
1. Başlamadan önce
Bu codelab, Cloud SQL'deki tek bir MySQL veritabanını GoogleSQL lehçesiyle Cloud Spanner veritabanına taşıma konusunda size yol gösterir. Temel uçtan uca taşıma akışına odaklanılarak temel adımlar gösterilir. Spanner Migration Tool (SMT), Dataflow, Datastream, Pub/Sub ve Google Cloud Storage dahil olmak üzere Google Cloud hizmetlerini kullanacaksınız.
Öğrenecekleriniz:
- Örnek Cloud SQL ve Cloud Spanner örneklerini ayarlama
- Spanner Migration Tool (SMT) kullanarak Cloud SQL MySQL şemasını Spanner ile uyumlu bir şemaya dönüştürme.
- Dataflow'u kullanarak Cloud SQL'den Cloud Spanner'a toplu veri taşıma işlemini gerçekleştirme.
- Datastream ve Dataflow kullanarak Cloud SQL'den Cloud Spanner'a sürekli replikasyon (CDC) ayarlama.
- Cloud Spanner'dan Cloud SQL'e tersine çoğaltmayı ayarlama.
Bu codelab'de ele alınmayan konular:
- Parçalanmış örneklerden yapılan taşıma işlemleri.
- Taşıma sırasında karmaşık veri dönüşümleri.
- Gelişmiş hata işleme veya geçersiz ileti kuyrukları (DLQ).
- Taşıma performansını ayarlama
- Uygulama Taşıma: Bu codelab, veritabanı katmanına (şema ve veriler) odaklanır. Uygulama hizmetlerinizin yeniden dağıtılması veya taşınmasıyla ilgili operasyonel süreçleri kapsamaz.
İhtiyacınız olanlar
- Faturalandırmanın etkin olduğu bir Google Cloud projesi.
- API'leri etkinleştirmek ve Cloud SQL, Spanner, Dataflow, Datastream ve GCS kaynaklarını oluşturup yönetmek için yeterli IAM izinleri. Proje
Ownerrolü, bir codelab için en basit rol olsa da daha spesifik roller "Ortam Kurulumu" bölümünde ele alınacaktır. - Google Chrome gibi bir web tarayıcısı
- Google Cloud Console ve
gcloudgibi komut satırı araçları hakkında temel düzeyde bilgi sahibi olmak. - Kabuk ortamına erişim.
gcloudiçerdiğinden Cloud Shell önerilir.
Yukarıdaki kurulumla ilgili daha fazla ayrıntı için Ortam Kurulumu bölümüne bakın.
2. Taşıma Sürecini Anlama
Veritabanı taşıma işlemi, kaynak Cloud SQL veritabanı örneğinizdeki verilerin bir Spanner örneğine taşınmasını içerir. Bu bölümde, mimari ve taşıma işleminde kullanılan temel araçlar açıklanmaktadır.
Taşıma Akışı Mimarisi
Taşıma işlemi şu aşamaları içerir:
1. Şema Dönüşümü:
- Amaç: Kaynak veritabanı şemasını uyumlu bir Cloud Spanner şemasına dönüştürmek.
- Araç: Spanner Taşıma Aracı (SMT)
- Süreç: SMT, kaynak veritabanı şemasını analiz eder ve eşdeğer Spanner Veri Tanımlama Dili'ni (DDL) oluşturur. Hedef Spanner örneğinde bir veritabanı oluşturulur ve DDL otomatik olarak uygulanır.
2. Toplu Veri Taşıma:
- Amaç: Kaynak veritabanındaki mevcut verilerin, sağlanan Spanner tablolarına ilk ve tam yüklemesini gerçekleştirmek.
- Araç: Google tarafından sağlanan
Sourcedb to Spannerşablonunu kullanan Dataflow. - Süreç: Bu Dataflow işi, belirtilen kaynak tablolardaki tüm verileri okur ve bunları ilgili Spanner tablolarına yazar. Bu işlem, Spanner şeması oluşturulduktan sonra yapılır.
3. Canlı geçiş (CDC):
- Amaç: Kaynak veritabanındaki devam eden değişiklikleri neredeyse gerçek zamanlı olarak yakalayıp Cloud Spanner'a uygulamak ve taşıma sırasında kapalı kalma süresini en aza indirmek.
- Araçlar:
- Datastream: Kaynak veritabanındaki değişiklikleri (eklemeler, güncellemeler, silmeler) yakalar ve bunları Cloud Storage'a (GCS) yazar.
- Dataflow: GCS'deki değişiklik etkinliklerini okumak ve bunları Cloud Spanner'a uygulamak için
Datastream to Spannerşablonunu kullanır.
4. Tersine Çoğaltma:
- Amaç: Cloud Spanner'daki veri değişikliklerini kaynak veritabanına geri kopyalamak. Bu özellik, yedek stratejileri, aşamalı geçişler veya belirli kullanım alanları için kaynakta bir kopya tutmak için yararlı olabilir.
- Araç:
Spanner to SourceDbşablonunu kullanan Dataflow. - İşlem: Bu iş, Spanner'daki değişiklikleri yakalamak ve bunları kaynak veritabanı örneğine geri yazmak için Spanner değişiklik akışlarını kullanır.
Aşağıdaki şemada bileşenler ve veri akışı gösterilmektedir:

Temel Terminoloji:
- Spanner Migration Tool (SMT): MySQL şemalarını değerlendirmek, Spanner şema eşdeğerleri önermek ve Spanner Veri Tanımlama Dili (DDL)'ni oluşturmak için kullanılan bir araçtır.
- Veri Tanımlama Dili (DDL): Veritabanı yapısını tanımlamak ve değiştirmek için kullanılan ifadelerdir (ör.
CREATE TABLEifadeleri). SMT, Cloud SQL şemasına göre Spanner DDL'si oluşturur. - Dataflow: Tümüyle yönetilen, sunucusuz bir veri işleme hizmeti. Bu codelab'de, toplu veri aktarımı, Datastream değişikliklerini uygulama ve ters çoğaltma için Google tarafından sağlanan şablonları çalıştırmak üzere kullanılır.
- Datastream: Sunucusuz bir Değişiklik Veri Yakalama (CDC) ve replikasyon hizmetidir. Bu codelab'de, Cloud SQL'deki değişiklikleri Cloud Storage'a aktarmak için kullanılır.
- Spanner Değişiklik Akışları: Verilerdeki değişikliklerin (eklemeler, güncellemeler, silmeler) gerçek zamanlı olarak aktarılmasına olanak tanıyan bir Spanner özelliği. Ters çoğaltma için kaynak olarak kullanılır.
- Pub/Sub: Etkinlik üreten hizmetleri bunları işleyen hizmetlerden ayırmak için kullanılan bir mesajlaşma hizmeti. Bu codelab'de, Datastream Cloud Storage'a yeni değişiklik dosyaları yüklediğinde Dataflow'un güncellemeleri işlemesi tetiklenir.
3. Ortam Kurulumu
Taşıma işlemine başlamadan önce Google Cloud projenizi ayarlamanız ve gerekli hizmetleri etkinleştirmeniz gerekir.
1. Google Cloud projesi seçme veya oluşturma
Bu codelab'deki hizmetleri kullanmak için faturalandırmanın etkinleştirildiği bir Google Cloud projesine ihtiyacınız var.
- Google Cloud Console'da proje seçici sayfasına gidin: Proje Seçici'ye git
- Bir Google Cloud projesi seçin veya oluşturun.
- Projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Projeniz için faturalandırmanın etkinleştirildiğini nasıl onaylayacağınızı öğrenin.
2. Cloud Shell'i açın
Cloud Shell, Google Cloud'da çalışan ve gcloud KSA'sı ile ihtiyaç duyduğunuz diğer araçlar önceden yüklenmiş olarak gelen bir komut satırı ortamıdır.
- Google Cloud Console'un sağ üst kısmındaki Cloud Shell'i Etkinleştir düğmesini tıklayın.
- Konsolun altındaki yeni bir çerçevede Cloud Shell oturumu açılır ve komut satırı istemi görüntülenir.

3. Proje ve Ortam Değişkenlerini Ayarlama
Cloud Shell'de proje kimliğiniz ve kullanacağınız bölge için bazı ortam değişkenleri ayarlayın.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. Gerekli Google Cloud API'lerini etkinleştirme
Cloud Spanner, Dataflow, Datastream ve diğer ilgili hizmetler için gerekli API'leri etkinleştirin.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
Bu komutun tamamlanması birkaç dakika sürebilir.
5. Hizmet Hesabı İzinlerini Yapılandırma
Dataflow işleri ve Datastream'in diğer Google Cloud hizmetleriyle etkileşimde bulunması için belirli izinler gerekir. Bu codelab'deki Dataflow işleri, varsayılan Compute Engine hizmet hesabını kullanır.
Öncelikle proje numaranızı alın:
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
Şimdi, Compute Engine varsayılan hizmet hesabına gerekli IAM rollerini atayın:
# Role for Dataflow to run jobs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.admin" \
--condition=None
# Roles for Dataflow workers
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.worker" \
--condition=None
# Role to connect to Cloud SQL instance
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/cloudsql.client" \
--condition=None
# Role to read/write from Cloud Spanner
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/spanner.databaseUser" \
--condition=None
# Role to access GCS buckets (Datastream output, Dataflow temp, JDBC driver)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/storage.objectAdmin" \
--condition=None
# Roles for Datastream and Pub/Sub (for CDC)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/datastream.viewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/pubsub.subscriber"
6. Cloud Storage paketi oluşturma
Diğer kaynaklarınızla aynı bölgede bir GCS paketi oluşturun. Bu paket, JDBC sürücüsünü ve Datastream çıkışını depolar ve Dataflow tarafından geçici dosyalar için kullanılır.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
echo "Created bucket: gs://$BUCKET_NAME"
7. Spanner Taşıma Aracı'nı (SMT) yükleme
Spanner Taşıma Aracı'nın (SMT) Cloud Shell kabuk ortamınıza yüklendiğinden emin olun.
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
Bu komut, SMT web arayüzüyle ilgili yardım bilgilerini göstererek gcloud bileşeninin yüklendiğini onaylamalıdır. Bu codelab'de, aynı bileşenin parçası olan SMT'nin KSA özellikleri kullanılacaktır.
4. Kaynak Cloud SQL Veritabanını Ayarlama
Bu bölümde, kaynak veritabanı olarak hizmet verecek genel IP'ye sahip bir MySQL İçin Cloud SQL örneği oluşturup yapılandıracaksınız.
1. MySQL için Cloud SQL örneği oluşturma
MySQL 8.0 örneği oluşturmak için Cloud Shell'de aşağıdaki gcloud komutunu çalıştırın. İkili günlük kaydı etkinleştirilmiş (Datastream için gereklidir) ve örnek, herkese açık IP ile yapılandırılmış olmalıdır.
export SQL_INSTANCE_NAME="source-mysql-instance"
export DB_ROOT_PASSWORD="Welcome@1" # Replace with a strong password if you prefer
gcloud sql instances create $SQL_INSTANCE_NAME \
--database-version=MYSQL_8_0 \
--tier=db-n1-standard-2 \
--region=$REGION \
--root-password=$DB_ROOT_PASSWORD \
--enable-bin-log \
--assign-ip
--enable-bin-log: Veri akışının değişiklikleri yakalaması için gereklidir.--assign-ip: Örneğe genel IP adresi atanmasını sağlar.
Örnek oluşturma işlemi birkaç dakika sürer. Örneğinizin oluşturulup oluşturulmadığını Cloud SQL örnekleri sayfasından kontrol edebilirsiniz.
2. Yetkili ağları yapılandırma
Herkese açık IP üzerinden örneğe bağlanmak için IP adreslerini "Yetkili Ağlar" listesine eklemeniz gerekir.
Cloud Shell IP'nizi alın:
export CLOUD_SHELL_IP=$(curl -s ipinfo.io/ip)
echo "Your Cloud Shell IP: $CLOUD_SHELL_IP"
Cloud Shell IP'si ve açık erişim için yetkilendirme
Aşağıdaki komut, Cloud Shell IP'nizi ekler. Ayrıca, herhangi bir IP adresinden erişime izin veren 0.0.0.0/0 ifadesini de ekler. Bu, karmaşık ağ kurulumları olmadan Dataflow çalışanlarından gelen bağlantıları basitleştirmek için gereklidir.
gcloud sql instances patch $SQL_INSTANCE_NAME \
--authorized-networks="${CLOUD_SHELL_IP}/32,0.0.0.0/0"
3. Cloud Shell'den Cloud SQL örneğine bağlanma
Atanan genel IP adresini getirme
export SQL_INSTANCE_IP=$(gcloud sql instances list --filter="name=$SQL_INSTANCE_NAME" --format="value(PRIMARY_ADDRESS)")
echo "Cloud SQL Public IP: $SQL_INSTANCE_IP"
Bağlanmak için bu IP adresi kullanılır.
Cloud Shell'den Cloud SQL örneğine bağlanma
Bağlanmak için standart MySQL istemcisini kullanın ve elde edilen genel IP adresini girin:
mysql -h $SQL_INSTANCE_IP -u root -p
İstendiğinde belirlediğiniz kök şifresini girin (Welcome@1). Artık mysql> isteminde olacaksınız.
4. Veritabanı ve örnek veriler oluşturma
mysql> isteminde aşağıdaki SQL komutlarını çalıştırın:
CREATE DATABASE music_db;
USE music_db;
CREATE TABLE Singers (
SingerId BIGINT NOT NULL,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
BirthDate DATE,
AlbumCount BIGINT,
PRIMARY KEY (SingerId)
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY (SingerId, AlbumId),
CONSTRAINT FK_Albums_Singers FOREIGN KEY (SingerId) REFERENCES Singers (SingerId)
);
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES
(1, 'Marc', 'Richards', '1970-09-03', 2),
(2, 'Catalina', 'Smith', '1990-08-17', 1),
(3, 'Alice', 'Trentor', '1991-10-02', 3);
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle, ReleaseDate) VALUES
(1, 1, 'Total Junk', '2014-03-15'),
(1, 2, 'Go Go Go', '2016-11-01'),
(2, 1, 'Green', '2018-02-28'),
(3, 1, 'Blue', '2019-01-10'),
(3, 2, 'Red', '2020-05-22'),
(3, 3, 'Purple', '2022-11-11');
Yukarıdaki şemaya ait döküm dosyasını burada bulabilirsiniz.
5. Verileri doğrulama
Verilerin mevcut olup olmadığını hızlıca kontrol edin:
SELECT 'Singers music_db' as tbl, COUNT(*) FROM music_db.Singers
UNION ALL
SELECT 'Albums music_db', COUNT(*) FROM music_db.Albums;
EXIT;
Her tablo için sayıları görürsünüz.
+------------------+----------+ | tbl | COUNT(*) | +------------------+----------+ | Singers music_db | 3 | | Albums music_db | 6 | +------------------+----------+
5. Cloud Spanner'ı ayarlama
Şimdi, verilerin taşınacağı hedef Cloud Spanner örneğini ayarlayacaksınız.
1. Cloud Spanner örneği oluşturma
Cloud SQL örneğinizle aynı bölgede bir Cloud Spanner örneği oluşturun. Bu komut, 100 işleme birimi kullanarak bu codelab için uygun küçük bir örnek oluşturur.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="music-db-migrated"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
Örnek oluşturma işlemi bir veya iki dakika sürebilir.
6. Spanner Taşıma Aracı'nı (SMT) kullanarak şemayı dönüştürme
MySQL veritabanını analiz etmek (music_db) ve Spanner Şema Tanımlama Dili'ni (DDL) oluşturmak için SMT CLI'yı kullanın. Cloud SQL örneği, genel IP ve uygun yetkili ağlarla yapılandırıldığından SMT doğrudan bağlanabilir.
1. Ortamı SMT için hazırlama
Önceki adımlarda gerekli ortam değişkenlerinin ayarlandığını doğrulayın:
echo "Cloud SQL Instance Public IP: $SQL_INSTANCE_IP"
echo "Cloud SQL Root Password: $DB_ROOT_PASSWORD"
echo "Spanner Instance: $SPANNER_INSTANCE_NAME"
echo "Spanner Database: $SPANNER_DATABASE_NAME"
echo "Project ID: $PROJECT_ID"
2. music_db için şema dönüştürme işlemini çalıştırın
Doğrudan Cloud SQL genel IP adresine bağlanarak SMT schema komutunu yürütün:
gcloud alpha spanner migrate schema \
--source=mysql \
--source-profile="host=${SQL_INSTANCE_IP},port=3306,user=root,password=${DB_ROOT_PASSWORD},dbName=music_db" \
--target-profile="project=${PROJECT_ID},instance=${SPANNER_INSTANCE_NAME},dbName=${SPANNER_DATABASE_NAME}" \
--prefix="music-db"
Bu komut, proxy üzerinden Cloud SQL örneğine bağlanır ve music-db ile başlayan şema dosyaları oluşturur.
3. Oluşturulan Dosyaları İnceleme
SMT, geçerli dizininizde birkaç dosya oluşturur. En önemlileri şunlardır:
music-db.schema.ddl.txt: Oluşturulan Spanner DDL ifadeleri.music-db-.overrides.json: Şema geçersiz kılma dosyası, manuel eşleme değişiklikleri içeriyor.music-db.session.json: Şema taşıma oturum dosyası.music-db.report.txt: Şema dönüşümünün değerlendirme raporu.
Bunları ls music-db-* kullanarak listeleyebilirsiniz.
4. Cloud Spanner'da Şemayı Doğrulama
Tabloların Spanner veritabanında oluşturulduğunu kontrol edin.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
Aşağıdaki çıkışı göreceksiniz:
table_name: Albums table_name: Singers
İsteğe bağlı: Spanner DDL'yi kontrol etmek istiyorsanız aşağıdaki komutu çalıştırın:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
7. Değişiklik Verisi Yakalama'yı (CDC) başlatma
Bu bölümde, taşıma işleminiz için "kaydedici"yi ayarlayacaksınız. Toplu veri yükleme işlemi başlamadan önce Datastream ve Pub/Sub'ı yapılandırarak kaynak veritabanında yapılan her değişikliğin yakalanıp sıraya alınmasını sağlarsınız. Böylece geçiş sırasında veri kaybı yaşanmaz. Bu kurulum, canlı taşıma için gereklidir.
1. Veri akışı bağlantı profilleri oluşturma
Kaynak profili (Cloud SQL)
Bu profil, Cloud SQL örneğinin genel IP'sine bağlanır. Veri akışı, bağlantı için IP izin verilenler listesini kullanır.
export SQL_CP_NAME="mysql-src-cp"
gcloud datastream connection-profiles create $SQL_CP_NAME \
--location=$REGION \
--type=mysql \
--mysql-hostname=$SQL_INSTANCE_IP \
--mysql-port=3306 \
--mysql-username=root \
--mysql-password=$DB_ROOT_PASSWORD \
--display-name="Cloud SQL Source - Public IP"
Not: Bu bağlantı, Cloud SQL örneğinin yetkili ağlarının erişime izin vermesine bağlıdır. 0.0.0.0/0 ile daha önce yapılandırıldığı gibi, Datastream'in herkese açık IP'leri bağlanabilir. Üretim ortamında, 0.0.0.0/0 yerine Datastream IP izin verilenler listeleri ve bölgeler bölümünde listelenen bölgenize ait belirli IP aralıklarını girersiniz.
Hedef profili (Cloud Storage)
Paketinizin kökünü gösterir.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
2. Datastream akışı oluşturma
music_db kaynağından kopyalanacak akışı oluşturun.
export STREAM_NAME="mysql-to-spanner-stream"
export GCS_STREAM_PATH="data/${STREAM_NAME}"
gcloud datastream streams create $STREAM_NAME \
--location=$REGION \
--display-name="MySQL to Spanner CDC Stream" \
--source=$SQL_CP_NAME \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "
includeObjects:
mysqlDatabases:
- database: 'music_db'
") \
--gcs-destination-config=<(echo "
path: ${GCS_STREAM_PATH}
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}
") \
--backfill-none
- Veri akışı, dosyaları
gs://${BUCKET_NAME}/${GCS_STREAM_PREFIX}/altında yazar. - DataStream, dosyaları Avro biçiminde yazar. Canlı geçiş komutunu çalıştırırken, ardışık düzenin dosyayı doğru şekilde işleyebilmesi için inputFileFormat'ı avro olarak belirleyeceğiz.
- Daha küçük dosya rotasyonu ayarları kullanmak, codelab'deki değişiklikleri daha hızlı görmenize yardımcı olur.
Bu komutun tamamlanması biraz zaman alabilir. Çek durumu: gcloud datastream streams describe $STREAM_NAME --location=$REGION.
3. Veri akışı akışını başlatma
gcloud datastream streams update $STREAM_NAME \
--location=$REGION \
--state=RUNNING
Durumu kontrol edin: gcloud datastream streams describe $STREAM_NAME --location=$REGION. Durum başlangıçta STARTING olur ve bir süre sonra RUNNING olarak değişir. Yalnızca RUNNING durumunda olduğunu onayladıktan sonra bir sonraki adıma geçin.
4. GCS bildirimleri için Pub/Sub'ı ayarlama
Pub/Sub konusu oluşturma:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
GCS bildirimi oluşturma
data/ ön eki altında nesne oluşturulduğunda bildirim gönderilir.
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
Pub/Sub aboneliği oluşturma
Önerilen onay bitiş süresini ekleyin.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. Verileri Cloud SQL'den Spanner'a toplu olarak taşıma
Spanner şeması hazır olduğunda, Cloud SQL music_db veritabanınızdaki mevcut verileri Cloud Spanner'a kopyalayacaksınız. JDBC ile erişilebilen veritabanlarından Spanner'a toplu olarak veri kopyalamak için tasarlanmış Sourcedb to Spanner Dataflow Flex şablonunu kullanacaksınız.
1. music_db için toplu taşıma Dataflow işini çalıştırma
Dataflow işini başlatmak için Cloud Shell'de aşağıdaki komutu çalıştırın. Bu komut, toplu JDBC'den Spanner'a taşıma işlemleri için Google tarafından sağlanan şablona referans vererek gcloud dataflow flex-template run komutunu kullanır.
export JOB_NAME_MUSIC="mysql-music-db-to-spanner-bulk-$(date +%Y%m%d-%H%M%S)"
export MUSIC_DB_JDBC_URL="jdbc:mysql://${SQL_INSTANCE_IP}:3306/music_db"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration-output"
gcloud dataflow flex-template run $JOB_NAME_MUSIC \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL="$MUSIC_DB_JDBC_URL",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
outputDirectory="$OUTPUT_DIR/music_db",\
username="root",\
password="$DB_ROOT_PASSWORD",\
jdbcDriverClassName="com.mysql.cj.jdbc.Driver",\
jdbcDriverJars="gs://${BUCKET_NAME}/lib/mysql-connector-j-8.0.33.jar",\
spannerHost="https://batch-spanner.googleapis.com"
Temel Parametreler Açıklaması:
sourceConfigURL: Kaynakmusic_dbiçin JDBC bağlantı dizesi.instanceId,databaseId,projectId: Hedef Cloud Spanner örneğini ve veritabanını belirtir.outputDirectory: Dataflow'un taşınamayan kayıtlarla ilgili bilgileri yazacağı bir Cloud Storage yolu.jdbcDriverClassName: MySQL JDBC sürücüsünü belirtir.jdbcDriverJars: Aşamalı JDBC sürücüsü JAR'ının GCS yolu.spannerHost: Spanner yazma işlemleri için toplu iş optimizasyonlu uç noktayı kullanır.maxWorkers,numWorkers: Dataflow işinin ölçeklendirmesini kontrol eder. Bu küçük veri kümesi için düşük tutulur.
Ağ Notu: Bu iş, Cloud SQL örneğine genel IP'si üzerinden bağlanır. Bunun nedeni, daha önce 0.0.0.0/0 adresini örneğin Yetkili Ağları'na eklemiş olmanızdır. Bu sayede, harici IP'lere sahip Dataflow çalışan VM'leri veritabanına ulaşabilir.
2. Dataflow işini izleme
İşin ilerleme durumunu Google Cloud Console'da takip edebilirsiniz:
- Dataflow işleri sayfasına gidin: Dataflow işlerine git
mysql-music-db-to-spanner-bulk-...adlı işi bulup tıklayın.- İş grafiğini ve metrikleri inceleyin. İş durumunun Başarılı olarak değişmesini bekleyin. Bu işlem yaklaşık 5-15 dakika sürer.
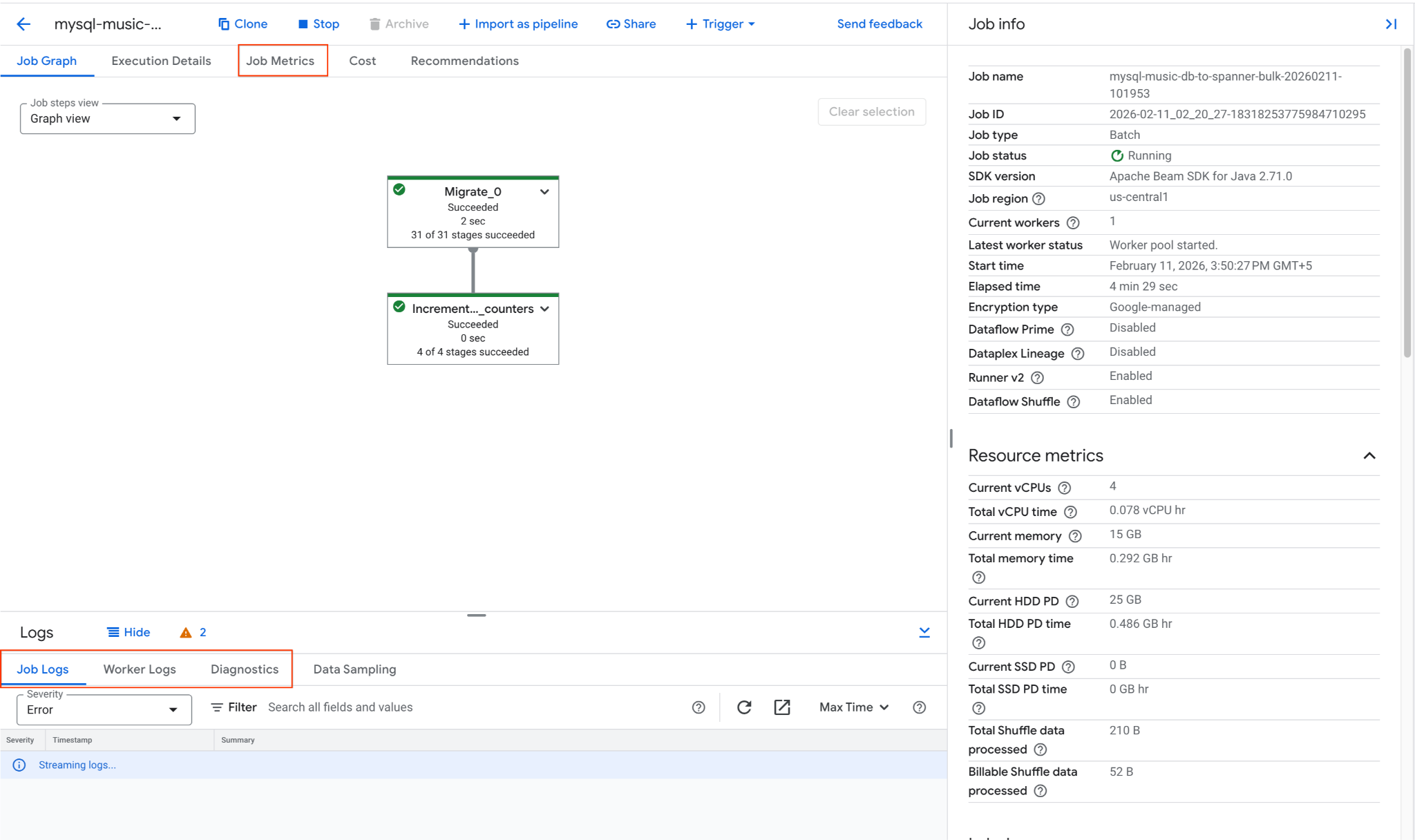
- İşte sorunlarla karşılaşılırsa hata mesajları için Dataflow işi ayrıntıları sayfasındaki Günlükler sekmesini inceleyin.
- İş Metrikleri, işin ilerleme durumu ve kaynak tüketimi (ör. işleme hızı ve CPU kullanımı) hakkında daha fazla bilgi verir.
3. Cloud Spanner'daki verileri doğrulama
Dataflow işi başarıyla tamamlandıktan sonra verilerin Spanner tablolarına kopyalandığını onaylayın. Spanner veritabanını sorgulamak için gcloud kullanın:
# Verify row counts
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Singers"
# Expected output: 3
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Albums"
# Expected output: 6
# Inspect some data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT SingerId, FirstName, LastName FROM Singers ORDER BY SingerId"
Beklenen çıkış:
row_count: 3 row_count: 6 SingerId: 1 FirstName: Marc LastName: Richards SingerId: 2 FirstName: Catalina LastName: Smith SingerId: 3 FirstName: Alice LastName: Trentor
Cloud SQL'den Cloud Spanner'a ilk toplu veri yükleme işlemi tamamlandı. Bir sonraki adım, devam eden değişiklikleri yakalamak için canlı replikasyonu ayarlamaktır.
9. Canlı geçişi (CDC) başlatma
Toplu veri yükleme işlemi tamamlandığına göre artık Cloud SQL'den değişiklik verisi yakalama (CDC) etkinliklerini yakalamak için Datastream'i kullanarak sürekli bir replikasyon akışı ve bu değişiklikleri Cloud Spanner'a neredeyse anında uygulamak için bir Dataflow akış işi ayarlayacaksınız.
1. Canlı geçiş Dataflow işini çalıştırma
GCS'den okuma yapmak ve Spanner'a yazmak için akış Dataflow işini başlatın. Bu şablon, yeni dosyaları anında işlemek için GCS Pub/Sub bildirimlerini kullanır.
export JOB_NAME_CDC="datastream-to-spanner-cdc-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR="gs://${BUCKET_NAME}/dlq"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
deadLetterQueueDirectory="$DLQ_DIR",\
streamName="projects/${PROJECT_ID}/locations/${REGION}/streams/${STREAM_NAME}"
Temel Parametreler
gcsPubSubSubscription: GCS'den gelen yeni dosya bildirimlerini dinleyen Pub/Sub aboneliği. Bu sayede, Datastream değişiklikleri yazdıkça işleme alınır.inputFileFormat="avro": Dataflow'a Datastream'den Avro dosyaları beklemesini söyler. Bu, veri akışınızın "Hedef" yapılandırmasıyla eşleşmelidir (ör.avroFileFormatvejsonFileFormat).deadLetterQueueDirectory: İşin, daha sonra manuel olarak incelenmek üzere işlenemeyen kayıtları (ör. şema uyuşmazlıkları nedeniyle) depoladığı bir GCS yolu.streamName: Dataflow işinin replikasyon durumunu ve meta verileri izlemesine olanak tanıyan, Datastream akışının tam kaynak yolu.
İşin başlatılmasını Dataflow İşleri Konsolu'nda izleyin.
2. Canlı geçişi test etme
CDC işlem hattını test etmek için kaynak Cloud SQL'de music_db değişiklikler uygulayın.
Cloud SQL'e bağlanın:
mysql -h $SQL_INSTANCE_IP -u root -p
Şifreyi girin (Welcome@1) ve veritabanını seçin:
USE music_db;
-- INSERT
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (4, 'Elena', 'Nadal', '1985-05-30', 0);
SELECT * FROM Singers WHERE SingerId = 4;
-- UPDATE
UPDATE Singers SET LastName = 'Richards-Smith' WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- DELETE
DELETE FROM Albums WHERE SingerId = 2;
DELETE FROM Singers WHERE SingerId = 2;
SELECT * FROM Singers WHERE SingerId = 2;
EXIT;
Spanner'da doğrulama (birkaç dakika sonra):
# Verify INSERT: This should return the new row for Elena Nadal.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 4"
# Verify UPDATE: This should show LastName as Richards-Smith.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName FROM Singers WHERE SingerId = 1"
# Verify DELETE: This should now return 0 rows.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Albums WHERE SingerId = 2"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 2"
Beklenen çıkış:
SingerId: 4 FirstName: Elena LastName: Nadal BirthDate: 1985-05-30 AlbumCount: 0 SingerId: 1 FirstName: Marc LastName: Richards-Smith
3. Spanner'da son doğrulama
Spanner'daki Singers tablosunun genel durumunu kontrol edin:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId"
Beklenen çıktı:
SingerId: 1 FirstName: Marc LastName: Richards-Smith AlbumCount: 2 SingerId: 3 FirstName: Alice LastName: Trentor AlbumCount: 3 SingerId: 4 FirstName: Elena LastName: Nadal AlbumCount: 0
10. Tersine Çoğaltmayı Ayarlama (Spanner'dan Cloud SQL'e)
Cloud SQL veritabanını bir süre için Spanner ile senkronize tutmanız veya geri döndürmeniz gerekebilecek senaryoları ele almak için ters çoğaltma ayarlayabilirsiniz. Bu ardışık düzen, Spanner'daki değişiklikleri yakalamak için Spanner Değişiklik Akışlarını kullanır ve bunları Cloud SQL'e geri yazar music_db.
1. Spanner değişiklik akışı oluşturma
Öncelikle, Singers ve Albums tablolarındaki değişiklikleri izlemek için Spanner veritabanınızda bir değişiklik akışı oluşturmanız gerekir.
export CHANGE_STREAM_NAME="MusicDBChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Singers, Albums"
Bu değişiklik akışı artık belirtilen tablolarda yapılan tüm veri değişikliklerini kaydeder.
2. Dataflow meta verileri için Spanner veritabanı oluşturma
Spanner to SourceDB Dataflow şablonu, değişiklik akışı tüketimini yönetmek için meta verileri depolamak üzere ayrı bir Spanner veritabanı gerektirir.
export SPANNER_METADATA_DB_NAME="reverse-replication-metadata"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. Dataflow için Cloud SQL bağlantı yapılandırmasını hazırlama
Dataflow şablonu, hedef Cloud SQL veritabanının bağlantı ayrıntılarını içeren bir Cloud Storage JSON dosyasına ihtiyaç duyar.
shard_config.json adlı bir yerel dosya oluşturun:
cat << EOF > shard_config.json
[
{
"logicalShardId": "mysql_shard",
"host": "${SQL_INSTANCE_IP}",
"port": "3306",
"user": "root",
"password": "${DB_ROOT_PASSWORD}",
"dbName": "music_db"
}
]
EOF
Bu dosyayı GCS paketinize yükleyin:
export SHARD_CONFIG_FILE="gs://${BUCKET_NAME}/shard_config.json"
gcloud storage cp shard_config.json $SHARD_CONFIG_FILE
4. Ters Çoğaltma Dataflow İşini Çalıştırma
Spanner_to_SourceDb Flex şablonunu kullanarak Dataflow işini başlatın.
export JOB_NAME_REVERSE="spanner-to-mysql-reverse-$(date +%Y%m%d-%H%M%S)"
export REVERSE_DLQ_DIR="gs://${BUCKET_NAME}/reverse-dlq"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$SHARD_CONFIG_FILE",\
deadLetterQueueDirectory="$REVERSE_DLQ_DIR"
Temel Parametreler
changeStreamName: Okunacak Spanner değişiklik akışının adı.metadataInstance, metadataDatabase: Bağlayıcı tarafından değişiklik akışı API verilerinin kullanımını kontrol etmek için kullanılan meta verileri depolayan Spanner örneği/veritabanı.sourceShardsFilePath:shard_config.jsondosyanızın GCS yolu.filtrationMode: Belirli kayıtların bir ölçüte göre nasıl bırakılacağını belirtir. Varsayılan olarakforward_migration(ileri taşıma ardışık düzeni kullanılarak yazılan kayıtları filtrele)
Ağ Notu: Dataflow çalışanları, shard_config.json içinde belirtilen herkese açık IP'yi kullanarak Cloud SQL örneğine bağlanır. Bu bağlantıya, Cloud SQL örneğinin Yetkili Ağları'ndaki 0.0.0.0/0 girişi nedeniyle izin verilir.
İşin başlatılmasını Dataflow İşleri Konsolu'nda izleyin.
5. Ters Çoğaltma Testi
Şimdi doğrudan Cloud Spanner'da değişiklik yapın ve bu değişikliklerin Cloud SQL'e yansıtıldığını doğrulayın. Bu işlemi yalnızca Dataflow işi başlatıldıktan ve işleme durumuna geçtikten sonra yapın.
INSERT, UPDATE ve DELETE testleri
# INSERT: Insert a new singer (SingerId 5) into Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (5, 'David', 'Chen', '1995-02-18', 0)"
# UPDATE: Update SingerId 3's AlbumCount in Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Singers SET AlbumCount = 5 WHERE SingerId = 3"
# DELETE: Delete SingerId 1 from Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Albums WHERE SingerId = 1"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Singers WHERE SingerId = 1"
Cloud SQL'de doğrulama (birkaç dakika sonra):
Cloud SQL'e bağlanın:
mysql -h $SQL_INSTANCE_IP -u root -p
İstendiğinde parolayı (Welcome@1) girin, ardından mysql> isteminde aşağıdaki SQL komutlarını çalıştırın.
USE music_db;
-- Verify INSERT: This should show the new row for David Chen
SELECT * FROM Singers WHERE SingerId = 5;
-- Verify UPDATE: This should show AlbumCount as 5.
SELECT SingerId, FirstName, AlbumCount FROM Singers WHERE SingerId = 3;
-- Verify DELETE: This should return an empty set.
SELECT * FROM Albums WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- Final Verification
SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId;
EXIT;
Cloud SQL'deki beklenen çıkış, Spanner'da yapılan değişiklikleri yansıtmalıdır.
+----------+-----------+----------------+------------+ | SingerId | FirstName | LastName | AlbumCount | +----------+-----------+----------------+------------+ | 3 | Alice | Trentor | 5 | | 4 | Elena | Nadal | 0 | | 5 | David | Chen | 0 | +----------+-----------+----------------+------------+
Bu, ters replika ardışık düzeninin çalıştığını ve Spanner'daki değişiklikleri Cloud SQL'e geri senkronize ettiğini doğrular.
11. Kaynakları Temizleme
Google Cloud hesabınızın daha fazla ücretlendirilmesini önlemek için bu codelab sırasında oluşturulan kaynakları silin.
Ortam değişkenlerini ayarlama (gerekirse)
Ortam değişkenlerinin doğru şekilde ayarlanıp ayarlanmadığını kontrol edin:
echo "PROJECT_ID: $PROJECT_ID"
echo "REGION: $REGION"
echo "SQL_INSTANCE_NAME: $SQL_INSTANCE_NAME"
echo "SPANNER_INSTANCE_NAME: $SPANNER_INSTANCE_NAME"
echo "BUCKET_NAME: $BUCKET_NAME"
echo "STREAM_NAME: $STREAM_NAME"
echo "SQL_CP_NAME: $SQL_CP_NAME"
echo "GCS_CP_NAME: $GCS_CP_NAME"
echo "PUBSUB_SUBSCRIPTION: $PUBSUB_SUBSCRIPTION"
echo "PUBSUB_TOPIC: $PUBSUB_TOPIC"
echo "CHANGE_STREAM_NAME: $CHANGE_STREAM_NAME"
Çalışan Dataflow işlerinin iş kimliklerini bulmak için işlerinizi listeleyin. JOB_ID_CDC ve JOB_ID_REVERSE öğelerini buna göre dışa aktarın.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
Yeni bir Cloud Shell oturumundaysanız anahtar ortam değişkenlerini yeniden dışa aktarın:
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or the region you used
export SQL_INSTANCE_NAME="source-mysql-instance"
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export STREAM_NAME="mysql-to-spanner-stream"
export SQL_CP_NAME="mysql-src-cp"
export GCS_CP_NAME="gcs-dest-cp"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CHANGE_STREAM_NAME="MusicDBChangeStream"
Dataflow akış işlerini durdurma
Datastream to Spanner (canlı taşıma) işini iptal edin:
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
Spanner to Cloud SQL (Ters Çoğaltma) işini iptal etme:
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
Veri akışı kaynaklarını silme
Akışı durdurup silme:
gcloud datastream streams update $STREAM_NAME \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Bağlantı Profillerini Silme
gcloud datastream connection-profiles delete $SQL_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
Pub/Sub kaynaklarını silme
Aboneliği silme:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
Konuyu silme:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
Cloud SQL örneğini silme
Bu işlem, içindeki veritabanlarını (music_db) otomatik olarak siler.
gcloud sql instances delete $SQL_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
Cloud Spanner örneğini silme
Bu işlem, içindeki veritabanlarını (music-db-migrated ve reverse-replication-metadata) da siler.
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
GCS Paketi ve İçeriğini Silme
gcloud storage rm --recursive gs://${BUCKET_NAME}
Yerel Dosyaları Silme
Cloud Shell ana dizininizde oluşturulan tüm dosyaları kaldırın:
rm -f music-db* shard_config.json
Bu codelab için oluşturulan kaynakları temizlediniz.