
1. บทนำ
นักวิเคราะห์ข้อมูลมักต้องเผชิญกับข้อมูลที่มีคุณค่าซึ่งล็อกอยู่ในรูปแบบกึ่งโครงสร้าง เช่น เพย์โหลด JSON การดึงและจัดเตรียมข้อมูลนี้เพื่อการวิเคราะห์และแมชชีนเลิร์นนิงมักเป็นอุปสรรคทางเทคนิคที่สำคัญ ซึ่งต้องใช้สคริปต์ ETL ที่ซับซ้อนและการแทรกแซงของทีมวิศวกรข้อมูล
Codelab นี้มีพิมพ์เขียวทางเทคนิคสำหรับนักวิเคราะห์ข้อมูลเพื่อเอาชนะความท้าทายนี้ได้ด้วยตนเอง ซึ่งแสดงให้เห็นถึงแนวทาง "แบบใช้โค้ดน้อย" ในการสร้างไปป์ไลน์ AI แบบต้นทางถึงปลายทาง คุณจะได้เรียนรู้วิธีเปลี่ยนจากไฟล์ CSV ดิบใน Google Cloud Storage ไปเป็นการขับเคลื่อนฟีเจอร์คำแนะนำที่ทำงานด้วยระบบ AI โดยใช้เฉพาะเครื่องมือที่มีอยู่ใน BigQuery Studio
เป้าหมายหลักคือการแสดงให้เห็นเวิร์กโฟลว์ที่แข็งแกร่ง รวดเร็ว และเป็นมิตรกับนักวิเคราะห์ ซึ่งก้าวข้ามกระบวนการที่ซับซ้อนและต้องใช้โค้ดจำนวนมากเพื่อสร้างมูลค่าทางธุรกิจที่แท้จริงจากข้อมูล
ข้อกำหนดเบื้องต้น
- ความเข้าใจพื้นฐานเกี่ยวกับ Google Cloud Console
- ทักษะพื้นฐานในอินเทอร์เฟซบรรทัดคำสั่งและ Google Cloud Shell
สิ่งที่คุณจะได้เรียนรู้
- วิธีนำเข้าและเปลี่ยนรูปแบบไฟล์ CSV จาก Google Cloud Storage โดยตรงโดยใช้การเตรียมข้อมูล BigQuery
- วิธีใช้การเปลี่ยนรูปแบบแบบไม่ต้องเขียนโค้ดเพื่อแยกวิเคราะห์และทำให้สตริง JSON ที่ซ้อนกันภายในข้อมูลแบนราบ
- วิธีสร้างโมเดลระยะไกลของ BigQuery ML ที่เชื่อมต่อกับโมเดลพื้นฐานของ Vertex AI สำหรับการฝังข้อความ
- วิธีใช้ฟังก์ชัน
ML.GENERATE_TEXT_EMBEDDINGเพื่อแปลงข้อมูลข้อความเป็นเวกเตอร์ตัวเลข - วิธีใช้ฟังก์ชัน
ML.DISTANCEเพื่อคำนวณความคล้ายคลึงกันของโคไซน์และค้นหารายการที่คล้ายกันมากที่สุดในชุดข้อมูล
สิ่งที่คุณต้องมี
- บัญชี Google Cloud และโปรเจ็กต์ Google Cloud
- เว็บเบราว์เซอร์ เช่น Chrome
แนวคิดหลัก
- การเตรียมข้อมูล BigQuery: เครื่องมือภายใน BigQuery Studio ที่มีอินเทอร์เฟซแบบอินเทอร์แอกทีฟและภาพสำหรับการล้างและการเตรียมข้อมูล โดยจะแนะนำการเปลี่ยนรูปแบบและอนุญาตให้ผู้ใช้สร้างไปป์ไลน์ข้อมูลด้วยโค้ดน้อยที่สุด
- โมเดลระยะไกล BQML: ออบเจ็กต์ BigQuery ML ที่ทําหน้าที่เป็นพร็อกซีไปยังโมเดลที่โฮสต์ใน Vertex AI (เช่น Gemini) ซึ่งช่วยให้คุณเรียกใช้โมเดล AI ที่มีประสิทธิภาพและได้รับการฝึกไว้ล่วงหน้าได้โดยใช้ไวยากรณ์ SQL ที่คุ้นเคย
- การฝังเวกเตอร์: การแสดงข้อมูลเป็นตัวเลข เช่น ข้อความหรือรูปภาพ ในโค้ดแล็บนี้ เราจะแปลงคำอธิบายที่เป็นข้อความของอาร์ตเวิร์กเป็นเวกเตอร์ โดยคำอธิบายที่คล้ายกันจะส่งผลให้เวกเตอร์ "อยู่ใกล้กัน" มากขึ้นในพื้นที่แบบหลายมิติ
- ความคล้ายคลึงกันของโคไซน์: การวัดทางคณิตศาสตร์ที่ใช้เพื่อพิจารณาว่าเวกเตอร์ 2 ตัวมีความคล้ายคลึงกันมากน้อยเพียงใด ซึ่งเป็นหัวใจสำคัญของตรรกะของเครื่องมือแนะนำที่ฟังก์ชัน
ML.DISTANCEใช้เพื่อค้นหาอาร์ตเวิร์กที่ "ใกล้เคียง" (คล้ายกันมากที่สุด)
2. การตั้งค่าและข้อกำหนด
เริ่มต้น Cloud Shell
แม้ว่าคุณจะใช้งาน Google Cloud จากระยะไกลจากแล็ปท็อปได้ แต่ใน Codelab นี้คุณจะใช้ Google Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานในระบบคลาวด์
จาก Google Cloud Console ให้คลิกไอคอน Cloud Shell ในแถบเครื่องมือด้านขวาบน

การจัดสรรและเชื่อมต่อกับสภาพแวดล้อมจะใช้เวลาเพียงไม่กี่นาที เมื่อเสร็จแล้ว คุณควรเห็นข้อความคล้ายกับตัวอย่างต่อไปนี้

เครื่องเสมือนนี้มาพร้อมเครื่องมือพัฒนาซอฟต์แวร์ทั้งหมดที่คุณต้องการ โดยมีไดเรกทอรีหลักแบบถาวรขนาด 5 GB และทำงานบน Google Cloud ซึ่งช่วยเพิ่มประสิทธิภาพเครือข่ายและการตรวจสอบสิทธิ์ได้อย่างมาก คุณสามารถทำงานทั้งหมดใน Codelab นี้ได้ภายในเบราว์เซอร์ คุณไม่จำเป็นต้องติดตั้งอะไร
เปิดใช้ API ที่จำเป็นและกำหนดค่าสภาพแวดล้อม
ใน Cloud Shell ให้เรียกใช้คำสั่งต่อไปนี้เพื่อตั้งค่ารหัสโปรเจ็กต์ กำหนดตัวแปรสภาพแวดล้อม และเปิดใช้ API ที่จำเป็นทั้งหมดสำหรับโค้ดแล็บนี้
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}" # Must be a globally unique name
gcloud services enable bigquery.googleapis.com \
storage.googleapis.com \
aiplatform.googleapis.com \
bigqueryconnection.googleapis.com
สร้างชุดข้อมูล BigQuery และที่เก็บข้อมูล GCS
สร้างชุดข้อมูล BigQuery ใหม่เพื่อเก็บตารางและ Bucket ของ Google Cloud Storage เพื่อจัดเก็บไฟล์ CSV ต้นทาง
# Create the BigQuery Dataset in the US multi-region
bq --location=$LOCATION mk --dataset $PROJECT_ID:met_art_dataset
# Create the GCS Bucket
gcloud storage buckets create gs://$GCS_BUCKET_NAME --project=$PROJECT_ID --location=$LOCATION
เตรียมและอัปโหลดข้อมูลตัวอย่าง
โคลนที่เก็บ GitHub ที่มีไฟล์ CSV ตัวอย่าง แล้วอัปโหลดไปยังที่เก็บข้อมูล GCS ที่เพิ่งสร้าง
# Clone the repository
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git
# Navigate to the correct directory
cd devrel-demos/data-analytics/dataprep
# Upload the CSV file to your GCS bucket
gsutil cp dataprep-met-bqml.csv gs://$GCS_BUCKET_NAME/
3. จาก GCS ไปยัง BigQuery ด้วยการเตรียมข้อมูล
ในส่วนนี้ เราจะใช้อินเทอร์เฟซแบบภาพที่ไม่มีโค้ดเพื่อส่งผ่านข้อมูลไฟล์ CSV จาก GCS ทำความสะอาด และโหลดลงในตาราง BigQuery ใหม่
เปิดใช้การเตรียมข้อมูลและเชื่อมต่อกับแหล่งข้อมูล
- ไปที่ BigQuery Studio ใน Google Cloud Console

- ในหน้าต้อนรับ ให้คลิกการ์ดการเตรียมข้อมูลเพื่อเริ่มต้น
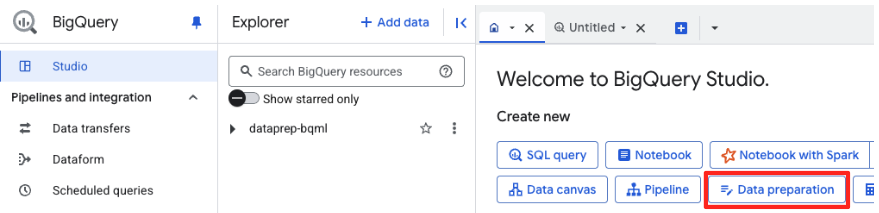
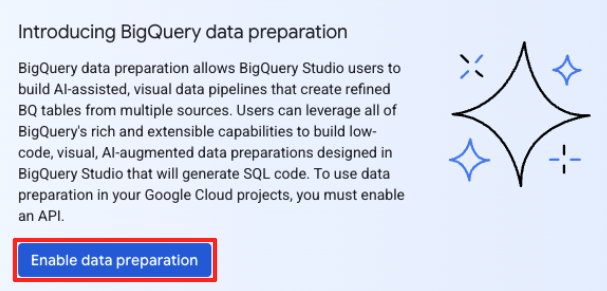
- หากนี่เป็นการใช้งานครั้งแรก คุณอาจต้องเปิดใช้ API ที่จำเป็น คลิกเปิดใช้สำหรับทั้ง "Gemini สำหรับ Google Cloud API" และ "BigQuery Unified API" เมื่อเปิดใช้แล้ว คุณจะปิดแผงนี้ได้

- ในหน้าต่างการเตรียมข้อมูลหลัก ให้คลิก Google Cloud Storage ในส่วน "เลือกแหล่งข้อมูลอื่นๆ" ซึ่งจะเป็นการเปิดแผง "เตรียมข้อมูล" ทางด้านขวา

- คลิกปุ่มเรียกดูเพื่อเลือกไฟล์ต้นฉบับ

- ไปที่ Bucket ของ GCS ที่คุณสร้างไว้ก่อนหน้านี้ (
met-artworks-source-...) แล้วเลือกdataprep-met-bqml.csvไฟล์ คลิกเลือก


- จากนั้นคุณต้องกำหนดค่าตารางการจัดเตรียม
- สําหรับชุดข้อมูล ให้เลือก
met_art_datasetที่คุณสร้าง - สำหรับชื่อตาราง ให้ป้อนชื่อ เช่น
temp - คลิกสร้าง

เปลี่ยนรูปแบบและล้างข้อมูล
- การเตรียมข้อมูลของ BigQuery จะโหลดตัวอย่างของ CSV ในตอนนี้ ค้นหาคอลัมน์
label_details_jsonซึ่งมีสตริง JSON แบบยาว คลิกส่วนหัวของคอลัมน์เพื่อเลือก

- ในแผงคำแนะนำทางด้านขวา Gemini ใน BigQuery จะแนะนำการเปลี่ยนรูปแบบที่เกี่ยวข้องโดยอัตโนมัติ คลิกปุ่ม "ใช้" ในการ์ด "คอลัมน์การแบน
label_details_json" ซึ่งจะแยกฟิลด์ที่ซ้อนกัน (description,scoreฯลฯ) ออกเป็นคอลัมน์ระดับบนสุดของตัวเอง

- คลิกคอลัมน์ object_id แล้วคลิกปุ่มใช้ใน "แปลงคอลัมน์
object_idจากประเภทstringเป็นint64


กำหนดปลายทางและเรียกใช้งาน
- ในแผงด้านขวา ให้คลิกปุ่มปลายทางเพื่อกำหนดค่าเอาต์พุตของการเปลี่ยนรูปแบบ

- ตั้งค่ารายละเอียดปลายทาง
- ควรกรอกข้อมูลชุดข้อมูลล่วงหน้าด้วย
met_art_dataset - ป้อนชื่อตารางใหม่สำหรับเอาต์พุต:
met_art_flatten_table - คลิกบันทึก

- คลิกปุ่มเรียกใช้ แล้วรอจนกว่างานการเตรียมข้อมูลจะเสร็จสมบูรณ์

- คุณสามารถตรวจสอบความคืบหน้าของงานได้ในแท็บการดำเนินการที่ด้านล่างของหน้า หลังจากนั้นไม่นาน งานจะเสร็จสมบูรณ์
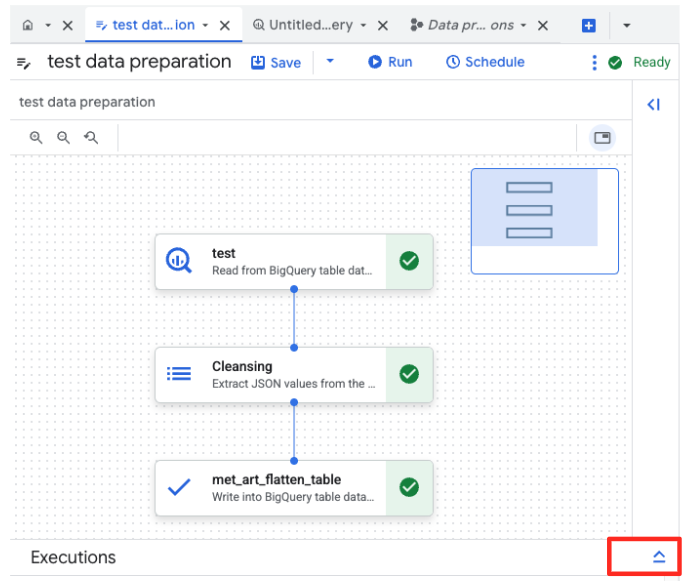

4. การสร้างการฝังเวกเตอร์ด้วย BQML
ตอนนี้ข้อมูลของเราสะอาดและมีโครงสร้างแล้ว เราจะใช้ BigQuery ML สำหรับงาน AI หลัก นั่นคือการแปลงคำอธิบายที่เป็นข้อความของอาร์ตเวิร์กให้เป็นเวกเตอร์ฝังตัวที่เป็นตัวเลข
สร้างการเชื่อมต่อ BigQuery
หากต้องการอนุญาตให้ BigQuery สื่อสารกับบริการ Vertex AI คุณต้องสร้างการเชื่อมต่อ BigQuery ก่อน
- ในแผง Explorer ของ BigQuery Studio ให้คลิกปุ่ม "+ เพิ่มข้อมูล"
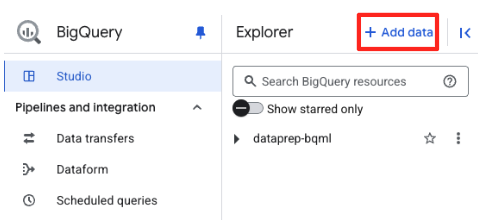
- ใช้แถบค้นหาในแผงด้านขวาเพื่อพิมพ์
Vertex AIเลือกแล้วเลือกการรวม BigQuery จากรายการที่กรอง

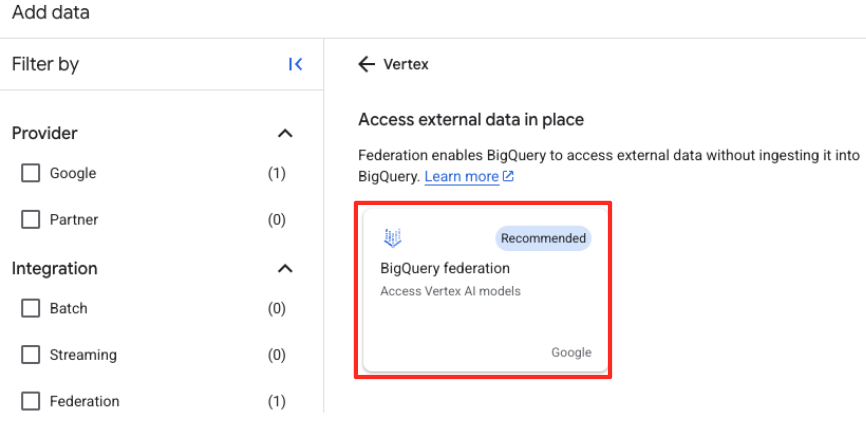
- ซึ่งจะเปิดแบบฟอร์มแหล่งข้อมูลภายนอก กรอกรายละเอียดต่อไปนี้
- รหัสการเชื่อมต่อ: ป้อนรหัสการเชื่อมต่อ (เช่น
bqml-vertex-connection) - ประเภทตำแหน่ง: ตรวจสอบว่าได้เลือกหลายภูมิภาคแล้ว
- สถานที่: เลือกสถานที่ (เช่น
US)

- เมื่อสร้างการเชื่อมต่อแล้ว กล่องโต้ตอบยืนยันจะปรากฏขึ้น คลิกไปที่การเชื่อมต่อหรือการเชื่อมต่อภายนอกในแท็บ Explorer ในหน้ารายละเอียดการเชื่อมต่อ ให้คัดลอกรหัสแบบเต็มไปยังคลิปบอร์ด นี่คือข้อมูลประจำตัวของบัญชีบริการที่ BigQuery จะใช้เพื่อเรียก Vertex AI

- ในเมนูการนำทางของ Google Cloud Console ให้ไปที่ IAM และผู้ดูแลระบบ > IAM
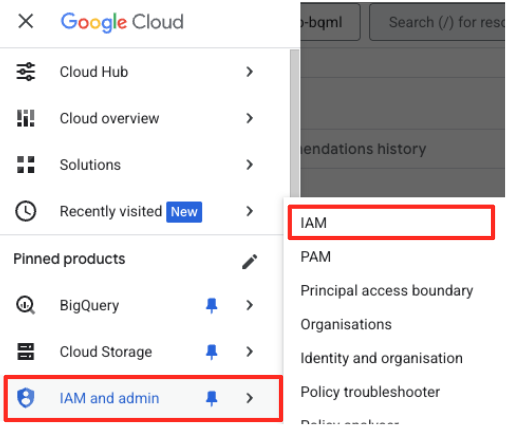
- คลิกปุ่ม "ให้สิทธิ์เข้าถึง"
- วางบัญชีบริการที่คุณคัดลอกไว้ในขั้นตอนก่อนหน้าในช่องผู้ใช้หลักรายใหม่
- กำหนดบทบาท "ผู้ใช้ Vertex AI" ในเมนูแบบเลื่อนลงของบทบาท แล้วคลิก "บันทึก"

ขั้นตอนนี้มีความสำคัญอย่างยิ่งเพื่อให้มั่นใจว่า BigQuery มีสิทธิ์ที่เหมาะสมในการใช้โมเดล Vertex AI ในนามของคุณ
สร้างโมเดลระยะไกล
ใน BigQuery Studio ให้เปิดแท็บ SQL Editor ใหม่ ส่วนนี้เป็นที่ที่คุณจะกำหนดโมเดล BQML ที่เชื่อมต่อกับ Gemini
คำสั่งนี้จะไม่ฝึกโมเดลใหม่ โดยจะสร้างการอ้างอิงใน BigQuery ที่ชี้ไปยังโมเดล gemini-embedding-001 ที่มีประสิทธิภาพและผ่านการฝึกมาแล้วโดยใช้การเชื่อมต่อที่คุณเพิ่งให้สิทธิ์
คัดลอกสคริปต์ SQL ทั้งหมดด้านล่างแล้ววางลงในตัวแก้ไข BigQuery
CREATE OR REPLACE MODEL `met_art_dataset.embedding_model`
REMOTE WITH CONNECTION `US.bqml-vertex-connection`
OPTIONS (endpoint = 'gemini-embedding-001');
สร้างการฝัง
ตอนนี้เราจะใช้โมเดล BQML เพื่อสร้างการฝังเวกเตอร์ แทนที่จะแปลงป้ายกำกับข้อความเดียวสำหรับแต่ละแถว เราจะใช้วิธีที่ซับซ้อนกว่าเพื่อสร้าง "ข้อมูลสรุปเชิงความหมาย" ที่สมบูรณ์และมีความหมายมากขึ้นสำหรับผลงานแต่ละชิ้น ซึ่งจะส่งผลให้ได้การฝังที่มีคุณภาพสูงขึ้นและคำแนะนำที่แม่นยำมากขึ้น
การค้นหานี้จะดำเนินการขั้นตอนการประมวลผลล่วงหน้าที่สำคัญ ดังนี้
- โดยใช้คําสั่ง
WITHเพื่อสร้างตารางชั่วคราวก่อน - ภายในนั้น เราจะ
GROUP BYobject_idแต่ละรายการเพื่อรวมข้อมูลทั้งหมดเกี่ยวกับอาร์ตเวิร์กเดียวไว้ในแถวเดียว - เราใช้ฟังก์ชัน
STRING_AGGเพื่อผสานคำอธิบายข้อความที่แยกกันทั้งหมด (เช่น "ภาพบุคคล" "ผู้หญิง" "ภาพวาดสีน้ำมันบนผืนผ้าใบ") เป็นสตริงข้อความเดียวที่ครอบคลุม โดยจัดเรียงตามคะแนนความเกี่ยวข้อง
ข้อความที่รวมกันนี้จะช่วยให้ AI มีบริบทเกี่ยวกับอาร์ตเวิร์กที่สมบูรณ์ยิ่งขึ้น ซึ่งจะนำไปสู่การฝังเวกเตอร์ที่ละเอียดและมีประสิทธิภาพมากขึ้น
ในแท็บตัวแก้ไข SQL ใหม่ ให้วางและเรียกใช้คำค้นหาต่อไปนี้
CREATE OR REPLACE TABLE `met_art_dataset.artwork_embeddings` AS
WITH artwork_semantic_text AS (
-- First, we group all text labels for each artwork into a single row.
SELECT
object_id,
ANY_VALUE(title) AS title,
ANY_VALUE(artist_display_name) AS artist_display_name,
-- STRING_AGG combines all descriptions into one comma-separated string,
-- ordering them by score to put the most relevant labels first.
STRING_AGG(description, ', ' ORDER BY score DESC) AS aggregated_labels
FROM
`met_art_dataset.met_art_flatten_table`
GROUP BY
object_id
)
SELECT
*
FROM ML.GENERATE_TEXT_EMBEDDING(
MODEL `met_art_dataset.embedding_model`,
(
-- We pass the new, combined string as the content to be embedded.
SELECT
object_id,
title,
artist_display_name,
aggregated_labels AS content
FROM
artwork_semantic_text
)
);
คำค้นหานี้จะใช้เวลาประมาณ 10 นาที เมื่อคําค้นหาเสร็จสมบูรณ์แล้ว ให้ยืนยันผลลัพธ์ ในแผง Explorer ให้ค้นหาartwork_embeddingsตารางใหม่ แล้วคลิก ในโปรแกรมดูสคีมาตาราง คุณจะเห็น object_id คอลัมน์ ml_generate_text_embedding_result ใหม่ที่มีเวกเตอร์ และคอลัมน์ aggregated_labels ที่ใช้เป็นข้อความต้นฉบับ

5. การค้นหางานศิลปะที่คล้ายกันด้วย SQL
เมื่อสร้างการฝังเวกเตอร์ที่มีคุณภาพสูงและมีบริบทที่สมบูรณ์แล้ว การค้นหาอาร์ตเวิร์กที่คล้ายกันตามธีมก็ง่ายเหมือนการเรียกใช้คำสั่งค้นหา SQL เราใช้ฟังก์ชัน ML.DISTANCE เพื่อคำนวณความคล้ายกันของโคไซน์ระหว่างเวกเตอร์ เนื่องจากเราสร้างการฝังจากข้อความที่รวบรวมไว้ ผลลัพธ์ความคล้ายคลึงจึงแม่นยำและเกี่ยวข้องมากขึ้น
- ในแท็บตัวแก้ไข SQL ใหม่ ให้วางคำค้นหาต่อไปนี้ คําค้นหานี้จําลองตรรกะหลักของแอปพลิเคชันคําแนะนํา
- โดยจะเลือกเวกเตอร์สำหรับอาร์ตเวิร์กเดียวที่เฉพาะเจาะจงก่อน (ในกรณีนี้คือ "ต้นไซปรัส" ของแวนโกะห์ ซึ่งมี
object_idเป็น 436535) - จากนั้นจะคำนวณระยะห่างระหว่างเวกเตอร์เดียวกับเวกเตอร์อื่นๆ ทั้งหมดในตาราง
- สุดท้ายนี้ ระบบจะจัดเรียงผลลัพธ์ตามระยะทาง (ระยะทางที่สั้นกว่าหมายถึงความคล้ายคลึงกันมากขึ้น) เพื่อค้นหา 10 รายการที่ตรงกันมากที่สุด
WITH selected_artwork AS (
SELECT text_embedding
FROM `met_art_dataset.artwork_embeddings`
WHERE object_id = 436535
)
SELECT
base.object_id,
base.title,
base.artist_display_name,
-- ML.DISTANCE calculates the cosine distance between the two vectors.
-- A smaller distance means the items are more similar.
ML.DISTANCE(base.text_embedding, (SELECT text_embedding FROM selected_artwork), 'COSINE') AS similarity_distance
FROM
`met_art_dataset.artwork_embeddings` AS base, selected_artwork
ORDER BY
similarity_distance
LIMIT 10;
- เรียกใช้การค้นหา ผลการค้นหาจะแสดง
object_idโดยมีรายการที่ตรงกันมากที่สุดอยู่ด้านบน อาร์ตเวิร์กต้นฉบับจะปรากฏก่อนโดยมีระยะห่างเป็น 0 นี่คือตรรกะหลักที่ขับเคลื่อนเครื่องมือแนะนำโดย AI และคุณได้สร้างตรรกะนี้ทั้งหมดภายใน BigQuery โดยใช้เพียง SQL
6. (ไม่บังคับ) การเรียกใช้การสาธิตใน Cloud Shell
ที่เก็บที่คุณโคลนมาจะมีเว็บแอปพลิเคชันอย่างง่ายเพื่อนำแนวคิดจาก Codelab นี้มาใช้ เดโมที่ไม่บังคับนี้ใช้ตาราง artwork_embeddings ที่คุณสร้างขึ้นเพื่อขับเคลื่อนเครื่องมือค้นหาภาพ ซึ่งช่วยให้คุณเห็นคำแนะนำที่ขับเคลื่อนด้วย AI ในการทำงาน
หากต้องการเรียกใช้การสาธิตใน Cloud Shell ให้ทำตามขั้นตอนต่อไปนี้
- ตั้งค่าตัวแปรสภาพแวดล้อม: ก่อนเรียกใช้แอปพลิเคชัน คุณต้องตั้งค่าตัวแปรสภาพแวดล้อม PROJECT_ID และ BIGQUERY_DATASET
export PROJECT_ID=$(gcloud config get-value project)
export BIGQUERY_DATASET=met_art_dataset
export REGION='us-central1'
bq cp bigquery-public-data:the_met.images $PROJECT_ID:met_art_dataset.images
- ติดตั้งการอ้างอิงและเริ่มเซิร์ฟเวอร์แบ็กเอนด์
cd ~/devrel-demos/data-analytics/dataprep/backend/ && npm install
node server.js
- คุณจะต้องมีแท็บเทอร์มินัลที่ 2 เพื่อเรียกใช้แอปพลิเคชันส่วนหน้า คลิกไอคอน "+" เพื่อเปิดแท็บ Cloud Shell ใหม่

- ตอนนี้ในแท็บใหม่ ให้เรียกใช้คำสั่งต่อไปนี้เพื่อติดตั้งทรัพยากร Dependency และเรียกใช้เซิร์ฟเวอร์ส่วนหน้า
cd ~/devrel-demos/data-analytics/dataprep/frontend/ && npm install
npm run dev
- ดูตัวอย่างแอปพลิเคชัน: ในแถบเครื่องมือ Cloud Shell ให้คลิกไอคอนแสดงตัวอย่างเว็บ แล้วเลือกแสดงตัวอย่างบนพอร์ต 5173 ซึ่งจะเป็นการเปิดแท็บเบราว์เซอร์ใหม่พร้อมแอปพลิเคชันที่ทำงานอยู่ ตอนนี้คุณสามารถใช้แอปพลิเคชันเพื่อค้นหางานศิลปะและดูการค้นหาที่คล้ายกันได้แล้ว


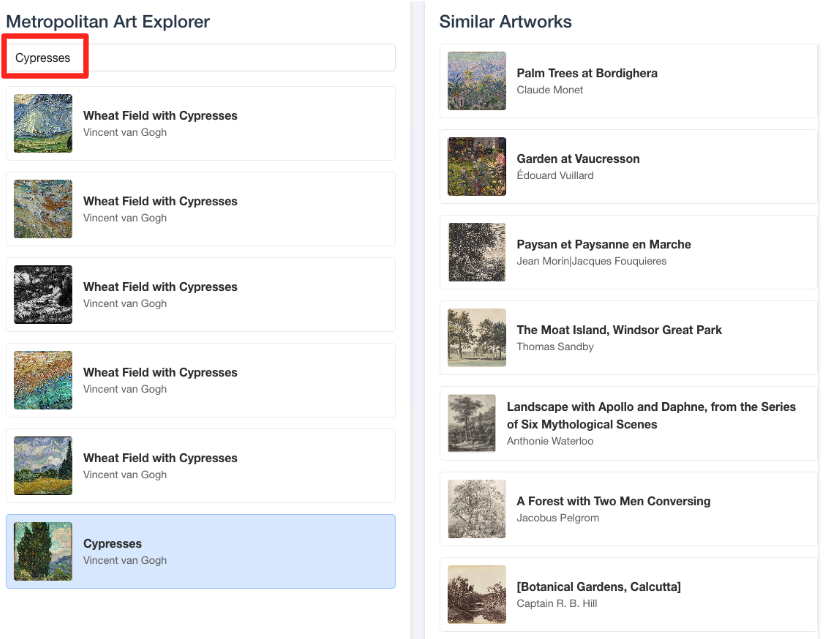
- หากต้องการเชื่อมต่อการสาธิตภาพนี้กลับไปที่งานที่คุณทำในเครื่องมือแก้ไข SQL ของ BigQuery ให้ลองพิมพ์ "Cypresses" ในแถบค้นหา นี่คืองานศิลปะเดียวกัน(
object_id=436535) กับที่คุณใช้ในคำค้นหาML.DISTANCEจากนั้นคลิกรูปภาพต้นไซปรัสเมื่อปรากฏในแผงด้านซ้าย คุณจะเห็นผลลัพธ์ทางด้านขวา แอปพลิเคชันจะแสดงอาร์ตเวิร์กที่คล้ายกันมากที่สุด ซึ่งแสดงให้เห็นถึงประสิทธิภาพของการค้นหาความคล้ายคลึงของเวกเตอร์ที่คุณสร้างขึ้น
7. การทำความสะอาดสภาพแวดล้อม
คุณควรลบทรัพยากรที่สร้างขึ้นเพื่อหลีกเลี่ยงการเรียกเก็บเงินในอนาคตกับบัญชี Google Cloud สำหรับทรัพยากรที่ใช้ใน Codelab นี้
เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล Cloud Shell เพื่อนำบัญชีบริการ การเชื่อมต่อ BigQuery, ถัง GCS และชุดข้อมูล BigQuery ออก
# Re-run these exports if your Cloud Shell session timed out
export PROJECT_ID=$(gcloud config get-value project)
export LOCATION="US"
export GCS_BUCKET_NAME="met-artworks-source-${PROJECT_ID}"
export BQ_CONNECTION_ID="bqml-vertex-connection"
นำการเชื่อมต่อ BigQuery และที่เก็บข้อมูล GCS ออก
# Delete the BigQuery connection
bq rm --connection $LOCATION.$BQ_CONNECTION_ID
# Delete the GCS bucket and its contents
gcloud storage rm --recursive gs://$GCS_BUCKET_NAME
ลบชุดข้อมูล BigQuery
สุดท้าย ให้ลบชุดข้อมูล BigQuery คำสั่งนี้จะย้อนกลับไม่ได้ แฟล็ก -f (บังคับ) จะนำชุดข้อมูลและตารางทั้งหมดออกโดยไม่ต้องแจ้งให้ยืนยัน
# Manually type this command to confirm you are deleting the correct dataset
bq rm -r -f --dataset $PROJECT_ID:met_art_dataset
8. ยินดีด้วย
คุณสร้างไปป์ไลน์ข้อมูลที่ทำงานด้วยระบบ AI แบบครบวงจรเรียบร้อยแล้ว
คุณเริ่มต้นด้วยไฟล์ CSV ดิบในที่เก็บข้อมูล GCS ใช้ไปป์ไลน์การประมวลผลข้อมูล BigQuery เพื่อนำเข้าและแปลงข้อมูล JSON ที่ซับซ้อนให้เป็นรูปแบบแบน สร้างโมเดลระยะไกล BQML ที่มีประสิทธิภาพเพื่อสร้างการฝังเวกเตอร์คุณภาพสูงด้วยโมเดล Gemini และเรียกใช้การค้นหาความคล้ายกันเพื่อค้นหารายการที่เกี่ยวข้อง
ตอนนี้คุณก็พร้อมที่จะใช้รูปแบบพื้นฐานในการสร้างเวิร์กโฟลว์ที่ AI ช่วยใน Google Cloud แล้ว ซึ่งจะเปลี่ยนข้อมูลดิบให้เป็นแอปพลิเคชันอัจฉริยะได้อย่างรวดเร็วและง่ายดาย
ขั้นตอนถัดไป
- แสดงผลลัพธ์เป็นภาพใน Looker Studio: เชื่อมต่อ
artwork_embeddingsตาราง BigQuery กับ Looker Studio โดยตรง (ไม่มีค่าใช้จ่าย) คุณสามารถสร้างแดชบอร์ดแบบอินเทอร์แอกทีฟที่ผู้ใช้เลือกอาร์ตเวิร์กและดูแกลเลอรีภาพของผลงานที่คล้ายกันมากที่สุดได้โดยไม่ต้องเขียนโค้ดส่วนหน้า - ทำงานอัตโนมัติด้วยการค้นหาที่ตั้งเวลาไว้: คุณไม่จำเป็นต้องใช้เครื่องมือจัดระเบียบที่ซับซ้อนเพื่ออัปเดตการฝังให้เป็นข้อมูลล่าสุด ใช้ฟีเจอร์การค้นหาตามกำหนดการในตัวของ BigQuery เพื่อเรียกใช้การค้นหา
ML.GENERATE_TEXT_EMBEDDINGอีกครั้งโดยอัตโนมัติทุกวันหรือทุกสัปดาห์ - สร้างแอปด้วย Gemini CLI: ใช้ Gemini CLI เพื่อสร้างแอปพลิเคชันที่สมบูรณ์ได้ง่ายๆ เพียงอธิบายข้อกำหนดของคุณในข้อความธรรมดา ซึ่งจะช่วยให้คุณสร้างต้นแบบที่ใช้งานได้จริงสำหรับการค้นหาความคล้ายกันได้อย่างรวดเร็วโดยไม่ต้องเขียนโค้ด Python ด้วยตนเอง
- อ่านเอกสารประกอบ