
1. מבוא
בשיעור Lab הזה תלמדו איך להשתמש ב-למידת מכונה של BigQuery (BQML) כדי לבצע היקש באמצעות מודלים מרוחקים (מודלים של Gemini) ולנתח תמונות של פוסטרים של סרטים, וליצור סיכומים של הסרטים על סמך הפוסטרים ישירות במחסן הנתונים של BigQuery.

בתמונה שלמעלה: דוגמה לתמונות של פוסטרים של סרטים שתנתחו.
BigQuery היא פלטפורמה מנוהלת לניתוח נתונים, שתואמת ל-AI ויכולה לעזור לכם להפיק כמה שיותר תועלת מהנתונים שלכם. מילת המפתח שמתארת אותה היא ריבוי: ריבוי מנועים, ריבוי פורמטים ואפילו ריבוי עננים. אחת התכונות העיקריות שלו היא BigQuery Machine Learning (למידת מכונה ב-BigQuery) להסקת מסקנות, שמאפשרת ליצור ולהפעיל מודלים של למידת מכונה (ML) באמצעות שאילתות GoogleSQL.
Gemini היא משפחה של מודלים של AI גנרטיבי שפותחו על ידי Google ומיועדים לתרחישי שימוש מולטימודאליים.
הרצת מודלים של למידת מכונה באמצעות שאילתות GoogleSQL
בדרך כלל, כדי לבצע למידת מכונה (ML) או בינה מלאכותית (AI) במערכי נתונים גדולים, צריך ידע רב בתכנות ובמסגרות ML. הדבר מגביל את פיתוח הפתרונות לקבוצה קטנה של מומחים בכל חברה. בעזרת BigQuery Machine Learning for inference, משתמשי SQL יכולים להשתמש בכלים הקיימים ובמיומנויות של SQL שהם רכשו כדי לבנות מודלים, וליצור תוצאות מ-LLM ומממשקי Cloud AI API.
דרישות מוקדמות
- הבנה בסיסית של מסוף Google Cloud
- ניסיון ב-BigQuery הוא יתרון
מה תלמדו
- איך מגדירים את הסביבה והחשבון לשימוש בממשקי API
- איך יוצרים קישור למשאבים ב-Cloud ב-BigQuery
- איך יוצרים מערך נתונים וטבלת אובייקטים ב-BigQuery לתמונות של פוסטרים של סרטים
- איך יוצרים את המודלים המרוחקים של Gemini ב-BigQuery
- איך מבקשים ממודל Gemini לספק סיכומי סרטים לכל פוסטר
- איך ליצור הטמעות טקסט לסרט שמיוצג בכל פוסטר
- איך משתמשים ב-BigQuery
VECTOR_SEARCHכדי להתאים בין תמונות של פוסטרים של סרטים לבין סרטים קרובים במערך הנתונים
מה תצטרכו
- חשבון Google Cloud ופרויקט Google Cloud עם חיוב מופעל
- דפדפן אינטרנט כמו Chrome
2. הגדרה ודרישות
הגדרת סביבה בקצב אישי
- נכנסים ל-מסוף Google Cloud ויוצרים פרויקט חדש או משתמשים בפרויקט קיים. אם עדיין אין לכם חשבון Gmail או Google Workspace, אתם צריכים ליצור חשבון.



- שם הפרויקט הוא השם המוצג של הפרויקט הזה למשתתפים. זו מחרוזת תווים שלא נמצאת בשימוש ב-Google APIs. תמיד אפשר לעדכן את המיקום.
- מזהה הפרויקט הוא ייחודי לכל הפרויקטים ב-Google Cloud ואי אפשר לשנות אותו אחרי שהוא מוגדר. מסוף Cloud יוצר באופן אוטומטי מחרוזת ייחודית, ובדרך כלל לא צריך לדעת מה היא. ברוב ה-Codelabs, תצטרכו להפנות למזהה הפרויקט (בדרך כלל מסומן כ-
PROJECT_ID). אם אתם לא אוהבים את המזהה שנוצר, אתם יכולים ליצור מזהה אקראי אחר. אפשר גם לנסות שם משתמש משלכם ולבדוק אם הוא זמין. אי אפשר לשנות את ההגדרה הזו אחרי השלב הזה, והיא תישאר לאורך הפרויקט. - לידיעתכם, יש ערך שלישי, מספר פרויקט, שחלק מממשקי ה-API משתמשים בו. במאמרי העזרה מפורט מידע נוסף על שלושת הערכים האלה.
- בשלב הבא, תצטרכו להפעיל את החיוב במסוף Cloud כדי להשתמש במשאבי Cloud או בממשקי API של Cloud. השלמת ה-codelab הזה לא תעלה לכם הרבה, אם בכלל. כדי להשבית את המשאבים ולמנוע חיובים נוספים אחרי שתסיימו את המדריך הזה, תוכלו למחוק את המשאבים שיצרתם או למחוק את הפרויקט. משתמשים חדשים ב-Google Cloud זכאים לתוכנית תקופת ניסיון בחינם בשווי 300$.
מפעילים את Cloud Shell
אפשר להפעיל את Google Cloud מרחוק מהמחשב הנייד, אבל ב-codelab הזה תשתמשו ב-Google Cloud Shell, סביבת שורת פקודה שפועלת בענן.
ב-מסוף Google Cloud, לוחצים על סמל Cloud Shell בסרגל הכלים שבפינה הימנית העליונה:

יחלפו כמה רגעים עד שההקצאה והחיבור לסביבת העבודה יושלמו. בסיום התהליך, אמור להופיע משהו כזה:

המכונה הווירטואלית הזו כוללת את כל הכלים שדרושים למפתחים. יש בה ספריית בית בנפח מתמיד של 5GB והיא פועלת ב-Google Cloud, מה שמשפר מאוד את הביצועים והאימות ברשת. אפשר לבצע את כל העבודה ב-codelab הזה בדפדפן. לא צריך להתקין שום דבר.
3. לפני שמתחילים
יש כמה שלבי הגדרה שצריך לבצע כדי לעבוד עם מודלים של Gemini ב-BigQuery, כולל הפעלת ממשקי API, יצירת קישור למשאבים ב-Cloud והענקת הרשאות מסוימות לחשבון השירות של הקישור למשאבים ב-Cloud. השלבים האלה מתבצעים פעם אחת לכל פרויקט, והם מוסברים בקטעים הבאים.
הפעלת ממשקי API
ב-Cloud Shell, מוודאים שמזהה הפרויקט מוגדר:
gcloud config set project [YOUR-PROJECT-ID]
מגדירים את משתנה הסביבה PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
מגדירים את אזור ברירת המחדל שבו ישמשו מודלים של Vertex AI. מידע נוסף על המיקומים שבהם Vertex AI זמין בדוגמה אנחנו משתמשים באזור us-central1.
gcloud config set compute/region us-central1
מגדירים את משתנה הסביבה REGION:
REGION=$(gcloud config get-value compute/region)
מפעילים את כל השירותים הנדרשים:
gcloud services enable bigqueryconnection.googleapis.com \
aiplatform.googleapis.com
הפלט הצפוי אחרי הרצת כל הפקודות שלמעלה:
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable bigqueryconnection.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. יצירת קישור למשאבים ב-Cloud
במשימה הזו תיצרו קישור למשאבים ב-Cloud, שיאפשר ל-BigQuery לגשת לקובצי תמונות ב-Cloud Storage ולבצע קריאות ל-Vertex AI.
- במסוף Google Cloud, בתפריט הניווט (
 ), לוחצים על BigQuery.
), לוחצים על BigQuery.

- כדי ליצור קישור, לוחצים על + ADD (הוספה) ואז על Connections to external data sources (קישורים למקורות נתונים חיצוניים).

- ברשימה 'סוג החיבור', בוחרים באפשרות מודלים מרוחקים, פונקציות מרוחקות ו-BigLake (Cloud Resource) של Vertex AI.
- בשדה Connection ID (מזהה החיבור), מזינים gemini_conn לחיבור.
- בקטע Location type, בוחרים באפשרות במספר אזורים ואז בתפריט הנפתח בוחרים באפשרות US במספר אזורים.
- משתמשים בהגדרות ברירת המחדל בשאר ההגדרות.
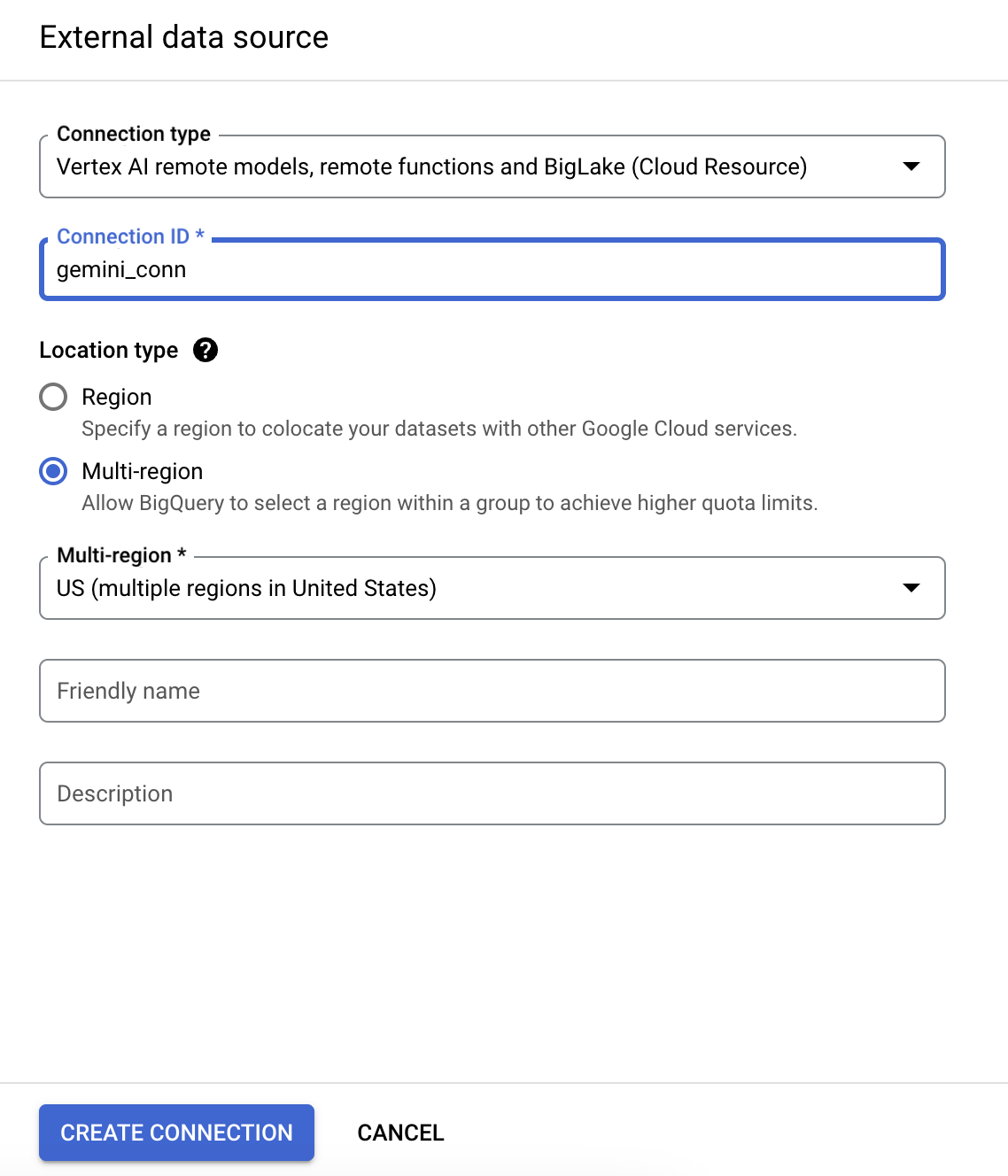
- לוחצים על יצירת קישור.
- לוחצים על מעבר לחיבור.
- בחלונית Connection info, מעתיקים את מזהה חשבון השירות לקובץ טקסט כדי להשתמש בו במשימה הבאה. בנוסף, החיבור יתווסף לקטע External Connections (חיבורים חיצוניים) בפרויקט שלכם ב-BigQuery Explorer.
5. מתן הרשאות IAM לחשבון השירות של החיבור
במשימה הזו, אתם מעניקים לחשבון השירות של חיבור משאבי הענן הרשאות IAM באמצעות תפקיד, כדי לאפשר לו גישה לשירותי Vertex AI.
- במסוף Google Cloud, בתפריט הניווט, לוחצים על IAM & Admin.
- לוחצים על הענקת גישה.
- בשדה New principals, מזינים את מזהה חשבון השירות שהעתקתם קודם.
- בשדה 'בחירת תפקיד', מזינים Vertex AI ובוחרים בתפקיד Vertex AI User.
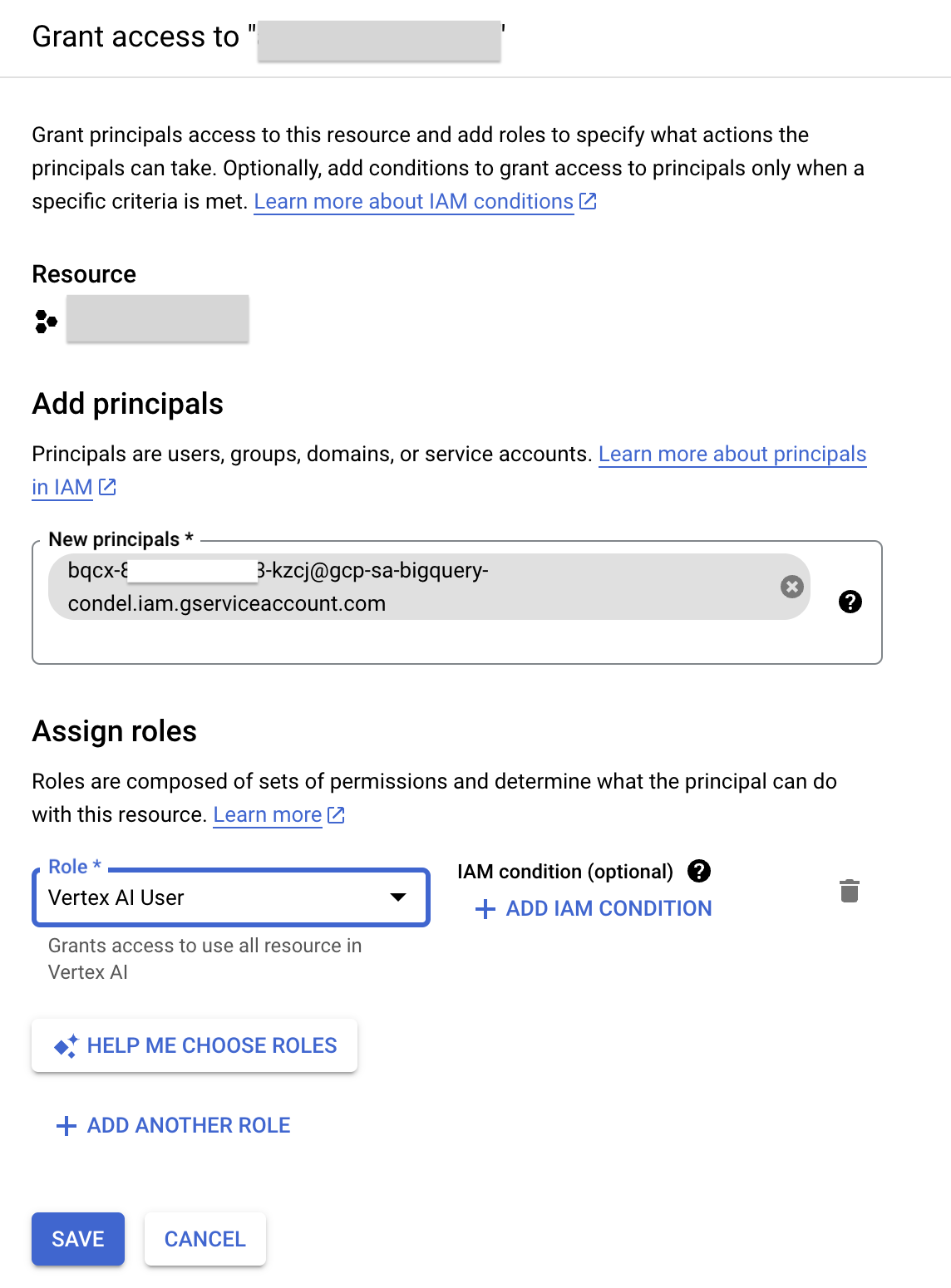
- לוחצים על שמירה. התוצאה היא שמזהה חשבון השירות כולל עכשיו את התפקיד Vertex AI User.
6. יצירת מערך הנתונים וטבלת האובייקטים ב-BigQuery לתמונות של פוסטרים של סרטים
במשימה הזו תיצרו מערך נתונים לפרויקט וטבלת אובייקטים בתוכו כדי לאחסן את תמונות הפוסטר.
מערך הנתונים של תמונות פוסטרים של סרטים שבו נעשה שימוש במדריך הזה מאוחסן בקטגוריה ציבורית של Cloud Storage: gs://cloud-samples-data/vertex-ai/dataset-management/datasets/classic-movie-posters
יצירת מערך נתונים
תצטרכו ליצור מערך נתונים כדי לאחסן אובייקטים של מסד נתונים, כולל טבלאות ומודלים, שמשמשים במדריך הזה.
- במסוף Google Cloud, לוחצים על תפריט הניווט ( ) ואז על BigQuery.
- בחלונית Explorer, לצד שם הפרויקט, בוחרים באפשרות View actions (
 ) ואז באפשרות Create dataset.
) ואז באפשרות Create dataset. - בחלונית Create dataset, מזינים את הפרטים הבאים:
- מזהה מערך הנתונים: gemini_demo
- סוג המיקום: בוחרים באפשרות במספר אזורים
- במספר אזורים: בוחרים באפשרות ארה"ב
- משאירים את ערכי ברירת המחדל בשאר השדות.
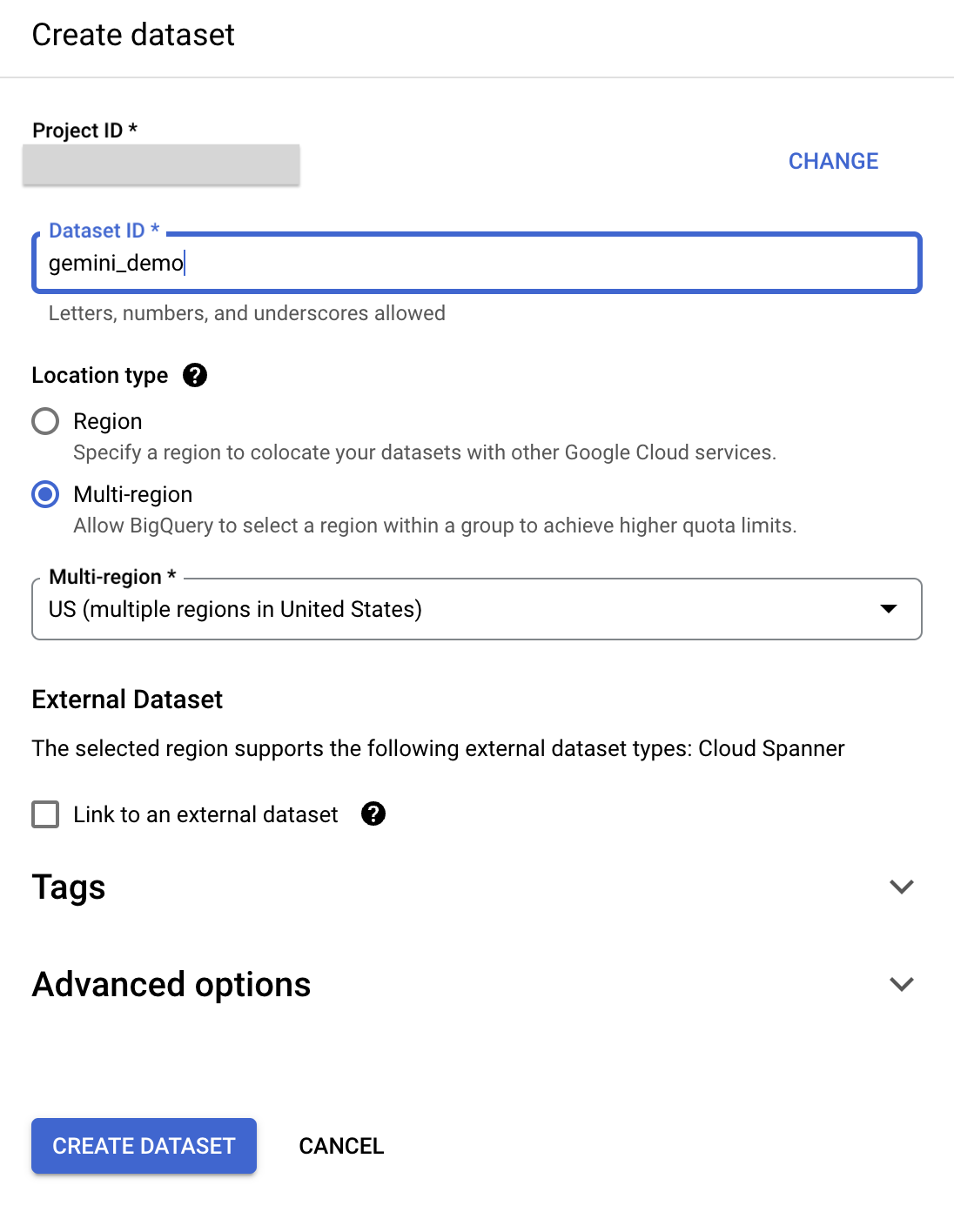
- לוחצים על יצירת קבוצת נתונים.
מערך הנתונים gemini_demo נוצר ומופיע מתחת לפרויקט בכלי BigQuery Explorer.
יצירת טבלת האובייקטים
ב-BigQuery יש לא רק נתונים מובנים, אלא גם גישה לנתונים לא מובנים (כמו תמונות הפוסטרים) דרך טבלאות אובייקטים.
יוצרים טבלת אובייקטים על ידי הפניה לקטגוריה של Cloud Storage, ובטבלת האובייקטים שמתקבלת יש שורה לכל אובייקט מהקטגוריה עם נתיב האחסון והמטא-נתונים שלו.
כדי ליצור את טבלת האובייקטים, תשתמשו בשאילתת SQL.
- לוחצים על + כדי ליצור שאילתת SQL חדשה.
- בעורך השאילתות, מדביקים את השאילתה שלמטה.
CREATE OR REPLACE EXTERNAL TABLE
`gemini_demo.movie_posters`
WITH CONNECTION `us.gemini_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://cloud-samples-data/vertex-ai/dataset-management/datasets/classic-movie-posters/*']
);
- מריצים את השאילתה. התוצאה היא טבלת אובייקטים
movie_postersשנוספת למערך הנתוניםgemini_demoונטענת עםURI(המיקום ב-Cloud Storage) של כל תמונה של פוסטר לסרט. - בכלי Explorer, לוחצים על
movie_postersובודקים את הסכימה והפרטים. אפשר להריץ שאילתות על הטבלה כדי לבדוק רשומות ספציפיות.
7. יצירת מודל Gemini מרוחק ב-BigQuery
אחרי שיוצרים את טבלת האובייקטים, אפשר להתחיל לעבוד איתה. במשימה הזו תיצרו מודל מרוחק של Gemini 1.5 Flash כדי להפוך אותו לזמין ב-BigQuery.
יצירת מודל Gemini 1.5 Flash מרוחק
- לוחצים על + כדי ליצור שאילתת SQL חדשה.
- בעורך השאילתות, מדביקים את השאילתה הבאה ומפעילים פתרונות חכמים.
CREATE OR REPLACE MODEL `gemini_demo.gemini_1_5_flash`
REMOTE WITH CONNECTION `us.gemini_conn`
OPTIONS (endpoint = 'gemini-1.5-flash')
התוצאה היא יצירת המודל gemini_1_5_flash, והוא יתווסף למערך הנתונים gemini_demo בקטע 'מודלים'.
- ב-Explorer, לוחצים על מודל
gemini_1_5_flashובודקים את הפרטים.
8. הנחיית מודל Gemini לספק סיכומי סרטים לכל פוסטר
במשימה הזו תשתמשו במודל Gemini המרוחק שיצרתם כדי לנתח את תמונות הפוסטרים של הסרטים וליצור סיכומים לכל סרט.
אפשר לשלוח בקשות למודל באמצעות הפונקציה ML.GENERATE_TEXT, עם הפניה למודל בפרמטרים.
ניתוח התמונות באמצעות מודל Gemini 1.5 Flash
- יוצרים ומריצים שאילתה חדשה עם הצהרת ה-SQL הבאה:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results` AS (
SELECT
uri,
ml_generate_text_llm_result
FROM
ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_1_5_flash`,
TABLE `gemini_demo.movie_posters`,
STRUCT( 0.2 AS temperature,
'For the movie represented by this poster, what is the movie title and year of release? Answer in JSON format with two keys: title, year. title should be string, year should be integer. Do not use JSON decorators.' AS PROMPT,
TRUE AS FLATTEN_JSON_OUTPUT)));
כשהשאילתה מופעלת, BigQuery מציג הנחיה למודל Gemini לכל שורה בטבלת האובייקטים, ומשלב את התמונה עם ההנחיה הסטטית שצוינה. התוצאה היא יצירת הטבלה movie_posters_results.
- עכשיו נראה את התוצאות. יוצרים ומריצים שאילתה חדשה עם הצהרת ה-SQL הבאה:
SELECT * FROM `gemini_demo.movie_posters_results`
התוצאה היא שורות לכל פוסטר של סרט עם URI (המיקום ב-Cloud Storage של תמונת הפוסטר של הסרט) ותוצאת JSON שכוללת את שם הסרט ואת שנת היציאה שלו, מתוך מודל Gemini 1.5 Flash.
אפשר לקבל את התוצאות האלה בצורה קריאה יותר על ידי שימוש בשאילתה הבאה. השאילתה הזו משתמשת ב-SQL כדי לשלוף את שם הסרט ושנת היציאה שלו מהתשובות האלה לעמודות חדשות.
- יוצרים ומריצים שאילתה חדשה עם הצהרת ה-SQL הבאה:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results_formatted` AS (
SELECT
uri,
JSON_VALUE(ml_generate_text_llm_result, "$.title") AS title,
JSON_VALUE(ml_generate_text_llm_result, "$.year") AS year
FROM
`gemini_demo.movie_posters_results` results )
התוצאה היא יצירת הטבלה movie_posters_result_formatted.
- כדי לראות את השורות שנוצרו, אפשר להריץ את השאילתה שבהמשך.
SELECT * FROM `gemini_demo.movie_posters_results_formatted`
שימו לב שהתוצאות בעמודה URI נשארות זהות, אבל ה-JSON מומר עכשיו לעמודות title ו-year בכל שורה.
איך מבקשים ממודל Gemini 1.5 Flash לספק סיכומי סרטים
מה אם תרצה לקבל קצת יותר מידע על כל אחד מהסרטים האלה, למשל סיכום טקסט של כל אחד מהסרטים? מקרה השימוש הזה של יצירת תוכן מתאים במיוחד למודל LLM כמו Gemini 1.5 Flash.
- אתם יכולים להשתמש ב-Gemini 1.5 Flash כדי לספק סיכומי סרטים לכל פוסטר על ידי הפעלת השאילתה הבאה:
SELECT
uri,
title,
year,
prompt,
ml_generate_text_llm_result
FROM
ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_1_5_flash`,
(
SELECT
CONCAT('Provide a short summary of movie titled ',title, ' from the year ',year,'.') AS prompt,
uri,
title,
year
FROM
`gemini_demo.movie_posters_results_formatted`
LIMIT
20 ),
STRUCT(0.2 AS temperature,
TRUE AS FLATTEN_JSON_OUTPUT));
שימו לב לשדה ml_generate_text_llm_result בתוצאות, שכולל סיכום קצר של הסרט.
9. יצירת הטמעות טקסט באמצעות מודל מרוחק
עכשיו אפשר לצרף את הנתונים המובְנים שיצרתם לנתונים מובְנים אחרים במחסן הנתונים. מערך הנתונים הציבורי של IMDB שזמין ב-BigQuery מכיל כמות גדולה של מידע על סרטים, כולל דירוגים של צופים וכמה דוגמאות של ביקורות משתמשים בפורמט חופשי. הנתונים האלה יכולים לעזור לכם להעמיק את הניתוח של פוסטרים של סרטים ולהבין איך הסרטים האלה נתפסו.
כדי לצרף נתונים, תצטרכו מפתח. במקרה כזה, יכול להיות ששמות הסרטים שנוצרו על ידי מודל Gemini לא יהיו זהים לשמות במערך הנתונים של IMDB.
במשימה הזו תיצרו הטמעות טקסט של שמות הסרטים ושנות היציאה שלהם משני מערכי הנתונים, ואז תשתמשו במרחק בין ההטמעות האלה כדי לאחד את שם הסרט הכי קרוב ב-IMDB עם שמות הסרטים בפוסטרים ממערך הנתונים החדש שיצרתם.
יצירת המודל המרוחק
כדי ליצור את הטמעות הטקסט, צריך ליצור מודל חדש מרוחק שמפנה לנקודת הקצה text-multilingual-embedding-002.
- יוצרים ומריצים שאילתה חדשה עם הצהרת ה-SQL הבאה:
CREATE OR REPLACE MODEL `gemini_demo.text_embedding`
REMOTE WITH CONNECTION `us.gemini_conn`
OPTIONS (endpoint = 'text-multilingual-embedding-002')
התוצאה היא שמודל text_embedding נוצר ומופיע בכלי המחקר מתחת למערך הנתונים gemini_demo.
יצירת הטמעות טקסט לכותרת ולשנה שמשויכות לפוסטרים
מעכשיו תוכלו להשתמש במודל המרוחק הזה עם הפונקציה ML.GENERATE_EMBEDDING כדי ליצור הטמעה לכל כותרת ושנה של פוסטר סרט.
- יוצרים ומריצים שאילתה חדשה עם הצהרת ה-SQL הבאה:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results_embeddings` AS (
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
MODEL `gemini_demo.text_embedding`,
(
SELECT
CONCAT('The movie titled ', title, ' from the year ', year,'.') AS content,
title,
year,
uri
FROM
`gemini_demo.movie_posters_results_formatted` ),
STRUCT(TRUE AS flatten_json_output)));
התוצאה היא יצירת הטבלה movie_poster_results_embeddings שמכילה את ההטמעות של תוכן הטקסט ששורשר לכל שורה בטבלה gemini_demo.movie_posters_results_formatted.
- אפשר לראות את תוצאות השאילתה באמצעות השאילתה החדשה שבהמשך:
SELECT * FROM `gemini_demo.movie_posters_results_embeddings`
כאן אפשר לראות את ההטמעות (וקטורים שמיוצגים על ידי מספרים) של כל סרט שנוצר על ידי המודל.
יצירת הטמעות של טקסט עבור קבוצת משנה של מערך הנתונים מ-IMDB
תצרו תצוגה חדשה של נתונים ממערך נתונים ציבורי של IMDB, שמכיל רק את הסרטים שהופצו לפני 1935 (פרק הזמן הידוע של הסרטים מתמונות הפוסטרים).
- יוצרים ומריצים שאילתה חדשה עם הצהרת ה-SQL הבאה:
CREATE OR REPLACE VIEW
`gemini_demo.imdb_movies` AS (
WITH
reviews AS (
SELECT
reviews.movie_id AS movie_id,
title.primary_title AS title,
title.start_year AS year,
reviews.review AS review
FROM
`bigquery-public-data.imdb.reviews` reviews
LEFT JOIN
`bigquery-public-data.imdb.title_basics` title
ON
reviews.movie_id = title.tconst)
SELECT
DISTINCT(movie_id),
title,
year
FROM
reviews
WHERE
year < 1935)
התוצאה היא תצוגה חדשה שמכילה רשימה של מזהי סרטים, שמות ושנת יציאה ייחודיים מתוך הטבלה bigquery-public-data.imdb.reviews לכל הסרטים במערך הנתונים שיצאו לפני 1935.
- עכשיו תיצרו הטמעות עבור קבוצת המשנה של הסרטים מ-IMDB בתהליך דומה לזה שמתואר בקטע הקודם. יוצרים ומריצים שאילתה חדשה עם הצהרת ה-SQL הבאה:
CREATE OR REPLACE TABLE
`gemini_demo.imdb_movies_embeddings` AS (
SELECT
*
FROM
ML.GENERATE_EMBEDDING( MODEL `gemini_demo.text_embedding`,
(
SELECT
CONCAT('The movie titled ', title, ' from the year ', year,'.') AS content,
title,
year,
movie_id
FROM
`gemini_demo.imdb_movies` ),
STRUCT(TRUE AS flatten_json_output) )
WHERE
ml_generate_embedding_status = '' );
תוצאת השאילתה היא טבלה שמכילה את ההטמעות של תוכן הטקסט בטבלת gemini_demo.imdb_movies.
התאמה בין תמונות של פוסטרים של סרטים לבין IMDB movie_id באמצעות BigQuery VECTOR_SEARCH
עכשיו אפשר להצטרף לשתי הטבלאות באמצעות הפונקציה VECTOR_SEARCH.
- יוצרים ומריצים שאילתה חדשה עם הצהרת ה-SQL הבאה:
SELECT
query.uri AS poster_uri,
query.title AS poster_title,
query.year AS poster_year,
base.title AS imdb_title,
base.year AS imdb_year,
base.movie_id AS imdb_movie_id,
distance
FROM
VECTOR_SEARCH( TABLE `gemini_demo.imdb_movies_embeddings`,
'ml_generate_embedding_result',
TABLE `gemini_demo.movie_posters_results_embeddings`,
'ml_generate_embedding_result',
top_k => 1,
distance_type => 'COSINE');
השאילתה משתמשת בפונקציה VECTOR_SEARCH כדי למצוא את השכן הקרוב ביותר בטבלה gemini_demo.imdb_movies_embeddings לכל שורה בטבלה gemini_demo.movie_posters_results_embeddings. השכן הקרוב ביותר נמצא באמצעות מדד המרחק הקוסינוסי, שקובע עד כמה שתי הטמעות דומות.
אפשר להשתמש בשאילתה הזו כדי למצוא את הסרט הכי דומה במערך הנתונים של IMDB לכל אחד מהסרטים שזוהו על ידי Gemini 1.5 Flash בכרזות הסרטים. לדוגמה, אפשר להשתמש בשאילתה הזו כדי למצוא את ההתאמה הקרובה ביותר לסרט 'Au Secours!' במערך הנתונים הציבורי של IMDB, שמתייחס לסרט הזה לפי השם שלו באנגלית, 'Help!'.
- יוצרים ומריצים שאילתה חדשה כדי לצרף מידע נוסף על סיווגי סרטים שמופיע במערך הנתונים הציבורי של IMDB:
SELECT
query.uri AS poster_uri,
query.title AS poster_title,
query.year AS poster_year,
base.title AS imdb_title,
base.year AS imdb_year,
base.movie_id AS imdb_movie_id,
distance,
imdb.average_rating,
imdb.num_votes
FROM
VECTOR_SEARCH( TABLE `gemini_demo.imdb_movies_embeddings`,
'ml_generate_embedding_result',
TABLE `gemini_demo.movie_posters_results_embeddings`,
'ml_generate_embedding_result',
top_k => 1,
distance_type => 'COSINE') DATA
LEFT JOIN
`bigquery-public-data.imdb.title_ratings` imdb
ON
base.movie_id = imdb.tconst
ORDER BY
imdb.average_rating DESC
השאילתה הזו דומה לשאילתה הקודמת. הוא עדיין משתמש בייצוגים מספריים מיוחדים שנקראים הטמעות וקטוריות כדי למצוא סרטים דומים לפוסטר של סרט נתון. עם זאת, הוא גם מצטרף לדירוג הממוצע ולמספר ההצבעות של כל סרט שכן קרוב מטבלה נפרדת ממערך הנתונים הציבורי של IMDB.
10. מזל טוב
כל הכבוד, סיימתם את ה-Codelab. יצרתם בהצלחה טבלת אובייקטים לתמונות של פוסטרים ב-BigQuery, יצרתם מודל Gemini מרוחק, השתמשתם במודל כדי להנחות את מודל Gemini לנתח תמונות ולספק תקצירים של סרטים, יצרתם הטמעות טקסט לשמות של סרטים והשתמשתם בהטמעות האלה כדי להתאים בין תמונות של פוסטרים של סרטים לבין שם הסרט הרלוונטי במערך הנתונים של IMDB.
מה נכלל
- איך מגדירים את הסביבה והחשבון לשימוש בממשקי API
- איך יוצרים קישור למשאבים ב-Cloud ב-BigQuery
- איך יוצרים מערך נתונים וטבלת אובייקטים ב-BigQuery לתמונות של פוסטרים של סרטים
- איך יוצרים את המודלים המרוחקים של Gemini ב-BigQuery
- איך מבקשים ממודל Gemini לספק סיכומי סרטים לכל פוסטר
- איך ליצור הטמעות טקסט לסרט שמיוצג בכל פוסטר
- איך משתמשים ב-BigQuery
VECTOR_SEARCHכדי להתאים בין תמונות של פוסטרים של סרטים לבין סרטים קרובים במערך הנתונים
השלבים הבאים / מידע נוסף