
۱. قبل از شروع
این آزمایشگاه کد شما را در مهاجرت یک پایگاه داده MySQL واحد روی Cloud SQL به یک پایگاه داده Cloud Spanner با گویش GoogleSQL راهنمایی میکند. تمرکز بر جریان اساسی مهاجرت سرتاسری است و مراحل اصلی را نشان میدهد. شما از سرویسهای Google Cloud شامل ابزار مهاجرت Spanner (SMT)، Dataflow، Datastream، PubSub و Google Cloud Storage استفاده خواهید کرد.
آنچه یاد خواهید گرفت:
- نحوه راهاندازی نمونههای Cloud SQL و Cloud Spanner.
- نحوه تبدیل یک طرحواره Cloud SQL MySQL به یک طرحواره سازگار با Spanner با استفاده از ابزار مهاجرت Spanner (SMT).
- نحوه انجام مهاجرت حجم زیادی از دادهها از Cloud SQL به Cloud Spanner با استفاده از Dataflow.
- نحوه تنظیم تکثیر مداوم (CDC) از Cloud SQL به Cloud Spanner با استفاده از Datastream و Dataflow.
- نحوه تنظیم همانندسازی معکوس از Cloud Spanner به Cloud SQL.
آنچه این آزمایشگاه کد پوشش نمیدهد:
- مهاجرت از نمونههای خرد شده.
- تبدیلهای پیچیده دادهها در طول مهاجرت.
- مدیریت پیشرفته خطا یا صفهای نامههای از کار افتاده (DLQ).
- تنظیم عملکرد مهاجرت.
- مهاجرت برنامه: این آزمایشگاه کد بر لایه پایگاه داده (طرحواره و داده) تمرکز دارد. این آزمایشگاه فرآیند عملیاتی استقرار مجدد یا مهاجرت سرویسهای برنامه شما را پوشش نمیدهد.
آنچه نیاز دارید
- یک پروژه گوگل کلود با قابلیت پرداخت.
- مجوزهای کافی IAM برای فعال کردن APIها و ایجاد/مدیریت منابع Cloud SQL، Spanner، Dataflow، Datastream و GCS. در حالی که نقش
Ownerپروژه برای یک آزمایشگاه کد سادهترین نقش است، نقشهای خاصتر در «تنظیمات محیط» پوشش داده خواهند شد. - یک مرورگر وب، مانند گوگل کروم.
- آشنایی اولیه با کنسول گوگل کلود و ابزارهای خط فرمان مانند
gcloud. - دسترسی به محیط shell. استفاده از Cloud Shell توصیه میشود زیرا شامل
gcloudمیشود.
جزئیات بیشتر در مورد تنظیمات فوق در بخش تنظیمات محیط پوشش داده شده است.
۲. درک فرآیند مهاجرت
مهاجرت یک پایگاه داده شامل انتقال دادهها از نمونه پایگاه داده CloudSQL منبع شما به یک نمونه Spanner است. این بخش معماری و ابزارهای کلیدی مورد استفاده در این مهاجرت را شرح میدهد.
معماری جریان مهاجرت
روند مهاجرت شامل این مراحل است:
۱. تبدیل طرحواره:
- هدف: تبدیل طرحواره پایگاه داده منبع به یک طرحواره سازگار با Cloud Spanner.
- ابزار: ابزار مهاجرت Spanner (SMT)
- فرآیند: SMT طرحواره پایگاه داده منبع را تجزیه و تحلیل میکند و معادل آن را تولید میکند. زبان تعریف داده Spanner (DDL). در نمونه Spanner هدف، یک پایگاه داده ایجاد میشود و سپس DDL به طور خودکار اعمال میشود.
۲. مهاجرت دادههای حجیم:
- هدف: انجام بارگذاری اولیه و کامل دادههای موجود از پایگاه داده منبع به جداول Spanner فراهم شده.
- ابزار: Dataflow، با استفاده از الگوی
Sourcedb to Spannerارائه شده توسط گوگل. - فرآیند: این کار Dataflow تمام دادهها را از جداول منبع مشخص شده میخواند و آنها را در جداول Spanner مربوطه مینویسد. این کار پس از ایجاد طرحواره Spanner انجام میشود.
۳. مهاجرت زنده (CDC):
- هدف: ثبت و اعمال تغییرات مداوم از پایگاه داده منبع به Cloud Spanner به صورت تقریباً بلادرنگ، و به حداقل رساندن زمان از کارافتادگی در طول مهاجرت.
- ابزارها:
- جریان داده: تغییرات (درج، بهروزرسانی، حذف) را از پایگاه داده منبع ثبت کرده و آنها را در فضای ذخیرهسازی ابری (GCS) مینویسد.
- جریان داده: از الگوی
Datastream to Spannerبرای خواندن رویدادهای تغییر از GCS و اعمال آنها به Cloud Spanner استفاده میکند.
۴. همانندسازی معکوس:
- هدف: تکرار تغییرات دادهها از Cloud Spanner به پایگاه داده منبع. این میتواند برای استراتژیهای بازگشت به نسخه قبلی، مهاجرتهای مرحلهای یا حفظ یک نسخه مشابه در منبع برای موارد استفاده خاص مفید باشد.
- ابزار: Dataflow، با استفاده از الگوی
Spanner to SourceDb. - فرآیند: این کار از جریانهای تغییر Spanner برای ثبت تغییرات در Spanner و نوشتن مجدد آنها در نمونه پایگاه داده منبع استفاده میکند.
نمودار زیر اجزا و جریان داده را نشان میدهد:

اصطلاحات کلیدی:
- ابزار مهاجرت Spanner (SMT) : ابزاری که برای ارزیابی طرحوارههای MySQL، پیشنهاد معادلهای طرحواره Spanner و تولید زبان تعریف داده Spanner (DDL) استفاده میشود.
- زبان تعریف داده (DDL): دستوراتی که برای تعریف و تغییر ساختار پایگاه داده استفاده میشوند، مانند دستورات
CREATE TABLE. SMT دستورات DDL مربوط به Spanner را بر اساس طرح Cloud SQL تولید میکند. - Dataflow : یک سرویس پردازش داده کاملاً مدیریتشده و بدون سرور. در این آزمایشگاه کد، از آن برای اجرای قالبهای ارائه شده توسط گوگل برای انتقال دادههای انبوه، اعمال تغییرات Datastream و تکثیر معکوس استفاده میشود.
- Datastream : یک سرویس ضبط و تکثیر تغییرات (CDC) بدون سرور. در این آزمایشگاه کد، برای انتقال تغییرات از Cloud SQL به Cloud Storage استفاده میشود.
- Spanner Change Streams : یک ویژگی Spanner که امکان ارسال تغییرات در دادهها (درج، بهروزرسانی، حذف) را به صورت بلادرنگ فراهم میکند و به عنوان منبعی برای تکثیر معکوس استفاده میشود.
- Pub/Sub : یک سرویس پیامرسانی است که برای جدا کردن سرویسهایی که رویدادها را تولید میکنند از سرویسهایی که آنها را پردازش میکنند، استفاده میشود. در این آزمایشگاه کد، این سرویس، Dataflow را برای پردازش بهروزرسانیها، هر زمان که Datastream فایلهای تغییر جدید را در Cloud Storage آپلود میکند، فعال میکند.
۳. تنظیمات محیطی
قبل از شروع مهاجرت، باید پروژه Google Cloud خود را راهاندازی کرده و سرویسهای لازم را فعال کنید.
۱. یک پروژه گوگل کلود انتخاب یا ایجاد کنید
برای استفاده از خدمات این آزمایشگاه کد، به یک پروژه گوگل کلود با قابلیت پرداخت نیاز دارید.
- در کنسول گوگل کلود، به صفحه انتخاب پروژه بروید: به انتخابگر پروژه بروید
- یک پروژه Google Cloud انتخاب یا ایجاد کنید.
- مطمئن شوید که صورتحساب برای پروژه شما فعال است. یاد بگیرید که چگونه تأیید کنید که صورتحساب برای پروژه شما فعال است .
۲. پوسته ابری را باز کنید
Cloud Shell یک محیط خط فرمان است که در Google Cloud اجرا میشود و از قبل با رابط خط فرمان gcloud و سایر ابزارهای مورد نیاز شما بارگذاری شده است.
- روی دکمهی «فعالسازی پوستهی ابری» در سمت راست بالای کنسول ابری گوگل کلیک کنید.
- یک جلسه Cloud Shell درون یک قاب جدید در پایین کنسول باز میشود و یک اعلان خط فرمان را نمایش میدهد.

۳. تنظیم متغیرهای پروژه و محیط
در Cloud Shell، برخی از متغیرهای محیطی را برای شناسه پروژه و منطقهای که استفاده خواهید کرد، تنظیم کنید.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or your preferred region
export ZONE="us-central1-a" # Or a zone within your selected region
gcloud config set project $PROJECT_ID
gcloud config set compute/region $REGION
gcloud config set compute/zone $ZONE
echo "Project ID: $PROJECT_ID"
echo "Region: $REGION"
echo "Zone: $ZONE"
۴. فعال کردن APIهای مورد نیاز گوگل کلود
APIهای لازم برای Cloud Spanner، Dataflow، Datastream و سایر سرویسهای مرتبط را فعال کنید.
gcloud services enable \
spanner.googleapis.com \
dataflow.googleapis.com \
datastream.googleapis.com \
pubsub.googleapis.com \
storage.googleapis.com \
compute.googleapis.com \
sqladmin.googleapis.com \
servicenetworking.googleapis.com \
cloudresourcemanager.googleapis.com
اجرای این دستور ممکن است چند دقیقه طول بکشد.
۵. پیکربندی مجوزهای حساب سرویس
وظایف Dataflow و Datastream برای تعامل با سایر سرویسهای Google Cloud به مجوزهای خاصی نیاز دارند. وظایف Dataflow در این آزمایشگاه کد از حساب کاربری پیشفرض سرویس Compute Engine استفاده خواهند کرد.
ابتدا، شماره پروژه خود را دریافت کنید:
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SA_EMAIL="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
اکنون، نقشهای IAM مورد نیاز را به حساب سرویس پیشفرض Compute Engine اعطا کنید:
# Role for Dataflow to run jobs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.admin" \
--condition=None
# Roles for Dataflow workers
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/dataflow.worker" \
--condition=None
# Role to connect to Cloud SQL instance
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/cloudsql.client" \
--condition=None
# Role to read/write from Cloud Spanner
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/spanner.databaseUser" \
--condition=None
# Role to access GCS buckets (Datastream output, Dataflow temp, JDBC driver)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/storage.objectAdmin" \
--condition=None
# Roles for Datastream and Pub/Sub (for CDC)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/datastream.viewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/pubsub.subscriber"
۶. یک فضای ذخیرهسازی ابری ایجاد کنید
یک سطل GCS در همان ناحیهای که سایر منابع شما قرار دارند، ایجاد کنید. این سطل درایور JDBC و خروجی Datastream را ذخیره میکند و توسط Dataflow برای فایلهای موقت استفاده میشود.
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
echo "Created bucket: gs://$BUCKET_NAME"
۷. ابزار مهاجرت Spanner (SMT) را نصب کنید
مطمئن شوید که ابزار مهاجرت Spanner (SMT) در محیط Cloud Shell شما نصب شده است.
sudo apt-get update && sudo apt-get install google-cloud-cli-spanner-migration-tool
# Verify installation
gcloud alpha spanner migrate web --help
این دستور باید اطلاعات راهنما را برای رابط وب SMT نمایش دهد و تأیید کند که مؤلفه gcloud نصب شده است. این آزمایشگاه کد از ویژگیهای رابط خط فرمان (CLI) SMT که بخشی از همان مؤلفه هستند، استفاده خواهد کرد.
۴. پایگاه داده SQL ابری منبع را تنظیم کنید
در این بخش، شما یک نمونه Cloud SQL برای MySQL با IP عمومی ایجاد و پیکربندی خواهید کرد تا به عنوان پایگاه داده منبع عمل کند.
۱. یک Cloud SQL برای نمونه MySQL ایجاد کنید
دستور gcloud زیر را در Cloud Shell اجرا کنید تا یک نمونه MySQL 8.0 ایجاد شود. ثبت وقایع دودویی فعال است (برای Datastream لازم است) و نمونه با یک IP عمومی پیکربندی شده است.
export SQL_INSTANCE_NAME="source-mysql-instance"
export DB_ROOT_PASSWORD="Welcome@1" # Replace with a strong password if you prefer
gcloud sql instances create $SQL_INSTANCE_NAME \
--database-version=MYSQL_8_0 \
--tier=db-n1-standard-2 \
--region=$REGION \
--root-password=$DB_ROOT_PASSWORD \
--enable-bin-log \
--assign-ip
-
--enable-bin-log: برای ثبت تغییرات توسط Datastream مورد نیاز است. -
--assign-ip: تضمین میکند که نمونه یک آدرس IP عمومی دریافت میکند.
ایجاد نمونه چند دقیقه طول خواهد کشید. میتوانید بررسی کنید که آیا نمونه شما در صفحه نمونههای CloudSQL ایجاد شده است یا خیر.
۲. پیکربندی شبکههای مجاز
برای اتصال به نمونه از طریق IP عمومی، باید آدرسهای IP را به لیست «شبکههای مجاز» اضافه کنید.
آیپی Cloud Shell خود را دریافت کنید:
export CLOUD_SHELL_IP=$(curl -s ipinfo.io/ip)
echo "Your Cloud Shell IP: $CLOUD_SHELL_IP"
IP و دسترسی آزاد Cloud Shell را مجاز کنید
دستور زیر IP مربوط به Cloud Shell شما را اضافه میکند. همچنین 0.0.0.0/0 را اضافه میکند که امکان دسترسی از هر آدرس IP را فراهم میکند. این کار برای سادهسازی اتصالات از Dataflow workerها بدون تنظیمات پیچیده شبکه ضروری است.
gcloud sql instances patch $SQL_INSTANCE_NAME \
--authorized-networks="${CLOUD_SHELL_IP}/32,0.0.0.0/0"
۳. از طریق Cloud Shell به Cloud SQL Instance متصل شوید
آدرس IP عمومی اختصاص داده شده را دریافت کنید
export SQL_INSTANCE_IP=$(gcloud sql instances list --filter="name=$SQL_INSTANCE_NAME" --format="value(PRIMARY_ADDRESS)")
echo "Cloud SQL Public IP: $SQL_INSTANCE_IP"
این آدرس IP برای اتصال استفاده خواهد شد.
اتصال به نمونه SQL ابری از CloudShell
برای اتصال از کلاینت استاندارد mysql و با استفاده از آدرس IP عمومی به دست آمده استفاده کنید:
mysql -h $SQL_INSTANCE_IP -u root -p
وقتی از شما خواسته شد، رمز عبور root که تنظیم کردهاید ( Welcome@1 ) را وارد کنید. اکنون در اعلان mysql> خواهید بود.
۴. ایجاد پایگاه داده و نمونهبرداری از دادهها
دستورات SQL زیر را در اعلان mysql> اجرا کنید:
CREATE DATABASE music_db;
USE music_db;
CREATE TABLE Singers (
SingerId BIGINT NOT NULL,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
BirthDate DATE,
AlbumCount BIGINT,
PRIMARY KEY (SingerId)
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY (SingerId, AlbumId),
CONSTRAINT FK_Albums_Singers FOREIGN KEY (SingerId) REFERENCES Singers (SingerId)
);
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES
(1, 'Marc', 'Richards', '1970-09-03', 2),
(2, 'Catalina', 'Smith', '1990-08-17', 1),
(3, 'Alice', 'Trentor', '1991-10-02', 3);
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle, ReleaseDate) VALUES
(1, 1, 'Total Junk', '2014-03-15'),
(1, 2, 'Go Go Go', '2016-11-01'),
(2, 1, 'Green', '2018-02-28'),
(3, 1, 'Blue', '2019-01-10'),
(3, 2, 'Red', '2020-05-22'),
(3, 3, 'Purple', '2022-11-11');
فایل dump مربوط به طرحواره فوق را میتوانید اینجا پیدا کنید.
۵. دادهها را تأیید کنید
به سرعت بررسی کنید که دادهها موجود هستند:
SELECT 'Singers music_db' as tbl, COUNT(*) FROM music_db.Singers
UNION ALL
SELECT 'Albums music_db', COUNT(*) FROM music_db.Albums;
EXIT;
شما باید تعداد هر جدول را ببینید.
+------------------+----------+ | tbl | COUNT(*) | +------------------+----------+ | Singers music_db | 3 | | Albums music_db | 6 | +------------------+----------+
۵. تنظیم اسپنر ابری
اکنون، نمونهی هدف Cloud Spanner را که دادهها به آن منتقل خواهند شد، تنظیم خواهید کرد.
۱. یک نمونهی Cloud Spanner ایجاد کنید
یک نمونه Cloud Spanner در همان ناحیهای که نمونه Cloud SQL شما قرار دارد، ایجاد کنید. این دستور با استفاده از ۱۰۰ واحد پردازش، یک نمونه کوچک مناسب برای این آزمایشگاه کد ایجاد میکند.
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export SPANNER_DATABASE_NAME="music-db-migrated"
export SPANNER_CONFIG="regional-${REGION}"
gcloud spanner instances create $SPANNER_INSTANCE_NAME \
--config=$SPANNER_CONFIG \
--description="Target Spanner Instance" \
--processing-units=100
ایجاد نمونه ممکن است یک یا دو دقیقه طول بکشد.
۶. تبدیل طرحواره با استفاده از ابزار مهاجرت Spanner (SMT)
از رابط خط فرمان SMT برای تجزیه و تحلیل پایگاه داده MySQL ( music_db ) و تولید زبان تعریف طرحواره Spanner (DDL) استفاده کنید. از آنجایی که نمونه Cloud SQL با IP عمومی و شبکههای مجاز مناسب پیکربندی شده است، SMT میتواند مستقیماً متصل شود.
۱. آمادهسازی محیط برای SMT
تأیید کنید که متغیرهای محیطی لازم از مراحل قبلی تنظیم شدهاند:
echo "Cloud SQL Instance Public IP: $SQL_INSTANCE_IP"
echo "Cloud SQL Root Password: $DB_ROOT_PASSWORD"
echo "Spanner Instance: $SPANNER_INSTANCE_NAME"
echo "Spanner Database: $SPANNER_DATABASE_NAME"
echo "Project ID: $PROJECT_ID"
۲. اجرای تبدیل طرحواره برای music_db
دستور SMT schema را اجرا کنید و مستقیماً به آدرس IP عمومی Cloud SQL متصل شوید:
gcloud alpha spanner migrate schema \
--source=mysql \
--source-profile="host=${SQL_INSTANCE_IP},port=3306,user=root,password=${DB_ROOT_PASSWORD},dbName=music_db" \
--target-profile="project=${PROJECT_ID},instance=${SPANNER_INSTANCE_NAME},dbName=${SPANNER_DATABASE_NAME}" \
--prefix="music-db"
این دستور از طریق پروکسی به نمونه Cloud SQL متصل میشود و فایلهای طرحوارهای با پیشوند music-db تولید میکند.
۳. بررسی فایلهای تولید شده
SMT چند فایل در دایرکتوری فعلی شما ایجاد میکند. فایلهای کلیدی عبارتند از:
-
music-db.schema.ddl.txt: دستورات DDL تولید شده Spanner. -
music-db-.overrides.json: این طرحواره، فایل حاوی تغییرات نگاشت دستی را لغو میکند. -
music-db.session.json: فایل جلسه مربوط به مهاجرت طرحواره. -
music-db.report.txt: یک گزارش ارزیابی از تبدیل طرحواره.
میتوانید آنها را با استفاده از ls music-db-* فهرست کنید.
۴. تأیید طرحواره در Cloud Spanner
بررسی کنید که جداول در پایگاه داده Spanner ایجاد شده باشند.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT table_name FROM information_schema.tables WHERE table_schema = '' ORDER BY table_name"
شما باید خروجی زیر را ببینید:
table_name: Albums table_name: Singers
اختیاری: اگر میخواهید Spanner DDL را بررسی کنید، دستور زیر را اجرا کنید:
gcloud spanner databases ddl describe $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME
۷. مقداردهی اولیهی ثبت دادههای تغییر (CDC)
در این بخش، شما "ضبط کننده" را برای مهاجرت خود تنظیم خواهید کرد. با پیکربندی Datastream و Pub/Sub قبل از شروع بارگذاری دادههای حجیم، اطمینان حاصل میکنید که هر تغییری که در پایگاه داده منبع ایجاد میشود، ثبت و در صف قرار میگیرد و از هرگونه از دست رفتن دادهها در طول انتقال جلوگیری میشود. این تنظیمات برای مهاجرت زنده مورد نیاز است.
۱. ایجاد پروفایلهای اتصال جریان داده
پروفایل منبع (SQL ابری)
این پروفایل به IP عمومی نمونه Cloud SQL متصل میشود. Datastream از لیست مجاز IP برای اتصال استفاده خواهد کرد.
export SQL_CP_NAME="mysql-src-cp"
gcloud datastream connection-profiles create $SQL_CP_NAME \
--location=$REGION \
--type=mysql \
--mysql-hostname=$SQL_INSTANCE_IP \
--mysql-port=3306 \
--mysql-username=root \
--mysql-password=$DB_ROOT_PASSWORD \
--display-name="Cloud SQL Source - Public IP"
توجه: این اتصال به شبکههای مجاز نمونه Cloud SQL که اجازه دسترسی میدهند، متکی است. همانطور که قبلاً با 0.0.0.0/0 پیکربندی شده بود، IPهای عمومی Datastream میتوانند متصل شوند. در یک محیط عملیاتی، شما باید 0.0.0.0/0 با محدودههای IP خاص برای منطقه خود که در فهرستهای مجاز IP Datastream و مناطق ذکر شده است، جایگزین کنید.
نمایه مقصد (فضای ذخیرهسازی ابری)
به ریشه سطل شما اشاره میکند.
export GCS_CP_NAME="gcs-dest-cp"
gcloud datastream connection-profiles create $GCS_CP_NAME \
--location=$REGION \
--type=google-cloud-storage \
--bucket=$BUCKET_NAME \
--root-path=/ \
--display-name="GCS Destination" --force
۲. ایجاد یک جریان داده
جریانی را برای تکثیر از music_db ایجاد کنید.
export STREAM_NAME="mysql-to-spanner-stream"
export GCS_STREAM_PATH="data/${STREAM_NAME}"
gcloud datastream streams create $STREAM_NAME \
--location=$REGION \
--display-name="MySQL to Spanner CDC Stream" \
--source=$SQL_CP_NAME \
--destination=$GCS_CP_NAME \
--mysql-source-config=<(echo "
includeObjects:
mysqlDatabases:
- database: 'music_db'
") \
--gcs-destination-config=<(echo "
path: ${GCS_STREAM_PATH}
fileRotationMb: 5
fileRotationInterval: 15s
avroFileFormat: {}
") \
--backfill-none
- جریان داده، فایلها را در مسیر
gs://${BUCKET_NAME}/${GCS_STREAM_PREFIX}/مینویسد. - Datastream فایلها را با فرمت Avro مینویسد. هنگام اجرای دستور مهاجرت زنده، inputFileFormat را روی avro مشخص میکنیم تا pipeline بتواند فایل را به درستی پردازش کند.
- استفاده از تنظیمات چرخش فایل کوچکتر به مشاهده سریعتر تغییرات در codelab کمک میکند.
تکمیل این دستور ممکن است کمی طول بکشد. وضعیت را بررسی کنید: gcloud datastream streams describe $STREAM_NAME --location=$REGION .
۳. شروع جریان داده
gcloud datastream streams update $STREAM_NAME \
--location=$REGION \
--state=RUNNING
بررسی وضعیت: gcloud datastream streams describe $STREAM_NAME --location=$REGION. این وضعیت در ابتدا در STARTING خواهد بود و پس از مدتی به RUNNING ) تبدیل میشود. تنها پس از تأیید اینکه در حالت RUNNING قرار دارد، به مرحله بعدی بروید.
۴. تنظیمات Pub/Sub را برای اعلانهای GCS انجام دهید
ایجاد یک موضوع عمومی/زیرموضوعی:
export PUBSUB_TOPIC="datastream-gcs-updates"
gcloud pubsub topics create $PUBSUB_TOPIC
ایجاد اعلان GCS
اطلاع رسانی در مورد ایجاد شیء تحت data/ پیشوند.
gcloud storage buckets notifications create gs://${BUCKET_NAME} --topic=projects/$PROJECT_ID/topics/$PUBSUB_TOPIC --payload-format=json --object-prefix=data/
ایجاد اشتراک در میخانه/زیرمجموعه
مهلت تأیید توصیه شده را نیز ذکر کنید.
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
gcloud pubsub subscriptions create $PUBSUB_SUBSCRIPTION \
--topic=$PUBSUB_TOPIC \
--ack-deadline=600
۸. انتقال انبوه دادهها از Cloud SQL به Spanner
با فعال بودن طرحواره Spanner، اکنون دادههای موجود را از پایگاه داده Cloud SQL music_db خود به Cloud Spanner کپی خواهید کرد. شما از الگوی Sourcedb to Spanner Dataflow Flex استفاده خواهید کرد که برای کپی کردن انبوه دادهها از پایگاههای داده قابل دسترسی با JDBC به Spanner طراحی شده است.
۱. اجرای عملیات انتقال دادهی Bulk Migration برای music_db
برای شروع کار Dataflow، دستور زیر را در Cloud Shell اجرا کنید. این دستور از دستور gcloud dataflow flex-template run استفاده میکند و به الگوی ارائه شده توسط گوگل برای مهاجرتهای JDBC به Spanner اشاره دارد.
export JOB_NAME_MUSIC="mysql-music-db-to-spanner-bulk-$(date +%Y%m%d-%H%M%S)"
export MUSIC_DB_JDBC_URL="jdbc:mysql://${SQL_INSTANCE_IP}:3306/music_db"
export OUTPUT_DIR="gs://${BUCKET_NAME}/bulk-migration-output"
gcloud dataflow flex-template run $JOB_NAME_MUSIC \
--project=$PROJECT_ID \
--region=$REGION \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Sourcedb_to_Spanner_Flex" \
--max-workers=2 \
--num-workers=1 \
--worker-machine-type=n2-highmem-8 \
--parameters \
sourceConfigURL="$MUSIC_DB_JDBC_URL",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
outputDirectory="$OUTPUT_DIR/music_db",\
username="root",\
password="$DB_ROOT_PASSWORD",\
jdbcDriverClassName="com.mysql.cj.jdbc.Driver",\
jdbcDriverJars="gs://${BUCKET_NAME}/lib/mysql-connector-j-8.0.33.jar",\
spannerHost="https://batch-spanner.googleapis.com"
پارامترهای کلیدی توضیح داده شده:
-
sourceConfigURL: رشته اتصال JDBC برای منبعmusic_db. -
instanceId،databaseId،projectId: نمونه و پایگاه داده هدف Cloud Spanner را مشخص میکند. -
outputDirectory: یک مسیر ذخیرهسازی ابری که Dataflow اطلاعات مربوط به رکوردهایی که مهاجرت آنها ناموفق بوده است را در آن مینویسد. -
jdbcDriverClassName: درایور JDBC مربوط به MySQL را مشخص میکند. -
jdbcDriverJars: مسیر GCS به JAR درایور JDBC مرحلهبندیشده. -
spannerHost: از نقطه پایانی بهینهسازیشده برای نوشتنهای Spanner استفاده میکند. -
maxWorkersوnumWorkers: مقیاسبندی کار Dataflow را کنترل میکند. برای این مجموعه داده کوچک، مقدار آن پایین نگه داشته میشود.
نکته شبکه: این کار از طریق IP عمومی به نمونه Cloud SQL متصل میشود. این امر به این دلیل امکانپذیر است که شما قبلاً 0.0.0.0/0 به شبکههای مجاز نمونه اضافه کردهاید. این به ماشینهای مجازی Dataflow worker که دارای IPهای خارجی هستند، اجازه میدهد تا به پایگاه داده دسترسی پیدا کنند.
۲. نظارت بر کار جریان داده
میتوانید پیشرفت کار را در کنسول ابری گوگل پیگیری کنید:
- به صفحه مشاغل Dataflow بروید: به Dataflow Jobs بروید
- وظیفهای با نام
mysql-music-db-to-spanner-bulk-...را پیدا کرده و روی آن کلیک کنید. - نمودار و معیارهای کار را مشاهده کنید. منتظر بمانید تا وضعیت کار به «موفق» تغییر کند. این کار تقریباً ۵ تا ۱۵ دقیقه طول میکشد.
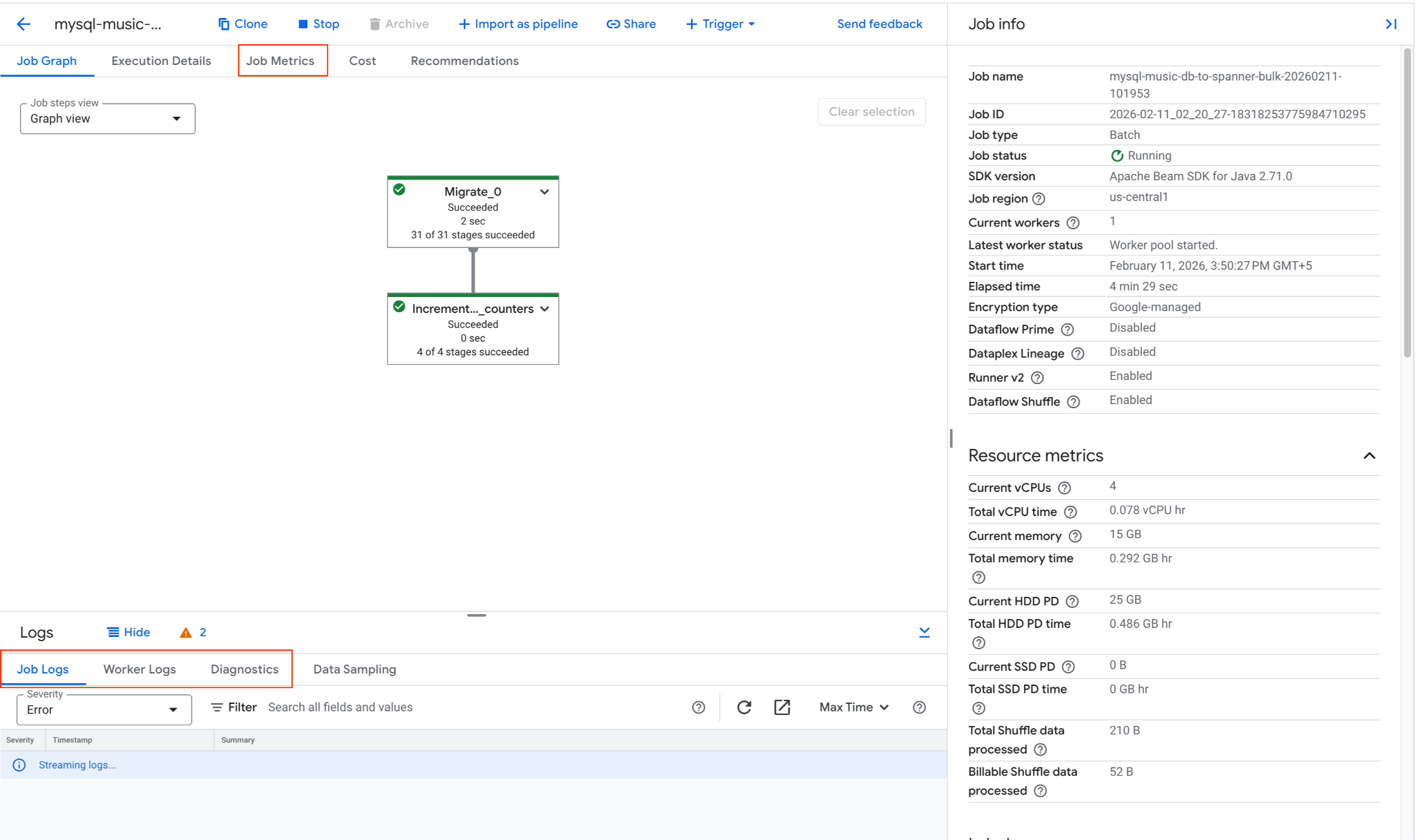
- اگر کار با مشکلاتی مواجه شد، تب Logs را در صفحه جزئیات کار Dataflow برای پیامهای خطا بررسی کنید.
- معیارهای کار، اطلاعات بیشتری در مورد پیشرفت کار و میزان مصرف منابع مانند توان عملیاتی و میزان استفاده از CPU ارائه میدهد.
۳. تأیید دادهها در Cloud Spanner
پس از اتمام موفقیتآمیز کار Dataflow، تأیید کنید که دادهها در جداول Spanner کپی شدهاند. gcloud برای پرسوجو از پایگاه داده Spanner استفاده کنید:
# Verify row counts
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Singers"
# Expected output: 3
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT COUNT(*) as row_count FROM Albums"
# Expected output: 6
# Inspect some data
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME --instance=$SPANNER_INSTANCE_NAME --sql="SELECT SingerId, FirstName, LastName FROM Singers ORDER BY SingerId"
خروجی مورد انتظار:
row_count: 3 row_count: 6 SingerId: 1 FirstName: Marc LastName: Richards SingerId: 2 FirstName: Catalina LastName: Smith SingerId: 3 FirstName: Alice LastName: Trentor
بارگذاری اولیه حجم زیادی از دادهها از Cloud SQL به Cloud Spanner اکنون تکمیل شده است. گام بعدی راهاندازی تکثیر زنده برای ثبت تغییرات مداوم است.
۹. شروع مهاجرت زنده (CDC)
اکنون که بارگذاری دادههای حجیم تکمیل شده است، شما یک جریان تکرار مداوم با استفاده از Datastream برای ثبت رویدادهای Change Data Capture (CDC) از Cloud SQL و یک کار جریانسازی Dataflow برای اعمال این تغییرات به Cloud Spanner تقریباً به صورت بلادرنگ راهاندازی خواهید کرد.
۱. اجرای کار Live Migration Dataflow
کار Streaming Dataflow را برای خواندن از GCS و نوشتن در Spanner اجرا کنید. این الگو از اعلانهای GCS Pub/Sub برای پردازش فوری فایلهای جدید استفاده میکند.
export JOB_NAME_CDC="datastream-to-spanner-cdc-$(date +%Y%m%d-%H%M%S)"
export DLQ_DIR="gs://${BUCKET_NAME}/dlq"
gcloud dataflow flex-template run $JOB_NAME_CDC \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Cloud_Datastream_to_Spanner" \
--parameters \
gcsPubSubSubscription="projects/${PROJECT_ID}/subscriptions/${PUBSUB_SUBSCRIPTION}",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
projectId="$PROJECT_ID",\
inputFileFormat="avro",\
deadLetterQueueDirectory="$DLQ_DIR",\
streamName="projects/${PROJECT_ID}/locations/${REGION}/streams/${STREAM_NAME}"
پارامترهای کلیدی
-
gcsPubSubSubscription: اشتراک Pub/Sub که به اعلانهای فایل جدید از GCS گوش میدهد. این به job اجازه میدهد تا تغییرات را فوراً همزمان با نوشتن آنها توسط Datastream پردازش کند. -
inputFileFormat="avro": به Dataflow میگوید که فایلهای Avro را از Datastream دریافت کند. این باید با پیکربندی "مقصد" Datastream شما مطابقت داشته باشد (مثلاًavroFileFormatدر مقابلjsonFileFormat). -
deadLetterQueueDirectory: یک مسیر GCS که در آن کار، رکوردهایی را که پردازش آنها با شکست مواجه شده است (مثلاً به دلیل عدم تطابق طرحواره) برای بررسی دستی بعدی ذخیره میکند. -
streamName: مسیر کامل منبع جریان Datastream، که به Dataflow job اجازه میدهد وضعیت تکثیر و فراداده را ردیابی کند.
شروع کار را در کنسول کارهای Dataflow نظارت کنید.
۲. تست مهاجرت زنده
برای آزمایش خط لوله CDC، تغییرات را در منبع Cloud SQL music_db اعمال کنید.
اتصال به SQL ابری:
mysql -h $SQL_INSTANCE_IP -u root -p
رمز عبور ( Welcome@1 ) را وارد کنید و پایگاه داده را انتخاب کنید:
USE music_db;
-- INSERT
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (4, 'Elena', 'Nadal', '1985-05-30', 0);
SELECT * FROM Singers WHERE SingerId = 4;
-- UPDATE
UPDATE Singers SET LastName = 'Richards-Smith' WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- DELETE
DELETE FROM Albums WHERE SingerId = 2;
DELETE FROM Singers WHERE SingerId = 2;
SELECT * FROM Singers WHERE SingerId = 2;
EXIT;
تأیید در Spanner (پس از چند لحظه):
# Verify INSERT: This should return the new row for Elena Nadal.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 4"
# Verify UPDATE: This should show LastName as Richards-Smith.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName FROM Singers WHERE SingerId = 1"
# Verify DELETE: This should now return 0 rows.
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Albums WHERE SingerId = 2"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT * FROM Singers WHERE SingerId = 2"
خروجی مورد انتظار:
SingerId: 4 FirstName: Elena LastName: Nadal BirthDate: 1985-05-30 AlbumCount: 0 SingerId: 1 FirstName: Marc LastName: Richards-Smith
۳. تأیید نهایی در Spanner
وضعیت کلی جدول Singers را در Spanner بررسی کنید:
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId"
خروجی مورد انتظار:
SingerId: 1 FirstName: Marc LastName: Richards-Smith AlbumCount: 2 SingerId: 3 FirstName: Alice LastName: Trentor AlbumCount: 3 SingerId: 4 FirstName: Elena LastName: Nadal AlbumCount: 0
۱۰. راهاندازی Reverse Replication (انتقال به Cloud SQL)
برای مدیریت سناریوهایی که ممکن است نیاز به بازگرداندن یا همگامسازی پایگاه داده Cloud SQL با Spanner برای مدتی داشته باشید، میتوانید تکثیر معکوس را تنظیم کنید. این خط لوله از Spanner Change Streams برای ثبت تغییرات در Spanner استفاده میکند و آنها را در Cloud SQL music_db مینویسد.
۱. یک جریان تغییر سریع ایجاد کنید
ابتدا، باید یک جریان تغییر در پایگاه داده Spanner خود ایجاد کنید تا تغییرات روی جداول Singers و Albums را ردیابی کنید.
export CHANGE_STREAM_NAME="MusicDBChangeStream"
gcloud spanner databases ddl update $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--ddl="CREATE CHANGE STREAM $CHANGE_STREAM_NAME FOR Singers, Albums"
این جریان تغییر اکنون تمام تغییرات دادهها را در جداول مشخص شده ثبت میکند.
۲. ایجاد یک پایگاه داده Spanner برای متادیتای Dataflow
الگوی Spanner to SourceDB Dataflow به یک پایگاه داده Spanner جداگانه برای ذخیره فراداده جهت مدیریت مصرف جریان تغییر نیاز دارد.
export SPANNER_METADATA_DB_NAME="reverse-replication-metadata"
gcloud spanner databases create $SPANNER_METADATA_DB_NAME \
--instance=$SPANNER_INSTANCE_NAME
۳. پیکربندی اتصال Cloud SQL را برای Dataflow آماده کنید
الگوی Dataflow به یک فایل JSON در Cloud Storage نیاز دارد که حاوی جزئیات اتصال برای پایگاه داده Cloud SQL هدف باشد.
یک فایل محلی با نام shard_config.json ایجاد کنید:
cat << EOF > shard_config.json
[
{
"logicalShardId": "mysql_shard",
"host": "${SQL_INSTANCE_IP}",
"port": "3306",
"user": "root",
"password": "${DB_ROOT_PASSWORD}",
"dbName": "music_db"
}
]
EOF
این فایل را در مخزن GCS خود آپلود کنید:
export SHARD_CONFIG_FILE="gs://${BUCKET_NAME}/shard_config.json"
gcloud storage cp shard_config.json $SHARD_CONFIG_FILE
۴. اجرای عملیات Reverse Replication Dataflow
کار Dataflow را با استفاده از الگوی Spanner_to_SourceDb Flex آغاز کنید.
export JOB_NAME_REVERSE="spanner-to-mysql-reverse-$(date +%Y%m%d-%H%M%S)"
export REVERSE_DLQ_DIR="gs://${BUCKET_NAME}/reverse-dlq"
gcloud dataflow flex-template run $JOB_NAME_REVERSE \
--project=$PROJECT_ID \
--region=$REGION \
--worker-machine-type=n2-highmem-8 \
--max-workers=2 \
--num-workers=1 \
--additional-experiments=use_runner_v2 \
--template-file-gcs-location="gs://dataflow-templates-${REGION}/latest/flex/Spanner_to_SourceDb" \
--parameters \
changeStreamName="$CHANGE_STREAM_NAME",\
instanceId="$SPANNER_INSTANCE_NAME",\
databaseId="$SPANNER_DATABASE_NAME",\
spannerProjectId="$PROJECT_ID",\
metadataInstance="$SPANNER_INSTANCE_NAME",\
metadataDatabase="$SPANNER_METADATA_DB_NAME",\
sourceShardsFilePath="$SHARD_CONFIG_FILE",\
deadLetterQueueDirectory="$REVERSE_DLQ_DIR"
پارامترهای کلیدی
-
changeStreamName: نام جریان تغییر Spanner که قرار است از آن خوانده شود. -
metadataInstance, metadataDatabase: نمونه/پایگاه داده Spanner برای ذخیره متادیتای مورد استفاده توسط کانکتور جهت کنترل مصرف دادههای API جریان تغییر. -
sourceShardsFilePath: مسیر GCS بهshard_config.jsonشما. -
filtrationMode: نحوه حذف رکوردهای خاص را بر اساس یک معیار مشخص میکند. مقدار پیشفرضforward_migrationاست (فیلتر رکوردهای نوشته شده با استفاده از خط لوله مهاجرت رو به جلو)
نکته شبکه: کارگران Dataflow با استفاده از IP عمومی مشخص شده در shard_config.json به نمونه Cloud SQL متصل میشوند. این اتصال به دلیل ورودی 0.0.0.0/0 در شبکههای مجاز نمونه Cloud SQL مجاز است.
شروع کار را در کنسول کارهای Dataflow نظارت کنید.
۵. تست تکرار معکوس
اکنون، تغییرات را مستقیماً در Cloud Spanner اعمال کنید و تأیید کنید که آنها در Cloud SQL منعکس شدهاند. این کار را فقط زمانی انجام دهید که کار جریان داده شروع شده و در حالت پردازش باشد.
تست INSERT ، UPDATE و DELETE
# INSERT: Insert a new singer (SingerId 5) into Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate, AlbumCount) VALUES (5, 'David', 'Chen', '1995-02-18', 0)"
# UPDATE: Update SingerId 3's AlbumCount in Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="UPDATE Singers SET AlbumCount = 5 WHERE SingerId = 3"
# DELETE: Delete SingerId 1 from Spanner
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Albums WHERE SingerId = 1"
gcloud spanner databases execute-sql $SPANNER_DATABASE_NAME \
--instance=$SPANNER_INSTANCE_NAME \
--sql="DELETE FROM Singers WHERE SingerId = 1"
تأیید در Cloud SQL (پس از چند لحظه):
اتصال به SQL ابری:
mysql -h $SQL_INSTANCE_IP -u root -p
در صورت درخواست، رمز عبور ( Welcome@1 ) را وارد کنید، سپس دستورات SQL زیر را در اعلان mysql> اجرا کنید.
USE music_db;
-- Verify INSERT: This should show the new row for David Chen
SELECT * FROM Singers WHERE SingerId = 5;
-- Verify UPDATE: This should show AlbumCount as 5.
SELECT SingerId, FirstName, AlbumCount FROM Singers WHERE SingerId = 3;
-- Verify DELETE: This should return an empty set.
SELECT * FROM Albums WHERE SingerId = 1;
SELECT * FROM Singers WHERE SingerId = 1;
-- Final Verification
SELECT SingerId, FirstName, LastName, AlbumCount FROM Singers ORDER BY SingerId;
EXIT;
خروجی مورد انتظار در Cloud SQL باید منعکس کننده تغییرات ایجاد شده در Spanner باشد.
+----------+-----------+----------------+------------+ | SingerId | FirstName | LastName | AlbumCount | +----------+-----------+----------------+------------+ | 3 | Alice | Trentor | 5 | | 4 | Elena | Nadal | 0 | | 5 | David | Chen | 0 | +----------+-----------+----------------+------------+
این امر تأیید میکند که خط لوله تکثیر معکوس در حال کار است و تغییرات را از Spanner به Cloud SQL همگامسازی میکند.
۱۱. پاکسازی منابع
برای جلوگیری از تحمیل هزینههای بیشتر به حساب Google Cloud خود، منابع ایجاد شده در طول این آزمایش کد را حذف کنید.
تنظیم متغیرهای محیطی (در صورت نیاز)
بررسی کنید که آیا متغیرهای محیطی به درستی تنظیم شدهاند یا خیر:
echo "PROJECT_ID: $PROJECT_ID"
echo "REGION: $REGION"
echo "SQL_INSTANCE_NAME: $SQL_INSTANCE_NAME"
echo "SPANNER_INSTANCE_NAME: $SPANNER_INSTANCE_NAME"
echo "BUCKET_NAME: $BUCKET_NAME"
echo "STREAM_NAME: $STREAM_NAME"
echo "SQL_CP_NAME: $SQL_CP_NAME"
echo "GCS_CP_NAME: $GCS_CP_NAME"
echo "PUBSUB_SUBSCRIPTION: $PUBSUB_SUBSCRIPTION"
echo "PUBSUB_TOPIC: $PUBSUB_TOPIC"
echo "CHANGE_STREAM_NAME: $CHANGE_STREAM_NAME"
برای یافتن شناسههای (ID) کارهای جریان داده در حال اجرا، کارهای خود را فهرست کنید. بر این اساس، JOB_ID_CDC و JOB_ID_REVERSE را صادر کنید.
gcloud dataflow jobs list --region=$REGION --filter="state=Running"
export JOB_ID_CDC=<PASTE_JOB_ID_HERE>
export JOB_ID_REVERSE=<PASTE_JOB_ID_HERE>
اگر در یک جلسه جدید Cloud Shell هستید، متغیرهای کلیدی محیط را دوباره صادر کنید:
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1" # Or the region you used
export SQL_INSTANCE_NAME="source-mysql-instance"
export SPANNER_INSTANCE_NAME="target-spanner-instance"
export BUCKET_NAME="migration-${PROJECT_ID}-bucket"
export STREAM_NAME="mysql-to-spanner-stream"
export SQL_CP_NAME="mysql-src-cp"
export GCS_CP_NAME="gcs-dest-cp"
export PUBSUB_TOPIC="datastream-gcs-updates"
export PUBSUB_SUBSCRIPTION="datastream-gcs-sub"
export CHANGE_STREAM_NAME="MusicDBChangeStream"
توقف کارهای مربوط به استریمینگ جریان داده
لغو کار Datastream to Spanner (Live Migration):
gcloud dataflow jobs cancel $JOB_ID_CDC --region=$REGION --project=$PROJECT_ID
لغو کار Spanner to Cloud SQL (Reverse Replication):
gcloud dataflow jobs cancel $JOB_ID_REVERSE --region=$REGION --project=$PROJECT_ID
حذف منابع جریان داده
توقف و حذف جریان:
gcloud datastream streams update $STREAM_NAME \
--location=$REGION --state=PAUSED --project=$PROJECT_ID
# Wait a moment for the stream to pause
gcloud datastream streams delete $STREAM_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
حذف پروفایلهای اتصال
gcloud datastream connection-profiles delete $SQL_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
gcloud datastream connection-profiles delete $GCS_CP_NAME \
--location=$REGION --project=$PROJECT_ID --quiet
حذف منابع Pub/Sub
حذف اشتراک:
gcloud pubsub subscriptions delete $PUBSUB_SUBSCRIPTION \
--project=$PROJECT_ID --quiet
حذف تاپیک:
gcloud pubsub topics delete $PUBSUB_TOPIC \
--project=$PROJECT_ID --quiet
حذف نمونه SQL ابری
این کار به طور خودکار پایگاههای داده ( music_db ) درون آن را حذف میکند.
gcloud sql instances delete $SQL_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
حذف نمونه Cloud Spanner
این کار همچنین پایگاههای داده ( music-db-migrated و reverse-replication-metadata ) موجود در آن را حذف خواهد کرد.
gcloud spanner instances delete $SPANNER_INSTANCE_NAME \
--project=$PROJECT_ID --quiet
حذف سطل و محتویات GCS
gcloud storage rm --recursive gs://${BUCKET_NAME}
حذف فایلهای محلی
هر فایلی که در دایرکتوری خانگی Cloud Shell شما ایجاد شده است را حذف کنید:
rm -f music-db* shard_config.json
اکنون منابع ایجاد شده برای این آزمایشگاه کد را پاکسازی کردهاید.