
1. 簡介
在本實驗室中,您將瞭解如何使用 BigQuery 機器學習,透過遠端模型 ( Gemini 模型) 進行推論,分析電影海報圖片並根據海報直接在 BigQuery 資料倉儲中生成電影摘要。

上圖:您要分析的電影海報圖片範例。
BigQuery 是內建 AI 的全代管資料分析平台,專為多引擎、跨格式和多雲端環境而設計,可充分發揮資料價值。「BigQuery 機器學習推論」是 BigQuery 的一項重要功能,讓您能使用 GoogleSQL 查詢建立及執行機器學習模型。
Gemini 是 Google 開發的一系列生成式 AI 模型,專為多模態用途而設計。
使用 GoogleSQL 查詢執行機器學習模型
一般來說,要對大型資料集執行機器學習或人工智慧 (AI) 技術,需要進行大量程式設計,並具備機器學習框架的知識。因此每間公司只有少數專家能開發解決方案。有了「BigQuery 機器學習推論」功能,SQL 使用者就能運用現有的 SQL 工具和技能來建構模型,並以 LLM 和 Cloud AI API 生成結果。
必要條件
- 對 Google Cloud 控制台有基本瞭解
- 有 BigQuery 使用經驗者尤佳
課程內容
- 如何設定環境和帳戶以使用 API
- 如何在 BigQuery 中建立雲端資源連線
- 如何在 BigQuery 為電影海報圖片建立資料集和物件資料表
- 如何在 BigQuery 建立 Gemini 遠端模型
- 如何提示 Gemini 模型為每張海報提供電影摘要
- 如何根據每張海報代表的電影生成文字嵌入
- 如何使用 BigQuery
VECTOR_SEARCH,找出資料集中與電影海報圖片高度相關的電影
軟硬體需求
- Google Cloud 帳戶和 Google Cloud 專案,並啟用計費功能
- 網路瀏覽器,例如 Chrome
2. 設定和需求
自修實驗室環境設定
- 登入 Google Cloud 控制台,然後建立新專案或重複使用現有專案。如果沒有 Gmail 或 Google Workspace 帳戶,請先建立帳戶。


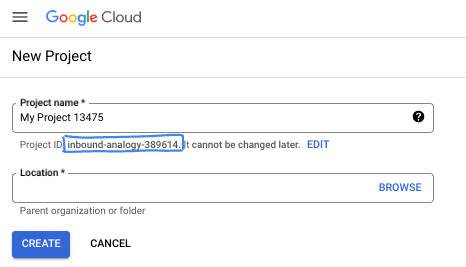
- 專案名稱是這個專案參與者的顯示名稱。這是 Google API 未使用的字元字串。你隨時可以更新。
- 專案 ID 在所有 Google Cloud 專案中都是不重複的,而且設定後即無法變更。Cloud 控制台會自動產生專屬字串,通常您不需要在意該字串為何。在大多數程式碼研究室中,您需要參照專案 ID (通常標示為
PROJECT_ID)。如果您不喜歡產生的 ID,可以產生另一個隨機 ID。你也可以嘗試使用自己的名稱,看看是否可用。完成這個步驟後就無法變更,且專案期間會維持不變。 - 請注意,有些 API 會使用第三個值,也就是「專案編號」。如要進一步瞭解這三種值,請參閱說明文件。
- 接著,您需要在 Cloud 控制台中啟用帳單,才能使用 Cloud 資源/API。完成這個程式碼研究室的費用不高,甚至可能完全免費。如要關閉資源,避免在本教學課程結束後繼續產生費用,請刪除您建立的資源或專案。Google Cloud 新使用者可參加價值$300 美元的免費試用計畫。
啟動 Cloud Shell
雖然可以透過筆電遠端操作 Google Cloud,但在本程式碼研究室中,您將使用 Google Cloud Shell,這是可在雲端執行的指令列環境。
在 Google Cloud 控制台中,點選右上工具列的 Cloud Shell 圖示:

佈建並連線至環境的作業需要一些時間才能完成。完成後,您應該會看到如下的內容:

這部虛擬機器搭載各種您需要的開發工具,並提供永久的 5GB 主目錄,而且可在 Google Cloud 運作,大幅提升網路效能並強化驗證功能。您可以在瀏覽器中完成本程式碼研究室的所有作業。您不需要安裝任何軟體。
3. 事前準備
如要在 BigQuery 中使用 Gemini 模型,需要完成幾個設定步驟,包括啟用 API、建立 Cloud 資源連線,以及授予 Cloud 資源連線的服務帳戶特定權限。這些步驟各專案只需執行一次,我們會在接下來的幾個章節中說明。
啟用 API
在 Cloud Shell 中,確認專案 ID 已設定完畢:
gcloud config set project [YOUR-PROJECT-ID]
設定環境變數 PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
設定要用於 Vertex AI 模型的預設區域。進一步瞭解 Vertex AI 服務地區。在本範例中,我們使用 us-central1 區域。
gcloud config set compute/region us-central1
設定環境變數 REGION:
REGION=$(gcloud config get-value compute/region)
啟用所有必要服務:
gcloud services enable bigqueryconnection.googleapis.com \
aiplatform.googleapis.com
執行上述所有指令後的預期輸出內容:
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable bigqueryconnection.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. 建立 Cloud 資源連線
在這項工作中,您將建立 Cloud 資源連線,讓 BigQuery 存取 Cloud Storage 中的圖片檔案,並呼叫 Vertex AI。
- 前往 Google Cloud 控制台,依序點選「導覽選單」圖示
 和「BigQuery」。
和「BigQuery」。

- 依序點選「+ 新增」和「連線至外部資料來源」來建立連線。
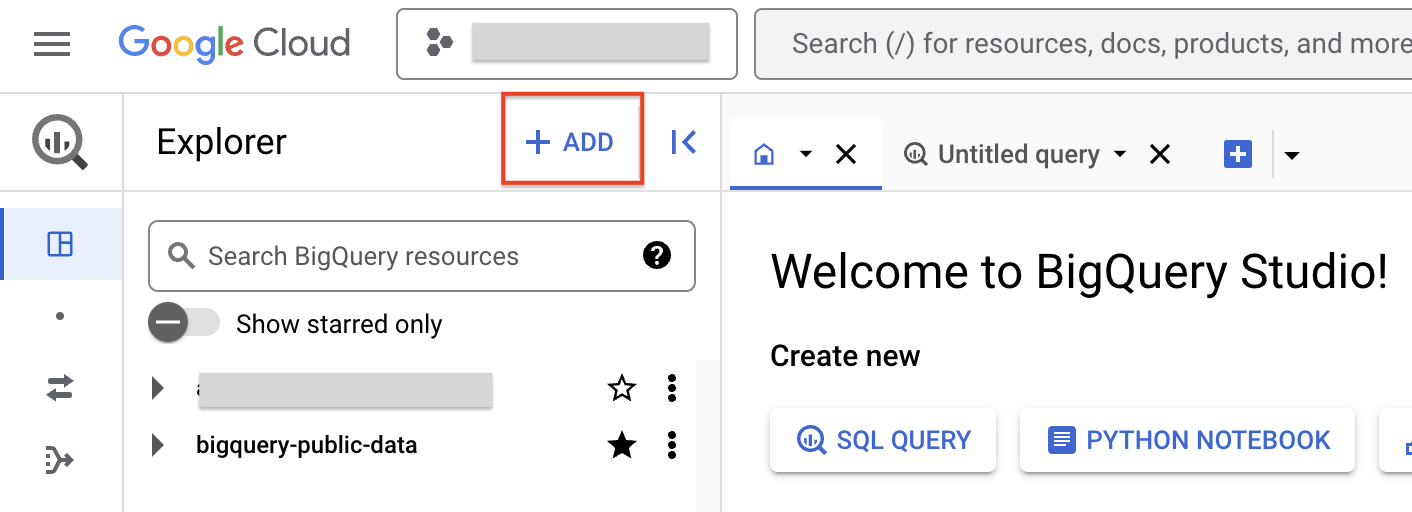
- 在「連線類型」清單中,選取「Vertex AI 遠端模型、遠端函式和 BigLake (Cloud 資源)」。
- 在「連線 ID」欄位為連線輸入 gemini_conn。
- 「位置類型」請選取「多區域」,然後從下拉式選單中選取「US」這個多區域。
- 其他設定均保留預設值。
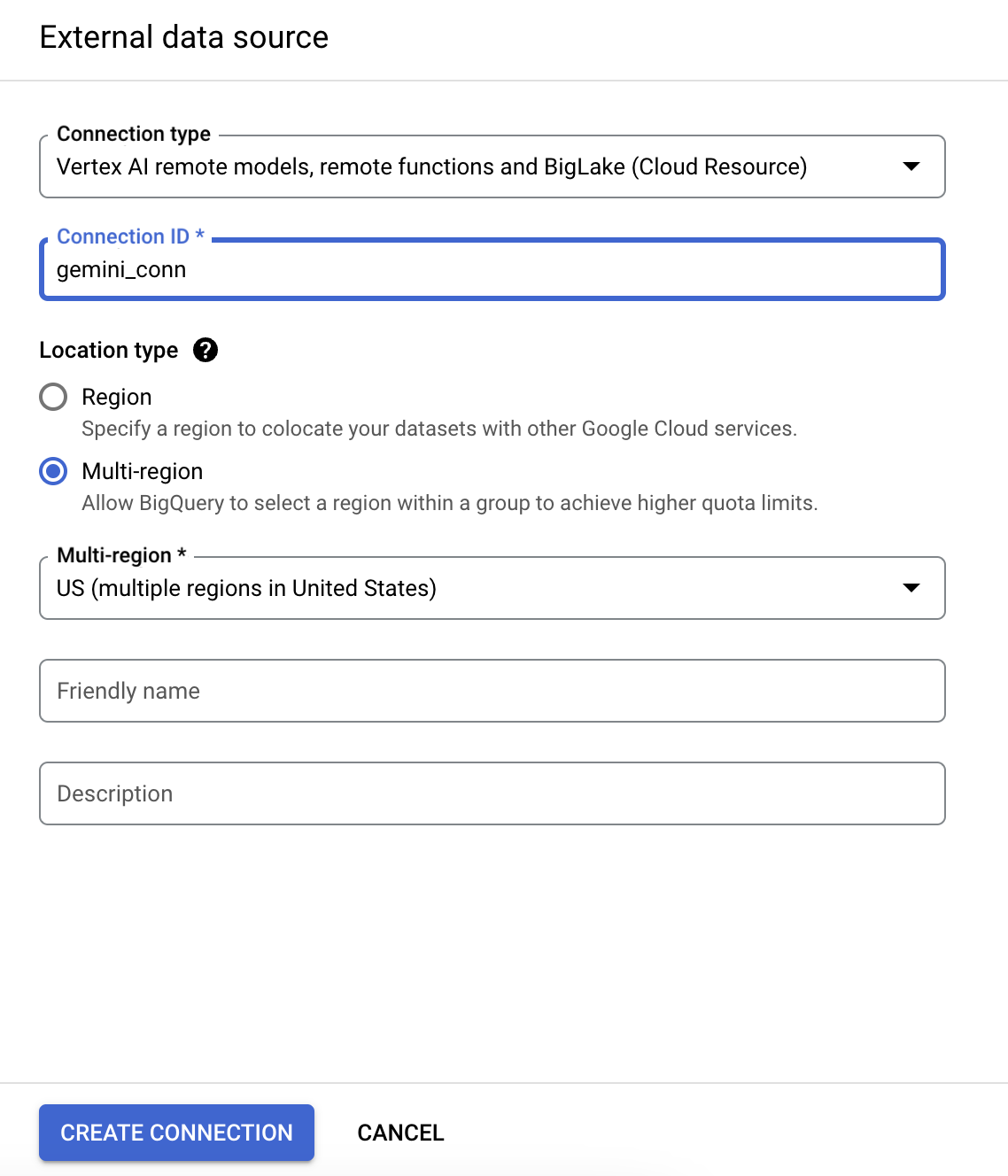
- 點選「建立連線」。
- 點選「前往連線」。
- 在「連線資訊」窗格,將服務帳戶 ID 複製到文字檔案,方便在下一項工作中使用。在 BigQuery Explorer,您也會看到該連線已新增至專案的「外部連線」專區。
5. 將 IAM 權限授予連線的服務帳戶
在這項工作,您會為 Cloud 資源連線的服務帳戶指定角色,讓帳戶具備 IAM 權限,以便使用 Vertex AI 服務。
- 前往 Google Cloud 控制台,依序點選「導覽選單」和「IAM 與管理」,
- 點選「授予存取權」。
- 在「新增主體」欄位,輸入先前複製的服務帳戶 ID。
- 在「選取角色」欄位輸入 Vertex AI,然後選取「Vertex AI 使用者」角色。
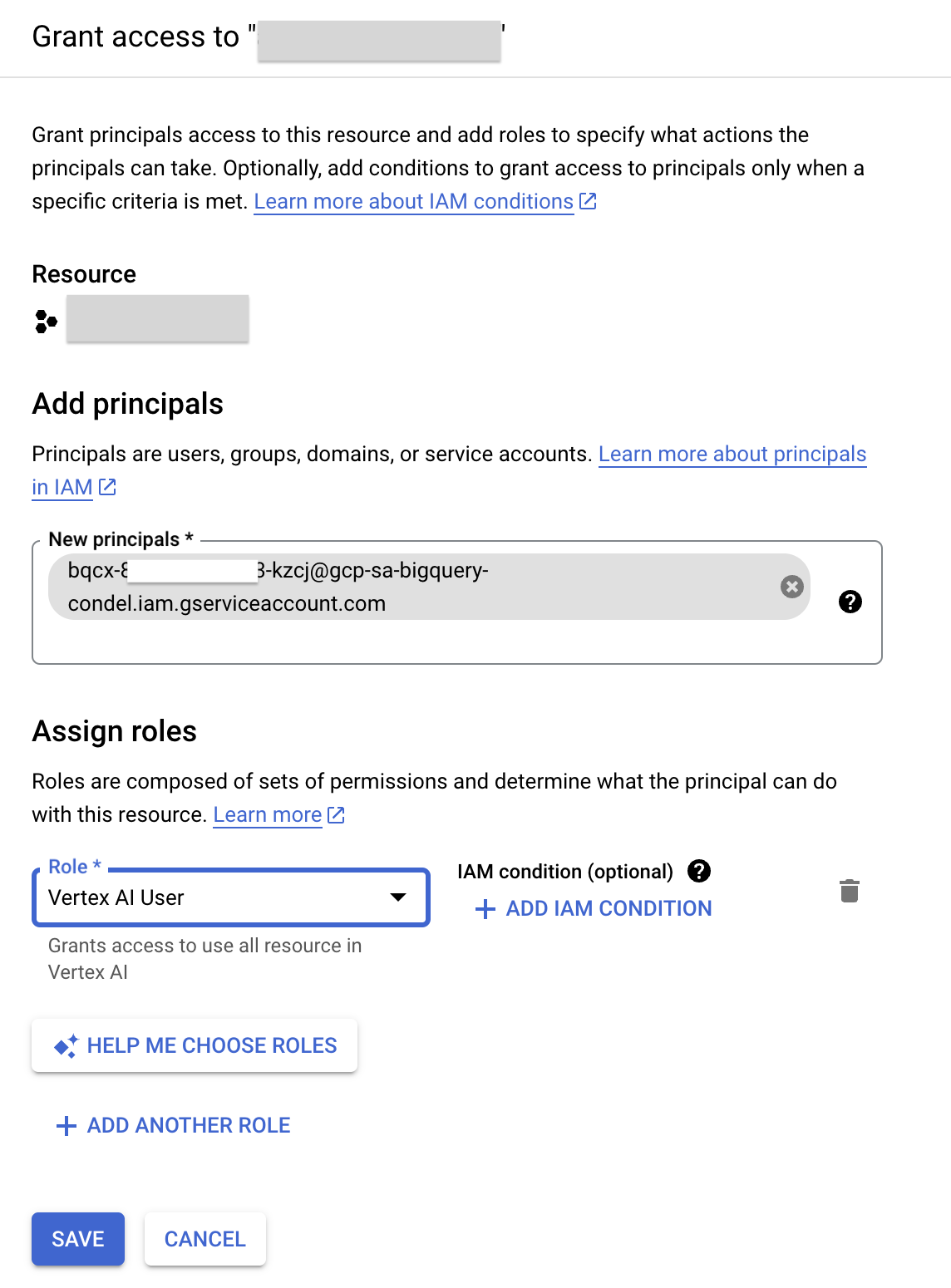
- 按一下 [儲存]。現在服務帳戶 ID 具備 Vertex AI 使用者角色。
6. 在 BigQuery 為電影海報圖片建立資料集和物件資料表
在這項工作中,您會建立專案資料集,並在當中建立物件資料表來儲存海報圖片。
本教學課程使用的電影海報圖片資料集儲存在公開的 Google Cloud Storage bucket 中:gs://cloud-samples-data/vertex-ai/dataset-management/datasets/classic-movie-posters
建立資料集
您將建立資料集,儲存本教學課程中使用的資料庫物件,包括資料表和模型。
- 前往 Google Cloud 控制台,依序選取「導覽選單」圖示 和「BigQuery」。
- 在「Explorer」面板中,選取專案名稱旁邊的「查看動作」圖示 (
 ),然後選取「建立資料集」。
),然後選取「建立資料集」。 - 在「建立資料集」窗格,輸入以下資訊:
- 資料集 ID:gemini_demo
- 位置類型:選取「多區域」
- 多區域:選取「美國」
- 其他欄位均保留預設值。
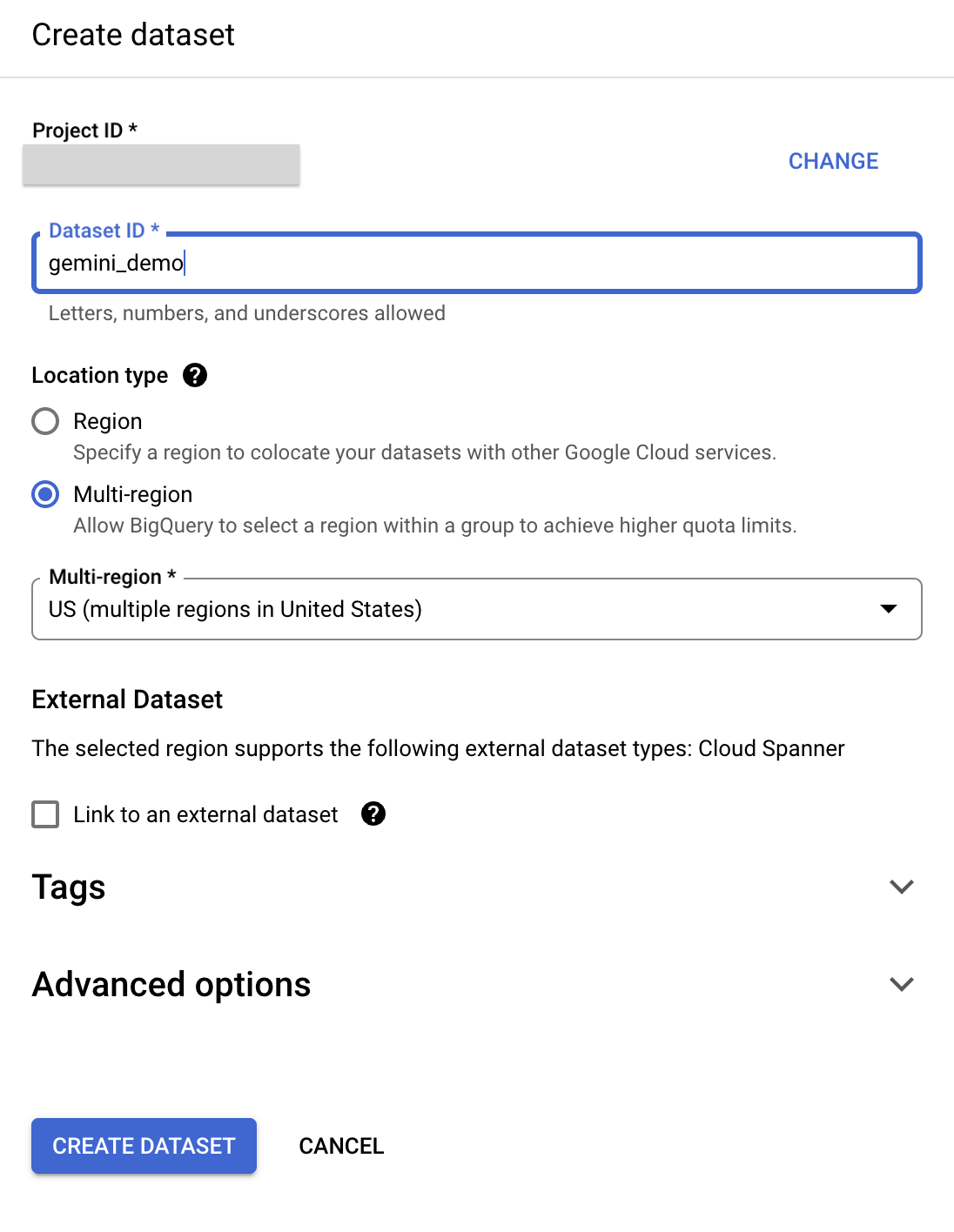
- 點選「建立資料集」。
系統就會建立 gemini_demo 資料集,並在 BigQuery Explorer 中列於專案下方。
建立物件資料表
BigQuery 不僅能保存結構化資料,還能透過物件資料表存取非結構化資料 (例如海報圖片)。
您只要指向 Cloud Storage 值區,即可建立物件資料表,產生的物件資料表會為值區中的每個物件提供一個資料列,其中包含儲存路徑和中繼資料。
您會使用 SQL 查詢來建立物件資料表。
- 點選「+」,建立新的 SQL 查詢。
- 在查詢編輯器貼上以下查詢。
CREATE OR REPLACE EXTERNAL TABLE
`gemini_demo.movie_posters`
WITH CONNECTION `us.gemini_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://cloud-samples-data/vertex-ai/dataset-management/datasets/classic-movie-posters/*']
);
- 執行查詢。系統會將
movie_posters物件資料表新增至gemini_demo資料集,並載入每張電影海報圖片的URI(Cloud Storage 位置)。 - 在 Explorer 點選「
movie_posters」,查看結構定義和詳細資料。如要查看特定記錄,可以查詢資料表。
7. 在 BigQuery 建立 Gemini 遠端模型
建立物件資料表後,即可開始使用。在這項工作中,您將建立 Gemini 1.5 Flash 的遠端模型,以便在 BigQuery 中使用。
建立 Gemini 1.5 Flash 遠端模型
- 點選「+」,建立新的 SQL 查詢。
- 在查詢編輯器中,貼上並執行以下查詢。
CREATE OR REPLACE MODEL `gemini_demo.gemini_1_5_flash`
REMOTE WITH CONNECTION `us.gemini_conn`
OPTIONS (endpoint = 'gemini-1.5-flash')
系統會建立 gemini_1_5_flash 模型,並新增至模型專區的 gemini_demo 資料集。
- 在 Explorer 點選「
gemini_1_5_flash」模型,查看詳細資料。
8. 提示 Gemini 模型為每張海報提供電影摘要
在這項工作中,您會使用剛建立的 Gemini 遠端模型分析電影海報圖片,為每部電影生成摘要。
您可以使用 ML.GENERATE_TEXT 函式向模型傳送要求,並在參數中參照模型。
使用 Gemini 1.5 Flash 模型分析圖片
- 使用以下 SQL 陳述式建立及執行新的查詢:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results` AS (
SELECT
uri,
ml_generate_text_llm_result
FROM
ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_1_5_flash`,
TABLE `gemini_demo.movie_posters`,
STRUCT( 0.2 AS temperature,
'For the movie represented by this poster, what is the movie title and year of release? Answer in JSON format with two keys: title, year. title should be string, year should be integer. Do not use JSON decorators.' AS PROMPT,
TRUE AS FLATTEN_JSON_OUTPUT)));
查詢執行時,BigQuery 會針對物件資料表的每個資料列提示 Gemini 模型,並將圖片與指定的靜態提示合併。系統就會建立 movie_posters_results 資料表。
- 現在來查看結果。使用以下 SQL 陳述式建立及執行新的查詢:
SELECT * FROM `gemini_demo.movie_posters_results`
在產生的資料表中,每張電影海報都有一個資料列,其中顯示 URI (電影海報圖片的 Cloud Storage 位置) 和 JSON 結果,包含 Gemini 1.5 Flash 模型生成的片名和上映年份。
您可以使用下方查詢,用較方便人類閱讀的方式擷取資料:這項查詢會使用 SQL,將這些回應中的電影名稱和發行年份擷取到新的資料欄。
- 使用以下 SQL 陳述式建立及執行新的查詢:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results_formatted` AS (
SELECT
uri,
JSON_VALUE(ml_generate_text_llm_result, "$.title") AS title,
JSON_VALUE(ml_generate_text_llm_result, "$.year") AS year
FROM
`gemini_demo.movie_posters_results` results )
系統就會建立 movie_posters_result_formatted 資料表。
- 您可以對這個資料表執行以下查詢,查看建立的資料列。
SELECT * FROM `gemini_demo.movie_posters_results_formatted`
您會發現每列的 URI 欄結果維持不變,但 JSON 現已轉為 title 和 year 欄。
提示 Gemini 1.5 Flash 模型提供電影摘要
如果想進一步瞭解這些電影,例如每部電影的文字摘要,該怎麼做?這類內容生成用途非常適合使用 LLM 模型,例如 Gemini 1.5 Flash 模型。
- 您可以執行下列查詢,使用 Gemini 1.5 Flash 為每張海報提供電影摘要:
SELECT
uri,
title,
year,
prompt,
ml_generate_text_llm_result
FROM
ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_1_5_flash`,
(
SELECT
CONCAT('Provide a short summary of movie titled ',title, ' from the year ',year,'.') AS prompt,
uri,
title,
year
FROM
`gemini_demo.movie_posters_results_formatted`
LIMIT
20 ),
STRUCT(0.2 AS temperature,
TRUE AS FLATTEN_JSON_OUTPUT));
請注意結果的 ml_generate_text_llm_result 欄位,其中包含電影的簡短摘要。
9. 使用遠端模型生成文字嵌入
現在,您可以將建構的結構化資料,與資料倉儲中的其他結構化資料彙整。BigQuery 提供的 IMDB 公開資料集包含豐富的電影資訊,包括觀眾評分和一些免費的任意形式使用者評論。這項資料有助於深入分析電影海報,瞭解這些電影的觀感。
如要聯結資料,您需要使用鍵。在這種情況下,Gemini 模型生成的電影名稱可能與 IMDb 資料集中的名稱不完全相符。
在這項工作中,您會從兩個資料集生成電影名稱和年份的文字嵌入,然後使用這些嵌入之間的距離,將最接近的 IMDb 片名與新建立資料集的電影海報片名合併。
建立遠端模型
如要生成文字嵌入,您需要建立指向 text-multilingual-embedding-002 端點的新遠端模型。
- 使用以下 SQL 陳述式建立及執行新的查詢:
CREATE OR REPLACE MODEL `gemini_demo.text_embedding`
REMOTE WITH CONNECTION `us.gemini_conn`
OPTIONS (endpoint = 'text-multilingual-embedding-002')
系統會建立 text_embedding 模型,並在 Explorer 列於 gemini_demo 資料集下方。
為片名和上映年份生成文字嵌入
您現在可以使用 ML.GENERATE_EMBEDDING 函式搭配這個遠端模型,為每部電影海報的片名和年份建立嵌入。
- 使用以下 SQL 陳述式建立及執行新的查詢:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results_embeddings` AS (
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
MODEL `gemini_demo.text_embedding`,
(
SELECT
CONCAT('The movie titled ', title, ' from the year ', year,'.') AS content,
title,
year,
uri
FROM
`gemini_demo.movie_posters_results_formatted` ),
STRUCT(TRUE AS flatten_json_output)));
系統會建立 movie_poster_results_embeddings 資料表,其中包含 gemini_demo.movie_posters_results_formatted 資料表每列串連的文字內容嵌入。
- 您可以使用下面這個新查詢來查看結果:
SELECT * FROM `gemini_demo.movie_posters_results_embeddings`
您可以看到模型為每部電影生成的嵌入 (以數字表示的向量)。
為 IMDb 資料集的部分資料生成文字嵌入
您會從公開的 IMDB 資料集建立新的資料檢視畫面,其中只包含 1935 年以前上映的電影 (海報圖片中電影的已知時間範圍)。
- 使用以下 SQL 陳述式建立及執行新的查詢:
CREATE OR REPLACE VIEW
`gemini_demo.imdb_movies` AS (
WITH
reviews AS (
SELECT
reviews.movie_id AS movie_id,
title.primary_title AS title,
title.start_year AS year,
reviews.review AS review
FROM
`bigquery-public-data.imdb.reviews` reviews
LEFT JOIN
`bigquery-public-data.imdb.title_basics` title
ON
reviews.movie_id = title.tconst)
SELECT
DISTINCT(movie_id),
title,
year
FROM
reviews
WHERE
year < 1935)
系統就會生成新的 view,其中涵蓋 bigquery-public-data.imdb.reviews 資料表中 1935 年以前上映的所有電影,並顯示各電影的 ID、片名和上映年份。
- 現在,您將使用與上一節類似的程序,為 IMDb 的電影子集建立嵌入。使用以下 SQL 陳述式建立及執行新的查詢:
CREATE OR REPLACE TABLE
`gemini_demo.imdb_movies_embeddings` AS (
SELECT
*
FROM
ML.GENERATE_EMBEDDING( MODEL `gemini_demo.text_embedding`,
(
SELECT
CONCAT('The movie titled ', title, ' from the year ', year,'.') AS content,
title,
year,
movie_id
FROM
`gemini_demo.imdb_movies` ),
STRUCT(TRUE AS flatten_json_output) )
WHERE
ml_generate_embedding_status = '' );
系統就會生成資料表,內含 gemini_demo.imdb_movies 資料表的文字內容嵌入。
使用 BigQuery VECTOR_SEARCH,為各電影海報圖片找出對應的 IMDb movie_id
現在,您可以使用 VECTOR_SEARCH 函式彙整這兩個資料表。
- 使用以下 SQL 陳述式建立及執行新的查詢:
SELECT
query.uri AS poster_uri,
query.title AS poster_title,
query.year AS poster_year,
base.title AS imdb_title,
base.year AS imdb_year,
base.movie_id AS imdb_movie_id,
distance
FROM
VECTOR_SEARCH( TABLE `gemini_demo.imdb_movies_embeddings`,
'ml_generate_embedding_result',
TABLE `gemini_demo.movie_posters_results_embeddings`,
'ml_generate_embedding_result',
top_k => 1,
distance_type => 'COSINE');
查詢會使用 VECTOR_SEARCH 函式,為 gemini_demo.movie_posters_results_embeddings 資料表中的每個資料列,在 gemini_demo.imdb_movies_embeddings 資料表找出最鄰近的項目。系統會使用餘弦距離指標來找出最鄰近的項目,這個指標用來表示兩個嵌入的相似度。
在前面的步驟,我們使用 Gemini 1.5 Flash 辨識出海報中的電影。這個查詢可根據 Gemini 辨識出的電影,在 IMDb 資料集找出最相似的電影。舉例來說,您可以使用這項查詢,根據 Gemini Pro Vision 從電影海報辨識出的片名《Au Secours!》,從 IMDb 公開資料集找出與最接近的電影,該電影在 IMDb 是以英文片名《Help!》表示。
- 建立並執行新的查詢,以 join 的方式結合 IMDb 公開資料集裡額外的電影評分資訊:
SELECT
query.uri AS poster_uri,
query.title AS poster_title,
query.year AS poster_year,
base.title AS imdb_title,
base.year AS imdb_year,
base.movie_id AS imdb_movie_id,
distance,
imdb.average_rating,
imdb.num_votes
FROM
VECTOR_SEARCH( TABLE `gemini_demo.imdb_movies_embeddings`,
'ml_generate_embedding_result',
TABLE `gemini_demo.movie_posters_results_embeddings`,
'ml_generate_embedding_result',
top_k => 1,
distance_type => 'COSINE') DATA
LEFT JOIN
`bigquery-public-data.imdb.title_ratings` imdb
ON
base.movie_id = imdb.tconst
ORDER BY
imdb.average_rating DESC
這項查詢與剛才類似,系統仍會使用向量嵌入這種特殊數值表示法,找出與某個電影海報相似的電影。不過,這個資料集也從 IMDb 公開資料集的另一個資料表,以 join 的方式結合每部最相似電影的平均評分和投票數。
10. 恭喜
恭喜您完成本程式碼研究室。您已在 BigQuery 中為海報圖片建立物件資料表、建立遠端 Gemini 模型、使用模型提示 Gemini 模型分析圖片並提供電影摘要、為電影名稱產生文字嵌入,以及使用這些嵌入將電影海報圖片與 IMDB 資料集中的相關電影名稱配對。
涵蓋內容
- 如何設定環境和帳戶以使用 API
- 如何在 BigQuery 中建立雲端資源連線
- 如何在 BigQuery 為電影海報圖片建立資料集和物件資料表
- 如何在 BigQuery 建立 Gemini 遠端模型
- 如何提示 Gemini 模型為每張海報提供電影摘要
- 如何根據每張海報代表的電影生成文字嵌入
- 如何使用 BigQuery
VECTOR_SEARCH,找出資料集中與電影海報圖片高度相關的電影
後續步驟 / 瞭解詳情