
1. はじめに
「金魚」問題
東京への理想の旅行を計画するために、旅行代理店に依頼したとします。セッション エージェントを使用して、「金魚問題」の動作を確認します。
オフィスに入って、次のように言います。
「お世話になっております。東京への 2 日間の旅行を計画したい。史跡と寿司に興味があります。」
エージェントは次のように熱心に返信します。
「ありがとうございます。では、皇居の見学と、すきやばし次郎での寿司ディナーを計画しています。」
笑顔で次のように言います。
「それはいいですね。旅程を送ってもらえますか?」
エージェントはあなたをぼんやりと見つめ、こう尋ねます。
「お世話になっております。本日はどのようなご用件でしょうか?」
これは「金魚問題」です。記憶機能がない場合、すべてのインタラクションは空白の状態から始まります。インテリジェンスは存在します。エージェントは旅行の計画方法を知っていますが、継続性がありません。AI エージェントが真に有用であるためには、記憶する必要があります。
今日のミッション
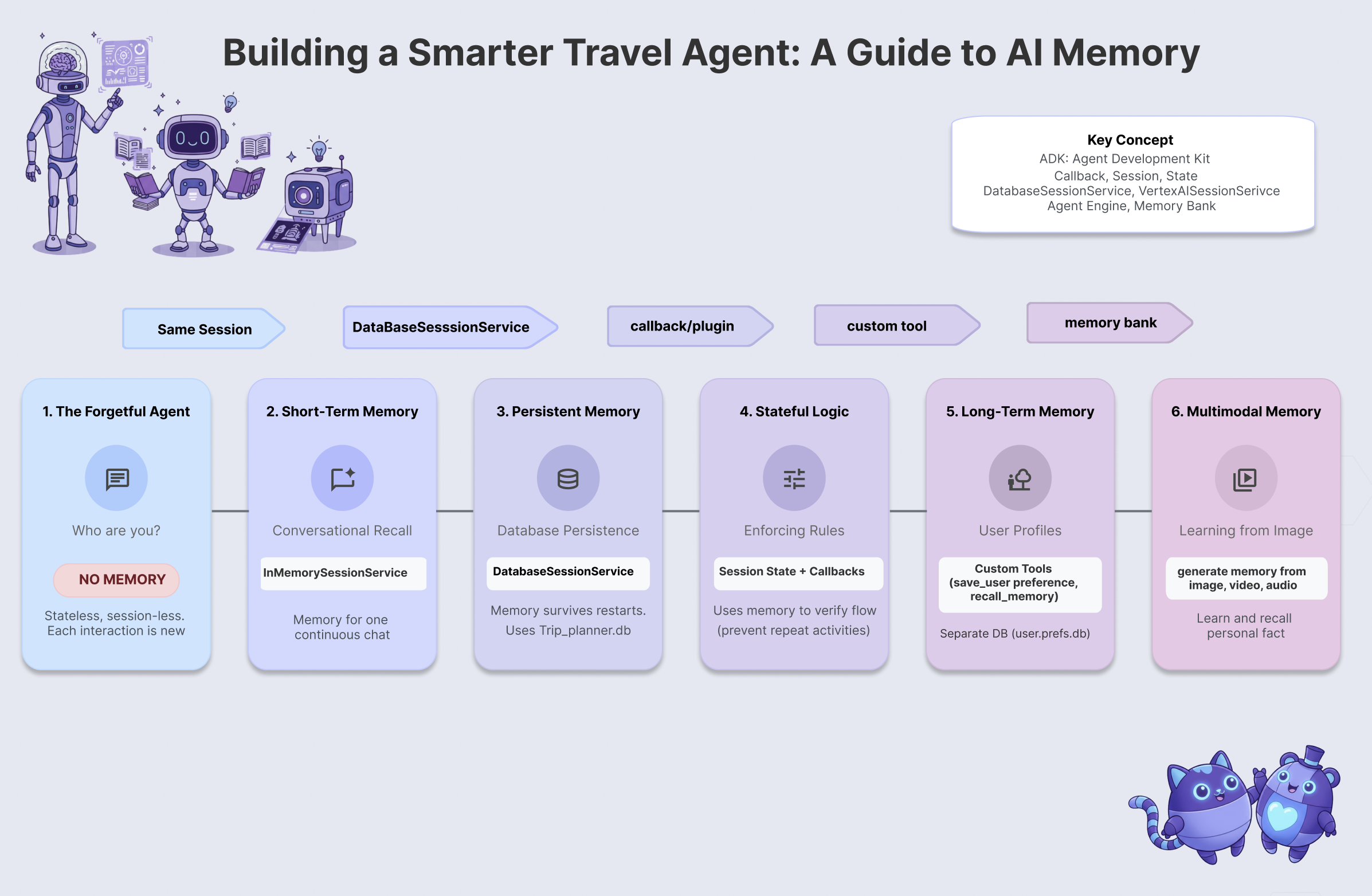
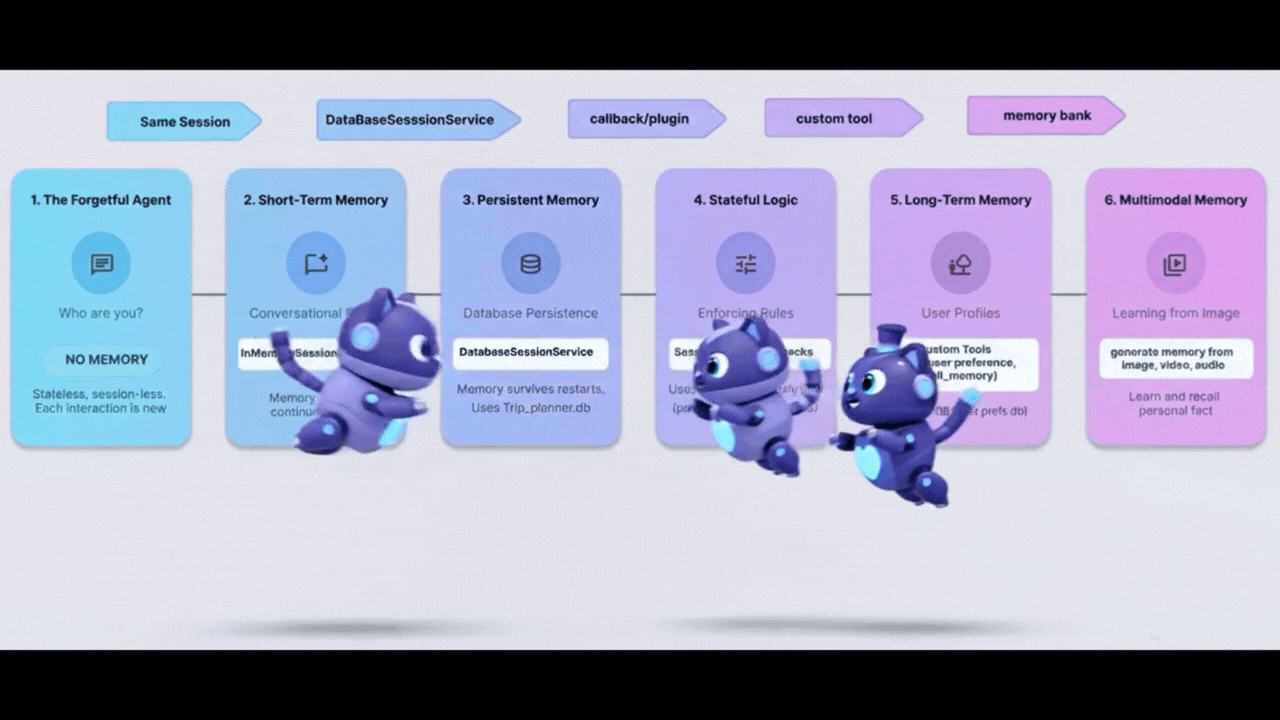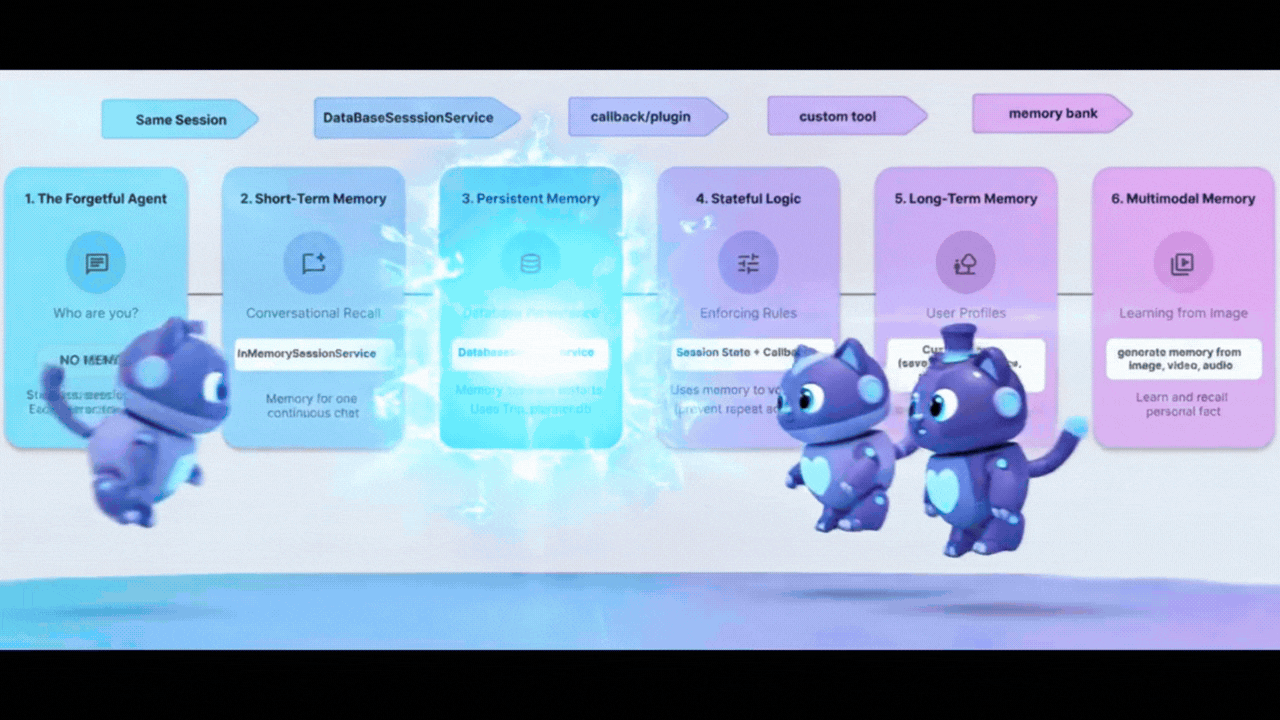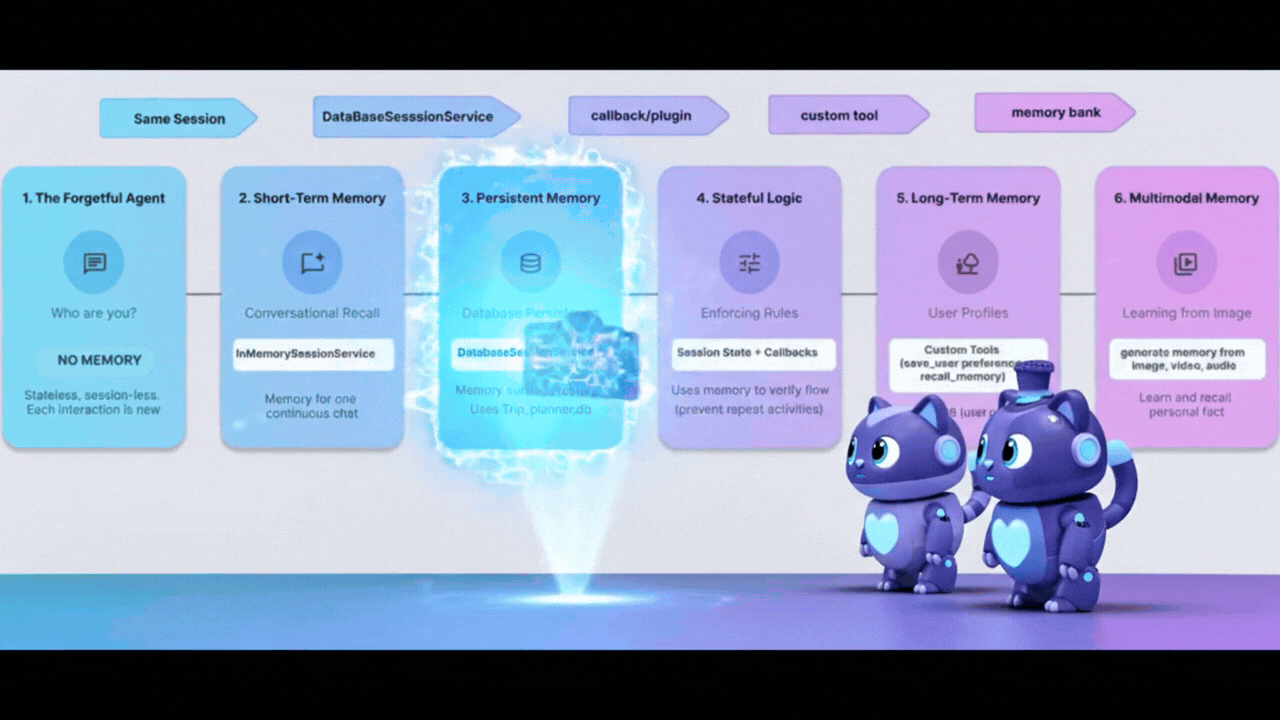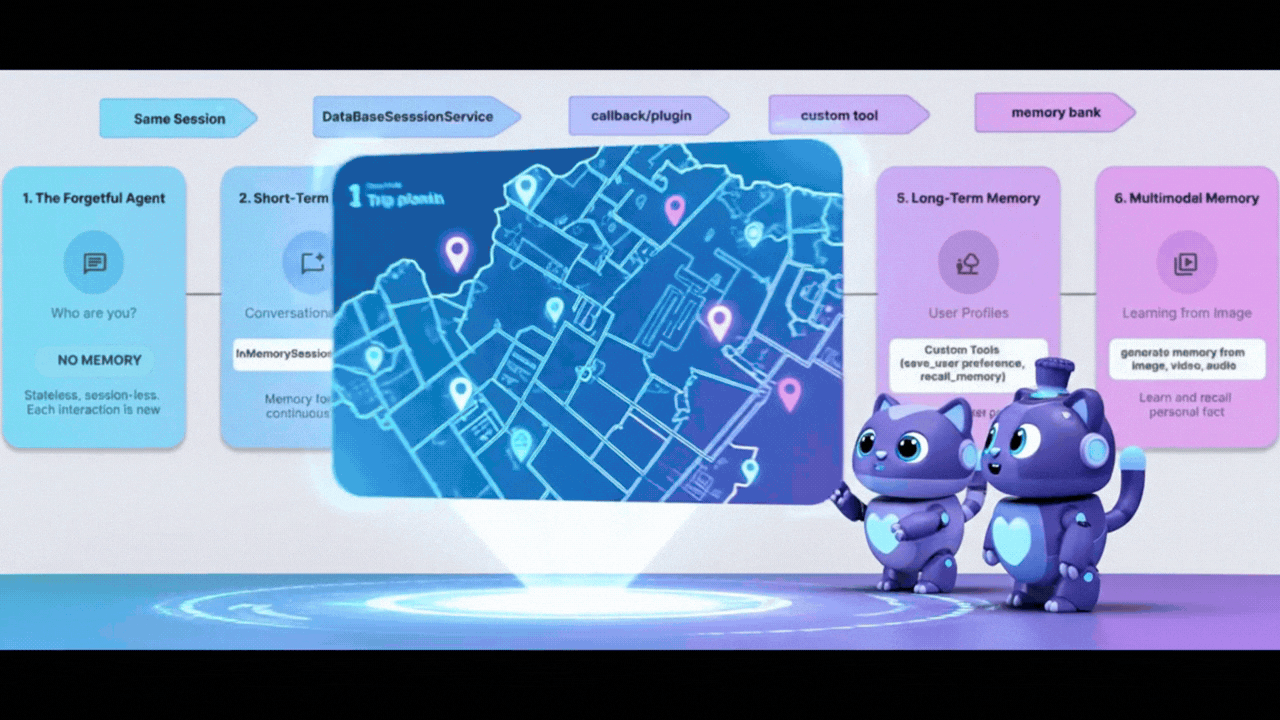
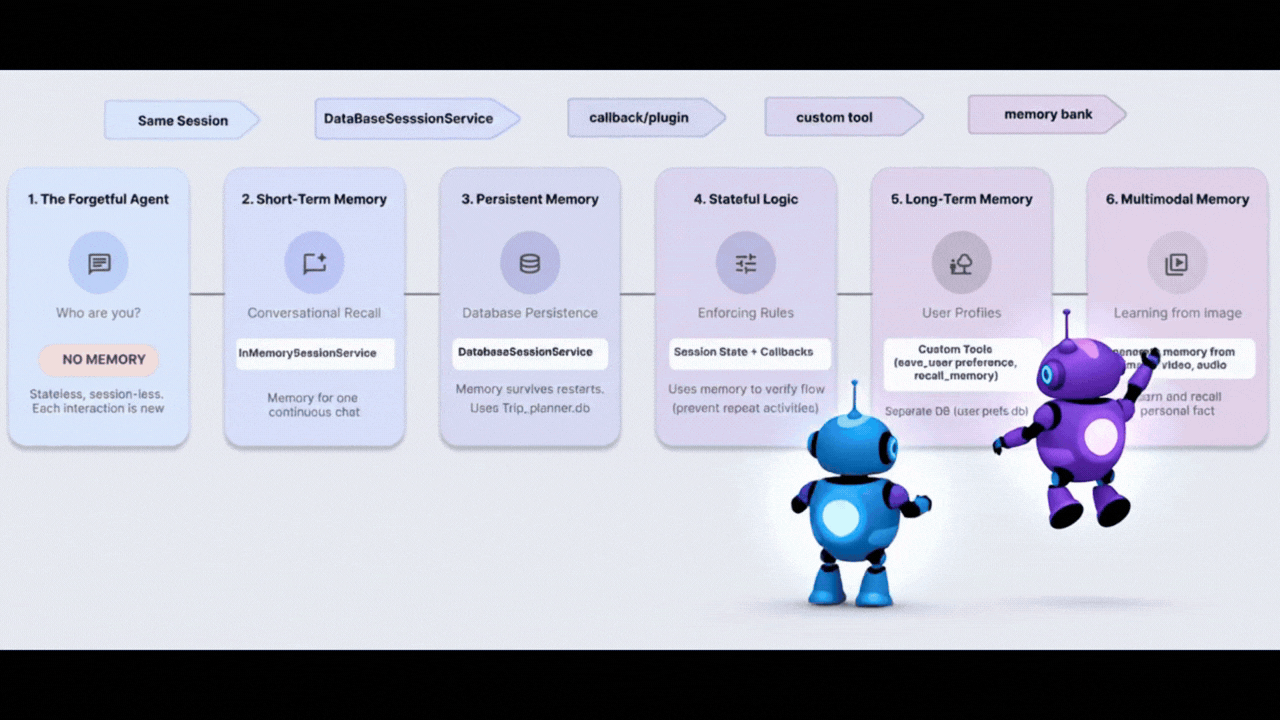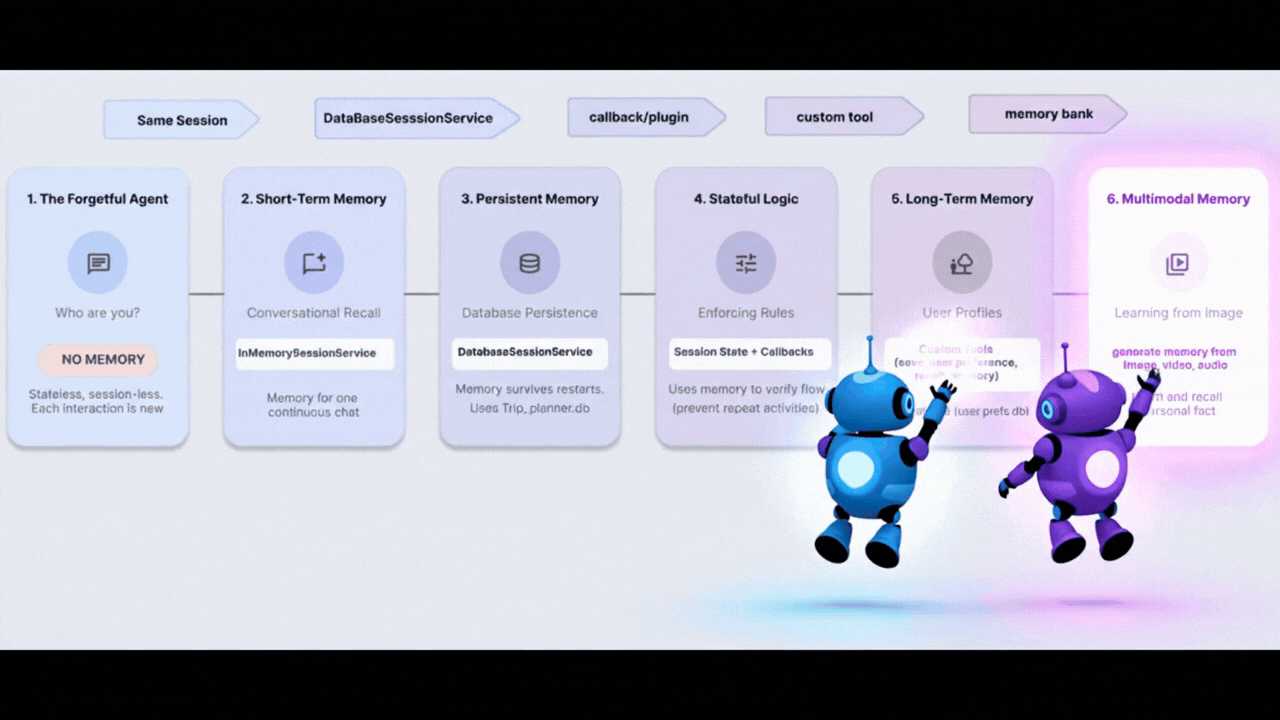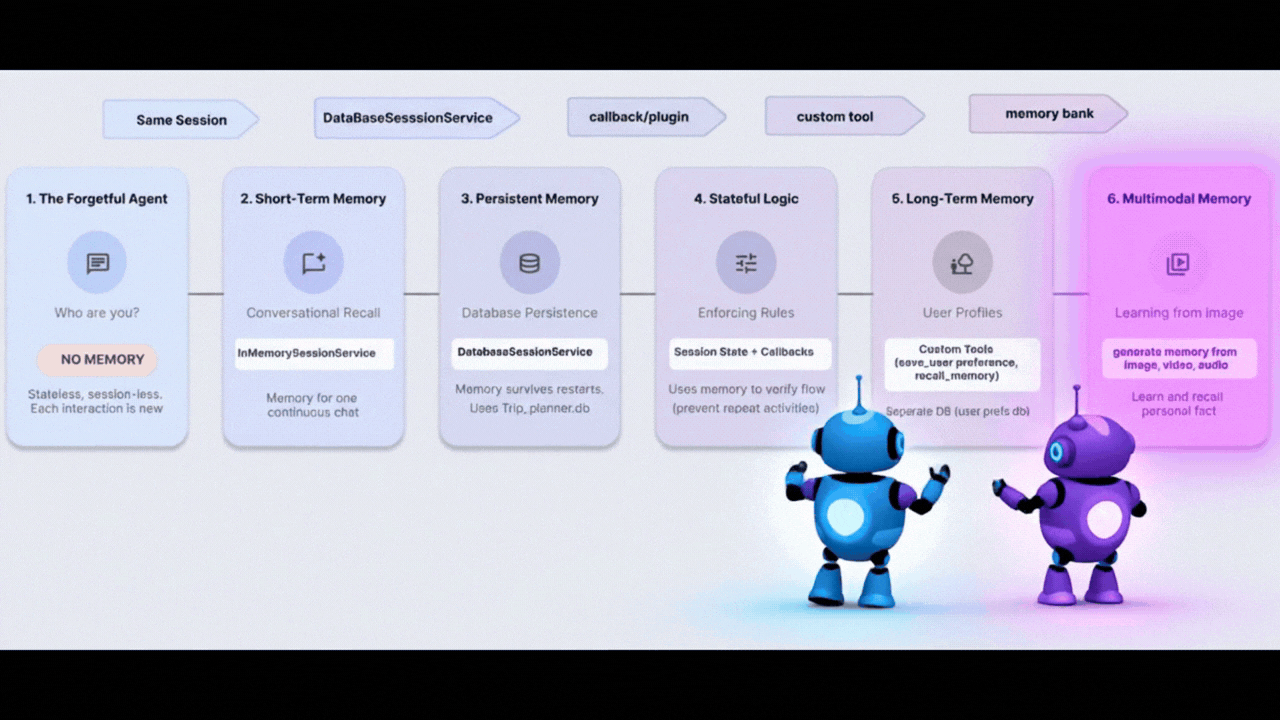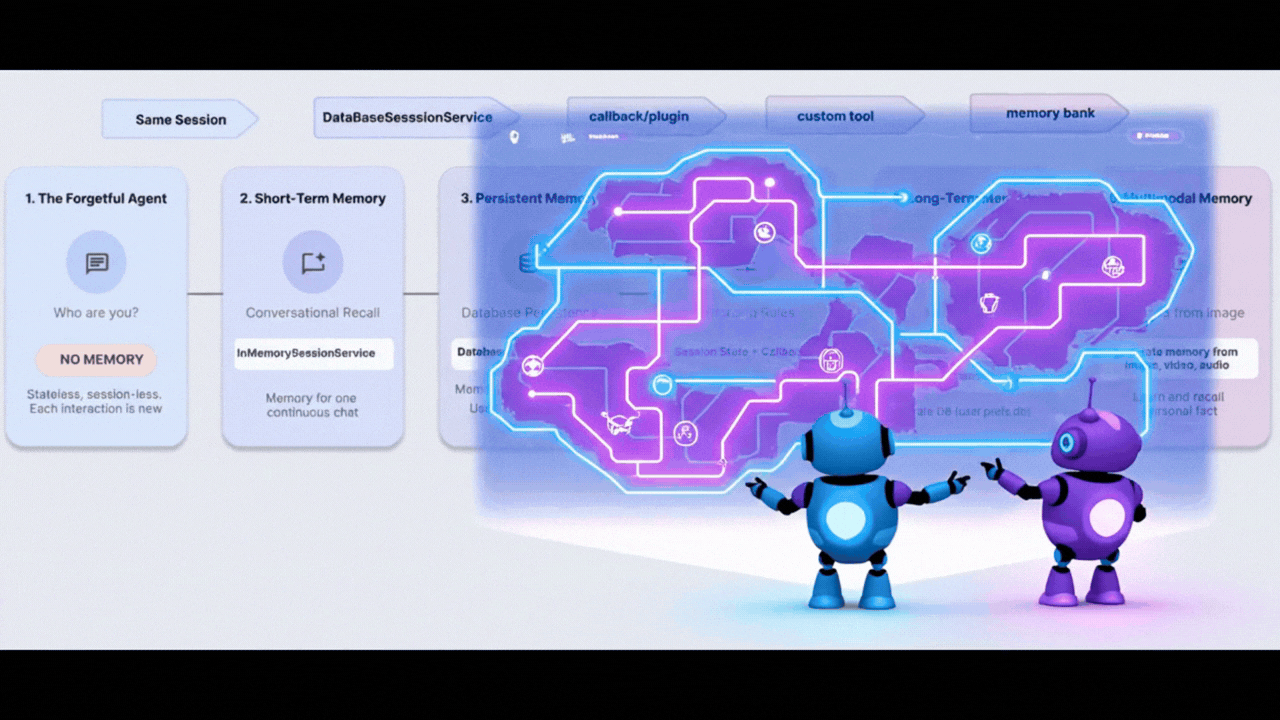
このワークショップでは、記憶、学習、適応を行う旅行代理店を構築して、金魚の問題を解決します。6 つのエージェント メモリレベルを進めて、チャットボットではなく、専用のパーソナル アシスタントのように動作するシステムを作成します。
レベル | コンセプト | 「Superpower」 |
レベル 1 | セッションと状態 | 忘れることなく会話を続ける |
レベル 2 | Multi-Agent State | チームメンバー間でメモを共有する |
レベル 3 | 永続性 | システムの再起動後もユーザーを記憶する |
レベル 4 | Callbacks | メモリを完全に自律的に更新する |
レベル 5 | カスタムツール | 構造化されたユーザー プロファイルの読み取りと書き込み |
レベル 6 | マルチモーダル メモリ | 写真や動画を「見て」記憶する |
ADK メモリスタック
コードを記述する前に、使用するツールについて理解しましょう。Google Agent Development Kit(ADK)は、メモリを処理するための構造化された方法を提供します。
- セッション: 会話のコンテナ。発言内容の履歴が保持されます。
- 状態: セッションに関連付けられた Key-Value の「スクラッチパッド」。エージェントは、特定の事実(
destination="Tokyo")。 - MemoryService: 長期保存。ユーザー設定や分析されたドキュメントなど、永続的に保存するデータがここに保存されます。
2. セットアップ
AI エージェントを強化するには、基盤となる Google Cloud プロジェクトが必要です。
パート 1: 請求先アカウントを有効にする
- デプロイには、5 ドルのクレジット付きの請求先アカウントが必要です。Gmail アカウントであることを確認します。
パート 2: オープン環境
- 👉 このリンクをクリックすると、Cloud Shell エディタに直接移動します。
- 👉 今日、どこかの時点で承認を求められた場合は、[承認] をクリックして続行します。
- 👉 画面下部にターミナルが表示されない場合は、ターミナルを開きます。
- [表示] をクリックします。
- [ターミナル] をクリックします。

- 👉💻 ターミナルで、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list - 👉💻 GitHub からブートストラップ プロジェクトのクローンを作成します。
git clone https://github.com/cuppibla/memory_agent_starter - 👉💻 プロジェクト ディレクトリから設定スクリプトを実行します。
cd ~/memory_agent_starter ./init.sh - 👉💻 必要なプロジェクト ID を設定します。
gcloud config set project $(cat ~/project_id.txt) --quiet
パート 3: 権限の設定
- 👉💻 次のコマンドを使用して、必要な API を有効にします。これには数分かかることがあります。
gcloud services enable \ cloudresourcemanager.googleapis.com \ servicenetworking.googleapis.com \ run.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - 👉💻 ターミナルで次のコマンドを実行して、必要な権限を付与します。
. ~/memory_agent_starter/set_env.sh
.env ファイルが作成されていることに注目してください。プロジェクト情報が表示されます。
3. 基盤 - セッションと状態
コンセプト: コンテキストが最重要
メモリの最も基本的な形式は、セッション メモリです。これにより、エージェントは「靴を買いたい」という文の「靴」が、10 秒前に話していた靴を指していることを認識できます。
ADK では、Session オブジェクトを使用してこれを管理します。
- ステートレス アプローチ: メッセージごとに新しいセッションを作成します。
- ステートフル アプローチ: 1 つのセッションを作成し、会話全体で再利用します。
ステップ 1: エージェントを調べる
👉💻 Cloud Shell ターミナルで、次のコマンドを実行して Cloud Shell エディタでファイルを開きます。
cloudshell edit ~/memory_agent_starter/01_session_agent/agent.py
~/memory_agent_starter/01_session_agent/agent.py を開きます。
👉 agent.py 関数内のコメント # TODO: Create a root agent を見つけます。
この行全体を次のコードに置き換えます。
root_agent = LlmAgent(
name="multi_day_trip_agent",
model="gemini-2.5-flash",
description="Agent that progressively plans a multi-day trip, remembering previous days and adapting to user feedback.",
instruction="""
You are the "Adaptive Trip Planner" 🗺️ - an AI assistant that builds multi-day travel itineraries step-by-step.
Your Defining Feature:
You have short-term memory. You MUST refer back to our conversation to understand the trip's context, what has already been planned, and the user's preferences. If the user asks for a change, you must adapt the plan while keeping the unchanged parts consistent.
Your Mission:
1. **Initiate**: Start by asking for the destination, trip duration, and interests.
2. **Plan Progressively**: Plan ONLY ONE DAY at a time. After presenting a plan, ask for confirmation.
3. **Handle Feedback**: If a user dislikes a suggestion (e.g., "I don't like museums"), acknowledge their feedback, and provide a *new, alternative* suggestion for that time slot that still fits the overall theme.
4. **Maintain Context**: For each new day, ensure the activities are unique and build logically on the previous days. Do not suggest the same things repeatedly.
5. **Final Output**: Return each day's itinerary in MARKDOWN format.
""",
tools=[google_search]
)
この指示は LLM に記憶するよう伝えていますが、コードは記憶する機能を備えている必要があります。
ステップ 2: 2 つのシナリオ
~/memory_agent_starter/01_session_agent/main.py を開きます。
👉 Cloud Shell ターミナルで、次のコマンドを実行して Cloud Shell エディタでファイルを開きます。
cloudshell edit ~/memory_agent_starter/01_session_agent/main.py
~/memory_agent_starter/01_session_agent/main.py を開き、main.py 関数内のコメント # TODO: Create a runner with in memorysession service を見つけます。
この行全体を次のコードに置き換えます。
runner = Runner(
agent=agent,
session_service=session_service,
app_name=agent.name
)
👉 main.py 関数内のコメント # TODO: create a different session to test を見つけます。
この行全体を次のコードに置き換えます。
tokyo_session_2 = await session_service.create_session(
app_name=multi_day_agent.name,
user_id=user_id
)
テスト
「金魚」メモリと「象」メモリの違いを示す 2 つの関数があります。
シナリオ 1: ステートフル(共有セッション)
async def run_trip_same_session_scenario(session_service, user_id):
# 1. Create ONE session
trip_session = await session_service.create_session(...)
# 2. Turn 1
await run_agent_query(..., trip_session, ...)
# 3. Turn 2 - REUSING the same session!
# The agent can "see" Turn 1 because it's in the session history.
await run_agent_query(..., trip_session, ...)
シナリオ 2: ステートレス(毎回新しいセッション)
async def run_trip_different_session_scenario(session_service, user_id):
# Turn 1
tokyo_session = await session_service.create_session(...)
await run_agent_query(..., tokyo_session, ...)
# Turn 2 - Creating a FREASH session
# The agent has NO IDEA what happened in Turn 1.
tokyo_session_2 = await session_service.create_session(...)
await run_agent_query(..., tokyo_session_2, ...)
ステップ 3: エージェントを実行する
この違いを実際に見てみましょう。スクリプトを実行します。
👉💻 コマンドラインで、次のコマンドラインを実行します。
cd ~/memory_agent_starter
uv run python ~/memory_agent_starter/01_session_agent/main.py
シナリオ 1 を確認する: エージェントは最初のメッセージでユーザーの好みを記憶し、2 番目のメッセージでプランを調整します。
シナリオ 2 を観察する: 2 回目のターン(「食べ物の何が好きだったか覚えていますか?」)では、新しいセッションであるため、エージェントは完全に失敗します。これは事実上、「何のことかわかりません」と言っているのと同じです。
重要ポイント
メモリのルール 1: 会話のコンテキストを維持するために、常に session.id を再利用します。Session オブジェクトは、エージェントの短期記憶バッファです。
4. チーム - マルチエージェントの状態

コンセプト: 「伝言ゲーム」
複数のエージェントが連携して作業する場合、同僚がファイル フォルダをやり取りするようなものです。1 人のエージェントがフォルダにメモを書き込んだ場合、次のエージェントがそのメモを読めるようにする必要があります。
ADK では、この「フォルダ」は状態です。
- 状態は、セッション内に存在する辞書(
{"key": "value"})です。 - セッション内のエージェントは、この変数から読み取り、この変数に書き込むことができます。
ステップ 1: ワークフローを調べる
👉💻 Cloud Shell ターミナルで、次のコマンドを実行して Cloud Shell エディタでファイルを開きます。
cloudshell edit ~/memory_agent_starter/02_multi_agent/agent.py
👉~/memory_agent_starter/02_multi_agent/agent.py ファイルで、# TODO: foodie agent というコメントを探します。
この行全体を次のコードに置き換えます。
foodie_agent = LlmAgent(
name="foodie_agent",
model="gemini-2.5-flash",
tools=[google_search],
instruction="""You are an expert food critic. Your goal is to find the best restaurant based on a user's request.
When you recommend a place, you must output *only* the name of the establishment and nothing else.
For example, if the best sushi is at 'Jin Sho', you should output only: Jin Sho
""",
output_key="destination" # ADK will save the agent's final response to state['destination']
)
👉 agent.py 関数内のコメント # TODO: transportation agent を見つけます。
この行全体を次のコードに置き換えます。
transportation_agent = LlmAgent(
name="transportation_agent",
model="gemini-2.5-flash",
tools=[google_search],
instruction="""You are a navigation assistant. Given a destination, provide clear directions.
The user wants to go to: {destination}.
Analyze the user's full original query to find their starting point.
Then, provide clear directions from that starting point to {destination}.
""",
)
👉 agent.py 関数内のコメント # TODO: root_agent を見つけます。
この行全体を次のコードに置き換えます。
root_agent = SequentialAgent(
name="find_and_navigate_agent",
sub_agents=[foodie_agent, transportation_agent],
description="A workflow that first finds a location and then provides directions to it."
)
これで、2 つのエージェントが順番に動作するようになりました。
- Foodie Agent: レストランを検索します。
- Transportation Agent: そのレストランへの道順を案内します。
マジック ハンドオフ: foodie_agent が transportation_agent にバトンを渡す様子に注目してください。
foodie_agent = LlmAgent(
# ...
# CRITICAL: This tells ADK to save the agent's output to state['destination']
output_key="destination"
)
transportation_agent = LlmAgent(
# ...
# CRITICAL: This injects state['destination'] into the prompt
instruction="""
The user wants to go to: {destination}.
Provide clear directions...
""",
)
output_key="destination": Foodie Agent の回答が効率的に保存されます。{destination}: 交通機関エージェントがその回答を自動的に読み取ります。
(対応は不要)ステップ 2: オーケストレーター
02_multi_agent/main.py を開きます。
SequentialAgent を使用して順番に実行します。
# 1. Create a single session for the sequential agent
session = await session_service.create_session(...)
# 2. Run the query
# The SequentialAgent manages the state flow:
# Query -> Foodie -> state['destination'] -> Transportation -> Final Answer
await run_agent_query(root_agent, query, ...)
ユーザーが1 つのプロンプトを送信します。
"Find best sushi in Palo Alto and then tell me how to get there."
エージェントが連携して回答します。
ステップ 3: チームを実行する
👉💻 Cloud Shell ターミナルで、マルチエージェント ワークフローを実行します。
cd ~/memory_agent_starter
uv run python ~/memory_agent_starter/02_multi_agent/main.py
どうなるでしょうか?
- Foodie Agent: 「Jin Sho」(または類似の語句)を検出します。
- ADK:
state['destination']に「Jin Sho」を保存します。 - Transportation Agent: 指示で「Jin Sho」を受け取ります。
- 結果: 「カルトレイン駅から Jin Sho に行くには、University Ave を下って...」
重要ポイント
メモリのルール #2: 状態を使用して、エージェント間で構造化された情報を渡します。書き込みには output_key を、読み取りには {placeholders} を使用します。
5. 再起動 - 永続性
コンセプト: 「再起動の問題」
これまでのところ、メモリは InMemory です。スクリプトを停止して再開すると、エージェントはすべてを忘れます。電源を切るたびにハードドライブが消去されるパソコンのようなものです。
この問題を解決するには、永続性が必要です。InMemorySessionService を DatabaseSessionService にスワップします。
ステップ 1: データベースの切り替え
👉💻 Cloud Shell ターミナルで、次のコマンドを実行して Cloud Shell エディタでファイルを開きます。
cloudshell edit ~/memory_agent_starter/03_persistent_agent/main.py
👉 ~/memory_agent_starter/03_persistent_agent/main.py ファイルで、# TODO: Configuration for Persistent Sessions というコメントを探します。
この行全体を次のコードに置き換えます。
SESSIONS_DIR = Path(os.path.expanduser("~")) / ".adk_codelab" / "sessions"
os.makedirs(SESSIONS_DIR, exist_ok=True)
SESSION_DB_FILE = SESSIONS_DIR / "trip_planner.db"
SESSION_URL = f"sqlite:///{SESSION_DB_FILE}"
これで、すべてのセッションとイベントが SQLite ファイルに保存されます。
ステップ 2: クロスセッション検索
永続性により、会話を再開できるだけでなく、過去の会話から学習することもできます。
同じファイル~/memory_agent_starter/03_persistent_agent/main.py で、テストケース 3: セッション間の取得を確認します。
👉 コメントを見つける # TODO: retrieve the previous session manually
この行全体を次のコードに置き換えます。
old_session = await session_service.get_session(
app_name=root_agent.name, user_id="user_01", session_id=session_id
)
👉 main.py 関数内のコメント # TODO: Extract content from the OLD session を見つけます。
この行全体を次のコードに置き換えます。
previous_context += f"- {role}: {text}\n"
👉 main.py 関数内のコメント # TODO: Manually inject the context to the query を見つけます。
この行全体を次のコードに置き換えます。
query_3 = f"""
{previous_context}
I'm planning a new trip to Osaka this time.
Based on my previous preferences (above), what should I eat?
"""
これは、ユーザーが数か月後に戻ってくることをシミュレートします。古い履歴を取得できるのはデータベースのみです。
ステップ 3: 再起動を乗り切る
👉💻 ターミナルでスクリプトを実行します。
cd ~/memory_agent_starter
uv run python ~/memory_agent_starter/03_persistent_agent/main.py
ファイル ~/memory_agent_starter/trip_planner.db が作成されます。試してみましょう: スクリプトを 2 回実行します。
- 2 回目の実行で、「Resumed existing session」を探します。
- エージェントはデータベース ファイルから読み込むため、初回実行時のコンテキストを記憶します。
重要ポイント
メモリのルール 3: 本番環境には DatabaseSessionService を使用します。これにより、サーバーの再起動後もユーザーの会話が保持され、長期的な履歴分析が可能になります。
6. スパイ - コールバック

エージェントの言葉だけでなく、エージェントの行動に基づいてメモリを自動的に更新する必要がある場合があります。エージェントを監視してメモを取る「スパイ」が必要になります。
ADK では、このスパイは Callback です。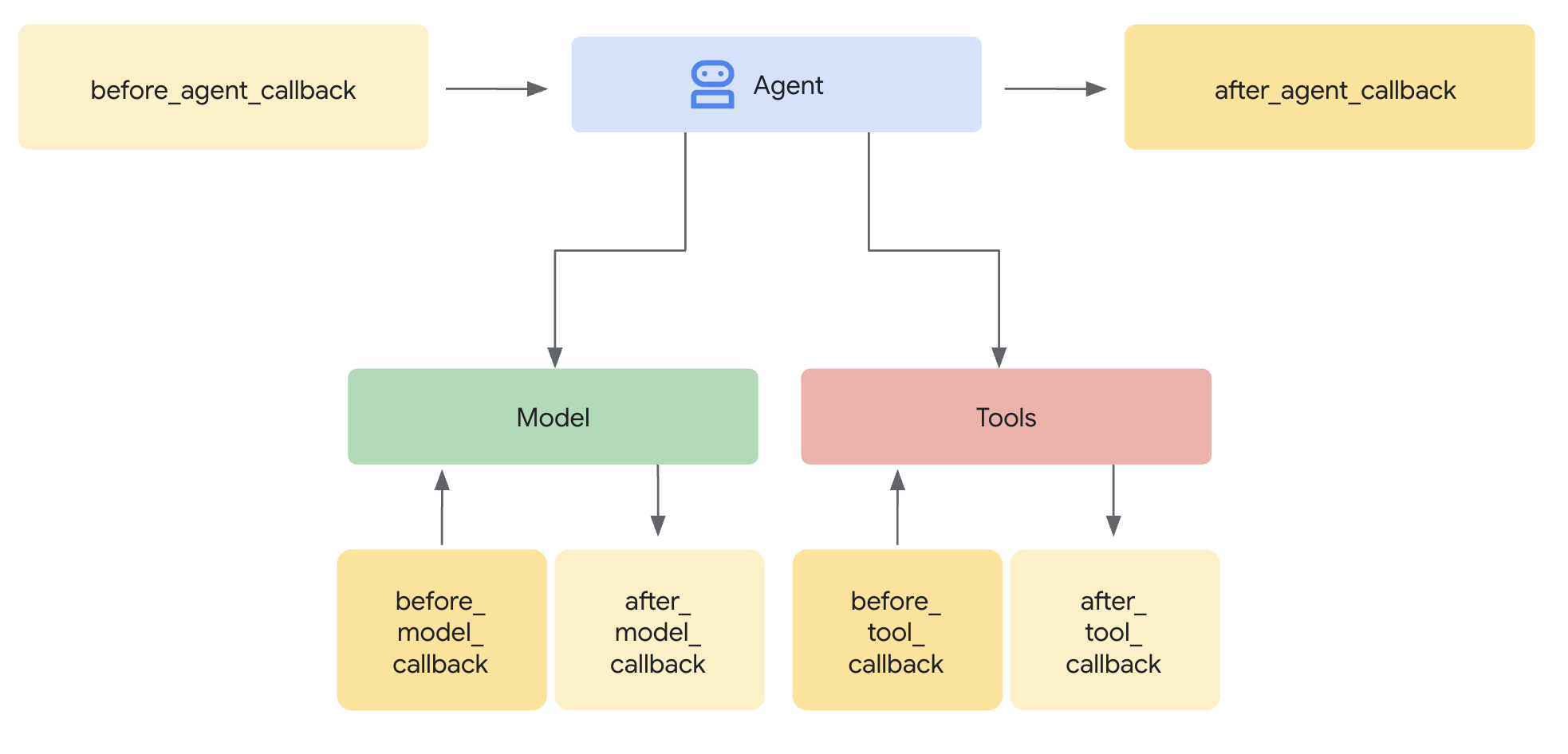
after_tool_callback: エージェントが動作するたびに実行される関数。ToolContext: その関数内から State に書き込む方法。
ステップ 1: ロジック
👉💻 Cloud Shell ターミナルで、次のコマンドを実行して Cloud Shell エディタでファイルを開きます。
cloudshell edit ~/memory_agent_starter/04_stateful_agent/agent.py
👉 ~/memory_agent_starter/04_stateful_agent/agent.py ファイルで、# TODO: Implement call back logic というコメントを探します。
この行全体を次のコードに置き換えます。
def save_activity_type_callback(
tool,
args: Dict[str, Any],
tool_context: ToolContext,
tool_response: Dict[str, Any],
) -> Optional[Dict[str, Any]]:
"""
Callback to save the TYPE of activity just planned into the session state.
"""
# 1. Get the actual agent name.
if tool.name == "transfer_to_agent":
agent_name = args.get("agent_name")
else:
agent_name = tool.name
activity_type = "unknown"
# 2. Determine the type based on which agent was actually used
if agent_name == "museum_expert":
activity_type = "CULTURAL"
elif agent_name == "restaurant_expert":
activity_type = "FOOD"
elif agent_name == "outdoor_expert":
activity_type = "OUTDOOR"
print(f"\n🔔 [CALLBACK] The planner transferred to '{agent_name}'.")
# 3. Update the state directly
tool_context.state["last_activity_type"] = activity_type
print(f"💾 [STATE UPDATE] 'last_activity_type' is now set to: {activity_type}\n")
return tool_response
👉 同じファイルで、04_stateful_agent/agent.py 関数内のコメント # TODO: add callback to root agent を探します。
この行全体を次のコードに置き換えます。
after_tool_callback=save_activity_type_callback,
動的指示: エージェントの指示が文字列ではなく関数になりました。状態によって変化します。
def get_planner_instruction(context):
last_activity = context.state.get("last_activity_type", "None")
return f"""
The last activity was: {last_activity}
If last_activity is 'CULTURAL' -> `museum_expert` is BANNED.
"""
ステップ 3: スパイをテストする
👉💻 ターミナルで、次のコマンドをコピーして貼り付け、スクリプトを実行します。
cd ~/memory_agent_starter
uv run python ~/memory_agent_starter/04_stateful_agent/main.py
このエージェントを実行すると、ループが表示されます。
- ターン 1: 美術館をリクエストします。スパイは
last_activity="CULTURAL"を設定します。 - ターン 2: 別の美術館をリクエストします。
- エージェント向け手順の更新: 「CULTURAL は禁止されています」。
- エージェント: 「別の美術館は無理です。公園はどう?」
コンソールログで [CALLBACK] と [STATE UPDATE] を確認します。エージェントの動作に伴ってメモリがリアルタイムで変化する様子を確認できます。
重要ポイント
メモリのルール #4: コールバックを使用して状態管理を自動化します。エージェントは、ジョブを実行するだけで独自のコンテキストを構築します。
7. ファイルキャビネット - カスタムツール
コンセプト: 「構造化されたメモリ」

これまでの「メモリ」は、チャットログまたは単純な Key-Value ペアでした。ただし、複雑なユーザー プロフィールを記憶する必要がある場合はどうでしょうか。たとえば、diet: vegan, budget: high, pets: [cat, dog]。
このため、メモリをツールとして扱います。エージェントは、ファイル キャビネットを開く(読み取り)タイミングとレポートを提出する(書き込み)タイミングを明示的に決定します。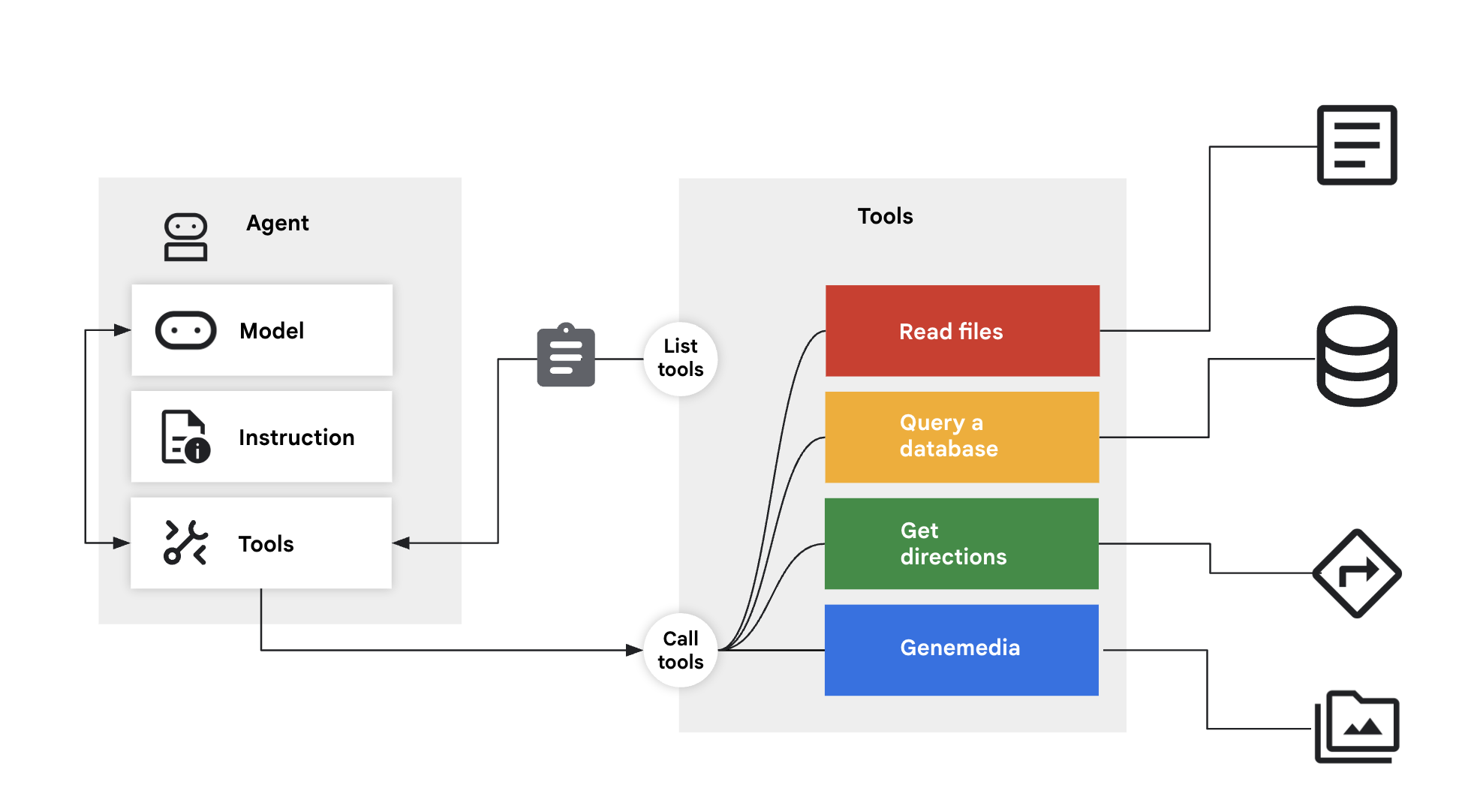
ステップ 1: ツール
👉💻 Cloud Shell ターミナルで、次のコマンドを実行して Cloud Shell エディタでファイルを開きます。
cloudshell edit ~/memory_agent_starter/05_profile_agent/tools.py
👉 このファイル: ~/memory_agent_starter/05_profile_agent/tools.py。
次の 2 つのツールを実装する必要があります。
save_user_preferences: データベースに書き込みます。recall_user_preferences: データベースから読み取ります。
~/memory_agent_starter/05_profile_agent/tools.py 関数内のコメント # TODO: implement save_user_preferences tools を見つけます。
この行全体を次のコードに置き換えます。
def save_user_preferences(tool_context: ToolContext, new_preferences: Dict[str, Any]) -> str:
user_id = tool_context.session.user_id
with sqlite3.connect(USER_DB_FILE) as conn:
for key, value in new_preferences.items():
conn.execute("INSERT INTO user_preferences (user_id, pref_key, pref_value) VALUES (?, ?, ?) ON CONFLICT(user_id, pref_key) DO UPDATE SET pref_value = excluded.pref_value;",
(user_id, key, json.dumps(value)))
return f"Preferences updated: {list(new_preferences.keys())}"
👉 05/tools.py 関数内のコメント # TODO: implement recall_user_preferences tools を見つけます。
この行全体を次のコードに置き換えます。
def recall_user_preferences(tool_context: ToolContext) -> Dict[str, Any]:
user_id = tool_context.session.user_id
preferences = {}
with sqlite3.connect(USER_DB_FILE) as conn:
rows = conn.execute("SELECT pref_key, pref_value FROM user_preferences WHERE user_id = ?", (user_id,)).fetchall()
if not rows: return {"message": "No preferences found."}
for key, value_str in rows: preferences[key] = json.loads(value_str)
return preferences
この指示により、ワークフローが強制的に実行されます。
instruction="""
1. RECALL FIRST: First action MUST be `recall_user_preferences`.
3. LEARN: If a user states a new preference, use `save_user_preferences`.
"""
ステップ 2: 実行
👉💻 Cloud Shell ターミナルで、次のコマンドを実行して Cloud Shell エディタでファイルを開きます。
cloudshell edit ~/memory_agent_starter/05_profile_agent/main.py
~/memory_agent_starter/05_profile_agent/main.py を開きます。
ADK が状態を自動的に処理していた以前のモジュールとは異なり、ここでは Agent が制御します。
- 最初に
recall_user_preferencesを呼び出すことを選択します。 - 「私はビーガンです」と言うと、
save_user_preferencesに電話をかけるよう選択します。
ステップ 3: プロファイルをビルドする
👉💻 スクリプトを実行します。
cd ~/memory_agent_starter
uv run python ~/memory_agent_starter/05_profile_agent/main.py
次の会話フローを試してください。
- 「夕食の献立を考えて。」-> エージェントが DB を確認しますが、何も見つかりません。好みを尋ねます。
- 「私はビーガンです。」-> エージェントが「vegan」を DB に保存します。
- スクリプトを再起動します。
- 「夕食の献立を考えて。」-> エージェントは DB を確認して「ビーガン」を見つけ、すぐにビーガン レストランを提案します。
重要ポイント
メモリのルール #5: 複雑な構造化データの場合は、エージェントに読み取り/書き込みツールを提供します。LLM が独自の長期保存を管理できるようにします。
8. The Brain - マルチモーダル メモリ
コンセプト: 「ヒューマン エクスペリエンス」
人間はテキスト以上のものを記憶します。写真の雰囲気、声の音、動画の感覚を記憶します。
Vertex AI Memory Bank を使用すると、エージェントはマルチモーダル メモリを処理できます。画像、動画、音声を取り込み、「理解」して、後で取得できます。
ステップ 1: 構成
👉💻 Cloud Shell ターミナルで、次のコマンドを実行して Cloud Shell エディタでファイルを開きます。
cloudshell edit ~/memory_agent_starter/06_multimodal_agent/main.py
👉 06_multimodal_agent/main.py を開きます。コメント # TODO: Configure Memory Bank Topic を見つけます。
この行全体を次のコードに置き換えます。
travel_topics = [
MemoryTopic(
managed_memory_topic=ManagedMemoryTopic(
managed_topic_enum=ManagedTopicEnum.USER_PREFERENCES
)
),
MemoryTopic(
managed_memory_topic=ManagedMemoryTopic(
managed_topic_enum=ManagedTopicEnum.USER_PERSONAL_INFO
)
),
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="travel_experiences",
description="""Memorable travel experiences including:
- Places visited and impressions
- Favorite restaurants, cafes, and food experiences
- Preferred accommodation types and locations
- Activities enjoyed (museums, hiking, beaches, etc.)
- Travel companions and social preferences
- Photos and videos from trips with location context""",
)
),
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="travel_preferences",
description="""Travel style and preferences:
- Budget preferences (luxury, mid-range, budget)
- Transportation preferences (flying, trains, driving)
- Trip duration preferences
- Season and weather preferences
- Cultural interests and language abilities
- Dietary restrictions and food preferences""",
)
),
MemoryTopic(
custom_memory_topic=CustomMemoryTopic(
label="travel_logistics",
description="""Practical travel information:
- Passport and visa information
- Frequent flyer numbers and hotel loyalty programs
- Emergency contacts
- Medical considerations and insurance
- Packing preferences and essentials
- Time zone preferences and jet lag strategies""",
)
),
]
コメントを見つける # TODO: Configure Memory Bank Customization
この行全体を次のコードに置き換えます。
memory_bank_config = {
"customization_configs": [
{
"memory_topics": travel_topics,
}
],
"similarity_search_config": {
"embedding_model": f"projects/{PROJECT_ID}/locations/{LOCATION}/publishers/google/models/gemini-embedding-001"
},
"generation_config": {
"model": f"projects/{PROJECT_ID}/locations/{LOCATION}/publishers/google/models/gemini-2.5-flash"
},
}
ステップ 2: 世界の取り込み
test_trip_planner で、次のものを送信します。
- テキスト メッセージ(「Hello」)
- 画像(ランドマーク)
- 動画(地中海)
- 音声クリップ(ガエタについての音声メモ)
6_multimodal_agent/main.py 関数内のコメント # TODO create session service and memory service を見つけます。
この行全体を次のコードに置き換えます。
session_service = VertexAiSessionService(
project=PROJECT_ID, location=LOCATION, agent_engine_id=agent_engine_id
)
memory_service = VertexAiMemoryBankService(
project=PROJECT_ID, location=LOCATION, agent_engine_id=agent_engine_id
)
👉 同じファイル 06_multimodal_agent/main.py で、コメント # TODO: create memory from session を探します。
この行全体を次のコードに置き換えます。
await memory_service.add_session_to_memory(final_session_state)
これがマジックラインです。このリッチメディアはすべて Vertex AI に送信され、処理とインデックス登録が行われます。
ステップ 3: 検索
👉💻 Cloud Shell ターミナルで、次のコマンドを実行して Cloud Shell エディタでファイルを開きます。
cloudshell edit ~/memory_agent_starter/06_multimodal_agent/agent.py
エージェントに PreloadMemoryTool がある。
tools=[PreloadMemoryTool(), budget_tool]
新しいセッションが開始されると、このツールは Memory Bank で関連する過去の経験を自動的に検索し、コンテキストに挿入します。
ステップ 4: Brain を実行する
👉💻 Cloud Shell ターミナルで、スクリプトを実行します(注: これには、Vertex AI が有効になっている Google Cloud プロジェクトが必要です)。
cd ~/memory_agent_starter
uv run python ~/memory_agent_starter/06_multimodal_agent/main.py
オーナー確認の最後のステップをご覧ください。
「以前に共有した写真、動画、音声に基づいて...」
エージェントは次のように返信します。
「ガエタにはぜひ行ってみてください。地中海の動画と、ガエタが好きだと言っている音声クリップを見せてくれました。」
過去のさまざまなメディアタイプを横断して点と点をつなぎました。
重要ポイント
メモリのルール #6: 究極のメモリ エクスペリエンスを実現するには、Vertex AI Memory Bank を使用します。テキスト、画像、動画を 1 つの検索可能な脳に統合します。
9. まとめ
忘れっぽい金魚からマルチモーダルな象へと進化しました。
作成した | 機能 |
Session Agent | 短期会話メモリ |
マルチエージェント | チームの共有メモリ |
Persistent Agent | 長期的な履歴 |
ステートフル エージェント | 動的で自動更新されるメモリ |
Profile Agent | 構造化データ メモリ |
マルチモーダル エージェント | 人間のような感覚記憶 |
信頼は記憶の上に築かれます。これらのパターンを実装することで、ユーザーの時間と履歴を尊重するエージェントを作成し、より効果的なインタラクションを実現できます。
今すぐパーソナライズされたエージェントの構築を始めましょう。