
1. Pengantar
Dalam codelab ini, Anda akan mempelajari cara menggunakan AlloyDB AI dengan menggabungkan penelusuran vektor dengan embedding Vertex AI. Lab ini adalah bagian dari koleksi lab yang dikhususkan untuk fitur AI AlloyDB. Anda dapat membaca selengkapnya di halaman AI AlloyDB dalam dokumentasi.

Prasyarat
- Pemahaman dasar tentang Konsol Google Cloud
- Keterampilan dasar dalam antarmuka command line dan Google Shell
Yang akan Anda pelajari
- Cara men-deploy cluster dan instance utama AlloyDB
- Cara terhubung ke AlloyDB dari VM Google Compute Engine
- Cara membuat database dan mengaktifkan AlloyDB AI
- Cara memuat data ke database
- Cara menggunakan AlloyDB Studio
- Cara menggunakan model embedding Vertex AI di AlloyDB
- Cara menggunakan Vertex AI Studio
- Cara memperkaya hasil menggunakan model generatif Vertex AI
- Cara meningkatkan performa menggunakan indeks vektor
Yang Anda butuhkan
- Akun Google Cloud dan Project Google Cloud
- Browser web seperti Chrome
2. Penyiapan dan Persyaratan
Penyiapan Project
- Login ke Konsol Google Cloud. Jika belum memiliki akun Gmail atau Google Workspace, Anda harus membuatnya.
Gunakan akun pribadi, bukan akun kantor atau sekolah.
- Buat project baru atau gunakan kembali project yang sudah ada. Untuk membuat project baru di konsol Google Cloud, di header, klik tombol Pilih project yang akan membuka jendela pop-up.

Di jendela Select a project, tekan tombol New Project yang akan membuka kotak dialog untuk project baru.

Di kotak dialog, masukkan Nama project yang Anda inginkan dan pilih lokasi.
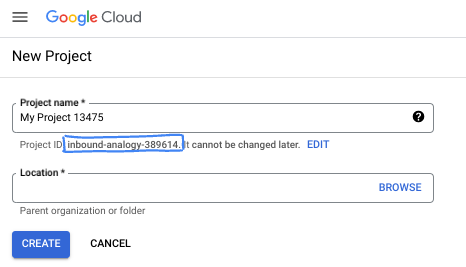
- Project name adalah nama tampilan untuk peserta project ini. Nama project tidak digunakan oleh Google API, dan dapat diubah kapan saja.
- Project ID bersifat unik di semua project Google Cloud dan tidak dapat diubah (tidak dapat diubah setelah ditetapkan). Konsol Google Cloud otomatis membuat ID unik, tetapi Anda dapat menyesuaikannya. Jika tidak menyukai ID yang dibuat, Anda dapat membuat ID acak lain atau memberikan ID Anda sendiri untuk memeriksa ketersediaannya. Di sebagian besar codelab, Anda harus merujuk project ID Anda, yang biasanya diidentifikasi dengan placeholder PROJECT_ID.
- Sebagai informasi, ada nilai ketiga, Project Number, yang digunakan oleh beberapa API. Pelajari lebih lanjut ketiga nilai ini di dokumentasi.
Aktifkan Penagihan
Untuk mengaktifkan penagihan, Anda memiliki dua opsi. Anda dapat menggunakan akun penagihan pribadi atau menukarkan kredit dengan langkah-langkah berikut.
Tukarkan kredit Google Cloud senilai $5 (opsional)
Untuk menjalankan workshop ini, Anda memerlukan Akun Penagihan dengan sejumlah kredit. Jika Anda berencana menggunakan penagihan sendiri, Anda dapat melewati langkah ini.
- Klik link ini dan login dengan Akun Google pribadi.
- Anda akan melihat sesuatu seperti ini:

- Klik tombol KLIK DI SINI UNTUK MENGAKSES KREDIT ANDA. Anda akan diarahkan ke halaman untuk menyiapkan profil penagihan. Jika Anda melihat layar pendaftaran uji coba gratis, klik batal dan lanjutkan untuk menautkan penagihan.

- Klik Confirm. Anda kini terhubung ke Akun Penagihan Uji Coba Google Cloud Platform.

Menyiapkan akun penagihan pribadi
Jika menyiapkan penagihan menggunakan kredit Google Cloud, Anda dapat melewati langkah ini.
Untuk menyiapkan akun penagihan pribadi, buka di sini untuk mengaktifkan penagihan di Cloud Console.
Beberapa Catatan:
- Menyelesaikan lab ini akan dikenai biaya kurang dari $3 USD untuk resource Cloud.
- Anda dapat mengikuti langkah-langkah di akhir lab ini untuk menghapus resource agar tidak dikenai biaya lebih lanjut.
- Pengguna baru memenuhi syarat untuk mengikuti Uji Coba Gratis senilai$300 USD.
Mulai Cloud Shell
Meskipun Google Cloud dapat dioperasikan dari jarak jauh menggunakan laptop Anda, dalam codelab ini, Anda akan menggunakan Google Cloud Shell, lingkungan command line yang berjalan di Cloud.
Dari Google Cloud Console, klik ikon Cloud Shell di toolbar kanan atas:

Atau, Anda dapat menekan G, lalu S. Urutan ini akan mengaktifkan Cloud Shell jika Anda berada dalam Konsol Google Cloud atau menggunakan link ini.
Hanya perlu waktu beberapa saat untuk penyediaan dan terhubung ke lingkungan. Jika sudah selesai, Anda akan melihat tampilan seperti ini:

Mesin virtual ini berisi semua alat pengembangan yang Anda perlukan. Layanan ini menawarkan direktori beranda tetap sebesar 5 GB dan beroperasi di Google Cloud, sehingga sangat meningkatkan performa dan autentikasi jaringan. Semua pekerjaan Anda dalam codelab ini dapat dilakukan di browser. Anda tidak perlu menginstal apa pun.
3. Sebelum memulai
Aktifkan API
Output:
Untuk menggunakan AlloyDB, Compute Engine, Layanan jaringan, dan Vertex AI, Anda harus mengaktifkan API masing-masing di project Google Cloud Anda.
Mengaktifkan API
Di dalam Cloud Shell di terminal, pastikan project ID Anda sudah disiapkan:
gcloud config set project [YOUR-PROJECT-ID]
Tetapkan variabel lingkungan PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Aktifkan semua API yang diperlukan:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Output yang diharapkan
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Memperkenalkan API
- AlloyDB API (
alloydb.googleapis.com) memungkinkan Anda membuat, mengelola, dan menskalakan cluster AlloyDB untuk PostgreSQL. Layanan ini menyediakan layanan database yang kompatibel dengan PostgreSQL dan terkelola sepenuhnya, yang dirancang untuk workload transaksional dan analitis perusahaan yang berat. - Compute Engine API (
compute.googleapis.com) memungkinkan Anda membuat dan mengelola mesin virtual (VM), persistent disk, dan setelan jaringan. Layanan ini menyediakan fondasi Infrastructure-as-a-Service (IaaS) inti yang diperlukan untuk menjalankan beban kerja Anda dan menghosting infrastruktur yang mendasarinya untuk banyak layanan terkelola. - Cloud Resource Manager API (
cloudresourcemanager.googleapis.com) memungkinkan Anda mengelola metadata dan konfigurasi project Google Cloud secara terprogram. Dengan demikian, Anda dapat mengatur resource, menangani kebijakan Identity and Access Management (IAM), dan memvalidasi izin di seluruh hierarki project. - Service Networking API (
servicenetworking.googleapis.com) memungkinkan Anda mengotomatiskan penyiapan konektivitas pribadi antara jaringan Virtual Private Cloud (VPC) dan layanan terkelola Google. Hal ini secara khusus diperlukan untuk membuat akses IP pribadi bagi layanan seperti AlloyDB agar dapat berkomunikasi dengan aman dengan resource Anda yang lain. - Vertex AI API (
aiplatform.googleapis.com) memungkinkan aplikasi Anda membangun, men-deploy, dan menskalakan model machine learning. Vertex AI menyediakan antarmuka terpadu untuk semua layanan AI Google Cloud, termasuk akses ke model AI Generatif (seperti Gemini) dan pelatihan model kustom.
Sebagai opsi, Anda dapat mengonfigurasi region default untuk menggunakan model sematan Vertex AI. Baca selengkapnya tentang lokasi yang tersedia untuk Vertex AI. Dalam contoh ini, kita menggunakan region us-central1.
gcloud config set compute/region us-central1
4. Men-deploy AlloyDB
Sebelum membuat cluster AlloyDB, kita memerlukan rentang IP pribadi yang tersedia di VPC untuk digunakan oleh instance AlloyDB mendatang. Jika belum ada, kita perlu membuatnya, menetapkannya untuk digunakan oleh layanan Google internal, dan setelah itu kita dapat membuat cluster dan instance.
Buat rentang IP pribadi
Kita perlu mengonfigurasi konfigurasi Akses Layanan Pribadi di VPC untuk AlloyDB. Asumsinya di sini adalah kita memiliki jaringan VPC "default" dalam project dan jaringan tersebut akan digunakan untuk semua tindakan.
Buat rentang IP pribadi:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Buat koneksi pribadi menggunakan rentang IP yang dialokasikan:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Output konsol yang diharapkan:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
Buat Cluster AlloyDB
Di bagian ini, kita akan membuat cluster AlloyDB di region us-central1.
Tentukan sandi untuk pengguna postgres. Anda dapat menentukan sandi Anda sendiri atau menggunakan fungsi acak untuk membuatnya
export PGPASSWORD=`openssl rand -hex 12`
Output konsol yang diharapkan:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
Catat sandi PostgreSQL untuk penggunaan berikutnya.
echo $PGPASSWORD
Anda akan memerlukan sandi tersebut pada masa mendatang untuk terhubung ke instance sebagai pengguna postgres. Sebaiknya tulis atau salin di suatu tempat agar dapat digunakan nanti.
Output konsol yang diharapkan:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723
Membuat Cluster Uji Coba Gratis
Jika belum pernah menggunakan AlloyDB, Anda dapat membuat cluster uji coba gratis:
Tentukan region dan nama cluster AlloyDB. Kita akan menggunakan region us-central1 dan alloydb-aip-01 sebagai nama cluster:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Jalankan perintah untuk membuat cluster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Output konsol yang diharapkan:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Buat instance utama AlloyDB untuk cluster di sesi cloud shell yang sama. Jika koneksi terputus, Anda harus menentukan variabel lingkungan nama cluster dan region lagi.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Output konsol yang diharapkan:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
Buat Cluster Standar AlloyDB
Jika ini bukan cluster AlloyDB pertama Anda dalam project, lanjutkan pembuatan cluster standar.
Tentukan region dan nama cluster AlloyDB. Kita akan menggunakan region us-central1 dan alloydb-aip-01 sebagai nama cluster:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Jalankan perintah untuk membuat cluster:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Output konsol yang diharapkan:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Buat instance utama AlloyDB untuk cluster di sesi cloud shell yang sama. Jika koneksi terputus, Anda harus menentukan variabel lingkungan nama cluster dan region lagi.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Output konsol yang diharapkan:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. Membuat koneksi ke AlloyDB
AlloyDB di-deploy menggunakan koneksi khusus pribadi, jadi kita memerlukan VM dengan klien PostgreSQL yang diinstal untuk bekerja dengan database.
Deploy VM GCE
Buat VM GCE di region dan VPC yang sama dengan cluster AlloyDB.
Di Cloud Shell, jalankan:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE \
--create-disk=auto-delete=yes,boot=yes,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" --format="value(name)") \
--scopes=https://www.googleapis.com/auth/cloud-platform
Output konsol yang diharapkan:
student@cloudshell:~ (test-project-402417)$ export ZONE=us-central1-a
student@cloudshell:~ (test-project-402417)$ export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE \
--create-disk=auto-delete=yes,boot=yes,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" --format="value(name)") \
--scopes=https://www.googleapis.com/auth/cloud-platform
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/zones/us-central1-a/instances/instance-1].
NAME: instance-1
ZONE: us-central1-a
MACHINE_TYPE: n1-standard-1
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.2
EXTERNAL_IP: 34.71.192.233
STATUS: RUNNING
Instal Klien Postgres
Instal software klien PostgreSQL pada VM yang di-deploy
Hubungkan ke VM:
gcloud compute ssh instance-1 --zone=us-central1-a
Output konsol yang diharapkan:
student@cloudshell:~ (test-project-402417)$ gcloud compute ssh instance-1 --zone=us-central1-a Updating project ssh metadata...working..Updated [https://www.googleapis.com/compute/v1/projects/test-project-402417]. Updating project ssh metadata...done. Waiting for SSH key to propagate. Warning: Permanently added 'compute.5110295539541121102' (ECDSA) to the list of known hosts. Linux instance-1.us-central1-a.c.gleb-test-short-001-418811.internal 6.1.0-18-cloud-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.76-1 (2024-02-01) x86_64 The programs included with the Debian GNU/Linux system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. student@instance-1:~$
Instal software yang menjalankan perintah dalam VM:
sudo apt-get update
sudo apt-get install --yes postgresql-client
Output konsol yang diharapkan:
student@instance-1:~$ sudo apt-get update sudo apt-get install --yes postgresql-client Get:1 https://packages.cloud.google.com/apt google-compute-engine-bullseye-stable InRelease [5146 B] Get:2 https://packages.cloud.google.com/apt cloud-sdk-bullseye InRelease [6406 B] Hit:3 https://deb.debian.org/debian bullseye InRelease Get:4 https://deb.debian.org/debian-security bullseye-security InRelease [48.4 kB] Get:5 https://packages.cloud.google.com/apt google-compute-engine-bullseye-stable/main amd64 Packages [1930 B] Get:6 https://deb.debian.org/debian bullseye-updates InRelease [44.1 kB] Get:7 https://deb.debian.org/debian bullseye-backports InRelease [49.0 kB] ...redacted... update-alternatives: using /usr/share/postgresql/13/man/man1/psql.1.gz to provide /usr/share/man/man1/psql.1.gz (psql.1.gz) in auto mode Setting up postgresql-client (13+225) ... Processing triggers for man-db (2.9.4-2) ... Processing triggers for libc-bin (2.31-13+deb11u7) ...
Hubungkan ke Instance
Hubungkan ke instance utama dari VM menggunakan psql.
Di tab Cloud Shell yang sama dengan sesi SSH yang dibuka ke VM instance-1 Anda.
Gunakan nilai sandi AlloyDB (PGPASSWORD) yang dicatat dan ID cluster AlloyDB untuk terhubung ke AlloyDB dari VM GCE:
export PGPASSWORD=<Noted password>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export INSTANCE_IP=$(gcloud alloydb instances describe $ADBCLUSTER-pr --cluster=$ADBCLUSTER --region=$REGION --format="value(ipAddress)")
psql "host=$INSTANCE_IP user=postgres sslmode=require"
Output konsol yang diharapkan:
student@instance-1:~$ export PGPASSWORD=CQhOi5OygD4ps6ty student@instance-1:~$ ADBCLUSTER=alloydb-aip-01 student@instance-1:~$ REGION=us-central1 student@instance-1:~$ INSTANCE_IP=$(gcloud alloydb instances describe $ADBCLUSTER-pr --cluster=$ADBCLUSTER --region=$REGION --format="value(ipAddress)") gleb@instance-1:~$ psql "host=$INSTANCE_IP user=postgres sslmode=require" psql (15.6 (Debian 15.6-0+deb12u1), server 15.5) SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off) Type "help" for help. postgres=>
Tutup sesi psql:
exit
6. Menyiapkan Database
Kita perlu membuat database, mengaktifkan integrasi Vertex AI, membuat objek database, dan mengimpor data.
Memberikan Izin yang Diperlukan ke AlloyDB
Tambahkan izin Vertex AI ke agen layanan AlloyDB.
Buka tab Cloud Shell lain menggunakan tanda "+" di bagian atas.

Di tab Cloud Shell baru, jalankan:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Output konsol yang diharapkan:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Tutup tab dengan menjalankan perintah "exit" di tab:
exit
Buat Database
Mulai cepat pembuatan database.
Dalam sesi VM GCE, jalankan:
Buat database:
psql "host=$INSTANCE_IP user=postgres" -c "CREATE DATABASE quickstart_db"
Output konsol yang diharapkan:
student@instance-1:~$ psql "host=$INSTANCE_IP user=postgres" -c "CREATE DATABASE quickstart_db" CREATE DATABASE student@instance-1:~$
Mengaktifkan Integrasi Vertex AI
Aktifkan integrasi Vertex AI dan ekstensi pgvector di database.
Di VM GCE, jalankan:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE"
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS vector"
Output konsol yang diharapkan:
student@instance-1:~$ psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE" psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS vector" CREATE EXTENSION CREATE EXTENSION student@instance-1:~$
Impor Data
Download data yang telah disiapkan dan impor ke database baru.
Di VM GCE, jalankan:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_products from stdin csv header"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_inventory from stdin csv header"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_stores from stdin csv header"
Output konsol yang diharapkan:
student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_products from stdin csv header" COPY 941 student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_inventory from stdin csv header" COPY 263861 student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_stores from stdin csv header" COPY 4654 student@instance-1:~$
7. Menghitung embedding
Setelah mengimpor data, kita mendapatkan data produk di tabel cymbal_products, inventaris yang menunjukkan jumlah produk yang tersedia di setiap toko dalam tabel cymbal_inventory, dan daftar toko dalam tabel cymbal_stores. Kita perlu menghitung data vektor berdasarkan deskripsi produk dan kita akan menggunakan fungsi embedding untuk itu. Dengan menggunakan fungsi ini, kita akan menggunakan integrasi Vertex AI untuk menghitung data vektor berdasarkan deskripsi produk dan menambahkannya ke tabel. Anda dapat membaca lebih lanjut teknologi yang digunakan dalam dokumentasi.
Membuatnya untuk beberapa baris memang mudah, tetapi bagaimana cara membuatnya secara efisien jika ada ribuan baris? Di sini saya akan menunjukkan cara membuat dan mengelola embedding untuk tabel besar. Anda juga dapat membaca lebih lanjut berbagai opsi dan teknik dalam panduan.
Mengaktifkan Pembuatan Embedding Cepat
Hubungkan ke database menggunakan psql dari VM Anda menggunakan IP instance AlloyDB dan sandi postgres:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Verifikasi versi ekstensi google_ml_integration.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Versinya harus 1.5.2 atau yang lebih tinggi. Berikut adalah contoh output-nya:
quickstart_db=> SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration'; extversion ------------ 1.5.2 (1 row)
Versi default harus 1.5.2 atau yang lebih tinggi, tetapi jika instance Anda menampilkan versi yang lebih lama, instance tersebut mungkin perlu diupdate. Periksa apakah pemeliharaan dinonaktifkan untuk instance.
Kemudian, kita perlu memverifikasi tanda database. Kita perlu mengaktifkan tanda google_ml_integration.enable_faster_embedding_generation. Dalam sesi psql yang sama, periksa nilai untuk tanda.
show google_ml_integration.enable_faster_embedding_generation;
Jika tanda berada di posisi yang benar, output yang diharapkan akan terlihat seperti ini:
quickstart_db=> show google_ml_integration.enable_faster_embedding_generation; google_ml_integration.enable_faster_embedding_generation ---------------------------------------------------------- on (1 row)
Namun, jika menunjukkan "nonaktif", kita perlu mengupdate instance. Anda dapat melakukannya menggunakan konsol web atau perintah gcloud seperti yang dijelaskan dalam dokumentasi. Di sini saya menunjukkan cara melakukannya menggunakan perintah gcloud:
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags google_ml_integration.enable_faster_embedding_generation=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Mungkin perlu waktu beberapa menit, tetapi pada akhirnya nilai tanda akan diubah menjadi "aktif". Setelah itu, Anda dapat melanjutkan ke langkah berikutnya.
Membuat kolom embedding
Hubungkan ke database menggunakan psql dan buat kolom virtual dengan data vektor menggunakan fungsi embedding di tabel cymbal_products. Fungsi embedding menampilkan data vektor dari Vertex AI berdasarkan data yang diberikan dari kolom product_description.
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Di sesi psql setelah terhubung ke database, jalankan:
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768);
Perintah ini akan membuat kolom virtual dan mengisinya dengan data vektor.
Output konsol yang diharapkan:
quickstart_db=> ALTER TABLE cymbal_products ADD COLUMN embedding vector(768); ALTER TABLE quickstart_db=>
Sekarang kita dapat membuat embedding menggunakan batch dengan masing-masing 50 baris. Anda dapat bereksperimen dengan berbagai ukuran batch dan melihat apakah hal itu mengubah waktu eksekusi. Dalam sesi psql yang sama, jalankan:
Aktifkan pengaturan waktu untuk mengukur berapa lama waktu yang dibutuhkan:
\timing
Jalankan perintah:
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'embedding',
batch_size => 50
);
Output konsol menunjukkan kurang dari 2 detik untuk pembuatan penyematan:
quickstart_db=> CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'embedding',
batch_size => 50
);
NOTICE: Initialize embedding completed successfully for table cymbal_products
CALL
Time: 1458.704 ms (00:01.459)
quickstart_db=>
Secara default, sematan tidak akan diperbarui jika kolom product_description yang sesuai diperbarui atau seluruh baris baru dimasukkan. Namun, Anda dapat melakukannya dengan menentukan parameter incremental_refresh_mode. Buat kolom "product_embeddings" dan buat agar dapat diperbarui secara otomatis.
ALTER TABLE cymbal_products ADD COLUMN product_embedding vector(768);
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'product_embedding',
batch_size => 50,
incremental_refresh_mode => 'transactional'
);
Sekarang, jika kita menyisipkan baris baru ke tabel.
INSERT INTO "cymbal_products" ("uniq_id", "crawl_timestamp", "product_url", "product_name", "product_description", "list_price", "sale_price", "brand", "item_number", "gtin", "package_size", "category", "postal_code", "available", "product_embedding", "embedding") VALUES ('fd604542e04b470f9e6348e640cff794', NOW(), 'https://example.com/new_product', 'New Cymbal Product', 'This is a new cymbal product description.', 199.99, 149.99, 'Example Brand', 'EB123', '1234567890', 'Single', 'Cymbals', '12345', TRUE, NULL, NULL);
Kita dapat membandingkan perbedaan di kolom menggunakan kueri:
SELECT uniq_id,embedding, (product_embedding::real[])[1:5] as product_embedding FROM cymbal_products WHERE uniq_id='fd604542e04b470f9e6348e640cff794';
Dalam output, kita dapat melihat bahwa meskipun kolom embedding tetap kosong, kolom product_embedding diperbarui secara otomatis
quickstart_db=> SELECT uniq_id,embedding, (product_embedding::real[])[1:5] as product_embedding FROM cymbal_products WHERE uniq_id='fd604542e04b470f9e6348e640cff794';
uniq_id | embedding | product_embedding
----------------------------------+-----------+---------------------------------------------------------------
fd604542e04b470f9e6348e640cff794 | | {0.015003494,-0.005349732,-0.059790313,-0.0087091,-0.0271452}
(1 row)
Time: 3.295 ms
8. Menjalankan Penelusuran Kemiripan
Sekarang kita dapat menjalankan penelusuran menggunakan penelusuran kemiripan berdasarkan nilai vektor yang dihitung untuk deskripsi dan nilai vektor yang kita dapatkan untuk permintaan kita.
Kueri SQL dapat dijalankan dari antarmuka command line psql yang sama atau, sebagai alternatif, dari AlloyDB Studio. Output multi-baris dan kompleks apa pun mungkin terlihat lebih baik di AlloyDB Studio.
Menghubungkan ke AlloyDB Studio
Di bab-bab berikutnya, semua perintah SQL yang memerlukan koneksi ke database dapat dijalankan secara alternatif di AlloyDB Studio. Untuk menjalankan perintah, Anda harus membuka antarmuka konsol web untuk cluster AlloyDB dengan mengklik instance utama.

Kemudian, klik AlloyDB Studio di sebelah kiri:

Pilih database quickstart_db, pengguna postgres, dan berikan sandi yang dicatat saat kita membuat cluster. Kemudian, klik tombol "Autentikasi".
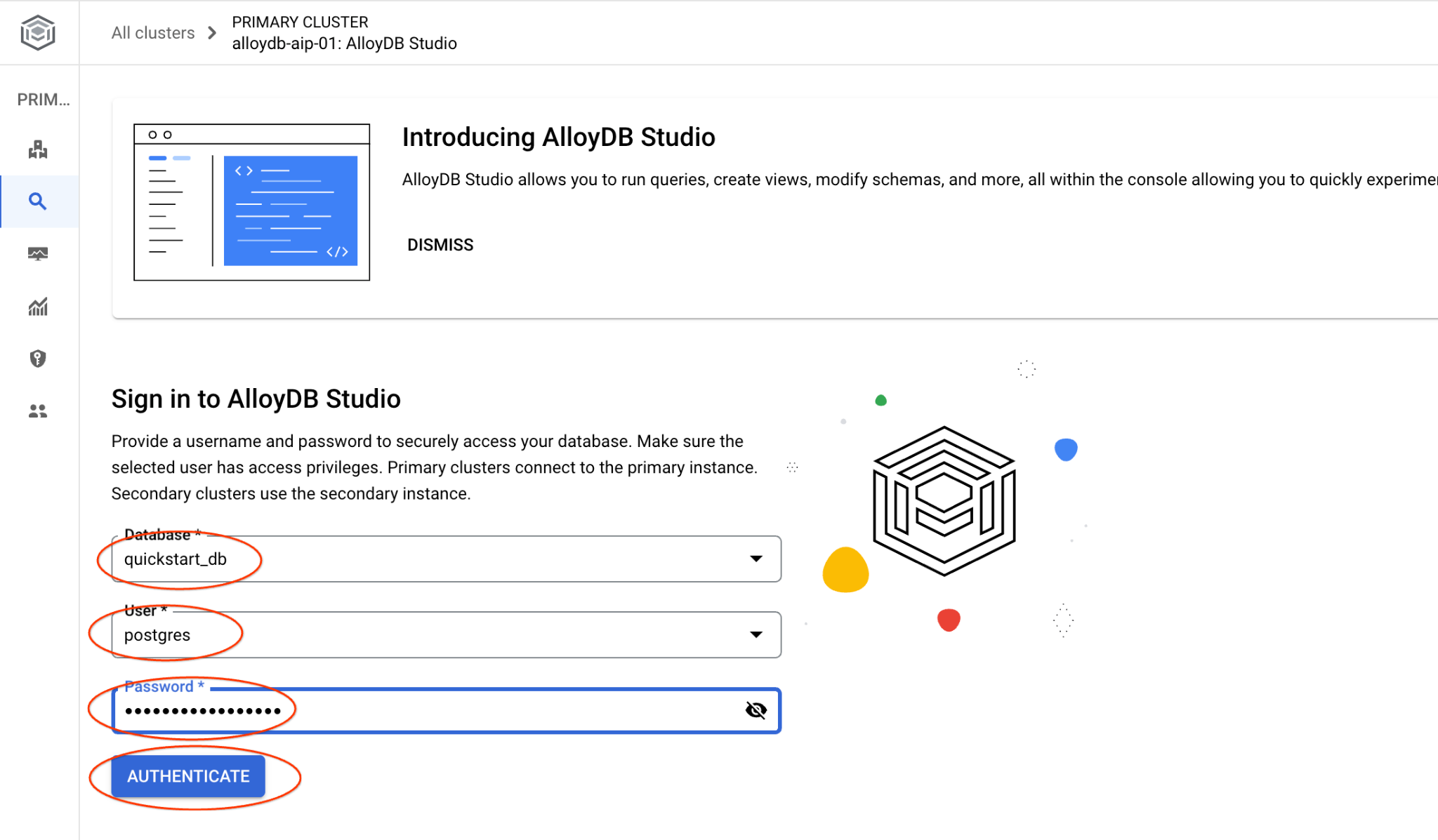
Tindakan ini akan membuka antarmuka AlloyDB Studio. Untuk menjalankan perintah di database, klik tab "Editor 1" di sebelah kanan.

Tindakan ini akan membuka antarmuka tempat Anda dapat menjalankan perintah SQL

Jika Anda lebih suka menggunakan psql command line, ikuti rute alternatif dan hubungkan ke database dari sesi SSH VM Anda seperti yang telah dijelaskan di bab sebelumnya.
Menjalankan Penelusuran Kemiripan dari psql
Jika sesi database Anda terputus, hubungkan kembali ke database menggunakan psql atau AlloyDB Studio.
Hubungkan ke database:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Jalankan kueri untuk mendapatkan daftar produk yang tersedia dan paling terkait dengan permintaan klien. Permintaan yang akan kita teruskan ke Vertex AI untuk mendapatkan nilai vektornya adalah "Jenis pohon buah apa yang tumbuh dengan baik di sini?"
Berikut kueri yang dapat Anda jalankan untuk memilih 10 item pertama yang paling sesuai untuk permintaan kami:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
Berikut output yang diharapkan:
quickstart_db=> SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
product_name | description | sale_price | zip_code | distance
-------------------------+----------------------------------------------------------------------------------+------------+----------+---------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.43922018972266397
Meyer Lemon Tree | Meyer Lemon trees are California's favorite lemon tree! Grow your own lemons by | 34 | 93230 | 0.4685112926118228
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.4835677149651668
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.4947204525907498
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5054166905547247
California Black Walnut | This is a beautiful walnut tree that can grow to be over 80 feet tall. It is a d | 100.00 | 93230 | 0.5084219510932597
California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.5140519790508755
Coast Live Oak | This is a beautiful oak tree that can grow to be over 100 feet tall. It is an ev | 500.00 | 93230 | 0.5143126438081371
Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.5174774727252058
Madrone | This is a beautiful madrona tree that can grow to be over 80 feet tall. It is an | 50.00 | 93230 | 0.5227400803389093
9. Tingkatkan Kualitas Respons
Anda dapat meningkatkan kualitas respons ke aplikasi klien menggunakan hasil kueri dan menyiapkan output yang bermakna menggunakan hasil kueri yang diberikan sebagai bagian dari perintah ke model bahasa dasar generatif Vertex AI.
Untuk mencapainya, kami berencana membuat JSON dengan hasil dari penelusuran vektor, lalu menggunakan JSON yang dibuat tersebut sebagai tambahan pada perintah untuk model LLM teks di Vertex AI guna membuat output yang bermakna. Pada langkah pertama, kita membuat JSON, lalu mengujinya di Vertex AI Studio, dan pada langkah terakhir, kita menggabungkannya ke dalam pernyataan SQL yang dapat digunakan dalam aplikasi.
Membuat output dalam format JSON
Ubah kueri untuk menghasilkan output dalam format JSON dan hanya menampilkan satu baris untuk diteruskan ke Vertex AI
Berikut adalah contoh kuerinya:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Berikut adalah JSON yang diharapkan dalam output:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Menjalankan perintah di Vertex AI Studio
Kita dapat menggunakan JSON yang dihasilkan untuk menyediakannya sebagai bagian dari perintah ke model teks AI generatif di Vertex AI Studio
Buka Vertex AI Studio di konsol cloud.

Aplikasi mungkin meminta Anda menyetujui persyaratan penggunaan jika Anda belum pernah menggunakannya. Tekan tombol "Setuju & lanjutkan"
Tulis perintah Anda di antarmuka.
Aplikasi ini mungkin meminta Anda mengaktifkan API tambahan, tetapi Anda dapat mengabaikan permintaan tersebut. Kita tidak memerlukan API tambahan untuk menyelesaikan lab ini.
Berikut perintah yang akan kita gunakan dengan output JSON dari kueri awal tentang pohon:
Anda adalah penasihat yang ramah dan membantu menemukan produk berdasarkan kebutuhan pelanggan.
Berdasarkan permintaan klien, kami telah memuat daftar produk yang terkait erat dengan penelusuran.
Daftar dalam format JSON dengan daftar nilai seperti {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Berikut daftar produknya:
{"product_name":"Cherry Tree","description":"Ini adalah pohon ceri yang indah dan akan menghasilkan ceri yang lezat. Ini adalah d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}
Pelanggan bertanya "Pohon apa yang tumbuh paling baik di sini?"
Anda harus memberikan informasi tentang produk, harga, dan beberapa informasi tambahan

Berikut adalah hasilnya saat kita menjalankan perintah dengan nilai JSON dan menggunakan model gemini-2.5-flash-light:

Jawaban yang kita dapatkan dari model dalam contoh ini adalah sebagai berikut. Perhatikan bahwa jawaban Anda mungkin berbeda karena perubahan model dan parameter dari waktu ke waktu:
"Berdasarkan produk yang tersedia, berikut informasi yang dapat saya berikan tentang "Cherry Tree":
Produk: Cherry Tree
Harga: $75,00
Deskripsi: Ini adalah pohon ceri yang indah dan akan menghasilkan ceri yang lezat.
Untuk menentukan pohon mana yang "tumbuh paling baik di sini", kami memerlukan informasi lebih lanjut. Apakah Anda memiliki pohon lain yang tercantum yang dapat kami bandingkan, atau apakah ada aspek tertentu dari "pertumbuhan terbaik" yang Anda minati (misalnya, pertumbuhan tercepat, produksi buah terbanyak, ketahanan dalam iklim khusus Anda)?"
Jalankan perintah di PSQL
Kita dapat menggunakan integrasi AI AlloyDB dengan Vertex AI untuk mendapatkan respons yang sama dari model generatif menggunakan SQL langsung di database. Namun, untuk menggunakan model gemini-1.5-flash, kita harus mendaftarkannya terlebih dahulu.
Verifikasi ekstensi google_ml_integration. Harus memiliki versi 1.4.2 atau yang lebih baru.
Hubungkan ke database quickstart_db dari psql seperti yang telah ditunjukkan sebelumnya (atau gunakan AlloyDB Studio) dan jalankan:
SELECT extversion from pg_extension where extname='google_ml_integration';
Periksa tanda database google_ml_integration.enable_model_support.
show google_ml_integration.enable_model_support;
Output yang diharapkan dari sesi psql adalah "on":
postgres=> show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
Jika menunjukkan "nonaktif", kita perlu menyetel tanda database google_ml_integration.enable_model_support ke "aktif". Untuk melakukannya, Anda dapat menggunakan antarmuka konsol web AlloyDB atau menjalankan perintah gcloud berikut.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags google_ml_integration.enable_faster_embedding_generation=on,google_ml_integration.enable_model_support=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Perintah ini memerlukan waktu sekitar 1-3 menit untuk dijalankan di latar belakang. Kemudian, Anda dapat memverifikasi tanda tersebut lagi.
Untuk kueri ini, kita memerlukan dua model. Yang pertama adalah model text-embedding-005 yang sudah digunakan dan yang kedua adalah salah satu model gemini generik Google.
Kita mulai dari model penyematan teks. Untuk mendaftarkan model yang berjalan di psql atau AlloyDB Studio, jalankan kode berikut:
CALL
google_ml.create_model(
model_id => 'text-embedding-005',
model_provider => 'google',
model_qualified_name => 'text-embedding-005',
model_type => 'text_embedding',
model_auth_type => 'alloydb_service_agent_iam',
model_in_transform_fn => 'google_ml.vertexai_text_embedding_input_transform',
model_out_transform_fn => 'google_ml.vertexai_text_embedding_output_transform');
Model berikutnya yang perlu kita daftarkan adalah gemini-2.0-flash-001 yang akan digunakan untuk menghasilkan output yang mudah digunakan.
CALL
google_ml.create_model(
model_id => 'gemini-2.5-flash',
model_request_url => 'publishers/google/models/gemini-2.5-flash:streamGenerateContent',
model_provider => 'google',
model_auth_type => 'alloydb_service_agent_iam');
Anda selalu dapat memverifikasi daftar model terdaftar dengan memilih informasi dari google_ml.model_info_view.
select model_id,model_type from google_ml.model_info_view;
Berikut contoh output
quickstart_db=> select model_id,model_type from google_ml.model_info_view;
model_id | model_type
-------------------------+----------------
textembedding-gecko | text_embedding
textembedding-gecko@001 | text_embedding
text-embedding-005 | text_embedding
gemini-2.5-flash | generic
(4 rows)
Sekarang kita dapat menggunakan JSON yang dihasilkan dalam subkueri untuk menyediakannya sebagai bagian dari perintah ke model teks AI generatif menggunakan SQL.
Dalam sesi psql atau AlloyDB Studio ke database, jalankan kueri
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005',
'What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1),
prompt AS (
SELECT
'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:' || json_agg(trees) || 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information' AS prompt_text
FROM
trees),
response AS (
SELECT
json_array_elements(google_ml.predict_row( model_id =>'gemini-2.5-flash',
request_body => json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text',
prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT
string_agg(resp::text,
' ')
FROM
response;
Berikut adalah output yang diharapkan. Output Anda mungkin berbeda bergantung pada versi dan parameter model.:
"Hello there! I can certainly help you with finding a great fruit tree for your area.\n\nBased on what grows well, we have a wonderful **Cherry Tree** that could be a perfect fit!\n\nThis beautiful cherry tree is an excellent choice for producing delicious cherries right in your garden. It's an deciduous tree that typically" " grows to about 15 feet tall. Beyond its fruit, it offers lovely aesthetics with dark green leaves in the summer that transition to a beautiful red in the fall, making it great for shade and privacy too.\n\nCherry trees generally prefer a cool, moist climate and sandy soil, and they are best suited for USDA Zones" " 4-9. Given the zip code you're inquiring about (93230), which is typically in USDA Zone 9, this Cherry Tree should thrive wonderfully!\n\nYou can get this magnificent tree for just **$75.00**.\n\nLet me know if you have any other questions!" "
10. Membuat indeks vektor
Set data kami cukup kecil dan waktu respons terutama bergantung pada interaksi dengan model AI. Namun, jika Anda memiliki jutaan vektor, bagian penelusuran vektor dapat memakan sebagian besar waktu respons kami dan memberikan beban yang tinggi pada sistem. Untuk meningkatkan kualitasnya, kita dapat membuat indeks di atas vektor.
Buat indeks ScaNN
Untuk membuat indeks SCANN, kita perlu mengaktifkan satu ekstensi lagi. Ekstensi alloydb_scann menyediakan antarmuka untuk bekerja dengan indeks vektor jenis ANN menggunakan algoritma ScaNN Google.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Output yang diharapkan:
quickstart_db=> CREATE EXTENSION IF NOT EXISTS alloydb_scann; CREATE EXTENSION Time: 27.468 ms quickstart_db=>
Indeks dapat dibuat dalam mode MANUAL atau AUTO. Mode MANUAL diaktifkan secara default dan Anda dapat membuat indeks serta mempertahankannya seperti indeks lainnya. Namun, jika Anda mengaktifkan mode OTOMATIS, Anda dapat membuat indeks yang tidak memerlukan pemeliharaan apa pun dari pihak Anda. Anda dapat membaca semua opsi secara mendetail dalam dokumentasi dan di sini saya akan menunjukkan cara mengaktifkan mode AUTO dan membuat indeks. Dalam kasus ini, kita tidak memiliki cukup baris untuk membuat indeks dalam mode OTOMATIS - jadi kita akan membuatnya sebagai MANUAL.
Dalam contoh berikut, saya membiarkan sebagian besar parameter sebagai default dan hanya memberikan jumlah partisi (num_leaves) untuk indeks:
CREATE INDEX cymbal_products_embeddings_scann ON cymbal_products
USING scann (embedding cosine)
WITH (num_leaves=31, max_num_levels = 2);
Anda dapat membaca tentang menyetel parameter indeks di dokumentasi.
Output yang diharapkan:
quickstart_db=> CREATE INDEX cymbal_products_embeddings_scann ON cymbal_products USING scann (embedding cosine) WITH (num_leaves=31, max_num_levels = 2); CREATE INDEX quickstart_db=>
Bandingkan Respons
Sekarang kita dapat menjalankan kueri penelusuran vektor dalam mode EXPLAIN dan memverifikasi apakah indeks telah digunakan.
EXPLAIN (analyze)
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Output yang diharapkan (disamarkan agar lebih jelas):
... Aggregate (cost=16.59..16.60 rows=1 width=32) (actual time=2.875..2.877 rows=1 loops=1) -> Subquery Scan on trees (cost=8.42..16.59 rows=1 width=142) (actual time=2.860..2.862 rows=1 loops=1) -> Limit (cost=8.42..16.58 rows=1 width=158) (actual time=2.855..2.856 rows=1 loops=1) -> Nested Loop (cost=8.42..6489.19 rows=794 width=158) (actual time=2.854..2.855 rows=1 loops=1) -> Nested Loop (cost=8.13..6466.99 rows=794 width=938) (actual time=2.742..2.743 rows=1 loops=1) -> Index Scan using cymbal_products_embeddings_scann on cymbal_products cp (cost=7.71..111.99 rows=876 width=934) (actual time=2.724..2.724 rows=1 loops=1) Order By: (embedding <=> '[0.008864171,0.03693164,-0.024245683,-0.00355923,0.0055611245,0.015985578,...<redacted>...5685,-0.03914233,-0.018452475,0.00826032,-0.07372604]'::vector) -> Index Scan using walmart_inventory_pkey on cymbal_inventory ci (cost=0.42..7.26 rows=1 width=37) (actual time=0.015..0.015 rows=1 loops=1) Index Cond: ((store_id = 1583) AND (uniq_id = (cp.uniq_id)::text)) ...
Dari output, kita dapat melihat dengan jelas bahwa kueri menggunakan "Index Scan using cymbal_products_embeddings_scann on cymbal_products".
Dan jika kita menjalankan kueri tanpa explain:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Output yang diharapkan:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Kita dapat melihat bahwa hasilnya adalah pohon Ceri yang sama yang berada di bagian atas penelusuran kami tanpa indeks. Terkadang, hal ini mungkin tidak terjadi dan respons dapat menampilkan bukan pohon yang sama, tetapi beberapa pohon lain dari atas. Jadi, indeks ini memberikan performa yang cukup akurat untuk memberikan hasil yang baik.
Anda dapat mencoba berbagai indeks yang tersedia untuk vektor serta lab dan contoh lainnya dengan integrasi langchain yang tersedia di halaman dokumentasi.
11. Membersihkan lingkungan
Hancurkan instance dan cluster AlloyDB setelah Anda selesai mengerjakan lab.
Hapus cluster AlloyDB dan semua instance
Jika Anda telah menggunakan versi uji coba AlloyDB. Jangan hapus cluster uji coba jika Anda berencana menguji lab dan resource lain menggunakan cluster uji coba. Anda tidak akan dapat membuat cluster uji coba lain dalam project yang sama.
Cluster tersebut dihancurkan dengan opsi paksa yang juga akan menghapus semua instance milik cluster tersebut.
Di Cloud Shell, tentukan variabel project dan lingkungan jika koneksi Anda terputus dan semua setelan sebelumnya hilang:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Hapus cluster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Output konsol yang diharapkan:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
Hapus Cadangan AlloyDB
Hapus semua cadangan AlloyDB untuk cluster:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Output konsol yang diharapkan:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
Sekarang kita bisa menghancurkan VM
Hapus VM GCE
Di Cloud Shell, jalankan:
export GCEVM=instance-1
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Output konsol yang diharapkan:
student@cloudshell:~ (test-project-001-402417)$ export GCEVM=instance-1
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Deleted
12. Selamat
Selamat, Anda telah menyelesaikan codelab.
Lab ini merupakan bagian dari Alur Pembelajaran AI Siap Produksi dengan Google Cloud.
- Jelajahi kurikulum lengkap untuk menjembatani kesenjangan dari prototipe hingga produksi.
- Bagikan progres Anda dengan hashtag
#ProductionReadyAI.
Yang telah kita bahas
- Cara men-deploy cluster dan instance utama AlloyDB
- Cara terhubung ke AlloyDB dari VM Google Compute Engine
- Cara membuat database dan mengaktifkan AlloyDB AI
- Cara memuat data ke database
- Cara menggunakan AlloyDB Studio
- Cara menggunakan model embedding Vertex AI di AlloyDB
- Cara menggunakan Vertex AI Studio
- Cara memperkaya hasil menggunakan model generatif Vertex AI
- Cara meningkatkan performa menggunakan indeks vektor
13. Survei
Output: