
1. บทนำ
ในแล็บนี้ คุณจะได้เรียนรู้วิธีใช้แมชชีนเลิร์นนิงของ BigQuery เพื่อการอนุมานด้วยโมเดลระยะไกล ( โมเดล Gemini) ในการวิเคราะห์รูปภาพโปสเตอร์ภาพยนตร์และสร้างข้อมูลสรุปของภาพยนตร์โดยอิงตามโปสเตอร์ในคลังข้อมูล BigQuery โดยตรง

รูปภาพด้านบน: ตัวอย่างรูปภาพโปสเตอร์ภาพยนตร์ที่คุณจะวิเคราะห์
BigQuery เป็นแพลตฟอร์มการวิเคราะห์ข้อมูลที่พร้อมใช้งาน AI และได้รับการจัดการอย่างเต็มรูปแบบ ซึ่งช่วยให้คุณได้รับประโยชน์สูงสุดจากข้อมูล และออกแบบมาให้ใช้ได้กับหลายเครื่องมือ หลายรูปแบบ และหลายระบบคลาวด์ ฟีเจอร์หลักอย่างหนึ่งคือ BigQuery Machine Learning สำหรับการอนุมาน ซึ่งช่วยให้คุณสร้างและเรียกใช้โมเดลแมชชีนเลิร์นนิง (ML) ได้โดยใช้การค้นหา GoogleSQL
Gemini คือตระกูลโมเดล Generative AI ที่พัฒนาโดย Google ซึ่งออกแบบมาสำหรับกรณีการใช้งานหลายรูปแบบ
การเรียกใช้โมเดล ML โดยใช้การค้นหา GoogleSQL
โดยปกติแล้ว การดำเนินการ ML หรือปัญญาประดิษฐ์ (AI) ในชุดข้อมูลขนาดใหญ่ต้องใช้การเขียนโปรแกรมและความรู้เกี่ยวกับเฟรมเวิร์ก ML อย่างกว้างขวาง ซึ่งจำกัดการพัฒนาโซลูชันไว้เฉพาะผู้เชี่ยวชาญกลุ่มเล็กๆ ภายในแต่ละบริษัท เมื่อใช้แมชชีนเลิร์นนิงของ BigQuery สำหรับการอนุมาน ผู้ปฏิบัติงาน SQL สามารถใช้ทักษะและเครื่องมือ SQL ที่มีอยู่เพื่อสร้างโมเดล และสร้างผลลัพธ์จาก LLM และ Cloud AI API
ข้อกำหนดเบื้องต้น
- ความเข้าใจพื้นฐานเกี่ยวกับ Google Cloud Console
- มีประสบการณ์การใช้งาน BigQuery จะได้รับการพิจารณาเป็นพิเศษ
สิ่งที่คุณจะได้เรียนรู้
- วิธีกำหนดค่าสภาพแวดล้อมและบัญชีเพื่อใช้ API
- วิธีสร้างการเชื่อมต่อทรัพยากรระบบคลาวด์ใน BigQuery
- วิธีสร้างชุดข้อมูลและตารางออบเจ็กต์ใน BigQuery สำหรับรูปภาพโปสเตอร์ภาพยนตร์
- วิธีสร้างโมเดลระยะไกลของ Gemini ใน BigQuery
- วิธีพรอมต์โมเดล Gemini เพื่อให้สรุปภาพยนตร์สำหรับโปสเตอร์แต่ละรายการ
- วิธีสร้างการฝังข้อความสำหรับภาพยนตร์ที่แสดงในโปสเตอร์แต่ละรายการ
- วิธีใช้ BigQuery
VECTOR_SEARCHเพื่อจับคู่รูปภาพโปสเตอร์ภาพยนตร์กับภาพยนตร์ที่เกี่ยวข้องอย่างใกล้ชิดในชุดข้อมูล
สิ่งที่คุณต้องมี
- บัญชี Google Cloud และโปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
- เว็บเบราว์เซอร์ เช่น Chrome
2. การตั้งค่าและข้อกำหนด
การตั้งค่าสภาพแวดล้อมแบบเรียนรู้ด้วยตนเอง
- ลงชื่อเข้าใช้ Google Cloud Console แล้วสร้างโปรเจ็กต์ใหม่หรือใช้โปรเจ็กต์ที่มีอยู่ซ้ำ หากยังไม่มีบัญชี Gmail หรือ Google Workspace คุณต้องสร้างบัญชี



- ชื่อโปรเจ็กต์คือชื่อที่แสดงสำหรับผู้เข้าร่วมโปรเจ็กต์นี้ ซึ่งเป็นสตริงอักขระที่ Google APIs ไม่ได้ใช้ คุณอัปเดตได้ทุกเมื่อ
- รหัสโปรเจ็กต์จะไม่ซ้ำกันในโปรเจ็กต์ Google Cloud ทั้งหมดและเปลี่ยนแปลงไม่ได้ (เปลี่ยนไม่ได้หลังจากตั้งค่าแล้ว) Cloud Console จะสร้างสตริงที่ไม่ซ้ำกันโดยอัตโนมัติ ซึ่งโดยปกติแล้วคุณไม่จำเป็นต้องสนใจว่าสตริงนั้นคืออะไร ใน Codelab ส่วนใหญ่ คุณจะต้องอ้างอิงรหัสโปรเจ็กต์ (โดยทั่วไปจะระบุเป็น
PROJECT_ID) หากไม่ชอบรหัสที่สร้างขึ้น คุณอาจสร้างรหัสแบบสุ่มอีกรหัสหนึ่งได้ หรือคุณอาจลองใช้ชื่อของคุณเองและดูว่ามีชื่อนั้นหรือไม่ คุณจะเปลี่ยนแปลงรหัสนี้หลังจากขั้นตอนนี้ไม่ได้ และรหัสจะคงอยู่ตลอดระยะเวลาของโปรเจ็กต์ - โปรดทราบว่ายังมีค่าที่ 3 ซึ่งคือหมายเลขโปรเจ็กต์ที่ API บางตัวใช้ ดูข้อมูลเพิ่มเติมเกี่ยวกับค่าทั้ง 3 นี้ได้ในเอกสารประกอบ
- จากนั้นคุณจะต้องเปิดใช้การเรียกเก็บเงินใน Cloud Console เพื่อใช้ทรัพยากร/API ของ Cloud การทำตาม Codelab นี้จะไม่มีค่าใช้จ่ายมากนัก หรืออาจไม่มีค่าใช้จ่ายเลย หากต้องการปิดทรัพยากรเพื่อหลีกเลี่ยงการเรียกเก็บเงินนอกเหนือจากบทแนะนำนี้ คุณสามารถลบทรัพยากรที่สร้างขึ้นหรือลบโปรเจ็กต์ได้ ผู้ใช้ Google Cloud รายใหม่มีสิทธิ์เข้าร่วมโปรแกรมช่วงทดลองใช้ฟรีมูลค่า$300 USD
เริ่มต้น Cloud Shell
แม้ว่าคุณจะใช้งาน Google Cloud จากระยะไกลจากแล็ปท็อปได้ แต่ใน Codelab นี้คุณจะใช้ Google Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานในระบบคลาวด์
จาก Google Cloud Console ให้คลิกไอคอน Cloud Shell ในแถบเครื่องมือด้านขวาบน

การจัดสรรและเชื่อมต่อกับสภาพแวดล้อมจะใช้เวลาเพียงไม่กี่นาที เมื่อเสร็จแล้ว คุณควรเห็นข้อความคล้ายกับตัวอย่างต่อไปนี้

เครื่องเสมือนนี้มาพร้อมเครื่องมือพัฒนาซอฟต์แวร์ทั้งหมดที่คุณต้องการ โดยมีไดเรกทอรีหลักแบบถาวรขนาด 5 GB และทำงานบน Google Cloud ซึ่งช่วยเพิ่มประสิทธิภาพเครือข่ายและการตรวจสอบสิทธิ์ได้อย่างมาก คุณสามารถทำงานทั้งหมดใน Codelab นี้ได้ภายในเบราว์เซอร์ คุณไม่จำเป็นต้องติดตั้งอะไร
3. ก่อนเริ่มต้น
มีขั้นตอนการตั้งค่า 2-3 ขั้นตอนสำหรับการทำงานกับโมเดล Gemini ใน BigQuery ซึ่งรวมถึงการเปิดใช้ API, การสร้างการเชื่อมต่อทรัพยากร Cloud และการให้สิทธิ์บางอย่างแก่บัญชีบริการสำหรับการเชื่อมต่อทรัพยากร Cloud ขั้นตอนเหล่านี้เป็นขั้นตอนแบบครั้งเดียวต่อโปรเจ็กต์ และจะอธิบายไว้ใน 2-3 ส่วนถัดไป
เปิดใช้ API
ใน Cloud Shell ให้ตรวจสอบว่าได้ตั้งค่ารหัสโปรเจ็กต์แล้ว
gcloud config set project [YOUR-PROJECT-ID]
ตั้งค่าตัวแปรสภาพแวดล้อม PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
กำหนดค่าภูมิภาคเริ่มต้นที่จะใช้สำหรับโมเดล Vertex AI อ่านเพิ่มเติมเกี่ยวกับสถานที่ที่ Vertex AI พร้อมให้บริการ ในตัวอย่างนี้ เราใช้ภูมิภาค us-central1
gcloud config set compute/region us-central1
ตั้งค่าตัวแปรสภาพแวดล้อม REGION:
REGION=$(gcloud config get-value compute/region)
เปิดใช้บริการที่จำเป็นทั้งหมด
gcloud services enable bigqueryconnection.googleapis.com \
aiplatform.googleapis.com
เอาต์พุตที่คาดไว้หลังจากเรียกใช้คำสั่งทั้งหมดข้างต้น
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable bigqueryconnection.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. สร้างการเชื่อมต่อทรัพยากรระบบคลาวด์
ในงานนี้ คุณจะสร้างการเชื่อมต่อทรัพยากรระบบคลาวด์ ซึ่งจะช่วยให้ BigQuery เข้าถึงไฟล์รูปภาพใน Cloud Storage และทำการเรียกไปยัง Vertex AI ได้
- ใน Google Cloud Console ให้คลิก BigQuery ในเมนูการนำทาง (
 )
)
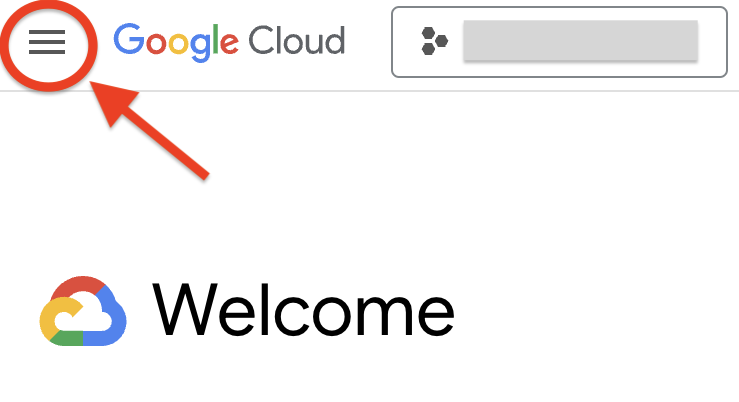
- หากต้องการสร้างการเชื่อมต่อ ให้คลิก + เพิ่ม แล้วคลิกการเชื่อมต่อกับแหล่งข้อมูลภายนอก
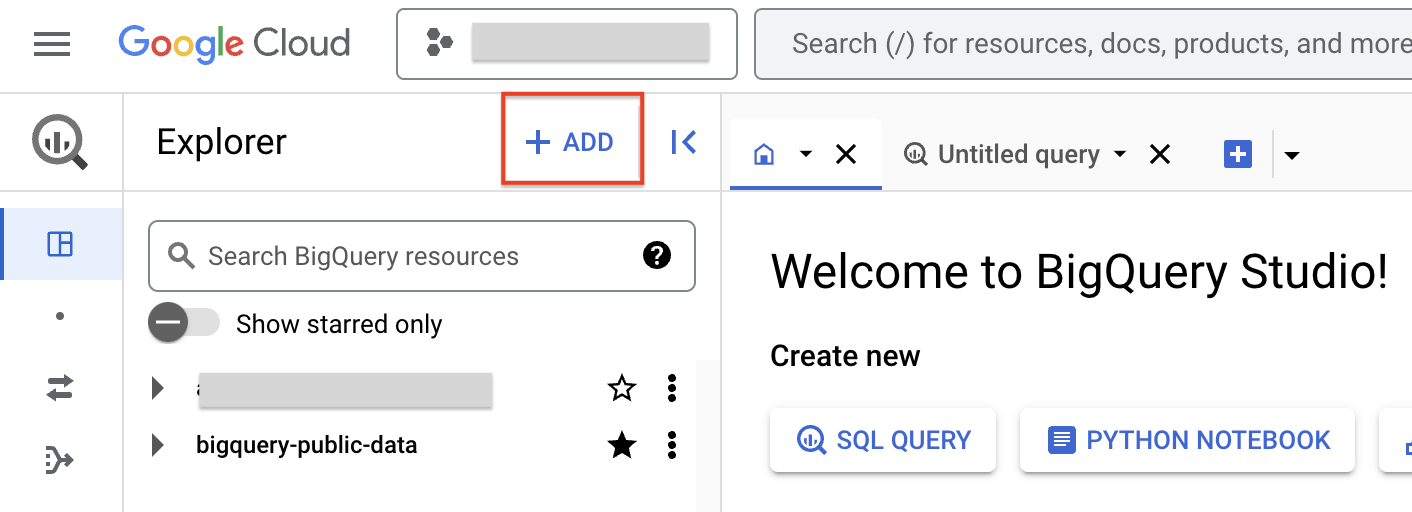
- ในรายการประเภทการเชื่อมต่อ ให้เลือกโมเดลระยะไกล ฟังก์ชันระยะไกล และ BigLake (ทรัพยากรระบบคลาวด์) ของ Vertex AI
- ในช่องรหัสการเชื่อมต่อ ให้ป้อน gemini_conn สำหรับการเชื่อมต่อ
- สำหรับประเภทสถานที่ตั้ง ให้เลือกหลายภูมิภาค แล้วเลือกหลายภูมิภาคในสหรัฐอเมริกาจากเมนูแบบเลื่อนลง
- ใช้ค่าเริ่มต้นสำหรับการตั้งค่าอื่นๆ
- คลิกสร้างการเชื่อมต่อ
- คลิกไปที่การเชื่อมต่อ
- ในแผงข้อมูลการเชื่อมต่อ ให้คัดลอกรหัสบัญชีบริการไปยังไฟล์ข้อความเพื่อใช้ในงานถัดไป นอกจากนี้ คุณยังจะเห็นว่าระบบได้เพิ่มการเชื่อมต่อไว้ในส่วนการเชื่อมต่อภายนอกของโปรเจ็กต์ใน BigQuery Explorer ด้วย
5. ให้สิทธิ์ IAM แก่บัญชีบริการของการเชื่อมต่อ
ในงานนี้ คุณจะให้สิทธิ์ IAM ของบัญชีบริการของ Cloud Resource Connection ผ่านบทบาท เพื่อให้บัญชีเข้าถึงบริการ Vertex AI ได้
- ใน Google Cloud Console ให้คลิก IAM และผู้ดูแลระบบในเมนูการนำทาง
- คลิกให้สิทธิ์เข้าถึง
- ในช่องผู้ใช้หลักรายใหม่ ให้ป้อนรหัสบัญชีบริการที่คัดลอกไว้ก่อนหน้านี้
- ในช่องเลือกบทบาท ให้ป้อน Vertex AI แล้วเลือกบทบาทผู้ใช้ Vertex AI
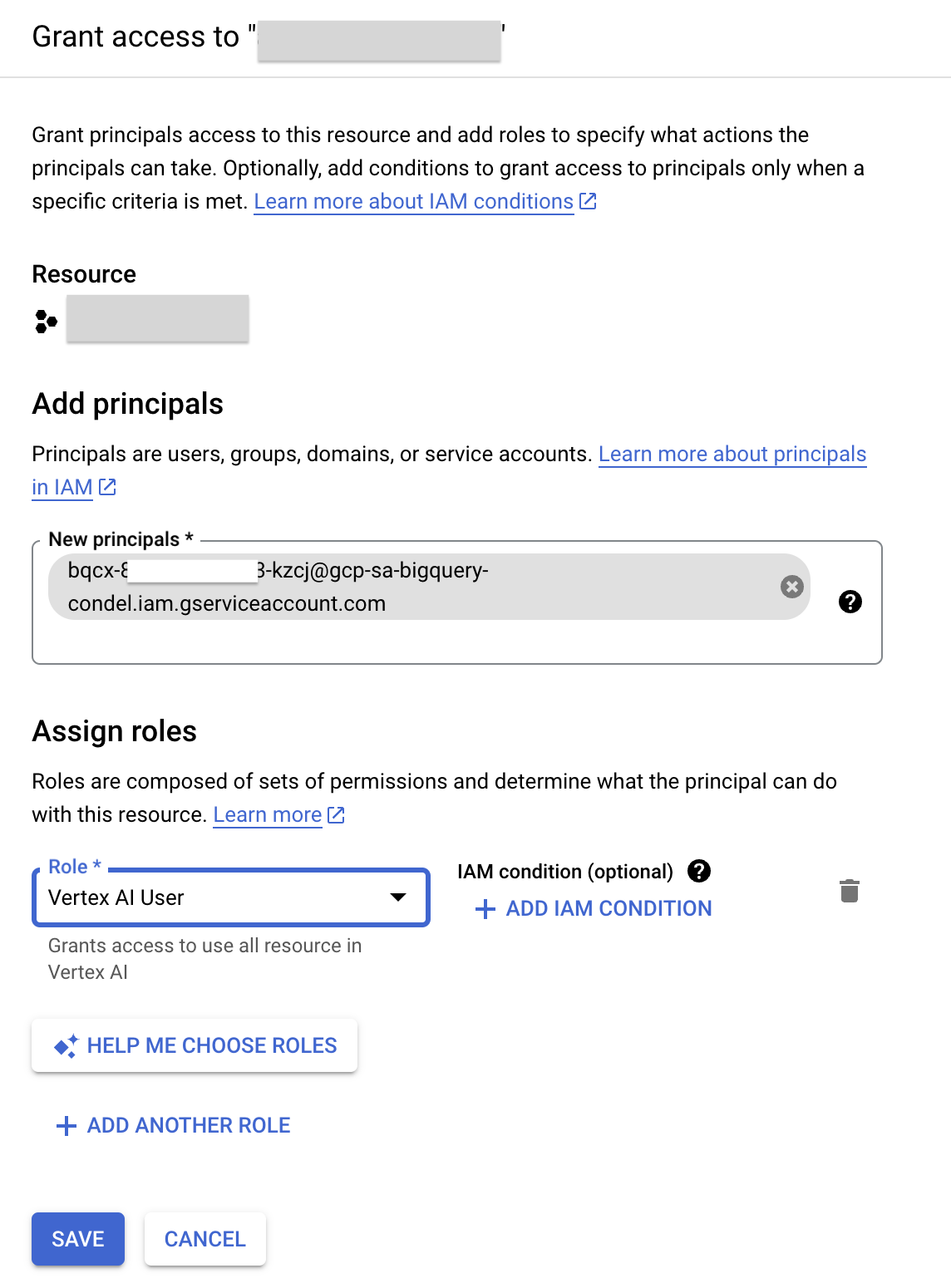
- คลิกบันทึก ผลลัพธ์คือตอนนี้รหัสบัญชีบริการมีบทบาทผู้ใช้ Vertex AI แล้ว
6. สร้างชุดข้อมูลและตารางออบเจ็กต์ใน BigQuery สำหรับรูปภาพโปสเตอร์ภาพยนตร์
ในงานนี้ คุณจะได้สร้างชุดข้อมูลสำหรับโปรเจ็กต์และตารางออบเจ็กต์ภายในชุดข้อมูลเพื่อจัดเก็บรูปภาพโปสเตอร์
ชุดข้อมูลรูปภาพโปสเตอร์ภาพยนตร์ที่ใช้ในบทแนะนำนี้จัดเก็บไว้ใน Bucket ของ Google Cloud Storage สาธารณะ gs://cloud-samples-data/vertex-ai/dataset-management/datasets/classic-movie-posters
สร้างชุดข้อมูล
คุณจะสร้างชุดข้อมูลเพื่อจัดเก็บออบเจ็กต์ฐานข้อมูล ซึ่งรวมถึงตารางและโมเดลที่ใช้ในบทแนะนำนี้
- ใน Google Cloud Console ให้เลือกเมนูการนำทาง ( ) แล้วเลือก BigQuery
- ในแผง Explorer ให้เลือกดูการดำเนินการ (
 ) ข้างชื่อโปรเจ็กต์ แล้วเลือกสร้างชุดข้อมูล
) ข้างชื่อโปรเจ็กต์ แล้วเลือกสร้างชุดข้อมูล - ในแผงสร้างชุดข้อมูล ให้ป้อนข้อมูลต่อไปนี้
- รหัสชุดข้อมูล: gemini_demo
- ประเภทสถานที่ตั้ง: เลือกหลายภูมิภาค
- หลายภูมิภาค: เลือก US
- ปล่อยช่องอื่นๆ เป็นค่าเริ่มต้นไว้

- คลิกสร้างชุดข้อมูล
ผลลัพธ์คือระบบจะสร้างgemini_demoชุดข้อมูลและแสดงไว้ใต้โปรเจ็กต์ใน BigQuery Explorer
สร้างตารางออบเจ็กต์
BigQuery ไม่เพียงจัดเก็บข้อมูลที่มีโครงสร้าง แต่ยังเข้าถึงข้อมูลที่ไม่มีโครงสร้าง (เช่น รูปภาพโปสเตอร์) ผ่านตารางออบเจ็กต์ได้ด้วย
คุณสร้างตารางออบเจ็กต์ได้โดยชี้ไปยังที่เก็บข้อมูล Cloud Storage และตารางออบเจ็กต์ที่ได้จะมีแถวสำหรับออบเจ็กต์แต่ละรายการจากที่เก็บข้อมูลพร้อมเส้นทางการจัดเก็บและข้อมูลเมตา
หากต้องการสร้างตารางออบเจ็กต์ คุณจะต้องใช้การค้นหา SQL
- คลิก + เพื่อสร้างการค้นหา SQL ใหม่
- วางคำค้นหาด้านล่างในตัวแก้ไขคำค้นหา
CREATE OR REPLACE EXTERNAL TABLE
`gemini_demo.movie_posters`
WITH CONNECTION `us.gemini_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://cloud-samples-data/vertex-ai/dataset-management/datasets/classic-movie-posters/*']
);
- เรียกใช้การค้นหา ผลลัพธ์คือตารางออบเจ็กต์
movie_postersที่เพิ่มลงในชุดข้อมูลgemini_demoและโหลดด้วยURI(ตำแหน่ง Cloud Storage) ของรูปภาพโปสเตอร์ภาพยนตร์แต่ละรายการ - ใน Explorer ให้คลิก
movie_postersแล้วตรวจสอบสคีมาและรายละเอียด คุณสามารถค้นหาตารางเพื่อตรวจสอบระเบียนที่เฉพาะเจาะจงได้
7. สร้างโมเดลระยะไกลของ Gemini ใน BigQuery
เมื่อสร้างตารางออบเจ็กต์แล้ว คุณก็เริ่มทำงานกับตารางได้ ในงานนี้ คุณจะสร้างโมเดลระยะไกลสำหรับ Gemini 1.5 Flash เพื่อให้พร้อมใช้งานใน BigQuery
สร้างโมเดลระยะไกล Gemini 1.5 Flash
- คลิก + เพื่อสร้างการค้นหา SQL ใหม่
- วางคำค้นหาด้านล่างในตัวแก้ไขคำค้นหา แล้วเรียกใช้
CREATE OR REPLACE MODEL `gemini_demo.gemini_1_5_flash`
REMOTE WITH CONNECTION `us.gemini_conn`
OPTIONS (endpoint = 'gemini-1.5-flash')
ผลลัพธ์คือระบบจะสร้างโมเดล gemini_1_5_flash และคุณจะเห็นว่าระบบได้เพิ่มโมเดลดังกล่าวลงในชุดข้อมูล gemini_demo ในส่วนโมเดลแล้ว
- ใน Explorer ให้คลิกโมเดล
gemini_1_5_flashแล้วตรวจสอบรายละเอียด
8. ป้อนพรอมต์โมเดล Gemini เพื่อให้สรุปภาพยนตร์สำหรับโปสเตอร์แต่ละรายการ
ในงานนี้ คุณจะได้ใช้โมเดลระยะไกลของ Gemini ที่เพิ่งสร้างขึ้นเพื่อวิเคราะห์รูปภาพโปสเตอร์ภาพยนตร์และสร้างข้อมูลสรุปสำหรับภาพยนตร์แต่ละเรื่อง
คุณส่งคำขอไปยังโมเดลได้โดยใช้ฟังก์ชัน ML.GENERATE_TEXT โดยอ้างอิงโมเดลในพารามิเตอร์
วิเคราะห์รูปภาพด้วยโมเดล Gemini 1.5 Flash
- สร้างและเรียกใช้การค้นหาใหม่ด้วยคำสั่ง SQL ต่อไปนี้
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results` AS (
SELECT
uri,
ml_generate_text_llm_result
FROM
ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_1_5_flash`,
TABLE `gemini_demo.movie_posters`,
STRUCT( 0.2 AS temperature,
'For the movie represented by this poster, what is the movie title and year of release? Answer in JSON format with two keys: title, year. title should be string, year should be integer. Do not use JSON decorators.' AS PROMPT,
TRUE AS FLATTEN_JSON_OUTPUT)));
เมื่อเรียกใช้การค้นหา BigQuery จะแจ้งโมเดล Gemini สำหรับแต่ละแถวของตารางออบเจ็กต์ โดยรวมรูปภาพเข้ากับพรอมต์แบบคงที่ที่ระบุ ผลลัพธ์คือระบบจะสร้างตาราง movie_posters_results
- ตอนนี้มาดูผลลัพธ์กัน สร้างและเรียกใช้การค้นหาใหม่ด้วยคำสั่ง SQL ต่อไปนี้
SELECT * FROM `gemini_demo.movie_posters_results`
ผลลัพธ์คือแถวสำหรับโปสเตอร์ภาพยนตร์แต่ละเรื่องที่มี URI (ตำแหน่ง Cloud Storage ของรูปภาพโปสเตอร์ภาพยนตร์) และผลลัพธ์ JSON ซึ่งรวมถึงชื่อภาพยนตร์และปีที่ภาพยนตร์ออกฉายจากโมเดล Gemini 1.5 Flash
คุณสามารถดึงผลลัพธ์เหล่านี้ในรูปแบบที่อ่านง่ายขึ้นได้โดยใช้การค้นหาถัดไป คำค้นหานี้ใช้ SQL เพื่อดึงชื่อภาพยนตร์และปีที่เผยแพร่จากคำตอบเหล่านี้ไปยังคอลัมน์ใหม่
- สร้างและเรียกใช้การค้นหาใหม่ด้วยคำสั่ง SQL ต่อไปนี้
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results_formatted` AS (
SELECT
uri,
JSON_VALUE(ml_generate_text_llm_result, "$.title") AS title,
JSON_VALUE(ml_generate_text_llm_result, "$.year") AS year
FROM
`gemini_demo.movie_posters_results` results )
ผลลัพธ์คือระบบจะสร้างตาราง movie_posters_result_formatted
- คุณสามารถค้นหาตารางด้วยการค้นหาด้านล่างเพื่อดูแถวที่สร้างขึ้น
SELECT * FROM `gemini_demo.movie_posters_results_formatted`
สังเกตว่าผลลัพธ์ในคอลัมน์ URI ยังคงเหมือนเดิม แต่ตอนนี้ระบบได้แปลง JSON เป็นคอลัมน์ title และ year สำหรับแต่ละแถวแล้ว
ป้อนพรอมต์ให้โมเดล Gemini 1.5 Flash สรุปภาพยนตร์
จะเกิดอะไรขึ้นหากคุณต้องการข้อมูลเพิ่มเติมเกี่ยวกับภาพยนตร์แต่ละเรื่อง เช่น สรุปข้อความของภาพยนตร์แต่ละเรื่อง กรณีการใช้งานการสร้างเนื้อหานี้เหมาะอย่างยิ่งสำหรับโมเดล LLM เช่น โมเดล Gemini 1.5 Flash
- คุณใช้ Gemini 1.5 Flash เพื่อสรุปภาพยนตร์สำหรับโปสเตอร์แต่ละรายการได้โดยเรียกใช้การค้นหาด้านล่าง
SELECT
uri,
title,
year,
prompt,
ml_generate_text_llm_result
FROM
ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_1_5_flash`,
(
SELECT
CONCAT('Provide a short summary of movie titled ',title, ' from the year ',year,'.') AS prompt,
uri,
title,
year
FROM
`gemini_demo.movie_posters_results_formatted`
LIMIT
20 ),
STRUCT(0.2 AS temperature,
TRUE AS FLATTEN_JSON_OUTPUT));
สังเกตml_generate_text_llm_resultฟิลด์ของผลการค้นหา ซึ่งมีข้อมูลสรุปสั้นๆ ของภาพยนตร์
9. สร้างการฝังข้อความโดยใช้โมเดลระยะไกล
ตอนนี้คุณสามารถรวม Structured Data ที่สร้างขึ้นกับ Structured Data อื่นๆ ในคลังได้แล้ว ชุดข้อมูลสาธารณะ IMDB ที่มีใน BigQuery มีข้อมูลมากมายเกี่ยวกับภาพยนตร์ ซึ่งรวมถึงการให้คะแนนโดยผู้ชมและรีวิวตัวอย่างแบบอิสระของผู้ใช้ด้วย ข้อมูลนี้จะช่วยให้คุณวิเคราะห์โปสเตอร์ภาพยนตร์ได้ลึกซึ้งยิ่งขึ้น และเข้าใจว่าผู้คนมองภาพยนตร์เหล่านี้อย่างไร
คุณต้องมีคีย์จึงจะรวมข้อมูลได้ ในกรณีนี้ ชื่อภาพยนตร์ที่โมเดล Gemini สร้างขึ้นอาจไม่ตรงกับชื่อในชุดข้อมูล IMDB อย่างสมบูรณ์
ในงานนี้ คุณจะสร้าง Text Embedding ของชื่อภาพยนตร์และปีจากทั้ง 2 ชุดข้อมูล จากนั้นใช้ระยะห่างระหว่าง Embedding เหล่านี้เพื่อรวมชื่อภาพยนตร์ที่ใกล้เคียงที่สุดจาก IMDB กับชื่อโปสเตอร์ภาพยนตร์จากชุดข้อมูลที่สร้างขึ้นใหม่
สร้างโมเดลระยะไกล
หากต้องการสร้างการฝังข้อความ คุณจะต้องสร้างโมเดลระยะไกลใหม่ที่ชี้ไปยังปลายทาง text-multilingual-embedding-002
- สร้างและเรียกใช้การค้นหาใหม่ด้วยคำสั่ง SQL ต่อไปนี้
CREATE OR REPLACE MODEL `gemini_demo.text_embedding`
REMOTE WITH CONNECTION `us.gemini_conn`
OPTIONS (endpoint = 'text-multilingual-embedding-002')
ผลลัพธ์คือระบบจะสร้างโมเดล text_embedding และปรากฏในโปรแกรมสำรวจใต้ชุดข้อมูล gemini_demo
สร้างการฝังข้อความสำหรับชื่อและปีที่เชื่อมโยงกับโปสเตอร์
ตอนนี้คุณจะใช้โมเดลระยะไกลนี้กับฟังก์ชัน ML.GENERATE_EMBEDDING เพื่อสร้างการฝังสำหรับชื่อและปีของโปสเตอร์ภาพยนตร์แต่ละเรื่อง
- สร้างและเรียกใช้การค้นหาใหม่ด้วยคำสั่ง SQL ต่อไปนี้
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results_embeddings` AS (
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
MODEL `gemini_demo.text_embedding`,
(
SELECT
CONCAT('The movie titled ', title, ' from the year ', year,'.') AS content,
title,
year,
uri
FROM
`gemini_demo.movie_posters_results_formatted` ),
STRUCT(TRUE AS flatten_json_output)));
ผลลัพธ์คือระบบจะสร้างmovie_poster_results_embeddingsตารางที่มีการฝังสำหรับเนื้อหาข้อความที่ต่อกันสำหรับแต่ละแถวของตาราง gemini_demo.movie_posters_results_formatted
- คุณดูผลลัพธ์ของการค้นหาได้โดยใช้การค้นหาใหม่ด้านล่าง
SELECT * FROM `gemini_demo.movie_posters_results_embeddings`
ในส่วนนี้ คุณจะเห็นการฝัง (เวกเตอร์ที่แสดงด้วยตัวเลข) สำหรับภาพยนตร์แต่ละเรื่องที่โมเดลสร้างขึ้น
สร้างการฝังข้อความสําหรับชุดข้อมูล IMDB บางส่วน
คุณจะสร้างมุมมองใหม่ของข้อมูลจากชุดข้อมูล IMDB สาธารณะซึ่งมีเฉพาะภาพยนตร์ที่เผยแพร่ก่อนปี 1935 (ช่วงเวลาที่ทราบของภาพยนตร์จากรูปภาพโปสเตอร์)
- สร้างและเรียกใช้การค้นหาใหม่ด้วยคำสั่ง SQL ต่อไปนี้
CREATE OR REPLACE VIEW
`gemini_demo.imdb_movies` AS (
WITH
reviews AS (
SELECT
reviews.movie_id AS movie_id,
title.primary_title AS title,
title.start_year AS year,
reviews.review AS review
FROM
`bigquery-public-data.imdb.reviews` reviews
LEFT JOIN
`bigquery-public-data.imdb.title_basics` title
ON
reviews.movie_id = title.tconst)
SELECT
DISTINCT(movie_id),
title,
year
FROM
reviews
WHERE
year < 1935)
ผลลัพธ์คือมุมมองใหม่ที่มีรายการรหัสภาพยนตร์ ชื่อ และปีที่เผยแพร่ที่ไม่ซ้ำกันจากตาราง bigquery-public-data.imdb.reviews สำหรับภาพยนตร์ทั้งหมดในชุดข้อมูลที่เผยแพร่ก่อนปี 1935
- ตอนนี้คุณจะสร้างการฝังสำหรับภาพยนตร์บางส่วนจาก IMDB โดยใช้วิธีการคล้ายกับในส่วนก่อนหน้า สร้างและเรียกใช้การค้นหาใหม่ด้วยคำสั่ง SQL ต่อไปนี้
CREATE OR REPLACE TABLE
`gemini_demo.imdb_movies_embeddings` AS (
SELECT
*
FROM
ML.GENERATE_EMBEDDING( MODEL `gemini_demo.text_embedding`,
(
SELECT
CONCAT('The movie titled ', title, ' from the year ', year,'.') AS content,
title,
year,
movie_id
FROM
`gemini_demo.imdb_movies` ),
STRUCT(TRUE AS flatten_json_output) )
WHERE
ml_generate_embedding_status = '' );
ผลลัพธ์ของการค้นหาคือตารางที่มีการฝังสำหรับเนื้อหาข้อความของgemini_demo.imdb_moviesตาราง
จับคู่รูปภาพโปสเตอร์ภาพยนตร์กับ IMDB movie_id โดยใช้ BigQuery VECTOR_SEARCH
ตอนนี้คุณสามารถรวม 2 ตารางเข้าด้วยกันโดยใช้ฟังก์ชัน VECTOR_SEARCH
- สร้างและเรียกใช้การค้นหาใหม่ด้วยคำสั่ง SQL ต่อไปนี้
SELECT
query.uri AS poster_uri,
query.title AS poster_title,
query.year AS poster_year,
base.title AS imdb_title,
base.year AS imdb_year,
base.movie_id AS imdb_movie_id,
distance
FROM
VECTOR_SEARCH( TABLE `gemini_demo.imdb_movies_embeddings`,
'ml_generate_embedding_result',
TABLE `gemini_demo.movie_posters_results_embeddings`,
'ml_generate_embedding_result',
top_k => 1,
distance_type => 'COSINE');
คําค้นหาใช้ฟังก์ชัน VECTOR_SEARCH เพื่อค้นหาเพื่อนบ้านที่ใกล้ที่สุดในตาราง gemini_demo.imdb_movies_embeddings สําหรับแต่ละแถวในตาราง gemini_demo.movie_posters_results_embeddings ระบบจะค้นหาเพื่อนบ้านที่ใกล้ที่สุดโดยใช้เมตริกระยะทางโคไซน์ ซึ่งจะกำหนดว่าการฝัง 2 รายการมีความคล้ายกันมากน้อยเพียงใด
การค้นหานี้ใช้เพื่อค้นหาภาพยนตร์ที่คล้ายกันมากที่สุดในชุดข้อมูล IMDB สำหรับภาพยนตร์แต่ละเรื่องที่ Gemini 1.5 Flash ระบุในโปสเตอร์ภาพยนตร์ ตัวอย่างเช่น คุณสามารถใช้การค้นหานี้เพื่อค้นหาภาพยนตร์ที่ตรงกันมากที่สุดสำหรับภาพยนตร์ "Au Secours!" ในชุดข้อมูลสาธารณะของ IMDB ซึ่งอ้างอิงถึงภาพยนตร์เรื่องนี้ด้วยชื่อภาษาอังกฤษว่า "Help!"
- สร้างและเรียกใช้การค้นหาใหม่เพื่อรวมข้อมูลเพิ่มเติมบางอย่างเกี่ยวกับการจัดประเภทภาพยนตร์ที่ระบุไว้ในชุดข้อมูลสาธารณะของ IMDB โดยทำดังนี้
SELECT
query.uri AS poster_uri,
query.title AS poster_title,
query.year AS poster_year,
base.title AS imdb_title,
base.year AS imdb_year,
base.movie_id AS imdb_movie_id,
distance,
imdb.average_rating,
imdb.num_votes
FROM
VECTOR_SEARCH( TABLE `gemini_demo.imdb_movies_embeddings`,
'ml_generate_embedding_result',
TABLE `gemini_demo.movie_posters_results_embeddings`,
'ml_generate_embedding_result',
top_k => 1,
distance_type => 'COSINE') DATA
LEFT JOIN
`bigquery-public-data.imdb.title_ratings` imdb
ON
base.movie_id = imdb.tconst
ORDER BY
imdb.average_rating DESC
การค้นหานี้คล้ายกับการค้นหาก่อนหน้า โดยยังคงใช้การแสดงตัวเลขพิเศษที่เรียกว่าการฝังเวกเตอร์เพื่อค้นหาภาพยนตร์ที่คล้ายกับโปสเตอร์ภาพยนตร์ที่กำหนด อย่างไรก็ตาม ยังรวมคะแนนเฉลี่ยและจำนวนโหวตของภาพยนตร์เพื่อนบ้านที่ใกล้ที่สุดแต่ละเรื่องจากตารางแยกต่างหากจากชุดข้อมูลสาธารณะของ IMDB ด้วย
10. ขอแสดงความยินดี
ขอแสดงความยินดีที่ทำ Codelab เสร็จสมบูรณ์ คุณสร้างตารางออบเจ็กต์สำหรับรูปภาพโปสเตอร์ใน BigQuery สร้างโมเดล Gemini ระยะไกล ใช้โมเดลเพื่อแจ้งให้โมเดล Gemini วิเคราะห์รูปภาพและสรุปภาพยนตร์ สร้างการฝังข้อความสำหรับชื่อภาพยนตร์ และใช้การฝังเหล่านั้นเพื่อจับคู่รูปภาพโปสเตอร์ภาพยนตร์กับชื่อภาพยนตร์ที่เกี่ยวข้องในชุดข้อมูล IMDB ได้สำเร็จ
สิ่งที่เราได้พูดถึง
- วิธีกำหนดค่าสภาพแวดล้อมและบัญชีเพื่อใช้ API
- วิธีสร้างการเชื่อมต่อทรัพยากรระบบคลาวด์ใน BigQuery
- วิธีสร้างชุดข้อมูลและตารางออบเจ็กต์ใน BigQuery สำหรับรูปภาพโปสเตอร์ภาพยนตร์
- วิธีสร้างโมเดลระยะไกลของ Gemini ใน BigQuery
- วิธีพรอมต์โมเดล Gemini เพื่อให้สรุปภาพยนตร์สำหรับโปสเตอร์แต่ละรายการ
- วิธีสร้างการฝังข้อความสำหรับภาพยนตร์ที่แสดงในโปสเตอร์แต่ละรายการ
- วิธีใช้ BigQuery
VECTOR_SEARCHเพื่อจับคู่รูปภาพโปสเตอร์ภาพยนตร์กับภาพยนตร์ที่เกี่ยวข้องอย่างใกล้ชิดในชุดข้อมูล
ขั้นตอนถัดไป / ดูข้อมูลเพิ่มเติม