
۱. مقدمه
دریافت بینش از دادهها اغلب به زمان، تلاش و تخصص عمیق SQL نیاز دارد. در این آزمایشگاه کد، شما کاتالوگ عاملهای BigQuery را بررسی خواهید کرد، پلتفرمی جدید که بینشهای فوری و مبتنی بر هوش مصنوعی را از طریق عاملهای داده محاورهای ارائه میدهد.
شما با ایجاد یک عامل دادهی گزینششده، فراتر از تبدیل سادهی متن به SQL خواهید رفت. یاد خواهید گرفت که چگونه عامل را با زمینهی کسبوکار، دستورالعملهای سیستم و پرسوجوهای تأییدشده غنیسازی کنید تا نتایج بسیار دقیقی را تضمین کنید. در نهایت، این عامل را برای استفادهی دیگران در سازمان خود منتشر خواهید کرد.
پیشنیازها
- درک اولیه از فضای ابری گوگل
آنچه یاد خواهید گرفت
- نحوه پیمایش در کاتالوگ عاملهای BigQuery
- نحوه ایجاد یک عامل سفارشی و تعریف منابع دانش
- نحوه استفاده از Gemini برای تولید فراداده معنایی
- نحوه اضافه کردن دستورالعملهای سیستم و پرسوجوهای تأیید شده برای راهنمایی اپراتور
- نحوه انتشار و اشتراکگذاری عوامل
آنچه نیاز دارید
- یک حساب کاربری گوگل کلود و پروژه گوگل کلود
- آشنایی اولیه با BigQuery و SQL
- یک مرورگر وب مانند کروم
۲. تنظیمات و الزامات
یک پروژه انتخاب کنید
- وارد کنسول گوگل کلود شوید و یک پروژه جدید ایجاد کنید یا از یک پروژه موجود دوباره استفاده کنید. اگر از قبل حساب جیمیل یا گوگل ورک اسپیس ندارید، باید یکی ایجاد کنید .



- نام پروژه، نام نمایشی برای شرکتکنندگان این پروژه است. این یک رشته کاراکتری است که توسط APIهای گوگل استفاده نمیشود. شما همیشه میتوانید آن را بهروزرسانی کنید.
- شناسه پروژه در تمام پروژههای گوگل کلود منحصر به فرد است و تغییرناپذیر است (پس از تنظیم، قابل تغییر نیست). کنسول کلود به طور خودکار یک رشته منحصر به فرد تولید میکند؛ معمولاً برای شما مهم نیست که چیست. در اکثر آزمایشگاههای کد، باید شناسه پروژه خود را (که معمولاً با عنوان
PROJECT_IDشناخته میشود) ارجاع دهید. اگر شناسه تولید شده را دوست ندارید، میتوانید یک شناسه تصادفی دیگر ایجاد کنید. به عنوان یک جایگزین، میتوانید شناسه خودتان را امتحان کنید و ببینید که آیا در دسترس است یا خیر. پس از این مرحله قابل تغییر نیست و در طول پروژه باقی میماند. - برای اطلاع شما، یک مقدار سوم، شماره پروژه ، وجود دارد که برخی از APIها از آن استفاده میکنند. برای کسب اطلاعات بیشتر در مورد هر سه این مقادیر، به مستندات مراجعه کنید.
- در مرحله بعد، برای استفاده از منابع/API های ابری، باید پرداخت صورتحساب را در کنسول ابری فعال کنید . اجرای این آزمایشگاه کد هزینه زیادی نخواهد داشت، اگر اصلاً هزینهای داشته باشد. برای خاموش کردن منابع به منظور جلوگیری از پرداخت صورتحساب پس از این آموزش، میتوانید منابعی را که ایجاد کردهاید یا پروژه را حذف کنید. کاربران جدید Google Cloud واجد شرایط برنامه آزمایشی رایگان ۳۰۰ دلاری هستند.
۳. قبل از شروع
به خودتان نقشهای مورد نیاز را اعطا کنید
به صفحه IAM پروژه بروید و نقش مالک عامل داده Gemini Data Analytics را به خود اختصاص دهید:

این نقش به شما اجازه ایجاد، ویرایش، اشتراکگذاری و حذف همه عوامل داده در پروژه را میدهد.
فعال کردن API های مورد نیاز
از منوی ناوبری نوار کناری یا منوی جستجو در بالای صفحه برای رفتن به BigQuery > Agents استفاده کنید.
روی فعال کردن API تجزیه و تحلیل دادهها با Gemini کلیک کنید:

فعال کردن Gemini در BigQuery API و Gemini برای Google Cloud API :

اکنون باید صفحه نماینده جدید را مشاهده کنید:

۴. یک نماینده ایجاد کنید
بیایید اولین عامل داده خود را با استفاده از مجموعه دادههای Google Trends International Public ایجاد کنیم. این مجموعه داده برای پرسیدن سوالاتی در مورد اینکه چه عبارات جستجویی در سطح بینالمللی پرطرفدار هستند و چگونه این علایق از نظر تاریخی مقایسه میشوند، مفید است.
بیایید با دادن نام و توضیح مختصری به نماینده خود شروع کنیم. این توضیح صرفاً برای این است که سایر کاربران هدف نماینده را درک کنند.
نام نماینده
Google Trends Agent
توضیحات عامل
Data agent for the Google Trends International Top Terms public dataset
منابع دانش
حالا منابع دانش را اضافه کنید. یک منبع دانش، یک جدول، نمای یا UDF در BigQuery است که عامل میتواند برای پاسخ به سوالات از آن استفاده کند.
برای این نسخه آزمایشی، فقط یک جدول اضافه کنید تا همه چیز ساده بماند. با این حال، به خاطر داشته باشید که میتوانید تا ۵۰ منبع دانش برای هر عامل اضافه کنید تا سناریوهای داده پیچیدهتر را مدیریت کنید.
جدول زیر را در کادر جستجو وارد کنید، کادر را علامت بزنید و روی افزودن کلیک کنید:
bigquery-public-data.google_trends.international_top_terms

زمینه ساختاریافته
برای بهبود دقت عامل داده، زمینه ساختاریافته را به جدول و ستونها اضافه کنید. روی سفارشیسازی کلیک کنید:

Gemini به طور خودکار پیشنهادهایی برای توضیحات ارائه میدهد. روی «پذیرش» در کنار توضیحات جدول کلیک کنید:
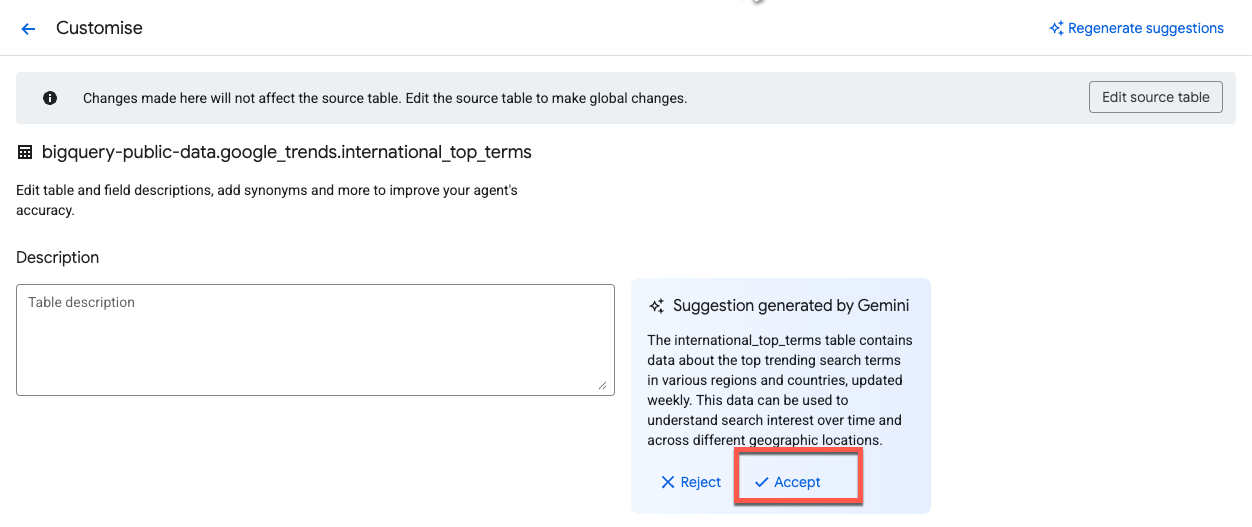
برای اعمال توضیحات به همه ستونها، گزینه Select all rows را تیک بزنید و سپس روی Accept suggestions کلیک کنید:

برای ذخیره تغییرات و بازگشت به ویرایشگر عامل، روی بهروزرسانی در پایین صفحه کلیک کنید.
دستورالعملها
کادر محاورهای دستورالعملهای عامل، جایی است که میتوانید به عامل راهنماییهای بیشتری برای تفسیر و پرسوجو از منابع داده بدهید. این شامل موارد زیر است:
- مترادفها : اصطلاحات جایگزین برای فیلدهای کلیدی.
- زمینههای کلیدی : مهمترین زمینهها برای تحلیل.
- فیلدهای مستثنی : فیلدهایی که عامل داده باید از آنها اجتناب کند.
- فیلتر کردن و گروهبندی : فیلدهایی که عامل باید برای فیلتر کردن و گروهبندی دادهها استفاده کند.
- پیوند روابط : نحوه ترکیب دو یا چند جدول بر اساس فیلدهای مشترک.
دستورالعملهای زیر را کپی و پیست کنید:
### System Instruction
* You are an expert data analyst for the Google Trends International public dataset.
* Always filter on yesterday's refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY).
* If yesterday returns no data, filter on 2 days ago's refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 2 DAY).
* Default to country-level results (one row per term).
* "Top" queries must deduplicate snapshot rows.
* Only include week or score when the user explicitly asks for trends over time.
* This is an international dataset and does not include any data for the United States.
### Additional Descriptions
#### 1. Core model:
* refresh_date selects the daily Top-25 term set.
* week + score are historical weekly values attached to those terms.
* Filtering week does not change which terms appear.
#### 2. Deduplication rule (critical):
* Snapshot rows repeat across weeks and regions.
* For "top" queries, always GROUP BY term (country-level) and compute rank as MIN(rank).
#### 3. Defaults:
* Country-level results only.
* Use region_code only if the user explicitly asks for regions.
* Limit results unless the user asks otherwise.
#### 4. Time series usage:
* Only include week or score when the user asks for trends over time, historical context, or week-over-week score changes.
#### 5. Field guidance:
* Prefer country_code or region_code for filters.
* country_name / region_name are for display only.
* score is normalized; compare trends within a term, not across terms.
پرسوجوهای تأیید شده
پرسوجوهای تأیید شده، که قبلاً با نام پرسوجوهای طلایی شناخته میشدند، به عنوان مرجعی برای عامل جهت بهبود دقت پاسخ استفاده میشوند. آنها ساختار پاسخ یک عامل را شکل میدهند و به عامل در آموزش منطق تجاری مورد استفاده سازمان شما کمک میکنند.
بیایید دو مثال برای نماینده شما اضافه کنیم. روی افزودن پرسوجو کلیک کنید و سوال و پرسوجوی زیر را کپی/پیست کنید:
سوال ۱:
What are the top search terms in the UK right now?
پرس و جو ۱:
SELECT term, MIN(rank) AS rank
FROM `bigquery-public-data.google_trends.international_top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
AND country_code = 'GB'
GROUP BY term
ORDER BY rank
LIMIT 25;
قبل از ذخیره این کوئری، بیایید آن را اجرا کنیم تا از معتبر بودن آن مطمئن شویم.

به نظر من خوب است! برای ذخیره پرس و جوی تأیید شده، روی افزودن کلیک کنید.
بیایید یک مثال دیگر برای یک مورد استفاده پیچیدهتر اضافه کنیم. روی مدیریت پرسوجوها کلیک کنید و موارد زیر را اضافه کنید:
سوال ۲:
Show the last 12 weeks of interest for the current top 5 terms in Auckland.
پاسخ ۲:
WITH top5 AS (
SELECT term, MIN(rank) AS rank
FROM `bigquery-public-data.google_trends.international_top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
AND country_code = 'NZ'
AND region_code = 'NZ-AUK'
GROUP BY 1
ORDER BY 2
LIMIT 5
),
series AS (
SELECT term, week, score,
ROW_NUMBER() OVER (PARTITION BY term ORDER BY week DESC) AS rn
FROM `bigquery-public-data.google_trends.international_top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)
AND country_code = 'NZ'
AND region_code = 'NZ-AUK'
AND term IN (SELECT term FROM top5)
)
SELECT week, term, score
FROM series
WHERE rn <= 12
ORDER BY 1 DESC, 3
قبل از رفتن به بخش بعدی، بیایید به پیشنهادهای تولید شده توسط Gemini نگاهی بیندازیم:

در اینجا میتوانید برخی از پرسوجوهای تأیید شده پیشنهادی را مشاهده کنید. هنگام ایجاد یک عامل جدید در آینده، این یک نقطه شروع عالی است. فقط مطمئن شوید که هر پرسوجویی را که اضافه میکنید، اعتبارسنجی میکنید!
واژهنامه
بیایید یک اصطلاح به واژهنامه اضافه کنیم. اگر کسب و کار شما از Dataplex استفاده میکند، این اصطلاحات مستقیماً از واژهنامه کسب و کار در کاتالوگ جهانی Dataplex وارد میشوند.
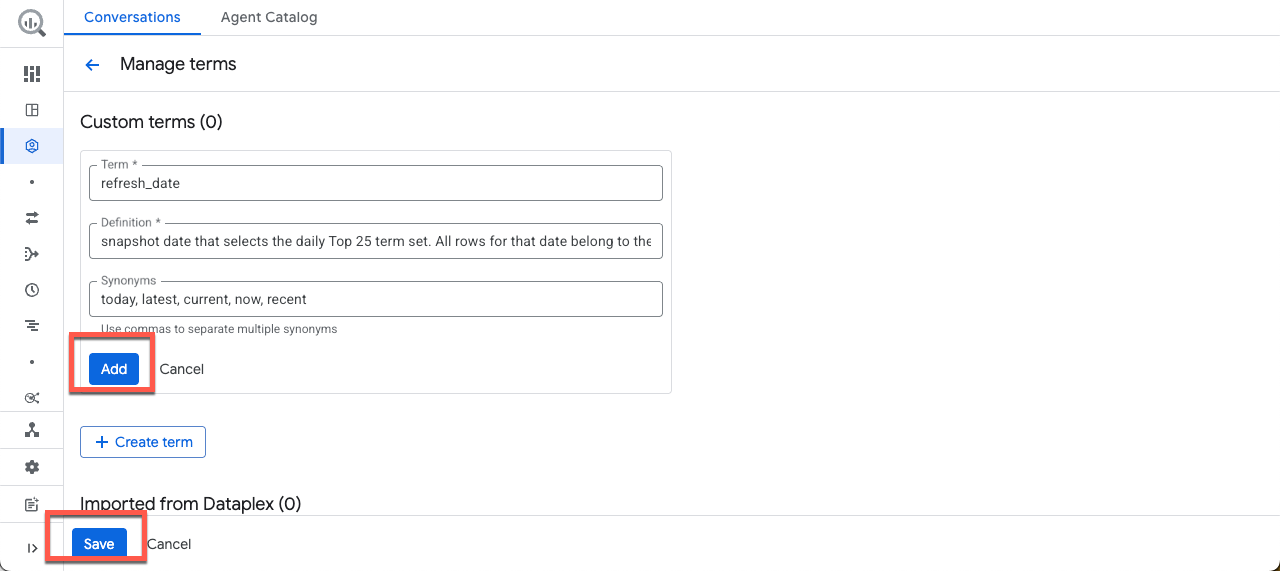
روی افزودن اصطلاح کلیک کنید و مثال زیر را کپی/پیست کنید:
اصطلاح:
refresh_date
تعریف:
Snapshot date that selects the daily Top 25 term set. All rows for that date belong to the same "what's trending now" snapshot. Attach Historical week and score values after this selection.
مترادفها:
today, latest, current, now, recent
سپس روی افزودن و سپس ذخیره کلیک کنید.
تنظیمات عامل
در بخش تنظیمات ، میتوانید برچسبها و حداکثر بایتهای پرداختی را پیکربندی کنید.
برچسبها
برچسبها جفتهای کلید-مقدار هستند که برای سازماندهی منابع Google Cloud در گروههای منطقی استفاده میشوند. برای متمرکز نگه داشتن این تمرین، برچسبها را خالی بگذارید.
حداکثر بایتهای محاسبهشده
برای اطمینان از اینکه به طور تصادفی هیچ پرس و جوی پرهزینهای ایجاد نمیکنید، بیایید محدودیتی برای حداکثر بایتهای محاسبه شده برای هر پرس و جو تعیین کنیم. اگر پرس و جوی نماینده بایتهایی بالاتر از این حد را پردازش کند، پرس و جو بدون متحمل شدن هزینه، با شکست مواجه میشود. مقدار زیر را وارد کنید:
10000000000
۱۰,۰۰۰,۰۰۰,۰۰۰ بایت تقریباً معادل ۹.۳ گیگابایت است. اگر مقداری مشخص نکنید، حداکثر بایتهای محاسبهشده بهطور پیشفرض برابر با سهمیهی روزانهی استفاده از کوئری پروژه خواهد بود.
۵. ذخیره و اشتراکگذاری عامل شما
پیشنمایش
همه چیز آماده است! بیایید قبل از ادامه، عامل شما را آزمایش کنیم. در سمت راست صفحه میتوانید عامل را به صورت پویا در حین انجام ویرایش در پیکربندی آزمایش کنید. پیشنمایش به طور خودکار از فرادادههای جدیدی که ارائه میدهید بدون ذخیره یا انتشار تغییرات استفاده میکند.
بیایید بپرسیم که نماینده به چه دادههایی دسترسی دارد. میتوانید چند سوال را با کلمات خودتان بپرسید:

ذخیره
پس از آزمایش چند دستور، ذخیره کنید و سپس عامل را منتشر کنید :

انتشار عامل، آن را در BigQuery Studio، API Conversational Analytics و Looker Studio Pro (منوط به مجوز) در دسترس قرار میدهد:

پشتیبانی از سطوح و یکپارچهسازیهای اضافی برای نسخههای آینده برنامهریزی شده است.
اشتراک گذاری
شما باید یک پیام تأیید مبنی بر انتشار عامل مشاهده کنید. اکنون میتوانید این عامل را با سایر کاربران به اشتراک بگذارید.

وقتی یک عامل را با سایر کاربران به اشتراک میگذارید، با اختصاص دادن یک نقش خاص به آنها، سطح دسترسی آنها را کنترل میکنید. این نقشها تعیین میکنند که آیا یک همکار میتواند به سادگی عامل شما را مشاهده کند یا اینکه قدرت ویرایش و مدیریت پیکربندی آن را دارد.
لازم به ذکر است که این نقشها را میتوان در دو سطح مختلف اعمال کرد:
- سطح پروژه : اعطای یک نقش در سطح پروژه، به کاربر این مجوزها را برای همه نمایندگان درون آن پروژه Google Cloud میدهد.
- سطح عامل : برای کنترل دقیقتر، میتوانید برای یک عامل خاص نقشهایی را تعیین کنید. این زمانی مفید است که میخواهید یک کاربر به یک عامل داده خاص دسترسی داشته باشد، بدون اینکه عاملهای داده دیگر را در پروژه ببیند.
نقشهای از پیش تعریفشده برای تحلیل مکالمهای به شرح زیر است:
- مالک عامل داده Gemini Data Analytics (roles/geminidataanalytics.dataAgentOwner) - ایجاد، ویرایش، اشتراکگذاری و حذف همه عاملهای داده
- سازنده عامل داده Gemini Data Analytics (roles/geminidataanalytics.dataAgentCreator) - عاملهای داده خودتان را ایجاد، ویرایش، اشتراکگذاری و حذف کنید
- ویرایشگر عامل داده Gemini Data Analytics (roles/geminidataanalytics.dataAgentEditor) - دسترسی چت و ویرایش به عاملهای داده
- کاربر عامل داده در تجزیه و تحلیل دادهها (roles/geminidataanalytics.dataAgentUser) - دسترسی چت و مشاهده به عاملهای داده
- نمایشگر عامل دادهی تحلیل دادهی جمینی (roles/geminidataanalytics.dataAgentViewer) - مشاهده (فقط خواندنی) دسترسی به عاملهای داده
۶. با یک نماینده گفتگو کنید
بیایید از تب اشتراکگذاری خارج شویم و یک مکالمه جدید ایجاد کنیم:

وقتی روی ایجاد مکالمه کلیک میکنید، یک مکالمه جدید بدون عنوان ایجاد میشود.
بیایید در مورد اصطلاحات رایج در انگلستان بپرسیم (میتوانید آنها را با مکان مورد نظر خود جایگزین کنید!):
Based on the top 10 terms in England, how did they trend for the past 3 months?
باز کردن جریان پاسخ
عامل داده معمولاً هنگام پاسخ دادن به سؤالات، جریان پاسخ یکسانی را دنبال میکند:
- استدلال : عامل ابتدا در مورد درخواست "فکر" میکند. دکمه نمایش استدلال را باز کنید تا بینشهای گام به گام در مورد فرآیند تصمیمگیری عامل را مشاهده کنید.
- خلاصه : عامل، خلاصهای سطح بالا از پرسوجو، گزارش حاصل و تصویرسازی تولید میکند.
- SQL تولید شده : برای بررسی SQL، بخش « اینجا پرسوجو است...» را باز کنید. برای تنظیم دقیق پرسوجو به صورت دستی در BigQuery Studio، روی «باز کردن در ویرایشگر» کلیک کنید.
- نتایج دادهها : عامل، نتایج پرسوجو را در قالبی واضح و جدولی ارائه میدهد.
- مصورسازی : یک نمودار در کنار توضیحی مختصر ظاهر میشود. عامل بهطور خودکار بهترین نوع مصورسازی (مثلاً یک نمودار خطی چند سری) را برای دادههای شما استنباط میکند.
- بینشهای دادهای : عامل، روندهای کلیدی و نکات کلیدی یافتشده در نتایج را خلاصه میکند.
- سوالات تکمیلی : در نهایت، کارشناس سوالات تکمیلی مرتبطی را پیشنهاد میدهد تا به شما در ادامه تحلیلتان کمک کند.

پشتیبانی از BigQuery ML
بیایید پیگیری کنیم و بپرسیم که آیا عامل داده میتواند بر اساس این نتایج پیشبینیهایی انجام دهد یا خیر. این کار از توابع BigQuery ML برای پیشبینی نقاط آینده استفاده میکند.
عبارت زیر را وارد کنید (مطمئن شوید که عبارت "monopoly board" را با عبارتی مرتبط با عبارت جستجوی خود جایگزین میکنید!):
Can you predict and visualize how monopoly board will trend in the next 4 weeks?
میتوانید ببینید که AI_FORECAST برای پیشبینی یک سری زمانی استفاده شده است. جای تعجب نیست، هرچند جالب است که میتوانید یک جهش بزرگ را در آگوست 2021 مشاهده کنید، که همزمان با افتتاح بزرگ جاذبه تفریحی مونوپولی لایفسایز در لندن است!

۷. کاتالوگ نمایندگان را بررسی کنید
بیایید قبل از جمعبندی، کاتالوگ عامل را بررسی کنیم. در بالای پنجره روی کاتالوگ عامل کلیک کنید:
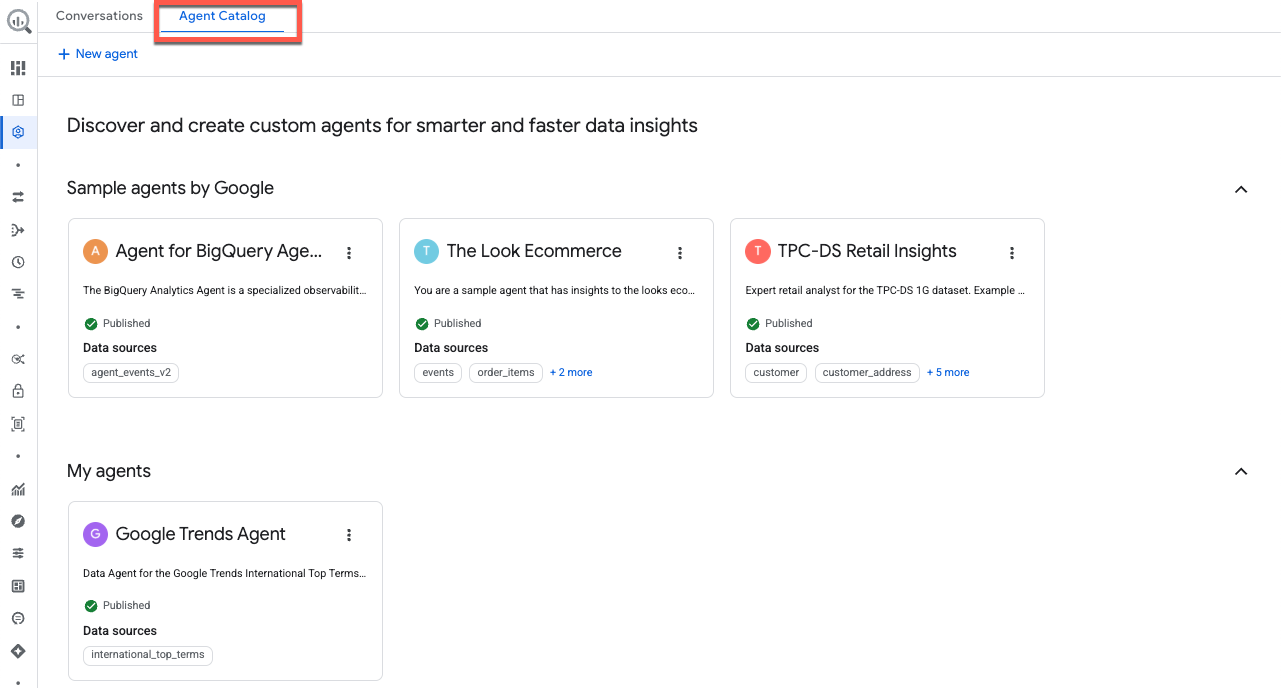
این صفحه به عنوان مرکز اصلی مدیریت عامل داده شما عمل میکند و به بخشهای زیر تقسیم شده است:
- نمایندگان من : نمایندگانی که در حال حاضر منتشر شدهاند.
- نمایندگان پیشنویس من : پیکربندیهایی که ذخیره کردهاید اما هنوز منتشر نکردهاید.
- اشتراکگذاریشده توسط دیگران در سازمان شما : عاملهایی که توسط همکارانی ایجاد شدهاند که شما اجازه دسترسی به آنها را دارید.
- نمونههایی از عاملهای گوگل : نمونههای از پیش پیکربندیشده برای کمک به شما در شروع کار.
برای هر عاملی که مدیریت میکنید، میتوانید پیکربندیها را ویرایش کنید، عاملها را کپی کنید و مجوزهای اشتراکگذاری را مدیریت کنید.
۸. نتیجهگیری
تبریک میگویم، شما با موفقیت یک عامل داده تحلیل مکالمهای ساختید. برای کسب اطلاعات بیشتر، به منابع مراجعه کنید!