embedding',
batch_size => 50,
incremental_refresh_mode => 'transactional'
);
আর এখন যদি আমরা টেবিলে একটি নতুন সারি সন্নিবেশ করি।
INSERT INTO "cymbal_products" ("uniq_id", "crawl_timestamp", "product_url", "product_name", "product_description", "list_price", "sale_price", "brand", "item_number", "gtin", "package_size", "category", "postal_code", "available", "product_embedding", "embedding") VALUES ('fd604542e04b470f9e6348e640cff794', NOW(), 'https://example.com/new_product', 'New Cymbal Product', 'This is a new cymbal product description.', 199.99, 149.99, 'Example Brand', 'EB123', '1234567890', 'Single', 'Cymbals', '12345', TRUE, NULL, NULL);
আমরা কোয়েরি ব্যবহার করে কলামের পার্থক্য তুলনা করতে পারি:
SELECT uniq_id,embedding, (product_embedding::real[])[1:5] as product_embedding FROM cymbal_products WHERE uniq_id='fd604542e04b470f9e6348e640cff794';
এবং আউটপুটে আমরা দেখতে পাচ্ছি যে এম্বেডিং কলামটি খালি থাকাকালীন product_embedding কলামটি স্বয়ংক্রিয়ভাবে আপডেট হয়।
quickstart_db=> SELECT uniq_id,embedding, (product_embedding::real[])[1:5] as product_embedding FROM cymbal_products WHERE uniq_id='fd604542e04b470f9e6348e640cff794';
uniq_id | embedding | product_embedding
----------------------------------+-----------+---------------------------------------------------------------
fd604542e04b470f9e6348e640cff794 | | {0.015003494,-0.005349732,-0.059790313,-0.0087091,-0.0271452}
(1 row)
Time: 3.295 ms
৮. সাদৃশ্য অনুসন্ধান চালান
আমরা এখন বর্ণনার জন্য গণনা করা ভেক্টর মানের উপর ভিত্তি করে এবং আমাদের অনুরোধের জন্য প্রাপ্ত ভেক্টর মানের উপর ভিত্তি করে সাদৃশ্য অনুসন্ধান ব্যবহার করে আমাদের অনুসন্ধান চালাতে পারি।
SQL কোয়েরিটি একই psql কমান্ড লাইন ইন্টারফেস থেকে অথবা বিকল্প হিসেবে, AlloyDB স্টুডিও থেকে কার্যকর করা যেতে পারে। যেকোনো মাল্টি-রো এবং জটিল আউটপুট AlloyDB স্টুডিওতে আরও ভালো দেখাতে পারে।
AlloyDB স্টুডিওতে সংযোগ করুন
পরবর্তী অধ্যায়গুলিতে ডাটাবেসের সাথে সংযোগের জন্য প্রয়োজনীয় সমস্ত SQL কমান্ড বিকল্পভাবে AlloyDB স্টুডিওতে কার্যকর করা যেতে পারে। কমান্ডটি চালানোর জন্য আপনাকে প্রাথমিক ইনস্ট্যান্সে ক্লিক করে আপনার AlloyDB ক্লাস্টারের জন্য ওয়েব কনসোল ইন্টারফেস খুলতে হবে।

তারপর বাম দিকে AlloyDB Studio-তে ক্লিক করুন:

quickstart_db ডাটাবেস, ব্যবহারকারী পোস্টগ্রেস নির্বাচন করুন এবং ক্লাস্টার তৈরি করার সময় উল্লেখিত পাসওয়ার্ডটি প্রদান করুন। তারপর "প্রমাণীকরণ" বোতামে ক্লিক করুন।

এটি AlloyDB স্টুডিও ইন্টারফেস খুলবে। ডাটাবেসে কমান্ডগুলি চালানোর জন্য আপনাকে ডানদিকে "Editor 1" ট্যাবে ক্লিক করতে হবে।
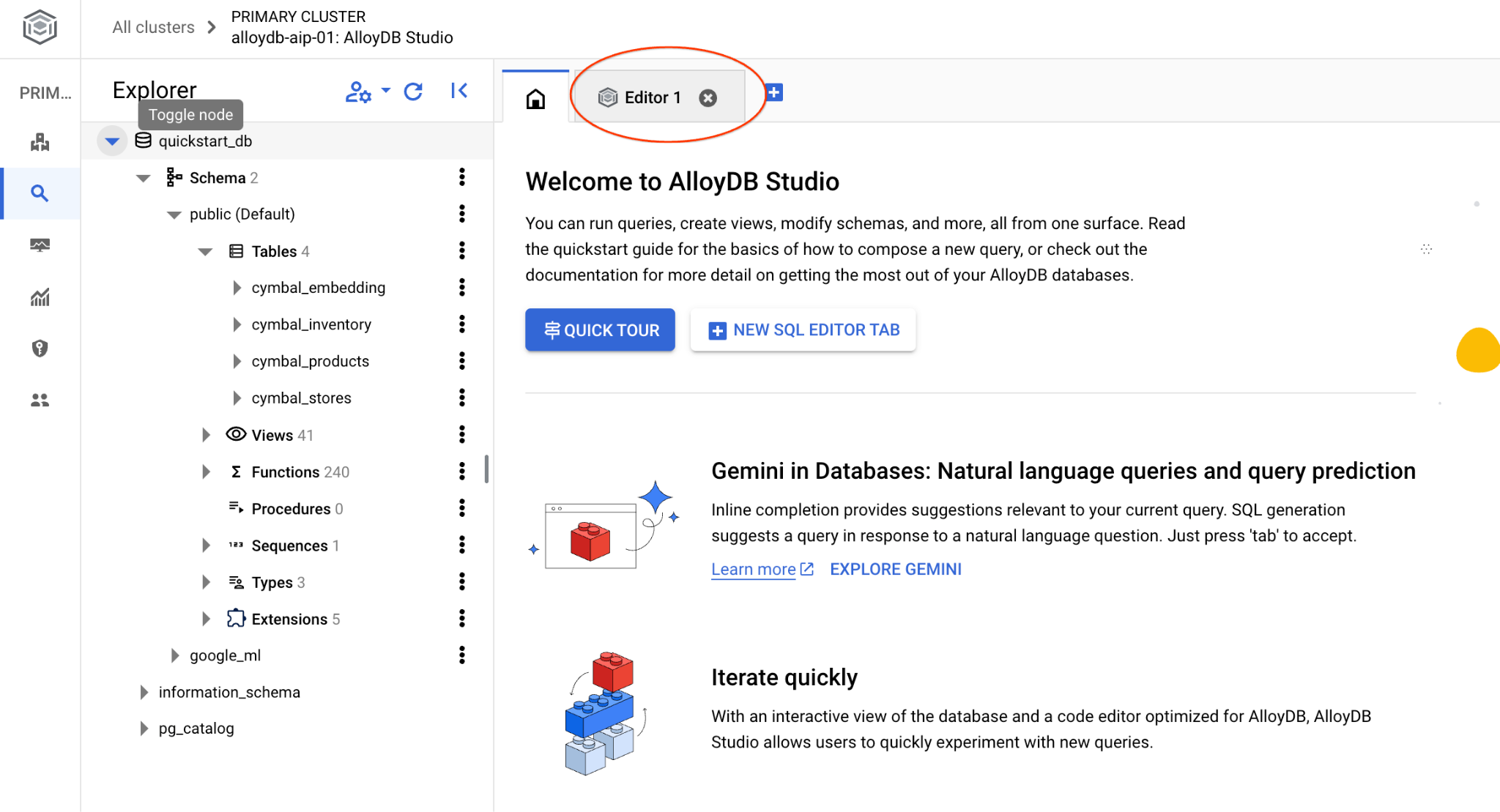
এটি ইন্টারফেস খোলে যেখানে আপনি SQL কমান্ড চালাতে পারবেন

যদি আপনি কমান্ড লাইন psql ব্যবহার করতে পছন্দ করেন তাহলে বিকল্প রুটটি অনুসরণ করুন এবং আপনার VM SSH সেশন থেকে ডাটাবেসের সাথে সংযোগ করুন যেমনটি পূর্ববর্তী অধ্যায়গুলিতে বর্ণনা করা হয়েছে।
পিএসকিউএল থেকে সাদৃশ্য অনুসন্ধান চালান
যদি আপনার ডাটাবেস সেশনটি সংযোগ বিচ্ছিন্ন হয়ে যায় তাহলে psql অথবা AlloyDB স্টুডিও ব্যবহার করে আবার ডাটাবেসের সাথে সংযোগ করুন।
ডাটাবেসের সাথে সংযোগ স্থাপন করুন:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
ক্লায়েন্টের অনুরোধের সাথে সবচেয়ে ঘনিষ্ঠভাবে সম্পর্কিত উপলব্ধ পণ্যগুলির একটি তালিকা পেতে একটি কোয়েরি চালান। ভেক্টর মান পেতে আমরা Vertex AI-কে যে অনুরোধটি পাঠাতে যাচ্ছি তা "এখানে কোন ধরণের ফলের গাছ ভালো জন্মে?" এর মতো শোনাচ্ছে।
আমাদের অনুরোধের জন্য সবচেয়ে উপযুক্ত প্রথম ১০টি আইটেম বেছে নেওয়ার জন্য আপনি এখানে একটি কোয়েরি চালাতে পারেন:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
এবং এখানে প্রত্যাশিত আউটপুট রয়েছে:
quickstart_db=> SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
product_name | description | sale_price | zip_code | distance
-------------------------+----------------------------------------------------------------------------------+------------+----------+---------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.43922018972266397
Meyer Lemon Tree | Meyer Lemon trees are California's favorite lemon tree! Grow your own lemons by | 34 | 93230 | 0.4685112926118228
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.4835677149651668
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.4947204525907498
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5054166905547247
California Black Walnut | This is a beautiful walnut tree that can grow to be over 80 feet tall. It is a d | 100.00 | 93230 | 0.5084219510932597
California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.5140519790508755
Coast Live Oak | This is a beautiful oak tree that can grow to be over 100 feet tall. It is an ev | 500.00 | 93230 | 0.5143126438081371
Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.5174774727252058
Madrone | This is a beautiful madrona tree that can grow to be over 80 feet tall. It is an | 50.00 | 93230 | 0.5227400803389093
9. প্রতিক্রিয়া উন্নত করুন
আপনি কোয়েরির ফলাফল ব্যবহার করে একটি ক্লায়েন্ট অ্যাপ্লিকেশনের প্রতিক্রিয়া উন্নত করতে পারেন এবং ভার্টেক্স এআই জেনারেটিভ ফাউন্ডেশন ল্যাঙ্গুয়েজ মডেলের প্রম্পটের অংশ হিসাবে সরবরাহিত কোয়েরি ফলাফল ব্যবহার করে একটি অর্থপূর্ণ আউটপুট প্রস্তুত করতে পারেন।
এটি অর্জনের জন্য আমরা ভেক্টর অনুসন্ধান থেকে আমাদের ফলাফলগুলি সহ একটি JSON তৈরি করার পরিকল্পনা করছি, তারপর একটি অর্থপূর্ণ আউটপুট তৈরি করতে Vertex AI-তে একটি টেক্সট LLM মডেলের জন্য একটি প্রম্পট যোগ করার জন্য সেই জেনারেট করা JSON ব্যবহার করব। প্রথম ধাপে আমরা JSON তৈরি করব, তারপর আমরা Vertex AI স্টুডিওতে এটি পরীক্ষা করব এবং শেষ ধাপে আমরা এটি একটি SQL স্টেটমেন্টে অন্তর্ভুক্ত করব যা একটি অ্যাপ্লিকেশনে ব্যবহার করা যেতে পারে।
JSON ফর্ম্যাটে আউটপুট তৈরি করুন
JSON ফর্ম্যাটে আউটপুট তৈরি করতে কোয়েরিটি পরিবর্তন করুন এবং Vertex AI তে পাস করার জন্য শুধুমাত্র একটি সারি ফেরত দিন।
এখানে কোয়েরির উদাহরণ দেওয়া হল:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
এবং আউটপুটে প্রত্যাশিত JSON এখানে রয়েছে:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
ভার্টেক্স এআই স্টুডিওতে প্রম্পটটি চালান
আমরা Vertex AI স্টুডিওতে জেনারেটিভ AI টেক্সট মডেলের প্রম্পটের অংশ হিসেবে জেনারেটেড JSON ব্যবহার করতে পারি।
ক্লাউড কনসোলে Vertex AI স্টুডিও খুলুন।
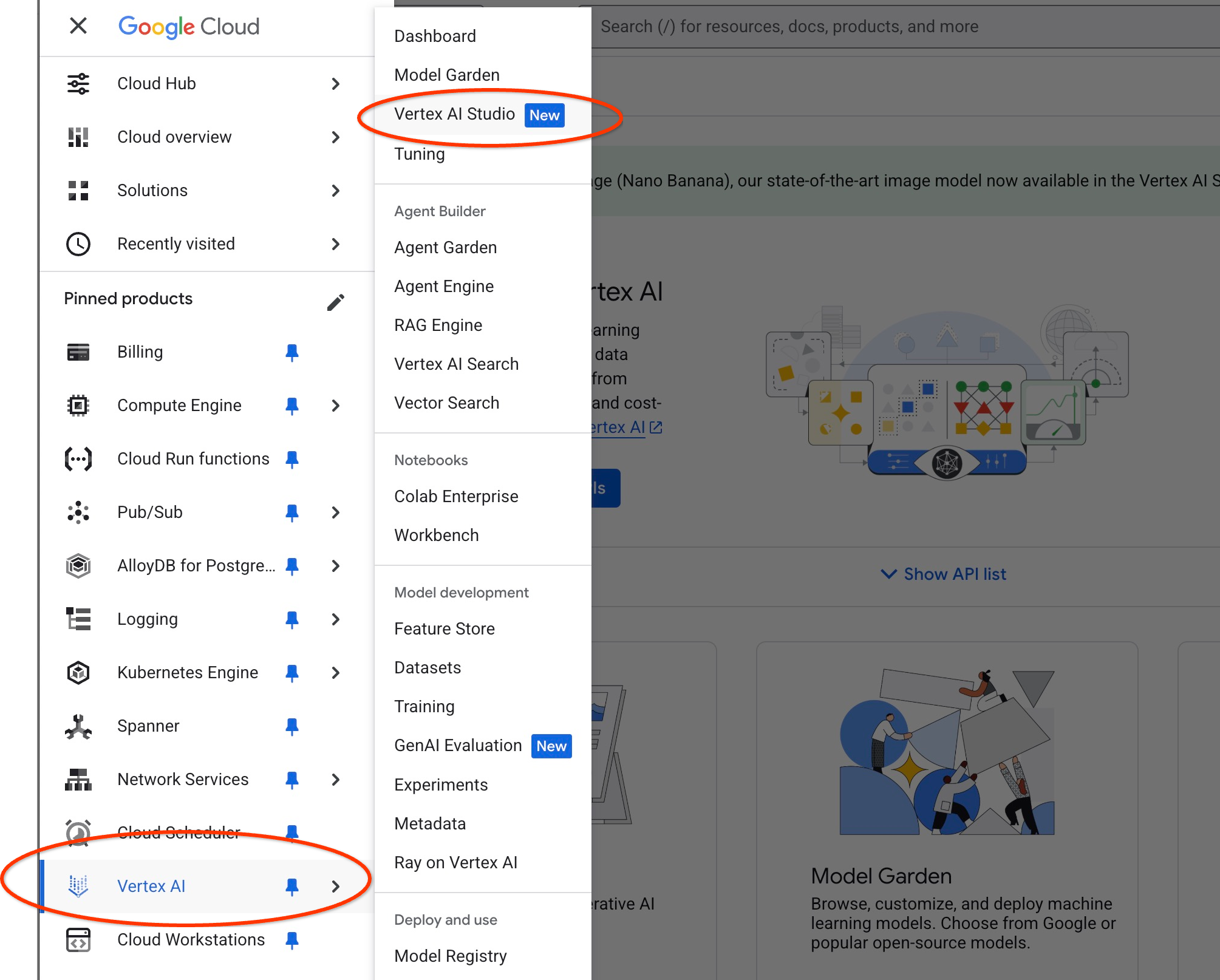
যদি আপনি আগে এটি ব্যবহার না করে থাকেন তবে এটি ব্যবহারের শর্তাবলীর সাথে একমত হতে পারে। "সম্মত হন এবং চালিয়ে যান" বোতামটি টিপুন।
ইন্টারফেসে আপনার প্রম্পট লিখুন।

এটি আপনাকে অতিরিক্ত API সক্রিয় করতে বলতে পারে কিন্তু আপনি অনুরোধটি উপেক্ষা করতে পারেন। আমাদের ল্যাবটি শেষ করার জন্য আমাদের কোনও অতিরিক্ত API-এর প্রয়োজন নেই।
গাছ সম্পর্কে প্রাথমিক প্রশ্নের JSON আউটপুটের সাথে আমরা যে প্রম্পটটি ব্যবহার করতে যাচ্ছি তা এখানে:
আপনি একজন বন্ধুত্বপূর্ণ উপদেষ্টা যিনি গ্রাহকের চাহিদার উপর ভিত্তি করে একটি পণ্য খুঁজে পেতে সাহায্য করেন।
ক্লায়েন্টের অনুরোধের ভিত্তিতে আমরা অনুসন্ধানের সাথে ঘনিষ্ঠভাবে সম্পর্কিত পণ্যগুলির একটি তালিকা লোড করেছি।
JSON ফর্ম্যাটের তালিকাটিতে {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"} এর মতো মান রয়েছে।
এখানে পণ্যের তালিকা দেওয়া হল:
{"product_name":"চেরি গাছ","description":"এটি একটি সুন্দর চেরি গাছ যা সুস্বাদু চেরি উৎপাদন করবে। এটি একটি d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}
গ্রাহক জিজ্ঞাসা করলেন, "এখানে কোন গাছটি সবচেয়ে ভালো জন্মাচ্ছে?"
আপনার পণ্য, দাম এবং কিছু সম্পূরক তথ্য সম্পর্কে তথ্য দেওয়া উচিত।
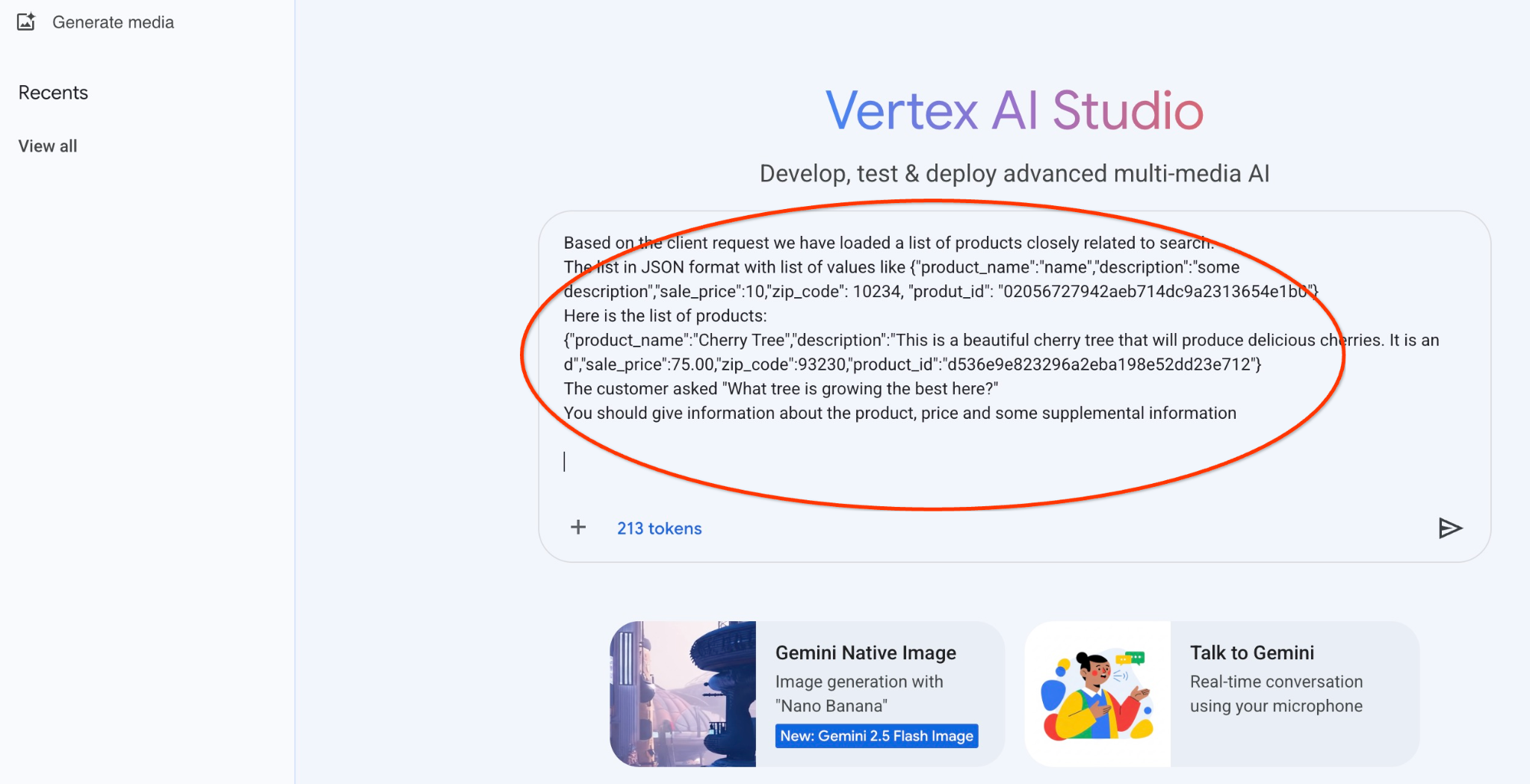
এবং যখন আমরা আমাদের JSON মান সহ এবং gemini-2.5-flash-light মডেল ব্যবহার করে প্রম্পটটি চালাই তখন ফলাফলটি এখানে:

এই উদাহরণে মডেল থেকে আমরা যে উত্তরটি পেয়েছি তা নিম্নরূপ। মনে রাখবেন যে সময়ের সাথে সাথে মডেল এবং প্যারামিটারের পরিবর্তনের কারণে আপনার উত্তর ভিন্ন হতে পারে:
"উপলব্ধ পণ্যের উপর ভিত্তি করে, "চেরি ট্রি" সম্পর্কে আমি আপনাকে যা বলতে পারি তা এখানে:"
পণ্য: চেরি গাছ
মূল্য: $৭৫.০০
বর্ণনা: এটি একটি সুন্দর চেরি গাছ যা সুস্বাদু চেরি উৎপাদন করবে।
কোন গাছটি "এখানে সবচেয়ে ভালো জন্মাচ্ছে" তা নির্ধারণ করার জন্য, আমার আরও তথ্যের প্রয়োজন হবে। আপনার কি এমন অন্য কোনও গাছের তালিকা আছে যা আমরা তুলনা করতে পারি, অথবা "সবচেয়ে ভালো জন্মাবার" কোনও নির্দিষ্ট দিক আছে যা আপনার আগ্রহী (যেমন, দ্রুততম বৃদ্ধি, সর্বাধিক ফলের উৎপাদন, আপনার নির্দিষ্ট জলবায়ুতে স্থায়িত্ব)?"
PSQL-এ প্রম্পট চালান
আমরা সরাসরি ডাটাবেসে SQL ব্যবহার করে জেনারেটিভ মডেল থেকে একই প্রতিক্রিয়া পেতে Vertex AI এর সাথে AlloyDB AI ইন্টিগ্রেশন ব্যবহার করতে পারি। কিন্তু gemini-1.5-flash মডেল ব্যবহার করার জন্য আমাদের প্রথমে এটি নিবন্ধন করতে হবে।
google_ml_integration এক্সটেনশনটি যাচাই করুন। এর সংস্করণ ১.৪.২ বা তার পরবর্তী হওয়া উচিত।
psql থেকে quickstart_db ডাটাবেসের সাথে সংযোগ করুন যেমনটি আগে দেখানো হয়েছে (অথবা AlloyDB স্টুডিও ব্যবহার করুন) এবং কার্যকর করুন:
SELECT extversion from pg_extension where extname='google_ml_integration';
google_ml_integration.enable_model_support ডাটাবেস ফ্ল্যাগটি পরীক্ষা করুন।
show google_ml_integration.enable_model_support;
পিএসকিউএল সেশন থেকে প্রত্যাশিত আউটপুট "চালু":
postgres=> show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
যদি এটি "বন্ধ" দেখায় তাহলে আমাদের google_ml_integration.enable_model_support ডাটাবেস ফ্ল্যাগটি "চালু" তে সেট করতে হবে। এটি করার জন্য আপনি AlloyDB ওয়েব কনসোল ইন্টারফেস ব্যবহার করতে পারেন অথবা নিম্নলিখিত gcloud কমান্ডটি চালাতে পারেন।
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags google_ml_integration.enable_faster_embedding_generation=on,google_ml_integration.enable_model_support=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
কমান্ডটি ব্যাকগ্রাউন্ডে কার্যকর হতে প্রায় ১-৩ মিনিট সময় নেয়। তারপর আপনি আবার পতাকাটি যাচাই করতে পারেন।
আমাদের প্রশ্নের জন্য আমাদের দুটি মডেলের প্রয়োজন। প্রথমটি হল ইতিমধ্যে ব্যবহৃত text-embedding-005 মডেল এবং দ্বিতীয়টি হল জেনেরিক গুগল জেমিনি মডেলগুলির মধ্যে একটি।
আমরা টেক্সট এম্বেডিং মডেল থেকে শুরু করি। মডেলটি নিবন্ধন করতে psql অথবা AlloyDB স্টুডিওতে নিম্নলিখিত কোডটি চালান:
CALL
google_ml.create_model(
model_id => 'text-embedding-005',
model_provider => 'google',
model_qualified_name => 'text-embedding-005',
model_type => 'text_embedding',
model_auth_type => 'alloydb_service_agent_iam',
model_in_transform_fn => 'google_ml.vertexai_text_embedding_input_transform',
model_out_transform_fn => 'google_ml.vertexai_text_embedding_output_transform');
এবং পরবর্তী মডেলটি আমাদের নিবন্ধন করতে হবে তা হল gemini-2.0-flash-001 যা ব্যবহারকারী-বান্ধব আউটপুট তৈরি করতে ব্যবহার করা হবে।
CALL
google_ml.create_model(
model_id => 'gemini-2.5-flash',
model_request_url => 'publishers/google/models/gemini-2.5-flash:streamGenerateContent',
model_provider => 'google',
model_auth_type => 'alloydb_service_agent_iam');
আপনি google_ml.model_info_view থেকে তথ্য নির্বাচন করে সর্বদা নিবন্ধিত মডেলের তালিকা যাচাই করতে পারেন।
select model_id,model_type from google_ml.model_info_view;
এখানে নমুনা আউটপুট আছে
quickstart_db=> select model_id,model_type from google_ml.model_info_view;
model_id | model_type
-------------------------+----------------
textembedding-gecko | text_embedding
textembedding-gecko@001 | text_embedding
text-embedding-005 | text_embedding
gemini-2.5-flash | generic
(4 rows)
এখন আমরা SQL ব্যবহার করে জেনারেটিভ AI টেক্সট মডেলের প্রম্পটের অংশ হিসেবে একটি সাবকোয়েরিতে জেনারেট করা JSON ব্যবহার করতে পারি।
psql অথবা AlloyDB স্টুডিও সেশনে ডাটাবেসে কোয়েরিটি চালান
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005',
'What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1),
prompt AS (
SELECT
'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:' || json_agg(trees) || 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information' AS prompt_text
FROM
trees),
response AS (
SELECT
json_array_elements(google_ml.predict_row( model_id =>'gemini-2.5-flash',
request_body => json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text',
prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT
string_agg(resp::text,
' ')
FROM
response;
এবং এখানে প্রত্যাশিত আউটপুট। মডেল সংস্করণ এবং প্যারামিটারের উপর নির্ভর করে আপনার আউটপুট ভিন্ন হতে পারে।:
"Hello there! I can certainly help you with finding a great fruit tree for your area.\n\nBased on what grows well, we have a wonderful **Cherry Tree** that could be a perfect fit!\n\nThis beautiful cherry tree is an excellent choice for producing delicious cherries right in your garden. It's an deciduous tree that typically" " grows to about 15 feet tall. Beyond its fruit, it offers lovely aesthetics with dark green leaves in the summer that transition to a beautiful red in the fall, making it great for shade and privacy too.\n\nCherry trees generally prefer a cool, moist climate and sandy soil, and they are best suited for USDA Zones" " 4-9. Given the zip code you're inquiring about (93230), which is typically in USDA Zone 9, this Cherry Tree should thrive wonderfully!\n\nYou can get this magnificent tree for just **$75.00**.\n\nLet me know if you have any other questions!" "
১০. ভেক্টর সূচক তৈরি করুন
আমাদের ডেটাসেটটি বেশ ছোট এবং প্রতিক্রিয়া সময় মূলত AI মডেলগুলির সাথে মিথস্ক্রিয়ার উপর নির্ভর করে। কিন্তু যখন আপনার লক্ষ লক্ষ ভেক্টর থাকে তখন ভেক্টর অনুসন্ধান অংশটি আমাদের প্রতিক্রিয়া সময়ের একটি উল্লেখযোগ্য অংশ নিতে পারে এবং সিস্টেমের উপর একটি উচ্চ লোড চাপিয়ে দিতে পারে। এটি উন্নত করার জন্য আমরা আমাদের ভেক্টরগুলির উপরে একটি সূচক তৈরি করতে পারি।
ScaNN সূচক তৈরি করুন
SCANN সূচক তৈরি করতে আমাদের আরও একটি এক্সটেনশন সক্রিয় করতে হবে। alloydb_scann এক্সটেনশনটি Google ScaNN অ্যালগরিদম ব্যবহার করে ANN টাইপ ভেক্টর সূচকের সাথে কাজ করার জন্য একটি ইন্টারফেস প্রদান করে।
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
প্রত্যাশিত আউটপুট:
quickstart_db=> CREATE EXTENSION IF NOT EXISTS alloydb_scann; CREATE EXTENSION Time: 27.468 ms quickstart_db=>
সূচকটি ম্যানুয়াল অথবা অটো মোডে তৈরি করা যেতে পারে। ম্যানুয়াল মোডটি ডিফল্টরূপে সক্রিয় থাকে এবং আপনি একটি সূচক তৈরি করতে পারেন এবং এটি অন্য যেকোনো সূচকের মতো বজায় রাখতে পারেন। কিন্তু আপনি যদি অটো মোড সক্ষম করেন তবে আপনি সূচক তৈরি করতে সক্ষম হবেন যার জন্য আপনার পক্ষ থেকে কোনও রক্ষণাবেক্ষণের প্রয়োজন হবে না। আপনি ডকুমেন্টেশনে সমস্ত বিকল্প সম্পর্কে বিস্তারিতভাবে পড়তে পারেন এবং এখানে আমি আপনাকে দেখাবো কিভাবে অটো মোড সক্ষম করবেন এবং সূচক তৈরি করবেন। আমাদের ক্ষেত্রে অটো মোডে সূচক তৈরি করার জন্য আমাদের কাছে পর্যাপ্ত সারি নেই - তাই আমরা এটি ম্যানুয়াল হিসাবে তৈরি করব।
নিম্নলিখিত উদাহরণে আমি বেশিরভাগ প্যারামিটার ডিফল্ট হিসেবে রেখে দিচ্ছি এবং সূচকের জন্য শুধুমাত্র কয়েকটি পার্টিশন (num_leaves) প্রদান করছি:
CREATE INDEX cymbal_products_embeddings_scann ON cymbal_products
USING scann (embedding cosine)
WITH (num_leaves=31, max_num_levels = 2);
আপনি ডকুমেন্টেশনে সূচক পরামিতি টিউনিং সম্পর্কে পড়তে পারেন।
প্রত্যাশিত আউটপুট:
quickstart_db=> CREATE INDEX cymbal_products_embeddings_scann ON cymbal_products USING scann (embedding cosine) WITH (num_leaves=31, max_num_levels = 2); CREATE INDEX quickstart_db=>
প্রতিক্রিয়া তুলনা করুন
এখন আমরা EXPLAIN মোডে ভেক্টর অনুসন্ধান কোয়েরি চালাতে পারি এবং সূচকটি ব্যবহার করা হয়েছে কিনা তা যাচাই করতে পারি।
EXPLAIN (analyze)
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
প্রত্যাশিত আউটপুট (স্পষ্টতার জন্য সংশোধন করা হয়েছে):
... Aggregate (cost=16.59..16.60 rows=1 width=32) (actual time=2.875..2.877 rows=1 loops=1) -> Subquery Scan on trees (cost=8.42..16.59 rows=1 width=142) (actual time=2.860..2.862 rows=1 loops=1) -> Limit (cost=8.42..16.58 rows=1 width=158) (actual time=2.855..2.856 rows=1 loops=1) -> Nested Loop (cost=8.42..6489.19 rows=794 width=158) (actual time=2.854..2.855 rows=1 loops=1) -> Nested Loop (cost=8.13..6466.99 rows=794 width=938) (actual time=2.742..2.743 rows=1 loops=1) -> Index Scan using cymbal_products_embeddings_scann on cymbal_products cp (cost=7.71..111.99 rows=876 width=934) (actual time=2.724..2.724 rows=1 loops=1) Order By: (embedding <=> '[0.008864171,0.03693164,-0.024245683,-0.00355923,0.0055611245,0.015985578,...<redacted>...5685,-0.03914233,-0.018452475,0.00826032,-0.07372604]'::vector) -> Index Scan using walmart_inventory_pkey on cymbal_inventory ci (cost=0.42..7.26 rows=1 width=37) (actual time=0.015..0.015 rows=1 loops=1) Index Cond: ((store_id = 1583) AND (uniq_id = (cp.uniq_id)::text)) ...
আউটপুট থেকে আমরা স্পষ্ট দেখতে পাচ্ছি যে কোয়েরিটি "Index Scan using cymbal_products_embeddings_scann on cymbal_products" ব্যবহার করছে।
এবং যদি আমরা ব্যাখ্যা ছাড়াই কোয়েরিটি চালাই:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
প্রত্যাশিত আউটপুট:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
আমরা দেখতে পাচ্ছি যে ফলাফলটি একই চেরি গাছ যা আমাদের অনুসন্ধানে সূচক ছাড়াই শীর্ষে ছিল। কখনও কখনও এটি নাও হতে পারে এবং প্রতিক্রিয়াটি একই গাছ নয় বরং উপরে থেকে অন্য কিছু গাছ ফেরত দিতে পারে। সুতরাং সূচকটি আমাদের কর্মক্ষমতা দিচ্ছে তবে এখনও ভাল ফলাফল দেওয়ার জন্য যথেষ্ট নির্ভুল।
আপনি ভেক্টরগুলির জন্য উপলব্ধ বিভিন্ন সূচক এবং ডকুমেন্টেশন পৃষ্ঠায় উপলব্ধ ল্যাংচেইন ইন্টিগ্রেশন সহ আরও ল্যাব এবং উদাহরণ চেষ্টা করতে পারেন।
১১. পরিবেশ পরিষ্কার করুন
ল্যাবের কাজ শেষ হলে AlloyDB ইনস্ট্যান্স এবং ক্লাস্টার ধ্বংস করুন।
AlloyDB ক্লাস্টার এবং সমস্ত ইনস্ট্যান্স মুছে ফেলুন
যদি আপনি AlloyDB এর ট্রায়াল ভার্সন ব্যবহার করে থাকেন। যদি আপনার ট্রায়াল ক্লাস্টার ব্যবহার করে অন্যান্য ল্যাব এবং রিসোর্স পরীক্ষা করার পরিকল্পনা থাকে, তাহলে ট্রায়াল ক্লাস্টারটি মুছে ফেলবেন না। আপনি একই প্রকল্পে আরেকটি ট্রায়াল ক্লাস্টার তৈরি করতে পারবেন না।
ক্লাস্টারটি অপশন ফোর্স দিয়ে ধ্বংস করা হয় যা ক্লাস্টারের সমস্ত ইনস্ট্যান্সও মুছে ফেলে।
যদি আপনার সংযোগ বিচ্ছিন্ন হয়ে যায় এবং পূর্ববর্তী সমস্ত সেটিংস হারিয়ে যায়, তাহলে ক্লাউড শেলে প্রকল্প এবং পরিবেশের ভেরিয়েবলগুলি সংজ্ঞায়িত করুন:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
ক্লাস্টারটি মুছুন:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
প্রত্যাশিত কনসোল আউটপুট:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
AlloyDB ব্যাকআপ মুছে ফেলুন
ক্লাস্টারের জন্য সমস্ত AlloyDB ব্যাকআপ মুছে ফেলুন:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
প্রত্যাশিত কনসোল আউটপুট:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
এখন আমরা আমাদের VM ধ্বংস করতে পারি
GCE VM মুছে ফেলুন
ক্লাউড শেলে কার্যকর করুন:
export GCEVM=instance-1
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
প্রত্যাশিত কনসোল আউটপুট:
student@cloudshell:~ (test-project-001-402417)$ export GCEVM=instance-1
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Deleted
১২. অভিনন্দন
কোডল্যাবটি সম্পন্ন করার জন্য অভিনন্দন।
এই ল্যাবটি গুগল ক্লাউড লার্নিং পাথ সহ প্রোডাকশন-রেডি এআই-এর অংশ।
- প্রোটোটাইপ থেকে উৎপাদন পর্যন্ত ব্যবধান পূরণ করতে সম্পূর্ণ পাঠ্যক্রমটি অন্বেষণ করুন ।
-
#ProductionReadyAIহ্যাশট্যাগ ব্যবহার করে আপনার অগ্রগতি শেয়ার করুন।
আমরা যা কভার করেছি
- AlloyDB ক্লাস্টার এবং প্রাথমিক উদাহরণ কীভাবে স্থাপন করবেন
- গুগল কম্পিউট ইঞ্জিন ভিএম থেকে অ্যালয়ডিবিতে কীভাবে সংযোগ করবেন
- কিভাবে ডাটাবেস তৈরি করবেন এবং AlloyDB AI সক্রিয় করবেন
- ডাটাবেসে ডেটা কীভাবে লোড করবেন
- AlloyDB স্টুডিও কীভাবে ব্যবহার করবেন
- AlloyDB-তে Vertex AI এমবেডিং মডেল কীভাবে ব্যবহার করবেন
- ভার্টেক্স এআই স্টুডিও কীভাবে ব্যবহার করবেন
- ভার্টেক্স এআই জেনারেটিভ মডেল ব্যবহার করে ফলাফল কীভাবে সমৃদ্ধ করা যায়
- ভেক্টর সূচক ব্যবহার করে কর্মক্ষমতা কীভাবে উন্নত করা যায়
১৩. জরিপ
আউটপুট: