
1. 소개
데이터에서 유용한 정보를 얻으려면 상당한 시간과 노력, 깊이 있는 SQL 전문 지식이 필요합니다. 이 Codelab에서는 대화형 데이터 에이전트를 통해 즉각적인 AI 기반 인사이트를 제공하는 새로운 플랫폼인 BigQuery의 에이전트 카탈로그를 살펴봅니다.
선별된 데이터 에이전트를 만들어 간단한 텍스트-SQL 변환을 넘어설 수 있습니다. 매우 정확한 결과를 보장하기 위해 비즈니스 컨텍스트, 시스템 안내, 검증된 질문으로 에이전트를 보강하는 방법을 알아봅니다. 마지막으로 조직의 다른 사용자가 사용할 수 있도록 이 에이전트를 게시합니다.
기본 요건
- Google Cloud에 대한 기본적인 이해
학습할 내용
- BigQuery 에이전트 카탈로그를 탐색하는 방법
- 맞춤 에이전트를 만들고 지식 소스를 정의하는 방법
- Gemini를 사용하여 시맨틱 메타데이터를 생성하는 방법
- 시스템 안내 및 검증된 질문을 추가하여 에이전트를 안내하는 방법
- 에이전트를 게시하고 공유하는 방법
필요한 항목
- Google Cloud 계정 및 Google Cloud 프로젝트
- BigQuery 및 SQL에 관한 기본 지식
- 웹브라우저(예: Chrome)
2. 설정 및 요건
프로젝트 선택
- Google Cloud Console에 로그인하여 새 프로젝트를 만들거나 기존 프로젝트를 재사용합니다. 아직 Gmail이나 Google Workspace 계정이 없는 경우 계정을 만들어야 합니다.


- 프로젝트 이름은 이 프로젝트 참가자의 표시 이름입니다. 이는 Google API에서 사용하지 않는 문자열이며 언제든지 업데이트할 수 있습니다.
- 프로젝트 ID는 모든 Google Cloud 프로젝트에서 고유하며, 변경할 수 없습니다(설정된 후에는 변경할 수 없음). Cloud 콘솔은 고유한 문자열을 자동으로 생성합니다. 일반적으로는 신경 쓰지 않아도 됩니다. 대부분의 Codelab에서는 프로젝트 ID (일반적으로
PROJECT_ID로 식별됨)를 참조해야 합니다. 생성된 ID가 마음에 들지 않으면 다른 임의 ID를 생성할 수 있습니다. 또는 직접 시도해 보고 사용 가능한지 확인할 수도 있습니다. 이 단계 이후에는 변경할 수 없으며 프로젝트 기간 동안 유지됩니다. - 참고로 세 번째 값은 일부 API에서 사용하는 프로젝트 번호입니다. 이 세 가지 값에 대한 자세한 내용은 문서를 참고하세요.
- 다음으로 Cloud 리소스/API를 사용하려면 Cloud 콘솔에서 결제를 사용 설정해야 합니다. 이 Codelab 실행에는 많은 비용이 들지 않습니다. 이 튜토리얼이 끝난 후에 요금이 청구되지 않도록 리소스를 종료하려면 만든 리소스 또는 프로젝트를 삭제하면 됩니다. Google Cloud 신규 사용자는 300달러(USD) 상당의 무료 체험판 프로그램에 참여할 수 있습니다.
3. 시작하기 전에
필수 역할 부여
프로젝트의 IAM 페이지로 이동하여 Gemini 데이터 분석 데이터 에이전트 소유자 역할을 부여합니다.

이 역할은 프로젝트의 모든 데이터 에이전트를 생성, 수정, 공유, 삭제할 수 있는 권한을 부여합니다.
필요한 API 사용 설정
사이드바 탐색 메뉴 또는 페이지 상단의 검색 메뉴를 사용하여 BigQuery > 에이전트로 이동합니다.
Gemini 기반 Data Analytics API 사용 설정을 클릭합니다.

BigQuery의 Gemini API와 Google Cloud를 위한 Gemini API를 모두 사용 설정합니다.
이제 새 에이전트 페이지가 표시됩니다.

4. 에이전트 만들기
Google 트렌드 국제 공개 데이터 세트를 사용하여 첫 번째 데이터 에이전트를 만들어 보겠습니다. 이 데이터 세트는 전 세계적으로 인기 급상승 중인 검색어와 이러한 관심사가 과거와 어떻게 비교되는지에 관한 질문에 유용합니다.
먼저 에이전트의 이름과 간단한 설명을 지정합니다. 이 설명은 다른 사용자가 에이전트의 목적을 이해하는 데만 사용됩니다.
에이전트 이름
Google Trends Agent
에이전트 설명
Data agent for the Google Trends International Top Terms public dataset
지식 소스
이제 지식 소스를 추가합니다. 지식 소스는 에이전트가 질문에 답변하는 데 사용할 수 있는 BigQuery 테이블, 뷰 또는 UDF입니다.
이 데모에서는 간단하게 테이블 하나만 추가합니다. 하지만 더 복잡한 데이터 시나리오를 처리하기 위해 에이전트당 최대 50개의 지식 소스를 추가할 수 있습니다.
검색창에 다음 표를 입력하고 체크박스를 선택한 후 추가를 클릭합니다.
bigquery-public-data.google_trends.international_top_terms

구조화된 컨텍스트
데이터 에이전트의 정확성을 개선하려면 테이블과 열에 구조화된 컨텍스트를 추가하세요. Customise을 클릭합니다.

Gemini가 설명에 대한 추천을 자동으로 생성합니다. 표 설명 옆에 있는 수락을 클릭합니다.

모든 열에 설명을 적용하려면 모든 행 선택을 선택한 다음 추천 수락을 클릭합니다.

페이지 하단의 업데이트를 클릭하여 변경사항을 저장하고 에이전트 편집기로 돌아갑니다.
안내
에이전트 지침 대화상자에서는 에이전트가 데이터 소스를 해석하고 쿼리할 수 있도록 추가 안내를 제공할 수 있습니다. 여기에는 다음이 포함됩니다.
- 동의어: 주요 필드의 대체 용어입니다.
- 주요 필드: 분석에 가장 중요한 필드입니다.
- 제외된 필드: 데이터 에이전트가 피해야 하는 필드입니다.
- 필터링 및 그룹화: 에이전트가 데이터를 필터링하고 그룹화하는 데 사용할 필드입니다.
- 조인 관계: 공통 필드를 기준으로 둘 이상의 테이블이 결합되는 방식입니다.
다음 안내를 복사하여 붙여넣습니다.
### System Instruction
* You are an expert data analyst for the Google Trends International public dataset.
* Always filter on yesterday's refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY).
* If yesterday returns no data, filter on 2 days ago's refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 2 DAY).
* Default to country-level results (one row per term).
* "Top" queries must deduplicate snapshot rows.
* Only include week or score when the user explicitly asks for trends over time.
* This is an international dataset and does not include any data for the United States.
### Additional Descriptions
#### 1. Core model:
* refresh_date selects the daily Top-25 term set.
* week + score are historical weekly values attached to those terms.
* Filtering week does not change which terms appear.
#### 2. Deduplication rule (critical):
* Snapshot rows repeat across weeks and regions.
* For "top" queries, always GROUP BY term (country-level) and compute rank as MIN(rank).
#### 3. Defaults:
* Country-level results only.
* Use region_code only if the user explicitly asks for regions.
* Limit results unless the user asks otherwise.
#### 4. Time series usage:
* Only include week or score when the user asks for trends over time, historical context, or week-over-week score changes.
#### 5. Field guidance:
* Prefer country_code or region_code for filters.
* country_name / region_name are for display only.
* score is normalized; compare trends within a term, not across terms.
확인된 쿼리
이전에는 골든 질문이라고 했던 확인된 질문은 에이전트가 대답 정확성을 개선하기 위한 참조로 사용됩니다. 이러한 프롬프트는 에이전트의 응답 구조를 형성하고 조직에서 사용하는 비즈니스 로직을 에이전트에게 학습시키는 데 도움이 됩니다.
에이전트에 두 가지 예시를 추가해 보겠습니다. 쿼리 추가를 클릭하고 다음 질문과 쿼리를 복사하여 붙여넣습니다.
질문 1:
What are the top search terms in the UK right now?
쿼리 1:
SELECT term, MIN(rank) AS rank
FROM `bigquery-public-data.google_trends.international_top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
AND country_code = 'GB'
GROUP BY term
ORDER BY rank
LIMIT 25;
이 쿼리를 저장하기 전에 실행하여 유효한지 확인해 보겠습니다.

좋아 보이네요. 추가를 클릭하여 확인된 쿼리를 저장합니다.
더 복잡한 사용 사례의 예를 하나 더 추가해 보겠습니다. 쿼리 관리를 클릭하고 다음을 추가합니다.
질문 2:
Show the last 12 weeks of interest for the current top 5 terms in Auckland.
답변 2:
WITH top5 AS (
SELECT term, MIN(rank) AS rank
FROM `bigquery-public-data.google_trends.international_top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
AND country_code = 'NZ'
AND region_code = 'NZ-AUK'
GROUP BY 1
ORDER BY 2
LIMIT 5
),
series AS (
SELECT term, week, score,
ROW_NUMBER() OVER (PARTITION BY term ORDER BY week DESC) AS rn
FROM `bigquery-public-data.google_trends.international_top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
AND country_code = 'NZ'
AND region_code = 'NZ-AUK'
AND term IN (SELECT term FROM top5)
)
SELECT week, term, score
FROM series
WHERE rn <= 12
ORDER BY 1 DESC, 3
다음 섹션으로 넘어가기 전에 Gemini가 생성한 추천을 살펴보겠습니다.

여기에서 확인된 추천 쿼리를 확인할 수 있습니다. 향후 새 에이전트를 만들 때 유용한 시작점이 될 수 있습니다. 추가하는 쿼리를 검증하기만 하면 됩니다.
용어 설명
용어집에 용어를 추가해 보겠습니다. 비즈니스에서 Dataplex를 사용하는 경우 이러한 용어는 Dataplex 범용 카탈로그의 비즈니스 용어집에서 직접 가져옵니다.
용어 추가를 클릭하고 다음 예시를 복사하여 붙여넣습니다.
기간:
refresh_date
정의:
Snapshot date that selects the daily Top 25 term set. All rows for that date belong to the same "what's trending now" snapshot. Attach Historical week and score values after this selection.
동의어:
today, latest, current, now, recent
그런 다음 추가를 클릭하고 저장을 클릭합니다.

에이전트 설정
설정 섹션에서 라벨과 청구 가능한 최대 바이트를 구성할 수 있습니다.
라벨
라벨은 Google Cloud 리소스를 논리적 그룹으로 구성하는 데 사용되는 키-값 쌍입니다. 이 실습에 집중하기 위해 라벨을 비워 둡니다.
청구 가능한 최대 바이트
실수로 비용이 많이 드는 쿼리를 생성하지 않도록 쿼리당 청구 가능한 최대 바이트 수를 제한해 보겠습니다. 에이전트의 쿼리가 이 한도를 초과하는 바이트를 처리하면 쿼리가 실패하고 요금은 청구되지 않습니다. 다음 값을 입력합니다.
10000000000
10,000,000,000바이트는 약 9.3GB입니다. 값을 지정하지 않으면 청구되는 최대 바이트가 프로젝트의 일일 쿼리 사용량 할당량으로 기본 설정됩니다.
5. 에이전트 저장 및 공유
미리보기
준비가 완료되었습니다. 계속하기 전에 에이전트를 테스트해 보겠습니다. 화면 오른쪽에서 구성을 수정하는 동안 에이전트를 동적으로 테스트할 수 있습니다. 미리보기에서는 변경사항을 저장하거나 게시하지 않고도 제공한 새 메타데이터를 자동으로 사용합니다.
상담사가 액세스할 수 있는 데이터를 물어보겠습니다. 다음과 같은 질문을 직접 해 보세요.

저장
프롬프트를 몇 개 테스트한 후 저장하고 에이전트를 게시합니다.

에이전트를 게시하면 BigQuery Studio, Conversational Analytics API, Looker Studio Pro에서 사용할 수 있습니다 (라이선스 적용).

향후 출시에서는 추가 표시 경로 및 통합이 지원될 예정입니다.
공유
에이전트가 게시되었다는 확인 메시지가 표시됩니다. 이제 이 에이전트를 다른 사용자와 공유할 수 있습니다.

다른 사용자와 에이전트를 공유할 때 특정 역할을 할당하여 액세스 수준을 제어할 수 있습니다. 이러한 역할은 공동작업자가 에이전트를 보기만 할 수 있는지 아니면 구성을 수정하고 관리할 수 있는 권한이 있는지 결정합니다.
이러한 역할은 두 가지 수준에서 적용할 수 있습니다.
- 프로젝트 수준: 프로젝트 수준에서 역할을 부여하면 해당 Google Cloud 프로젝트 내의 모든 에이전트에 대한 권한이 사용자에게 제공됩니다.
- 에이전트 수준: 보다 세부적인 제어를 위해 특정 에이전트에 역할을 부여할 수 있습니다. 사용자가 프로젝트의 다른 데이터 에이전트는 보지 않고 특정 데이터 에이전트에만 액세스하도록 하려는 경우에 유용합니다.
대화형 분석의 사전 정의된 역할은 다음과 같습니다.
- Gemini 데이터 분석 데이터 에이전트 소유자 (roles/geminidataanalytics.dataAgentOwner)- 모든 데이터 에이전트 생성, 수정, 공유, 삭제
- Gemini 데이터 분석 데이터 에이전트 생성자 (roles/geminidataanalytics.dataAgentCreator) - 자체 데이터 에이전트 생성, 수정, 공유, 삭제
- Gemini 데이터 분석 데이터 에이전트 편집자 (roles/geminidataanalytics.dataAgentEditor) - 데이터 에이전트에 대한 채팅 및 수정 액세스 권한
- 데이터 분석 데이터 에이전트 사용자 (roles/geminidataanalytics.dataAgentUser) - 데이터 에이전트에 대한 채팅 및 보기 액세스 권한
- Gemini 데이터 분석 데이터 에이전트 뷰어 (roles/geminidataanalytics.dataAgentViewer) - 데이터 에이전트에 대한 보기 (읽기 전용) 액세스 권한
6. 에이전트와의 대화 만들기
공유 탭을 종료하고 새 대화를 만들어 보겠습니다.

대화 만들기를 클릭하면 제목이 없는 새 대화가 생성됩니다.
영국에서 인기 급상승 중인 검색어를 물어보겠습니다 (원하는 위치로 바꿔도 됩니다).
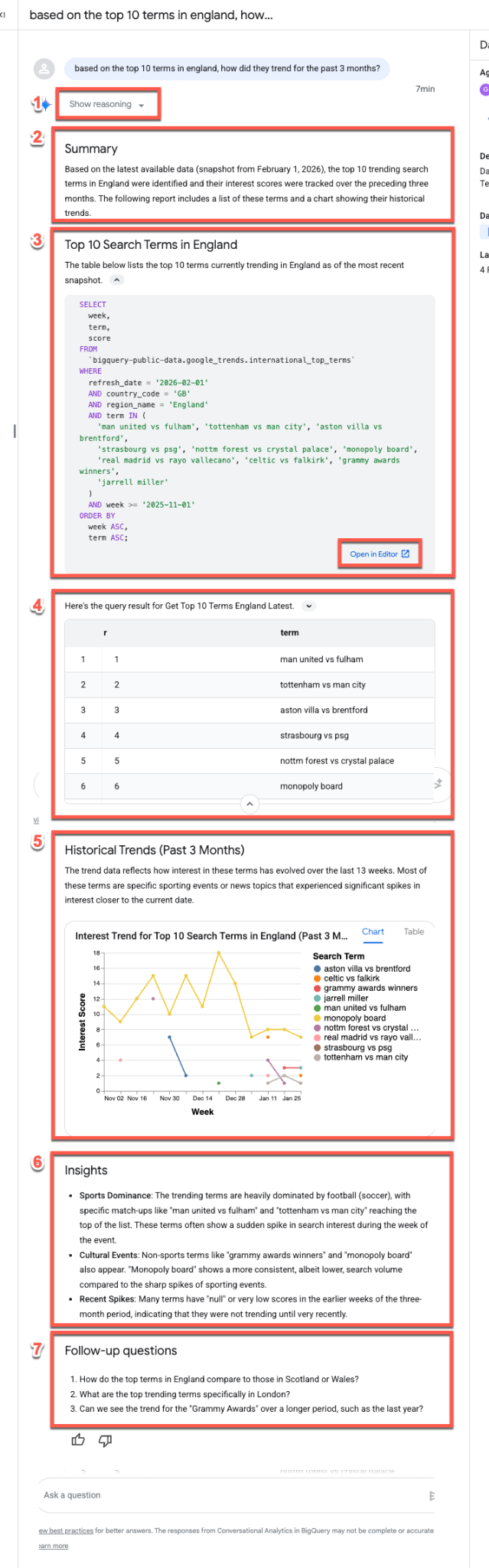
Based on the top 10 terms in England, how did they trend for the past 3 months?
응답 스트림 압축 해제
데이터 에이전트는 일반적으로 질문에 답변할 때 동일한 응답 스트림을 따릅니다.
- 추론: 에이전트가 먼저 프롬프트를 통해 '생각'합니다. 추론 표시 버튼을 펼쳐 에이전트의 의사 결정 프로세스에 대한 단계별 통계를 확인합니다.
- 요약: 에이전트가 질문, 결과 보고서, 시각화에 대한 개략적인 요약을 생성합니다.
- 생성된 SQL: 다음은 쿼리입니다... 섹션을 펼쳐 SQL을 검사합니다. 편집기에서 열기를 클릭하여 BigQuery Studio에서 쿼리를 수동으로 미세 조정합니다.
- 데이터 결과: 에이전트가 쿼리 결과를 명확한 표 형식으로 표시합니다.
- 시각화: 간단한 설명과 함께 차트가 표시됩니다. 에이전트가 데이터에 가장 적합한 시각화 유형 (예: 다중 계열 선 그래프)을 자동으로 추론합니다.
- 데이터 통계: 에이전트가 결과에서 발견된 주요 추세와 핵심 내용을 요약합니다.
- 후속 질문: 마지막으로 에이전트는 분석을 계속하는 데 도움이 되는 관련 후속 질문을 제안합니다.
BigQuery ML 지원
후속 조치로 데이터 에이전트가 이 결과를 기반으로 예측을 실행할 수 있는지 물어보겠습니다. BigQuery ML 함수를 활용하여 미래 포인트를 예측합니다.
다음 프롬프트를 입력합니다('monopoly board'를 질문과 관련된 용어로 바꿔야 합니다).
Can you predict and visualize how monopoly board will trend in the next 4 weeks?
AI_FORECAST를 사용하여 시계열을 예측한 것을 확인할 수 있습니다. 2021년 8월에 급격한 증가가 나타나는 것은 흥미롭습니다. 이는 런던에 Monopoly Lifesized 어트랙션이 개장한 시기와 일치합니다.

7. 에이전트 카탈로그 살펴보기
마무리하기 전에 에이전트 카탈로그를 살펴보겠습니다. 창 상단에서 에이전트 카탈로그를 클릭합니다.

이 페이지는 데이터 에이전트 관리를 위한 중앙 허브 역할을 하며 다음 섹션으로 구성되어 있습니다.
- 내 에이전트: 현재 게시된 에이전트입니다.
- 내 초안 에이전트: 저장했지만 아직 게시하지 않은 구성입니다.
- 조직의 다른 사용자가 공유: 액세스 권한이 있는 동료가 만든 에이전트입니다.
- Google의 샘플 에이전트: 시작하는 데 도움이 되는 사전 구성된 예입니다.
관리하는 에이전트의 경우 구성을 수정하고, 에이전트를 복제하고, 공유 권한을 관리할 수 있습니다.
8. 결론
수고하셨습니다. 대화형 분석 데이터 에이전트를 빌드했습니다. 참고 자료를 확인하여 자세히 알아보세요.