
1. ก่อนเริ่มต้น
Codelab นี้จะแนะนำวิธีย้ายฐานข้อมูล MySQL เดียวใน Cloud SQL ไปยังฐานข้อมูล Cloud Spanner ที่มีภาษา GoogleSQL โดยจะเน้นที่ขั้นตอนการย้ายข้อมูลตั้งแต่ต้นจนจบขั้นพื้นฐาน ซึ่งแสดงขั้นตอนหลัก คุณจะใช้บริการของ Google Cloud ซึ่งรวมถึงเครื่องมือย้ายข้อมูล Spanner (SMT), Dataflow, Datastream, PubSub และ Google Cloud Storage
สิ่งที่คุณจะได้เรียนรู้
- วิธีตั้งค่าอินสแตนซ์ Cloud SQL และ Cloud Spanner ตัวอย่าง
- วิธีแปลงสคีมา Cloud SQL MySQL เป็นสคีมาที่เข้ากันได้กับ Spanner โดยใช้เครื่องมือการย้ายข้อมูล Spanner (SMT)
- วิธีย้ายข้อมูลจำนวนมากจาก Cloud SQL ไปยัง Cloud Spanner โดยใช้ Dataflow
- วิธีตั้งค่าการจำลองอย่างต่อเนื่อง (CDC) จาก Cloud SQL ไปยัง Cloud Spanner โดยใช้ Datastream และ Dataflow
- วิธีตั้งค่าการจำลองแบบย้อนกลับจาก Cloud Spanner ไปยัง Cloud SQL
สิ่งที่ Codelab นี้ไม่ครอบคลุม
- การย้ายข้อมูลจากอินสแตนซ์ที่แยกส่วน
- การแปลงข้อมูลที่ซับซ้อนระหว่างการย้ายข้อมูล
- การจัดการข้อผิดพลาดขั้นสูงหรือคิวจดหมายที่ส่งไม่ได้ (DLQ)
- การปรับแต่งประสิทธิภาพการย้ายข้อมูล
- การย้ายข้อมูลแอปพลิเคชัน: Codelab นี้มุ่งเน้นที่เลเยอร์ฐานข้อมูล (สคีมาและข้อมูล) แต่ไม่ได้ครอบคลุมกระบวนการปฏิบัติงานในการติดตั้งใช้งานใหม่หรือการย้ายข้อมูลบริการแอปพลิเคชัน
สิ่งที่คุณต้องมี
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
- สิทธิ์ IAM ที่เพียงพอในการเปิดใช้ API และสร้าง/จัดการทรัพยากร Cloud SQL, Spanner, Dataflow, Datastream และ GCS แม้ว่าบทบาทโปรเจ็กต์
Ownerจะง่ายที่สุดสำหรับโค้ดแล็บ แต่บทบาทที่เฉพาะเจาะจงกว่าจะกล่าวถึงใน "การตั้งค่าสภาพแวดล้อม" - เว็บเบราว์เซอร์ เช่น Google Chrome
- มีความคุ้นเคยเบื้องต้นกับ Google Cloud Console และเครื่องมือบรรทัดคำสั่ง เช่น
gcloud - สิทธิ์เข้าถึงสภาพแวดล้อมเชลล์ เราขอแนะนำให้ใช้ Cloud Shell เนื่องจากมี
gcloud
รายละเอียดเพิ่มเติมเกี่ยวกับการตั้งค่าข้างต้นจะอยู่ในส่วนการตั้งค่าสภาพแวดล้อม
2. ทำความเข้าใจกระบวนการย้ายข้อมูล
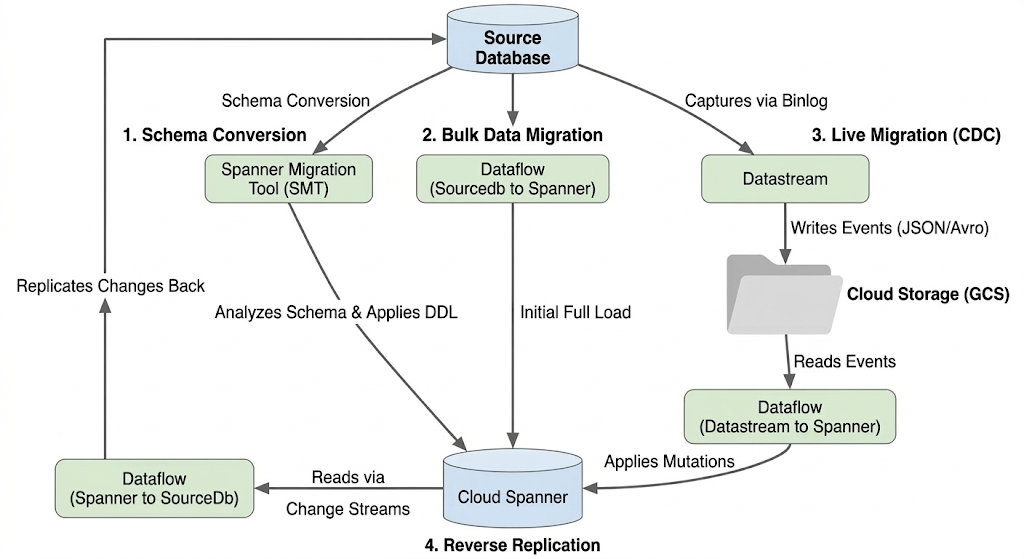
การย้ายข้อมูลฐานข้อมูลเกี่ยวข้องกับการย้ายข้อมูลจากอินสแตนซ์ฐานข้อมูล Cloud SQL ต้นทางไปยังอินสแตนซ์ Spanner ส่วนนี้จะอธิบายสถาปัตยกรรมและเครื่องมือหลักที่ใช้ในการย้ายข้อมูล
สถาปัตยกรรมโฟลว์การย้ายข้อมูล
กระบวนการย้ายข้อมูลมีขั้นตอนต่อไปนี้
1. การแปลงสคีมา
- วัตถุประสงค์: เพื่อแปลงสคีมาฐานข้อมูลต้นทางเป็นสคีมา Cloud Spanner ที่เข้ากันได้
- เครื่องมือ: เครื่องมือย้ายข้อมูล Spanner (SMT)
- กระบวนการ: SMT จะวิเคราะห์สคีมาของฐานข้อมูลต้นทางและสร้าง Data Definition Language (DDL) ของ Spanner ที่เทียบเท่า ในอินสแตนซ์ Spanner เป้าหมาย ระบบจะสร้างฐานข้อมูลและใช้ DDL โดยอัตโนมัติ
2. การย้ายข้อมูลจำนวนมาก
- วัตถุประสงค์: เพื่อทำการโหลดข้อมูลที่มีอยู่ทั้งหมดในเบื้องต้นจากฐานข้อมูลต้นทางไปยังตาราง Spanner ที่จัดสรรไว้
- เครื่องมือ: Dataflow โดยใช้
Sourcedb to Spannerเทมเพลตที่ Google จัดเตรียมให้ - กระบวนการ: งาน Dataflow นี้จะอ่านข้อมูลทั้งหมดจากตารางแหล่งที่มาระบุและเขียนลงในตาราง Spanner ที่เกี่ยวข้อง โดยจะดำเนินการหลังจากสร้างสคีมา Spanner แล้ว
3. การย้ายข้อมูลแบบสด (CDC):
- วัตถุประสงค์: เพื่อบันทึกและใช้การเปลี่ยนแปลงที่เกิดขึ้นอย่างต่อเนื่องจากฐานข้อมูลต้นทางไปยัง Cloud Spanner แบบเกือบเรียลไทม์ เพื่อลดช่วงหยุดทำงานระหว่างการย้ายข้อมูล
- เครื่องมือ:
- Datastream: บันทึกการเปลี่ยนแปลง (แทรก อัปเดต ลบ) จากฐานข้อมูลแหล่งที่มาและเขียนลงใน Cloud Storage (GCS)
- Dataflow: ใช้เทมเพลต
Datastream to Spannerเพื่ออ่านเหตุการณ์การเปลี่ยนแปลงจาก GCS และนำไปใช้กับ Cloud Spanner
4. การจำลองแบบย้อนกลับ
- วัตถุประสงค์: เพื่อจำลองการเปลี่ยนแปลงข้อมูลจาก Cloud Spanner กลับไปยังฐานข้อมูลแหล่งที่มา ซึ่งอาจมีประโยชน์สำหรับกลยุทธ์สำรอง การย้ายข้อมูลแบบค่อยเป็นค่อยไป หรือการรักษาสำเนาในแหล่งที่มาสำหรับกรณีการใช้งานที่เฉพาะเจาะจง
- เครื่องมือ: Dataflow โดยใช้
Spanner to SourceDbเทมเพลต - กระบวนการ: งานนี้ใช้สตรีมการเปลี่ยนแปลงของ Spanner เพื่อบันทึกการแก้ไขใน Spanner และเขียนกลับไปยังอินสแตนซ์ฐานข้อมูลต้นทาง
แผนภาพต่อไปนี้แสดงคอมโพเนนต์และโฟลว์ของข้อมูล
คำศัพท์สำคัญ
- เครื่องมือย้ายข้อมูล Spanner (SMT): เครื่องมือที่ใช้ประเมินสคีมา MySQL, แนะนำสคีมาที่เทียบเท่ากับ Spanner และสร้างภาษานิยามข้อมูล (DDL) ของ Spanner
- ภาษานิยามข้อมูล (DDL): คำสั่งที่ใช้เพื่อกำหนดและแก้ไขโครงสร้างฐานข้อมูล เช่น คำสั่ง
CREATE TABLESMT จะสร้าง DDL ของ Spanner ตามสคีมา Cloud SQL - Dataflow: บริการประมวลผลข้อมูลแบบ Serverless ที่มีการจัดการครบวงจร ใน Codelab นี้ จะใช้เพื่อเรียกใช้เทมเพลตที่ Google จัดเตรียมไว้สำหรับการโอนข้อมูลแบบกลุ่ม การใช้การเปลี่ยนแปลง Datastream และการจำลองแบบย้อนกลับ
- Datastream: บริการ Change Data Capture (CDC) และการจำลองแบบแบบไร้เซิร์ฟเวอร์ ซึ่งใช้เพื่อสตรีมการเปลี่ยนแปลงจาก Cloud SQL ไปยัง Cloud Storage ใน Codelab นี้
- สตรีมการเปลี่ยนแปลงของ Spanner: ฟีเจอร์ของ Spanner ที่ช่วยให้สตรีมการเปลี่ยนแปลงข้อมูล (การแทรก การอัปเดต การลบ) แบบเรียลไทม์ ซึ่งใช้เป็นแหล่งที่มาสำหรับการจำลองแบบย้อนกลับ
- Pub/Sub: บริการรับส่งข้อความที่ใช้เพื่อแยกบริการที่สร้างเหตุการณ์ออกจากบริการที่ประมวลผลเหตุการณ์ ใน Codelab นี้ จะทริกเกอร์ Dataflow เพื่อประมวลผลการอัปเดตทุกครั้งที่ Datastream อัปโหลดไฟล์การเปลี่ยนแปลงใหม่ไปยัง Cloud Storage
3. การตั้งค่าสภาพแวดล้อม
ก่อนที่จะเริ่มการย้ายข้อมูลได้ คุณต้องตั้งค่าโปรเจ็กต์ Google Cloud และเปิดใช้บริการที่จำเป็น
1. เลือกหรือสร้างโปรเจ็กต์ Google Cloud
คุณต้องมีโปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงินเพื่อใช้บริการในโค้ดแล็บนี้
- ใน Google Cloud Console ให้ไปที่หน้าตัวเลือกโปรเจ็กต์: ไปที่ตัวเลือกโปรเจ็กต์
- เลือกหรือสร้างโปรเจ็กต์ Google Cloud
- ตรวจสอบว่าโปรเจ็กต์เปิดใช้การเรียกเก็บเงินแล้ว ดูวิธียืนยันว่าโปรเจ็กต์เปิดใช้การเรียกเก็บเงินแล้ว
2. เปิด Cloud Shell
Cloud Shell เป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud ซึ่งมาพร้อมกับ gcloud CLI และเครื่องมืออื่นๆ ที่คุณต้องการ
- คลิกปุ่มเปิดใช้งาน Cloud Shell ที่ด้านขวาบนของ Google Cloud Console
- เซสชัน Cloud Shell จะเปิดในเฟรมใหม่ที่ด้านล่างของคอนโซลและแสดงข้อความแจ้งบรรทัดคำสั่ง

3. ตั้งค่าตัวแปรโปรเจ็กต์และตัวแปรสภาพแวดล้อม
ใน Cloud Shell ให้ตั้งค่าตัวแปรสภาพแวดล้อมบางอย่างสำหรับรหัสโปรเจ็กต์และภูมิภาคที่คุณจะใช้
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
4. เปิดใช้ Google Cloud APIs ที่จำเป็น
เปิดใช้ API ที่จำเป็นสำหรับ Cloud Spanner, Dataflow, Datastream และบริการอื่นๆ ที่เกี่ยวข้อง
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
คำสั่งนี้อาจใช้เวลาสักครู่จึงจะเสร็จสมบูรณ์
5. กำหนดค่าสิทธิ์ของบัญชีบริการ
งาน Dataflow และ Datastream ต้องมีสิทธิ์เฉพาะในการโต้ตอบกับบริการอื่นๆ ของ Google Cloud งาน Dataflow ใน Codelab นี้จะใช้บัญชีบริการเริ่มต้นของ Compute Engine
ก่อนอื่น ให้รับหมายเลขโปรเจ็กต์โดยทำดังนี้
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
ตอนนี้ให้มอบบทบาท IAM ที่จำเป็นให้กับบัญชีบริการเริ่มต้นของ Compute Engine โดยทำดังนี้
# Role for Dataflow to run jobs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.admin" \
--condition=None
# Roles for Dataflow workers
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.worker" \
--condition=None
# Role to connect to Cloud SQL instance
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/cloudsql.client" \
--condition=None
# Role to read/write from Cloud Spanner
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/spanner.databaseUser" \
--condition=None
# Role to access GCS buckets (Datastream output, Dataflow temp, JDBC driver)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/storage.objectAdmin" \
--condition=None
# Roles for Datastream and Pub/Sub (for CDC)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/datastream.viewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/pubsub.subscriber"
6. สร้าง Bucket ของ Cloud Storage
สร้าง Bucket ของ GCS ในภูมิภาคเดียวกับทรัพยากรอื่นๆ ที่เก็บข้อมูลนี้จะจัดเก็บไดรเวอร์ JDBC, เอาต์พุต Datastream และ Dataflow จะใช้ที่เก็บข้อมูลนี้สำหรับไฟล์ชั่วคราว
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
echo "Created bucket: gs://$BUCKET_NAME"
7. ติดตั้งเครื่องมือการย้ายข้อมูล Spanner (SMT)
ตรวจสอบว่าได้ติดตั้งเครื่องมือย้ายข้อมูล Spanner (SMT) ในสภาพแวดล้อม Cloud Shell แล้ว
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
คำสั่งนี้ควรแสดงข้อมูลความช่วยเหลือสำหรับเว็บอินเทอร์เฟซของ SMT ซึ่งเป็นการยืนยันว่าได้ติดตั้งคอมโพเนนต์ gcloud แล้ว Codelab นี้จะใช้ฟีเจอร์ CLI ของ SMT ซึ่งเป็นส่วนหนึ่งของคอมโพเนนต์เดียวกัน
4. ตั้งค่าฐานข้อมูล Cloud SQL ต้นทาง
ในส่วนนี้ คุณจะสร้างและกำหนดค่าอินสแตนซ์ Cloud SQL สำหรับ MySQL ที่มี IP สาธารณะเพื่อใช้เป็นฐานข้อมูลต้นทาง
1. สร้างอินสแตนซ์ Cloud SQL สำหรับ MySQL
เรียกใช้gcloudคำสั่งต่อไปนี้ใน Cloud Shell เพื่อสร้างอินสแตนซ์ MySQL 8.0 เปิดใช้การบันทึกไบนารี (จำเป็นสำหรับ Datastream) และกำหนดค่าอินสแตนซ์ด้วย IP สาธารณะ
export SQL_INSTANCE_NAME="source-mysql-instance"
export DB_ROOT_PASSWORD="Welcome@1" # Replace with a strong password if you prefer
gcloud sql instances create $SQL_INSTANCE_NAME \
--database-version=MYSQL_8_0 \
--tier=db-n1-standard-2 \
--region=$REGION \
--root-password=$DB_ROOT_PASSWORD \
--enable-bin-log \
--assign-ip
--enable-bin-log: ต้องใช้เพื่อให้ Datastream บันทึกการเปลี่ยนแปลงได้--assign-ip: ตรวจสอบว่าอินสแตนซ์ได้รับที่อยู่ IP สาธารณะ
การสร้างอินสแตนซ์จะใช้เวลา 2-3 นาที คุณตรวจสอบได้ว่ามีการสร้างอินสแตนซ์หรือไม่ในหน้าอินสแตนซ์ Cloud SQL
2. กำหนดค่าเครือข่ายที่ได้รับอนุญาต
หากต้องการเชื่อมต่อกับอินสแตนซ์ผ่าน IP สาธารณะ คุณต้องเพิ่มที่อยู่ IP ลงในรายการ "เครือข่ายที่ได้รับอนุญาต"
รับ IP ของ Cloud Shell โดยทำดังนี้
export CLOUD_SHELL_IP=$(curl -s ipinfo.io/ip)
echo "Your Cloud Shell IP: $CLOUD_SHELL_IP"
ให้สิทธิ์ IP ของ Cloud Shell และการเข้าถึงแบบเปิด
คำสั่งต่อไปนี้จะเพิ่ม IP ของ Cloud Shell นอกจากนี้ยังเพิ่ม 0.0.0.0/0 ซึ่งอนุญาตให้เข้าถึงจากที่อยู่ IP ใดก็ได้ ซึ่งจำเป็นต่อการลดความซับซ้อนของการเชื่อมต่อจากผู้ปฏิบัติงาน Dataflow โดยไม่ต้องตั้งค่าเครือข่ายที่ซับซ้อน
gcloud sql instances patch $SQL_INSTANCE_NAME \
--authorized-networks="${CLOUD_SHELL_IP}/32,0.0.0.0/0"
3. เชื่อมต่อกับอินสแตนซ์ Cloud SQL จาก Cloud Shell
ดึงข้อมูลที่อยู่ IP สาธารณะที่กำหนด
export SQL_INSTANCE_IP=$(gcloud sql instances list --filter="name=$SQL_INSTANCE_NAME" --format="value(PRIMARY_ADDRESS)")
echo "Cloud SQL Public IP: $SQL_INSTANCE_IP"
ระบบจะใช้ที่อยู่ IP นี้เพื่อเชื่อมต่อ
เชื่อมต่อกับอินสแตนซ์ Cloud SQL จาก Cloud Shell
ใช้ไคลเอ็นต์ MySQL มาตรฐานเพื่อเชื่อมต่อโดยใช้ที่อยู่ IP สาธารณะที่ได้รับ
mysql -h $SQL_INSTANCE_IP -u root -p
เมื่อได้รับข้อความแจ้ง ให้ป้อนรหัสผ่านรูทที่คุณตั้งไว้ (Welcome@1) ตอนนี้คุณจะอยู่ที่พรอมต์ mysql>
4. สร้างฐานข้อมูลและข้อมูลตัวอย่าง
เรียกใช้คำสั่ง SQL ต่อไปนี้ภายในพรอมต์ mysql>
CREATE DATABASE music_db;
USE music_db;
CREATE TABLE Singers (
SingerId BIGINT NOT NULL,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
BirthDate DATE,
AlbumCount BIGINT,
PRIMARY KEY (SingerId)
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY (SingerId, AlbumId),
CONSTRAINT FK_Albums_Singers FOREIGN KEY (SingerId) REFERENCES Singers (SingerId)
);
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES
(1, 'Marc', 'Richards', '1970-09-03', 2),
(2, 'Catalina', 'Smith', '1990-08-17', 1),
(3, 'Alice', 'Trentor', '1991-10-02', 3);
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle, ReleaseDate) VALUES
(1, 1, 'Total Junk', '2014-03-15'),
(1, 2, 'Go Go Go', '2016-11-01'),
(2, 1, 'Green', '2018-02-28'),
(3, 1, 'Blue', '2019-01-10'),
(3, 2, 'Red', '2020-05-22'),
(3, 3, 'Purple', '2022-11-11');
คุณดูไฟล์การทิ้งข้อมูลสำหรับสคีมาข้างต้นได้ที่นี่
5. ยืนยันข้อมูล
ตรวจสอบอย่างรวดเร็วว่ามีข้อมูลอยู่หรือไม่
SELECT 'Singers music_db' as tbl, COUNT(*) FROM music_db.Singers
UNION ALL
SELECT 'Albums music_db', COUNT(*) FROM music_db.Albums;
EXIT;
คุณควรเห็นจำนวนสำหรับแต่ละตาราง
+------------------+----------+ | tbl | COUNT(*) | +------------------+----------+ | Singers music_db | 3 | | Albums music_db | 6 | +------------------+----------+
5. ตั้งค่า Cloud Spanner
ตอนนี้คุณจะตั้งค่าอินสแตนซ์ Cloud Spanner เป้าหมายที่จะย้ายข้อมูล
1. สร้างอินสแตนซ์ Cloud Spanner
สร้างอินสแตนซ์ Cloud Spanner ในภูมิภาคเดียวกับอินสแตนซ์ Cloud SQL คำสั่งนี้จะสร้างอินสแตนซ์ขนาดเล็กที่เหมาะกับ Codelab นี้ โดยใช้หน่วยประมวลผล 100 หน่วย
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="music-db-migrated"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
การสร้างอินสแตนซ์อาจใช้เวลา 1-2 นาที
6. แปลงสคีมาโดยใช้เครื่องมือย้ายข้อมูล Spanner (SMT)
ใช้ SMT CLI เพื่อวิเคราะห์ฐานข้อมูล MySQL (music_db) และสร้าง Spanner Schema Definition Language (DDL) เนื่องจากอินสแตนซ์ Cloud SQL ได้รับการกำหนดค่าด้วย IP สาธารณะและเครือข่ายที่ได้รับอนุญาตที่เหมาะสม SMT จึงเชื่อมต่อได้โดยตรง
1. เตรียมสภาพแวดล้อมสำหรับ SMT
ตรวจสอบว่าได้ตั้งค่าตัวแปรสภาพแวดล้อมที่จำเป็นจากขั้นตอนก่อนหน้าแล้ว
echo "Cloud SQL Instance Public IP: $SQL_INSTANCE_IP"
echo "Cloud SQL Root Password: $DB_ROOT_PASSWORD"
echo "Spanner Instance: $SPANNER_INSTANCE_NAME"
echo "Spanner Database: $SPANNER_DATABASE_NAME"
echo "Project ID: $PROJECT_ID"
2. เรียกใช้การแปลงสคีมาสำหรับ music_db
เรียกใช้คำสั่ง SMT schema โดยเชื่อมต่อโดยตรงกับที่อยู่ IP สาธารณะของ Cloud SQL
gcloud alpha spanner migrate schema \
--source=mysql \
--source-profile="host=${SQL_INSTANCE_IP},port=3306,user=root,password=${DB_ROOT_PASSWORD},dbName=music_db" \
--target-profile="project=${PROJECT_ID},instance=${SPANNER_INSTANCE_NAME},dbName=${SPANNER_DATABASE_NAME}" \
--prefix="music-db"
คำสั่งนี้จะเชื่อมต่อกับอินสแตนซ์ Cloud SQL ผ่านพร็อกซีและสร้างไฟล์สคีมาที่มีคำนำหน้าเป็น music-db
3. ตรวจสอบไฟล์ที่สร้างขึ้น
SMT จะสร้างไฟล์ 2-3 ไฟล์ในไดเรกทอรีปัจจุบัน โดยมีรายการสำคัญดังนี้
music-db.schema.ddl.txt: คำสั่ง DDL ของ Spanner ที่สร้างขึ้นmusic-db-.overrides.json: สคีมาจะลบล้างไฟล์ที่มีการเปลี่ยนแปลงการแมปด้วยตนเองmusic-db.session.json: ไฟล์เซสชันของการย้ายข้อมูลสคีมาmusic-db.report.txt: รายงานการประเมินการแปลงสคีมา
คุณแสดงรายการได้โดยใช้ ls music-db-*
4. ยืนยันสคีมาใน Cloud Spanner
ตรวจสอบว่าได้สร้างตารางในฐานข้อมูล Spanner แล้ว
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
คุณควรเห็นเอาต์พุตต่อไปนี้
table_name: Albums table_name: Singers
ไม่บังคับ: หากต้องการตรวจสอบ DDL ของ Spanner ให้เรียกใช้คำสั่งต่อไปนี้
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
7. เริ่มต้น Change Data Capture (CDC)
ในส่วนนี้ คุณจะตั้งค่า "เครื่องบันทึก" สำหรับการย้ายข้อมูล การกำหนดค่า Datastream และ Pub/Sub ก่อนที่การโหลดข้อมูลแบบกลุ่มจะเริ่มขึ้นจะช่วยให้มั่นใจได้ว่าการเปลี่ยนแปลงทุกอย่างที่เกิดขึ้นกับฐานข้อมูลแหล่งที่มาจะได้รับการบันทึกและจัดคิว ซึ่งจะป้องกันไม่ให้ข้อมูลสูญหายระหว่างการเปลี่ยน การตั้งค่านี้จำเป็นสำหรับการย้ายข้อมูลแบบสด
1. สร้างโปรไฟล์การเชื่อมต่อ Datastream
โปรไฟล์แหล่งที่มา (Cloud SQL)
โปรไฟล์นี้เชื่อมต่อกับ IP สาธารณะของอินสแตนซ์ Cloud SQL Datastream จะใช้การอนุญาต IP สำหรับการเชื่อมต่อ
export SQL_CP_NAME="mysql-src-cp"
gcloud datastream connection-profiles create $SQL_CP_NAME \
--location=$REGION \
--type=mysql \
--mysql-hostname=$SQL_INSTANCE_IP \
--mysql-port=3306 \
--mysql-username=root \
--mysql-password=$DB_ROOT_PASSWORD \
--display-name="Cloud SQL Source - Public IP"
หมายเหตุ: การเชื่อมต่อนี้ขึ้นอยู่กับเครือข่ายที่ได้รับอนุญาตของอินสแตนซ์ Cloud SQL ที่อนุญาตให้เข้าถึง IP สาธารณะของ Datastream จะเชื่อมต่อได้ตามที่กำหนดค่าไว้ก่อนหน้านี้ด้วย 0.0.0.0/0 ในสภาพแวดล้อมการใช้งานจริง คุณจะต้องแทนที่ 0.0.0.0/0 ด้วยช่วง IP ที่เฉพาะเจาะจงสำหรับภูมิภาคของคุณซึ่งระบุไว้ในรายการที่อนุญาต IP และภูมิภาคของ Datastream
โปรไฟล์ปลายทาง (Cloud Storage)
ชี้ไปยังรูทของที่เก็บข้อมูล
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
2. สร้างสตรีม Datastream
สร้างสตรีมเพื่อจำลองจาก music_db
export STREAM_NAME="mysql-to-spanner-stream"
export GCS_STREAM_PATH="data/${STREAM_NAME}"
gcloud datastream streams create $STREAM_NAME \
--location=$REGION \
--display-name="MySQL to Spanner CDC Stream" \
--source=$SQL_CP_NAME \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "
includeObjects:
mysqlDatabases:
- database: 'music_db'
") \
--gcs-destination-config=<(echo "
path: ${GCS_STREAM_PATH}
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}
") \
--backfill-none
- Datastream จะเขียนไฟล์ภายใต้
gs://${BUCKET_NAME}/${GCS_STREAM_PREFIX}/ - Datastream จะเขียนไฟล์ในรูปแบบ Avro ขณะเรียกใช้คำสั่งการย้ายข้อมูลแบบสด เราจะระบุ inputFileFormat เป็น avro เพื่อให้ไปป์ไลน์ประมวลผลไฟล์ได้อย่างถูกต้อง
- การใช้การตั้งค่าการหมุนเวียนไฟล์ที่เล็กลงจะช่วยให้เห็นการเปลี่ยนแปลงใน Codelab ได้เร็วขึ้น
คำสั่งนี้อาจใช้เวลาสักครู่จึงจะเสร็จสมบูรณ์ ตรวจสอบสถานะ: gcloud datastream streams describe $STREAM_NAME --location=$REGION
3. เริ่มสตรีม Datastream
gcloud datastream streams update $STREAM_NAME \
--location=$REGION \
--state=RUNNING
ตรวจสอบสถานะ: gcloud datastream streams describe $STREAM_NAME --location=$REGION. สถานะจะเป็น STARTING ในตอนแรก และจะเปลี่ยนเป็น RUNNING หลังจากผ่านไปสักระยะ ทำขั้นตอนถัดไปหลังจากที่คุณยืนยันว่าอยู่ในสถานะ RUNNING เท่านั้น
4. ตั้งค่า Pub/Sub สำหรับการแจ้งเตือน GCS
สร้างหัวข้อ Pub/Sub
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
สร้างการแจ้งเตือนของ GCS
แจ้งเตือนเมื่อมีการสร้างออบเจ็กต์ภายใต้data/คำนำหน้า
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
สร้างการสมัครใช้บริการ Pub/Sub
ระบุวันที่ครบกำหนดในการรับทราบที่แนะนำ
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
8. ย้ายข้อมูลจาก Cloud SQL ไปยัง Spanner เป็นกลุ่ม
เมื่อมีสคีมา Spanner แล้ว คุณจะคัดลอกข้อมูลที่มีอยู่จากฐานข้อมูล Cloud SQL music_db ไปยัง Cloud Spanner ได้ คุณจะใช้Sourcedb to Spannerเทมเพลต Flex ของ Dataflow ซึ่งออกแบบมาเพื่อคัดลอกข้อมูลจำนวนมากจากฐานข้อมูลที่เข้าถึงได้ผ่าน JDBC ไปยัง Spanner
1. เรียกใช้งาน Dataflow Job สำหรับการย้ายข้อมูลแบบกลุ่มสำหรับ music_db
เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อเริ่มงาน Dataflow คำสั่งนี้ใช้คำสั่ง gcloud dataflow flex-template run โดยอ้างอิงเทมเพลตที่ Google จัดเตรียมไว้สำหรับการย้ายข้อมูล JDBC ไปยัง Spanner แบบเป็นกลุ่ม
export JOB_NAME_MUSIC="mysql-music-db-to-spanner-bulk-$(date +%Y%m%d-%H%M%S)"
export MUSIC_DB_JDBC_URL="jdbc:mysql://${SQL_INSTANCE_IP}:3306/music_db"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration-output"
gcloud dataflow flex-template run $JOB_NAME_MUSIC \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL="$MUSIC_DB_JDBC_URL",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
outputDirectory="$OUTPUT_DIR/music_db",\
username="root",\
password="$DB_ROOT_PASSWORD",\
jdbcDriverClassName="com.mysql.cj.jdbc.Driver",\
jdbcDriverJars="gs://${BUCKET_NAME}/lib/mysql-connector-j-8.0.33.jar",\
spannerHost="https://batch-spanner.googleapis.com"
คำอธิบายพารามิเตอร์หลัก
sourceConfigURL: สตริงการเชื่อมต่อ JDBC สำหรับแหล่งข้อมูลmusic_dbinstanceId,databaseId,projectId: ระบุอินสแตนซ์และฐานข้อมูล Cloud Spanner เป้าหมายoutputDirectory: เส้นทาง Cloud Storage ที่ Dataflow จะเขียนข้อมูลเกี่ยวกับระเบียนที่ย้ายข้อมูลไม่สำเร็จjdbcDriverClassName: ระบุไดรเวอร์ JDBC ของ MySQLjdbcDriverJars: เส้นทาง GCS ไปยัง JAR ของไดรเวอร์ JDBC ที่จัดเตรียมไว้spannerHost: ใช้ปลายทางที่เพิ่มประสิทธิภาพสำหรับกลุ่มสำหรับการเขียน SpannermaxWorkers,numWorkers: ควบคุมการปรับขนาดของงาน Dataflow เก็บไว้ในระดับต่ำสำหรับชุดข้อมูลขนาดเล็กนี้
หมายเหตุเกี่ยวกับเครือข่าย: งานนี้เชื่อมต่อกับอินสแตนซ์ Cloud SQL ผ่าน IP สาธารณะ ซึ่งทำได้เนื่องจากก่อนหน้านี้คุณได้เพิ่ม 0.0.0.0/0 ลงในเครือข่ายที่ได้รับอนุญาตของอินสแตนซ์ ซึ่งจะช่วยให้ VM ของผู้ปฏิบัติงาน Dataflow ที่มี IP ภายนอกเข้าถึงฐานข้อมูลได้
2. ตรวจสอบงาน Dataflow
คุณติดตามความคืบหน้าของงานได้ในคอนโซล Google Cloud โดยทำดังนี้
- ไปที่หน้างาน Dataflow: ไปที่งาน Dataflow
- ค้นหางานชื่อ
mysql-music-db-to-spanner-bulk-...แล้วคลิก - สังเกตกราฟงานและเมตริก รอให้สถานะของงานเปลี่ยนเป็นสำเร็จ การดำเนินการนี้จะใช้เวลาประมาณ 5-15 นาที
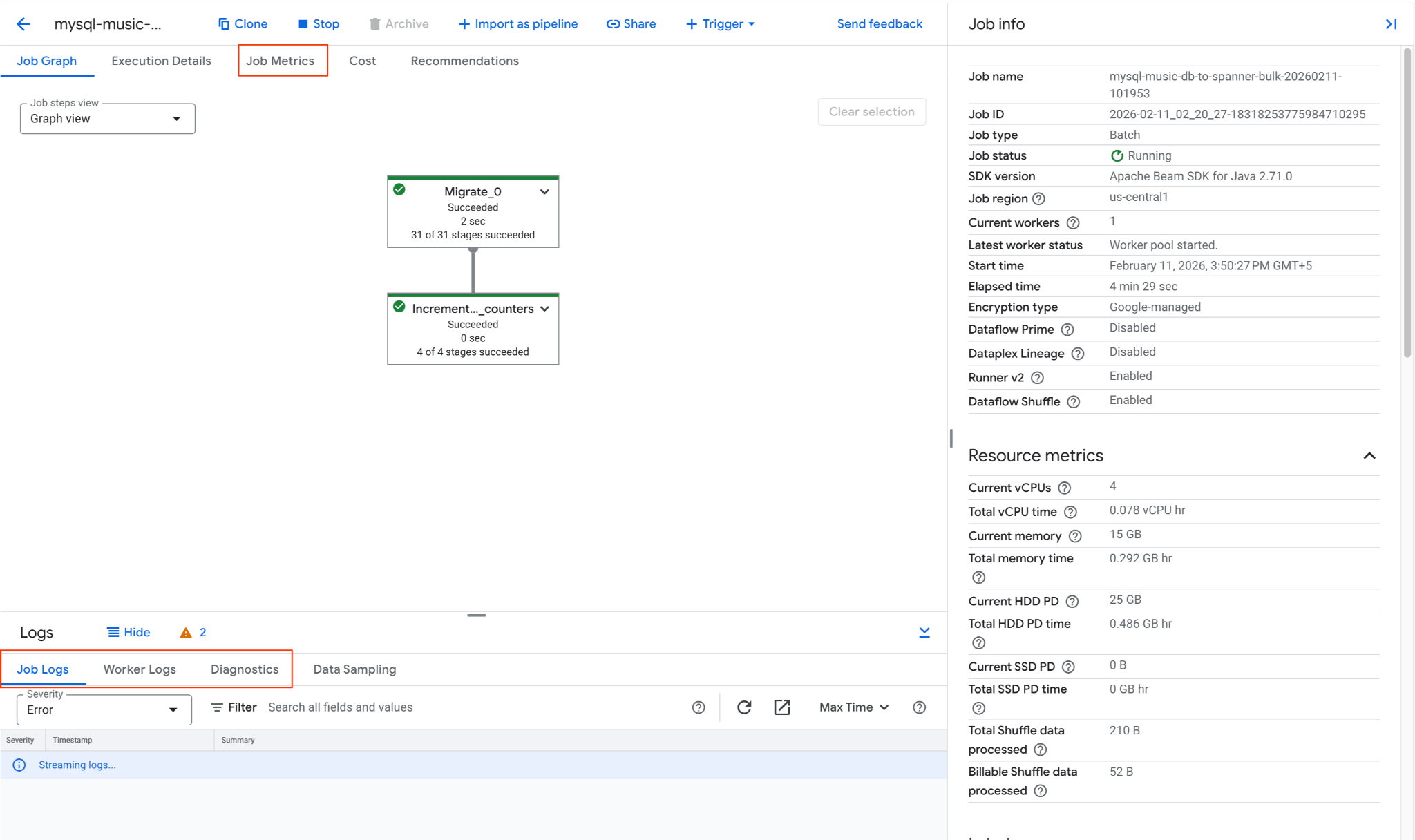
- หากงานพบปัญหา ให้ตรวจสอบแท็บบันทึกในหน้ารายละเอียดของงาน Dataflow เพื่อดูข้อความแสดงข้อผิดพลาด
- เมตริกงานจะให้ข้อมูลเพิ่มเติมเกี่ยวกับความคืบหน้าของงานและการใช้ทรัพยากร เช่น ปริมาณงานและอัตราการใช้ CPU
3. ยืนยันข้อมูลใน Cloud Spanner
เมื่องาน Dataflow เสร็จสมบูรณ์แล้ว ให้ยืนยันว่าได้คัดลอกข้อมูลไปยังตาราง Spanner แล้ว ใช้ gcloud เพื่อค้นหาฐานข้อมูล Spanner ดังนี้
# Verify row counts
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Singers"
# Expected output: 3
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Albums"
# Expected output: 6
# Inspect some data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT SingerId, FirstName, LastName FROM Singers ORDER BY SingerId"
ผลลัพธ์ที่คาดหวัง
row_count: 3 row_count: 6 SingerId: 1 FirstName: Marc LastName: Richards SingerId: 2 FirstName: Catalina LastName: Smith SingerId: 3 FirstName: Alice LastName: Trentor
การโหลดข้อมูลจำนวนมากครั้งแรกจาก Cloud SQL ไปยัง Cloud Spanner เสร็จสมบูรณ์แล้ว ขั้นตอนถัดไปคือการตั้งค่าการจำลองแบบสดเพื่อบันทึกการเปลี่ยนแปลงที่เกิดขึ้นอย่างต่อเนื่อง
9. เริ่มการย้ายข้อมูลแบบสด (CDC)
ตอนนี้การโหลดข้อมูลจำนวนมากเสร็จสมบูรณ์แล้ว คุณจะตั้งค่าสตรีมการจำลองแบบต่อเนื่องโดยใช้ Datastream เพื่อบันทึกเหตุการณ์การจับการเปลี่ยนแปลงข้อมูล (CDC) จาก Cloud SQL และงานการสตรีม Dataflow เพื่อใช้การเปลี่ยนแปลงเหล่านั้นกับ Cloud Spanner แบบเรียลไทม์
1. เรียกใช้งาน Dataflow Job ของการย้ายข้อมูลแบบสด
เปิดใช้งานงาน Dataflow แบบสตรีมมิงเพื่ออ่านจาก GCS และเขียนไปยัง Spanner เทมเพลตนี้จะใช้การแจ้งเตือน Pub/Sub ของ GCS เพื่อประมวลผลไฟล์ใหม่ทันที
export JOB_NAME_CDC="datastream-to-spanner-cdc-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR="gs://${BUCKET_NAME}/dlq"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
deadLetterQueueDirectory="$DLQ_DIR",\
streamName="projects/${PROJECT_ID}/locations/${REGION}/streams/${STREAM_NAME}"
พารามิเตอร์หลัก
gcsPubSubSubscription: การสมัครใช้บริการ Pub/Sub ที่รอรับการแจ้งเตือนไฟล์ใหม่จาก GCS ซึ่งจะช่วยให้งานประมวลผลการเปลี่ยนแปลงได้ทันทีที่ Datastream เขียนการเปลี่ยนแปลงinputFileFormat="avro": บอกให้ Dataflow คาดหวังไฟล์ Avro จาก Datastream ซึ่งต้องตรงกับการกำหนดค่า "ปลายทาง" ของ Datastream (เช่นavroFileFormatกับjsonFileFormat)deadLetterQueueDirectory: เส้นทาง GCS ที่งานจัดเก็บบันทึกที่ประมวลผลไม่สำเร็จ (เช่น เนื่องจากสคีมาไม่ตรงกัน) เพื่อให้ตรวจสอบด้วยตนเองในภายหลังstreamName: เส้นทางทรัพยากรแบบเต็มของสตรีม Datastream ซึ่งช่วยให้งาน Dataflow ติดตามสถานะการจำลองและข้อมูลเมตาได้
ตรวจสอบการเริ่มต้นงานใน Dataflow Jobs Console
2. ทดสอบการย้ายข้อมูลแบบสด
ใช้การเปลี่ยนแปลงกับ Cloud SQL ต้นทาง music_db เพื่อทดสอบไปป์ไลน์ CDC
เชื่อมต่อกับ Cloud SQL
mysql -h $SQL_INSTANCE_IP -u root -p
ป้อนรหัสผ่าน (Welcome@1) แล้วเลือกฐานข้อมูล
USE music_db;
-- INSERT
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (4, 'Elena', 'Nadal', '1985-05-30', 0);
SELECT * FROM Singers WHERE SingerId = 4;
-- UPDATE
UPDATE Singers SET LastName = 'Richards-Smith' WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- DELETE
DELETE FROM Albums WHERE SingerId = 2;
DELETE FROM Singers WHERE SingerId = 2;
SELECT * FROM Singers WHERE SingerId = 2;
EXIT;
การยืนยันใน Spanner (หลังจากผ่านไปสักครู่)
# Verify INSERT: This should return the new row for Elena Nadal.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 4"
# Verify UPDATE: This should show LastName as Richards-Smith.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName FROM Singers WHERE SingerId = 1"
# Verify DELETE: This should now return 0 rows.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Albums WHERE SingerId = 2"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 2"
ผลลัพธ์ที่คาดหวัง
SingerId: 4 FirstName: Elena LastName: Nadal BirthDate: 1985-05-30 AlbumCount: 0 SingerId: 1 FirstName: Marc LastName: Richards-Smith
3. การยืนยันขั้นสุดท้ายใน Spanner
ตรวจสอบสถานะโดยรวมของตาราง Singers ใน Spanner โดยทำดังนี้
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId"
ผลลัพธ์ที่คาดไว้
SingerId: 1 FirstName: Marc LastName: Richards-Smith AlbumCount: 2 SingerId: 3 FirstName: Alice LastName: Trentor AlbumCount: 3 SingerId: 4 FirstName: Elena LastName: Nadal AlbumCount: 0
10. ตั้งค่าการจำลองแบบย้อนกลับ (Spanner ไปยัง Cloud SQL)
หากต้องการจัดการสถานการณ์ที่คุณอาจต้องย้อนกลับหรือซิงค์ฐานข้อมูล Cloud SQL กับ Spanner เป็นระยะเวลาหนึ่ง คุณสามารถตั้งค่าการจำลองแบบย้อนกลับได้ ไปป์ไลน์นี้ใช้สตรีมการเปลี่ยนแปลงของ Spanner เพื่อบันทึกการเปลี่ยนแปลงใน Spanner และเขียนกลับไปยัง Cloud SQL music_db
1. สร้าง Change Stream ของ Spanner
ก่อนอื่น คุณต้องสร้างสตรีมการเปลี่ยนแปลงในฐานข้อมูล Spanner เพื่อติดตามการเปลี่ยนแปลงในตาราง Singers และ Albums
export CHANGE_STREAM_NAME="MusicDBChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Singers, Albums"
ตอนนี้สตรีมการเปลี่ยนแปลงนี้จะบันทึกการแก้ไขข้อมูลทั้งหมดในตารางที่ระบุ
2. สร้างฐานข้อมูล Spanner สำหรับข้อมูลเมตาของ Dataflow
Spanner to SourceDB เทมเพลต Dataflow ต้องใช้ฐานข้อมูล Spanner แยกต่างหากเพื่อจัดเก็บข้อมูลเมตาสำหรับการจัดการการใช้สตรีมการเปลี่ยนแปลง
export SPANNER_METADATA_DB_NAME="reverse-replication-metadata"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
3. เตรียมการกำหนดค่าการเชื่อมต่อ Cloud SQL สำหรับ Dataflow
เทมเพลต Dataflow ต้องมีไฟล์ JSON ใน Cloud Storage ซึ่งมีรายละเอียดการเชื่อมต่อสำหรับฐานข้อมูล Cloud SQL เป้าหมาย
สร้างไฟล์ในเครื่องชื่อ shard_config.json:
cat << EOF > shard_config.json
[
{
"logicalShardId": "mysql_shard",
"host": "${SQL_INSTANCE_IP}",
"port": "3306",
"user": "root",
"password": "${DB_ROOT_PASSWORD}",
"dbName": "music_db"
}
]
EOF
อัปโหลดไฟล์นี้ไปยังที่เก็บข้อมูล GCS
export SHARD_CONFIG_FILE="gs://${BUCKET_NAME}/shard_config.json"
gcloud storage cp shard_config.json $SHARD_CONFIG_FILE
4. เรียกใช้งาน Dataflow Job ของการจำลองแบบย้อนกลับ
เปิดใช้งานงาน Dataflow โดยใช้ Spanner_to_SourceDbFlex Template
export JOB_NAME_REVERSE="spanner-to-mysql-reverse-$(date +%Y%m%d-%H%M%S)"
export REVERSE_DLQ_DIR="gs://${BUCKET_NAME}/reverse-dlq"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$SHARD_CONFIG_FILE",\
deadLetterQueueDirectory="$REVERSE_DLQ_DIR"
พารามิเตอร์หลัก
changeStreamName: ชื่อของสตรีมการเปลี่ยนแปลง Spanner ที่จะอ่านmetadataInstance, metadataDatabase: อินสแตนซ์/ฐานข้อมูล Spanner เพื่อจัดเก็บข้อมูลเมตาที่ตัวเชื่อมต่อใช้เพื่อควบคุมการใช้ข้อมูล Change Stream APIsourceShardsFilePath: เส้นทาง GCS ไปยังshard_config.jsonfiltrationMode: ระบุวิธีทิ้งบางระเบียนตามเกณฑ์ ค่าเริ่มต้นคือforward_migration(กรองระเบียนที่เขียนโดยใช้ไปป์ไลน์การย้ายข้อมูลไปข้างหน้า)
หมายเหตุเกี่ยวกับเครือข่าย: ผู้ปฏิบัติงาน Dataflow จะเชื่อมต่อกับอินสแตนซ์ Cloud SQL โดยใช้ IP สาธารณะที่ระบุใน shard_config.json การเชื่อมต่อนี้ได้รับอนุญาตเนื่องจากมีรายการ 0.0.0.0/0 ในเครือข่ายที่ได้รับอนุญาตของอินสแตนซ์ Cloud SQL
ตรวจสอบการเริ่มต้นงานใน Dataflow Jobs Console
5. ทดสอบการจำลองแบบย้อนกลับ
ตอนนี้คุณสามารถทำการเปลี่ยนแปลงใน Cloud Spanner โดยตรงและตรวจสอบว่าการเปลี่ยนแปลงดังกล่าวแสดงใน Cloud SQL แล้ว ให้ทำขั้นตอนนี้เมื่อเริ่มงาน Dataflow แล้วและอยู่ในสถานะกำลังประมวลผลเท่านั้น
ทดสอบ INSERT, UPDATE และ DELETE
# INSERT: Insert a new singer (SingerId 5) into Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (5, 'David', 'Chen', '1995-02-18', 0)"
# UPDATE: Update SingerId 3's AlbumCount in Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Singers SET AlbumCount = 5 WHERE SingerId = 3"
# DELETE: Delete SingerId 1 from Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Albums WHERE SingerId = 1"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Singers WHERE SingerId = 1"
การยืนยันใน Cloud SQL (หลังจากผ่านไปสักครู่)
เชื่อมต่อกับ Cloud SQL
mysql -h $SQL_INSTANCE_IP -u root -p
ป้อนรหัสผ่าน (Welcome@1) เมื่อได้รับข้อความแจ้ง จากนั้นเรียกใช้คำสั่ง SQL ต่อไปนี้ที่พรอมต์ mysql>
USE music_db;
-- Verify INSERT: This should show the new row for David Chen
SELECT * FROM Singers WHERE SingerId = 5;
-- Verify UPDATE: This should show AlbumCount as 5.
SELECT SingerId, FirstName, AlbumCount FROM Singers WHERE SingerId = 3;
-- Verify DELETE: This should return an empty set.
SELECT * FROM Albums WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- Final Verification
SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId;
EXIT;
เอาต์พุตที่คาดไว้ใน Cloud SQL ควรแสดงการเปลี่ยนแปลงที่ทำใน Spanner
+----------+-----------+----------------+------------+ | SingerId | FirstName | LastName | AlbumCount | +----------+-----------+----------------+------------+ | 3 | Alice | Trentor | 5 | | 4 | Elena | Nadal | 0 | | 5 | David | Chen | 0 | +----------+-----------+----------------+------------+
ซึ่งเป็นการยืนยันว่าไปป์ไลน์การจำลองแบบย้อนกลับทำงานอยู่ โดยจะซิงค์การเปลี่ยนแปลงจาก Spanner กลับไปยัง Cloud SQL
11. ล้างข้อมูลทรัพยากร
โปรดลบทรัพยากรที่สร้างขึ้นระหว่างการทำ Codelab นี้เพื่อหลีกเลี่ยงการเรียกเก็บเงินเพิ่มเติมในบัญชี Google Cloud
ตั้งค่าตัวแปรสภาพแวดล้อม (หากจำเป็น)
ตรวจสอบว่าได้ตั้งค่าตัวแปรสภาพแวดล้อมอย่างถูกต้องหรือไม่
echo "PROJECT_ID: $PROJECT_ID"
echo "REGION: $REGION"
echo "SQL_INSTANCE_NAME: $SQL_INSTANCE_NAME"
echo "SPANNER_INSTANCE_NAME: $SPANNER_INSTANCE_NAME"
echo "BUCKET_NAME: $BUCKET_NAME"
echo "STREAM_NAME: $STREAM_NAME"
echo "SQL_CP_NAME: $SQL_CP_NAME"
echo "GCS_CP_NAME: $GCS_CP_NAME"
echo "PUBSUB_SUBSCRIPTION: $PUBSUB_SUBSCRIPTION"
echo "PUBSUB_TOPIC: $PUBSUB_TOPIC"
echo "CHANGE_STREAM_NAME: $CHANGE_STREAM_NAME"
แสดงรายการงานเพื่อค้นหารหัสงานของงาน Dataflow ที่กําลังทํางาน ส่งออก JOB_ID_CDC และ JOB_ID_REVERSE ตามนั้น
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
หากอยู่ในเซสชัน Cloud Shell ใหม่ ให้ส่งออกตัวแปรสภาพแวดล้อมของคีย์อีกครั้งโดยทำดังนี้
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or the region you used
export SQL_INSTANCE_NAME="source-mysql-instance"
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export STREAM_NAME="mysql-to-spanner-stream"
export SQL_CP_NAME="mysql-src-cp"
export GCS_CP_NAME="gcs-dest-cp"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CHANGE_STREAM_NAME="MusicDBChangeStream"
หยุดงานสตรีมมิง Dataflow
ยกเลิกงาน Datastream to Spanner (การย้ายข้อมูลแบบสด) โดยทำดังนี้
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
ยกเลิกงาน Spanner to Cloud SQL (การจำลองแบบย้อนกลับ)
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
ลบทรัพยากร Datastream
หยุดและลบสตรีม
gcloud datastream streams update $STREAM_NAME \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
ลบโปรไฟล์การเชื่อมต่อ
gcloud datastream connection-profiles delete $SQL_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
ลบทรัพยากร Pub/Sub
ลบการสมัครใช้บริการ
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
ลบหัวข้อ
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
ลบอินสแตนซ์ Cloud SQL
ซึ่งจะลบฐานข้อมูล (music_db) ภายในโดยอัตโนมัติ
gcloud sql instances delete $SQL_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
ลบอินสแตนซ์ Cloud Spanner
การดำเนินการนี้จะลบฐานข้อมูล (music-db-migrated และ reverse-replication-metadata) ภายในด้วย
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
ลบ Bucket และเนื้อหาของ GCS
gcloud storage rm --recursive gs://${BUCKET_NAME}
ลบไฟล์ในเครื่อง
นำไฟล์ที่สร้างในไดเรกทอรีหน้าแรกของ Cloud Shell ออกโดยทำดังนี้
rm -f music-db* shard_config.json
ตอนนี้คุณได้ล้างข้อมูลทรัพยากรที่สร้างขึ้นสำหรับ Codelab นี้แล้ว