
1. Introduction
Dans cet atelier, vous allez apprendre à utiliser BigQuery Machine Learning pour l'inférence avec des modèles distants ( modèles Gemini) afin d'analyser des images d'affiches de films et de générer des résumés des films en fonction des affiches directement dans votre entrepôt de données BigQuery.

Ci-dessus : exemple d'affiches de films que vous allez analyser.
BigQuery est une plate-forme d'analyse de données entièrement gérée et compatible avec l'IA, conçue pour être multimoteur, multiformat et multicloud. Elle vous aide à maximiser la valeur de vos données. BigQuery Machine Learning pour l'inférence, l'une de ses fonctionnalités essentielles, vous permet de créer et d'exécuter des modèles de machine learning (ML) à l'aide de requêtes GoogleSQL.
Gemini est une famille de modèles d'IA générative développés par Google et conçus pour les cas d'utilisation multimodaux.
Exécuter des modèles de ML à l'aide de requêtes GoogleSQL
En règle générale, l'exploitation du ML ou de l'intelligence artificielle (IA) sur des ensembles de données volumineux nécessite une programmation importante et une connaissance approfondie des frameworks de ML. Cela limite le développement de solutions à un petit groupe de spécialistes au sein de chaque entreprise. Grâce à BigQuery Machine Learning pour l'inférence, les utilisateurs de SQL peuvent mettre à profit leurs compétences et outils SQL existants pour créer des modèles et générer des résultats à partir de LLM et des API d'IA dans le cloud.
Prérequis
- Connaissances de base concernant la console Google Cloud
- Une expérience avec BigQuery est un plus
Points abordés
- Configurer votre environnement et votre compte pour utiliser les API
- Créer une connexion à une ressource cloud dans BigQuery
- Créer un ensemble de données et une table d'objets dans BigQuery pour les images d'affiches de films
- Créer les modèles distants Gemini dans BigQuery
- Comment demander au modèle Gemini de fournir un résumé du film pour chaque affiche
- Générer des embeddings textuels pour le film représenté sur chaque affiche
- Utiliser
VECTOR_SEARCHBigQuery pour mettre en correspondance les images des affiches avec des films étroitement liés dans l'ensemble de données
Prérequis
- Un compte Google Cloud et un projet Google Cloud avec la facturation activée
- Un navigateur Web tel que Chrome
2. Préparation
Configuration de l'environnement au rythme de chacun
- Connectez-vous à la console Google Cloud, puis créez un projet ou réutilisez un projet existant. Si vous n'avez pas encore de compte Gmail ou Google Workspace, vous devez en créer un.



- Le nom du projet est le nom à afficher pour les participants au projet. Il s'agit d'une chaîne de caractères non utilisée par les API Google. Vous pourrez toujours le modifier.
- L'ID du projet est unique parmi tous les projets Google Cloud et non modifiable une fois défini. La console Cloud génère automatiquement une chaîne unique (en général, vous n'y accordez d'importance particulière). Dans la plupart des ateliers de programmation, vous devrez indiquer l'ID de votre projet (généralement identifié par
PROJECT_ID). Si l'ID généré ne vous convient pas, vous pouvez en générer un autre de manière aléatoire. Vous pouvez également en spécifier un et voir s'il est disponible. Après cette étape, l'ID n'est plus modifiable et restera donc le même pour toute la durée du projet. - Pour information, il existe une troisième valeur (le numéro de projet) que certaines API utilisent. Pour en savoir plus sur ces trois valeurs, consultez la documentation.
- Vous devez ensuite activer la facturation dans la console Cloud pour utiliser les ressources/API Cloud. L'exécution de cet atelier de programmation est très peu coûteuse, voire sans frais. Pour désactiver les ressources et éviter ainsi que des frais ne vous soient facturés après ce tutoriel, vous pouvez supprimer le projet ou les ressources que vous avez créées. Les nouveaux utilisateurs de Google Cloud peuvent participer au programme d'essai sans frais pour bénéficier d'un crédit de 300 $.
Démarrer Cloud Shell
Bien que Google Cloud puisse être utilisé à distance depuis votre ordinateur portable, nous allons nous servir de Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Dans la console Google Cloud, cliquez sur l'icône Cloud Shell dans la barre d'outils supérieure :

Le provisionnement et la connexion à l'environnement prennent quelques instants seulement. Une fois l'opération terminée, le résultat devrait ressembler à ceci :

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez effectuer toutes les tâches de cet atelier de programmation dans un navigateur. Vous n'avez rien à installer.
3. Avant de commencer
Pour travailler avec les modèles Gemini dans BigQuery, vous devez effectuer quelques étapes de configuration, y compris activer les API, créer une connexion à une ressource Cloud et accorder certaines autorisations au compte de service pour la connexion à la ressource Cloud. Ces étapes ne sont à effectuer qu'une seule fois par projet. Elles seront abordées dans les prochaines sections.
Activer les API
Dans Cloud Shell, assurez-vous que l'ID de votre projet est configuré :
gcloud config set project [YOUR-PROJECT-ID]
Définissez la variable d'environnement PROJECT_ID :
PROJECT_ID=$(gcloud config get-value project)
Configurez votre région par défaut pour les modèles Vertex AI. En savoir plus sur les emplacements disponibles pour Vertex AI Dans l'exemple, nous utilisons la région us-central1.
gcloud config set compute/region us-central1
Définissez la variable d'environnement REGION :
REGION=$(gcloud config get-value compute/region)
Activez tous les services nécessaires :
gcloud services enable bigqueryconnection.googleapis.com \
aiplatform.googleapis.com
Résultat attendu après l'exécution de toutes les commandes ci-dessus :
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable bigqueryconnection.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Créer une connexion à une ressource Cloud
Dans cette tâche, vous allez créer une connexion à une ressource cloud, ce qui permettra à BigQuery d'accéder aux fichiers image dans Cloud Storage et d'effectuer des appels à Vertex AI.
- Dans la console Google Cloud, accédez au menu de navigation (
 ), puis cliquez sur BigQuery.
), puis cliquez sur BigQuery.

- Pour créer une connexion, cliquez sur + AJOUTER, puis sur Connexions à des sources de données externes.

- Dans la liste "Type de connexion", sélectionnez Modèles distants Vertex AI, fonctions à distance et BigLake (Ressource Cloud).
- Dans le champ "ID de connexion", saisissez gemini_conn.
- Pour Type d'emplacement sélectionnez Multirégional, puis États-Unis (multirégional) dans le menu déroulant.
- Utilisez les valeurs par défaut des autres paramètres.

- Cliquez sur Créer une connexion.
- Cliquez sur ACCÉDER À LA CONNEXION.
- Dans le volet "Informations de connexion", copiez l'ID du compte de service à utiliser à l'étape suivante dans un fichier texte. Vous verrez également que la connexion est ajoutée sous la section "Connexions externes" de votre projet dans l'explorateur BigQuery.
5. Accorder des autorisations IAM au compte de service de la connexion
Dans cette tâche, vous allez attribuer un rôle au compte de service de la connexion afin de lui accorder des autorisations IAM sur la ressource cloud et lui permettre d'accéder aux services Vertex AI.
- Dans la console Google Cloud, accédez au menu de navigation, puis cliquez sur IAM et administration.
- Cliquez sur Accorder l'accès.
- Dans le champ Nouveaux comptes principaux, saisissez l'ID de compte de service que vous avez copié précédemment.
- Dans le champ "Sélectionner un rôle", saisissez Vertex AI, puis choisissez le rôle Utilisateur Vertex AI.
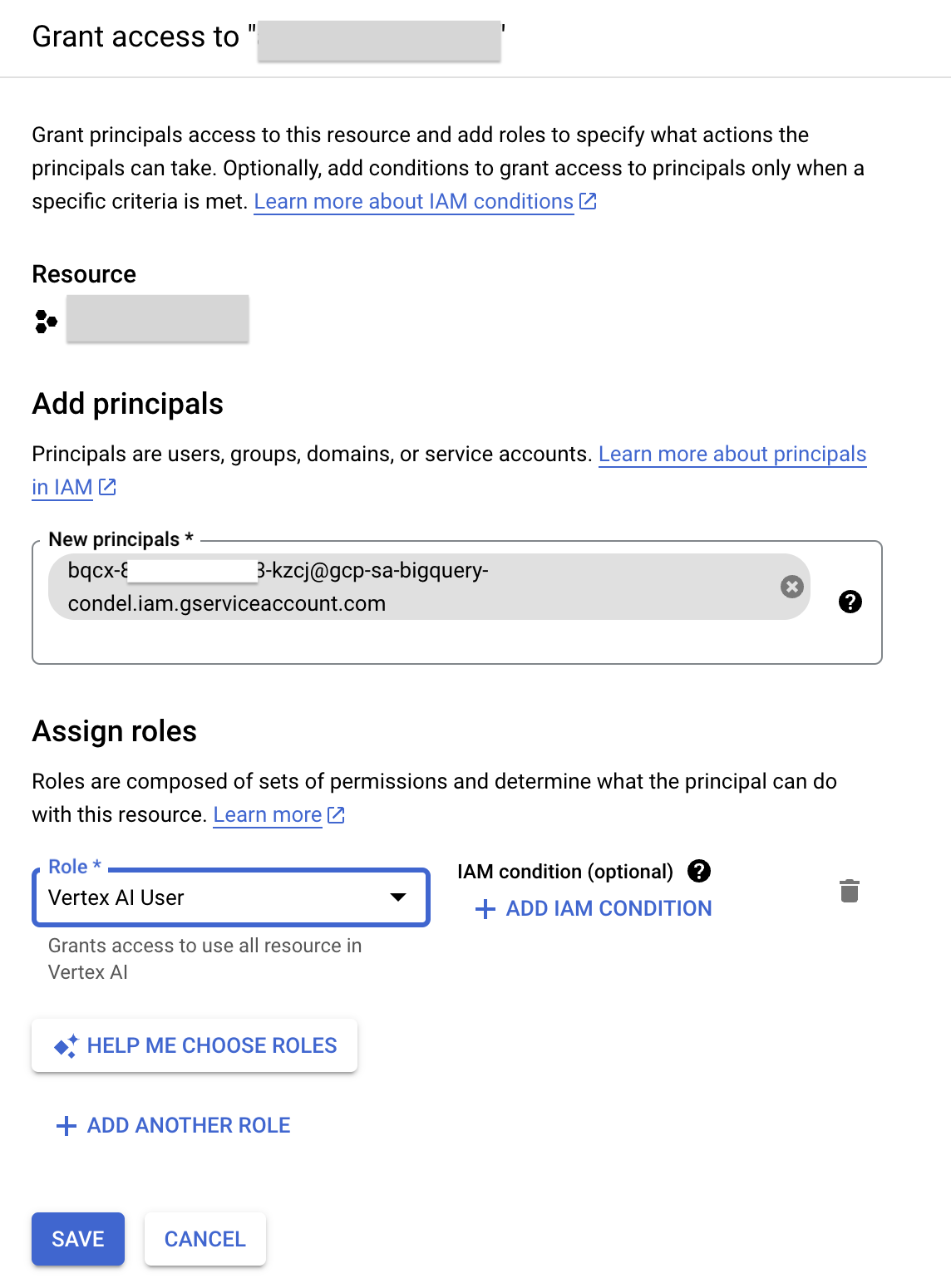
- Cliquez sur Enregistrer. L'ID du compte de service inclut désormais le rôle Utilisateur Vertex AI.
6. Créer l'ensemble de données et une table d'objets dans BigQuery pour les images d'affiches de films
Dans cette tâche, vous allez créer un ensemble de données pour le projet et une table d'objets dans laquelle stocker les images des affiches.
L'ensemble de données d'images d'affiches de films utilisé dans ce tutoriel est stocké dans un bucket Google Cloud Storage public : gs://cloud-samples-data/vertex-ai/dataset-management/datasets/classic-movie-posters.
Créer un ensemble de données
Vous allez créer un ensemble de données pour stocker les objets de base de données, y compris les tables et les modèles, utilisés dans ce tutoriel.
- Dans la console Google Cloud, ouvrez le menu de navigation ( ) et sélectionnez BigQuery.
- Dans le panneau Explorateur, à côté du nom de votre projet, sélectionnez Afficher les actions (
 ), puis Créer un ensemble de données.
), puis Créer un ensemble de données. - Dans le volet Créer un ensemble de données, saisissez les informations suivantes :
- ID de l'ensemble de données : gemini_demo
- Type d'emplacement : sélectionnez Multirégional.
- Multirégional : sélectionnez US
- Conservez les valeurs par défaut dans les autres champs.

- Cliquez sur Créer un ensemble de données.
L'ensemble de données gemini_demo est désormais créé et figure en dessous de votre projet dans l'explorateur BigQuery.
Créer la table d'objets
BigQuery contient non seulement des données structurées, mais il peut également accéder à des données non structurées (comme les images d'affiches) via des tables d'objets.
Pour créer une table d'objets, vous devez pointer vers un bucket Cloud Storage. La table d'objets obtenue comporte une ligne pour chaque objet du bucket, avec son chemin de stockage et ses métadonnées.
Pour créer la table d'objets, vous allez utiliser une requête SQL.
- Cliquez sur le signe + pour créer une requête SQL.
- Dans l'éditeur de requête, collez la requête ci-dessous.
CREATE OR REPLACE EXTERNAL TABLE
`gemini_demo.movie_posters`
WITH CONNECTION `us.gemini_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://cloud-samples-data/vertex-ai/dataset-management/datasets/classic-movie-posters/*']
);
- Exécutez la requête. Cette requête ajoute une table d'objets
movie_postersà l'ensemble de donnéesgemini_demoet charge leURI(l'emplacement Cloud Storage) de chaque image d'affiche de film dans cette table. - Dans l'explorateur, cliquez sur
movie_posters, puis examinez le schéma et les détails. Vous pouvez interroger la table pour examiner des enregistrements spécifiques.
7. Créer le modèle distant Gemini dans BigQuery
Maintenant que la table d'objets est créée, vous pouvez commencer à l'utiliser. Dans cette tâche, vous allez créer un modèle distant pour Gemini 1.5 Flash afin de le rendre disponible dans BigQuery.
Créer le modèle distant Gemini 1.5 Flash
- Cliquez sur le signe + pour créer une requête SQL.
- Dans l'éditeur de requête, collez la requête ci-dessous et exécutez-la.
CREATE OR REPLACE MODEL `gemini_demo.gemini_1_5_flash`
REMOTE WITH CONNECTION `us.gemini_conn`
OPTIONS (endpoint = 'gemini-1.5-flash')
Ce code crée le modèle gemini_1_5_flash, qui est ajouté à l'ensemble de données gemini_demo dans la section des modèles.
- Dans l'explorateur, cliquez sur le modèle
gemini_1_5_flashet examinez les détails.
8. Demander au modèle Gemini de fournir un résumé du film pour chaque affiche
Dans cette tâche, vous allez utiliser le modèle distant Gemini que vous venez de créer pour analyser les images des affiches et générer un résumé pour chaque film.
Vous pouvez envoyer des requêtes au modèle à l'aide de la fonction ML.GENERATE_TEXT, en référençant le modèle dans les paramètres.
Analyser les images avec le modèle Gemini 1.5 Flash
- Créez une requête et exécutez-la avec l'instruction SQL suivante :
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results` AS (
SELECT
uri,
ml_generate_text_llm_result
FROM
ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_1_5_flash`,
TABLE `gemini_demo.movie_posters`,
STRUCT( 0.2 AS temperature,
'For the movie represented by this poster, what is the movie title and year of release? Answer in JSON format with two keys: title, year. title should be string, year should be integer. Do not use JSON decorators.' AS PROMPT,
TRUE AS FLATTEN_JSON_OUTPUT)));
Lorsque la requête s'exécute, BigQuery invite le modèle Gemini pour chaque ligne de la table d'objets, en combinant l'image avec la requête statique spécifiée. Cette requête crée la table movie_posters_results.
- Affichons maintenant les résultats. Créez une requête et exécutez-la avec l'instruction SQL suivante :
SELECT * FROM `gemini_demo.movie_posters_results`
Cette requête affiche les lignes de chaque affiche de film avec l'URI (l'emplacement Cloud Storage de l'image de l'affiche de film) et un résultat JSON incluant le titre du film et l'année de sa sortie, fournis par le modèle Gemini 1.5 Flash.
Vous pouvez récupérer ces résultats dans un format plus lisible en utilisant la requête suivante. Cette requête utilise SQL pour extraire le titre du film et l'année de sortie de ces réponses dans de nouvelles colonnes.
- Créez une requête et exécutez-la avec l'instruction SQL suivante :
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results_formatted` AS (
SELECT
uri,
JSON_VALUE(ml_generate_text_llm_result, "$.title") AS title,
JSON_VALUE(ml_generate_text_llm_result, "$.year") AS year
FROM
`gemini_demo.movie_posters_results` results )
Cette requête crée la table movie_posters_result_formatted.
- Vous pouvez interroger la table avec la requête ci-dessous pour voir les lignes créées.
SELECT * FROM `gemini_demo.movie_posters_results_formatted`
Notez que les résultats de la colonne URI restent les mêmes, mais que le JSON est désormais converti en colonnes title et year pour chaque ligne.
Demander au modèle Gemini 1.5 Flash de fournir des résumés de films
Et si vous souhaitiez obtenir plus d'informations sur chacun de ces films, par exemple un résumé textuel ? Ce cas d'utilisation de génération de contenu est idéal pour un modèle LLM tel que Gemini 1.5 Flash.
- Vous pouvez utiliser Gemini 1.5 Flash pour fournir un résumé du film correspondant à chaque affiche en exécutant la requête ci-dessous :
SELECT
uri,
title,
year,
prompt,
ml_generate_text_llm_result
FROM
ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_1_5_flash`,
(
SELECT
CONCAT('Provide a short summary of movie titled ',title, ' from the year ',year,'.') AS prompt,
uri,
title,
year
FROM
`gemini_demo.movie_posters_results_formatted`
LIMIT
20 ),
STRUCT(0.2 AS temperature,
TRUE AS FLATTEN_JSON_OUTPUT));
Notez le champ ml_generate_text_llm_result des résultats, qui inclut un bref résumé du film.
9. Générer des embeddings textuels avec un modèle distant
Vous pouvez désormais joindre les données structurées que vous avez créées à d'autres données structurées de votre entrepôt. L'ensemble de données public IMDB disponible dans BigQuery contient de nombreuses informations sur les films, y compris les notes des spectateurs et quelques exemples d'avis d'utilisateurs au format libre. Ces données peuvent vous aider à approfondir votre analyse des affiches de films et à comprendre comment ces films ont été perçus.
Pour joindre des données, vous aurez besoin d'une clé. Dans ce cas, il est possible que les titres de films générés par le modèle Gemini ne correspondent pas parfaitement à ceux de l'ensemble de données IMDB.
Dans cette tâche, vous allez générer des embeddings de texte des titres et des années de sortie des films des deux ensembles de données. Vous utiliserez ensuite la distance entre ces embeddings pour associer le titre IMDB le plus proche aux titres des affiches de films de l'ensemble de données que vous venez de créer.
Créer le modèle distant
Pour générer les embeddings textuels, vous devez créer un modèle distant pointant vers le point de terminaison text-multilingual-embedding-002.
- Créez une requête et exécutez-la avec l'instruction SQL suivante :
CREATE OR REPLACE MODEL `gemini_demo.text_embedding`
REMOTE WITH CONNECTION `us.gemini_conn`
OPTIONS (endpoint = 'text-multilingual-embedding-002')
Le modèle text_embedding est créé et apparaît en dessous de l'ensemble de données gemini_demo dans l'explorateur.
Générer des embeddings textuels pour le titre et l'année associés aux affiches
Vous allez maintenant utiliser ce modèle distant avec la fonction ML.GENERATE_EMBEDDING pour créer un embedding pour chaque titre et année d'affiche de film.
- Créez une requête et exécutez-la avec l'instruction SQL suivante :
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results_embeddings` AS (
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
MODEL `gemini_demo.text_embedding`,
(
SELECT
CONCAT('The movie titled ', title, ' from the year ', year,'.') AS content,
title,
year,
uri
FROM
`gemini_demo.movie_posters_results_formatted` ),
STRUCT(TRUE AS flatten_json_output)));
Le résultat est la création de la table movie_poster_results_embeddings contenant les embeddings pour le contenu textuel concaténé pour chaque ligne de la table gemini_demo.movie_posters_results_formatted.
- Vous pouvez afficher les résultats de la requête à l'aide de la nouvelle requête ci-dessous :
SELECT * FROM `gemini_demo.movie_posters_results_embeddings`
Vous pouvez voir ici les embeddings (vecteurs représentés par des nombres) que le modèle a générés pour chaque film.
Générer des embeddings textuels pour un sous-ensemble de l'ensemble de données IMDB
Vous allez créer une vue des données d'un ensemble de données IMDB public qui ne contient que les films sortis avant 1935 (la période connue des films à partir des images d'affiches).
- Créez une requête et exécutez-la avec l'instruction SQL suivante :
CREATE OR REPLACE VIEW
`gemini_demo.imdb_movies` AS (
WITH
reviews AS (
SELECT
reviews.movie_id AS movie_id,
title.primary_title AS title,
title.start_year AS year,
reviews.review AS review
FROM
`bigquery-public-data.imdb.reviews` reviews
LEFT JOIN
`bigquery-public-data.imdb.title_basics` title
ON
reviews.movie_id = title.tconst)
SELECT
DISTINCT(movie_id),
title,
year
FROM
reviews
WHERE
year < 1935)
Cette requête crée une vue contenant une liste des ID, titres et années de sortie des différents films provenant de la table bigquery-public-data.imdb.reviews pour tous les films de l'ensemble de données sortis avant 1935.
- Vous allez maintenant créer des embeddings pour le sous-ensemble de films d'IMDb en suivant une procédure semblable à celle de la section précédente. Créez une requête et exécutez-la avec l'instruction SQL suivante :
CREATE OR REPLACE TABLE
`gemini_demo.imdb_movies_embeddings` AS (
SELECT
*
FROM
ML.GENERATE_EMBEDDING( MODEL `gemini_demo.text_embedding`,
(
SELECT
CONCAT('The movie titled ', title, ' from the year ', year,'.') AS content,
title,
year,
movie_id
FROM
`gemini_demo.imdb_movies` ),
STRUCT(TRUE AS flatten_json_output) )
WHERE
ml_generate_embedding_status = '' );
Le résultat de la requête est une table contenant les embeddings pour le contenu textuel de la table gemini_demo.imdb_movies.
Associer les images d'affiches de films aux movie_id IMDB à l'aide de la fonction VECTOR_SEARCH de BigQuery
Vous pouvez maintenant joindre les deux tables à l'aide de la fonction VECTOR_SEARCH.
- Créez une requête et exécutez-la avec l'instruction SQL suivante :
SELECT
query.uri AS poster_uri,
query.title AS poster_title,
query.year AS poster_year,
base.title AS imdb_title,
base.year AS imdb_year,
base.movie_id AS imdb_movie_id,
distance
FROM
VECTOR_SEARCH( TABLE `gemini_demo.imdb_movies_embeddings`,
'ml_generate_embedding_result',
TABLE `gemini_demo.movie_posters_results_embeddings`,
'ml_generate_embedding_result',
top_k => 1,
distance_type => 'COSINE');
La requête utilise la fonction VECTOR_SEARCH pour trouver le voisin le plus proche dans la table gemini_demo.imdb_movies_embeddings pour chaque ligne de la table gemini_demo.movie_posters_results_embeddings. Le voisin le plus proche est identifié à l'aide de la métrique de distance de cosinus, qui détermine le degré de similarité entre deux embeddings.
Cette requête permet de trouver le film le plus similaire dans l'ensemble de données IMDB pour chacun des films identifiés par Gemini 1.5 Flash à partir des affiches. Par exemple, vous pourriez utiliser cette requête pour trouver le résultat le plus proche du film "Au Secours !" dans l'ensemble de données public IMDB, qui fait référence à ce film par son titre en anglais : "Help!".
- Créez une requête et exécutez-la pour joindre des informations supplémentaires sur les notes attribuées aux films dans l'ensemble de données public IMDB :
SELECT
query.uri AS poster_uri,
query.title AS poster_title,
query.year AS poster_year,
base.title AS imdb_title,
base.year AS imdb_year,
base.movie_id AS imdb_movie_id,
distance,
imdb.average_rating,
imdb.num_votes
FROM
VECTOR_SEARCH( TABLE `gemini_demo.imdb_movies_embeddings`,
'ml_generate_embedding_result',
TABLE `gemini_demo.movie_posters_results_embeddings`,
'ml_generate_embedding_result',
top_k => 1,
distance_type => 'COSINE') DATA
LEFT JOIN
`bigquery-public-data.imdb.title_ratings` imdb
ON
base.movie_id = imdb.tconst
ORDER BY
imdb.average_rating DESC
Cette requête ressemble à la précédente. Elle utilise encore des représentations numériques particulières appelées embeddings vectoriels pour trouver des films similaires à une affiche de film donnée. Toutefois, elle ajoute aussi la note moyenne et le nombre de votes pour chaque film voisin le plus proche à partir d'une table distincte de l'ensemble de données public IMDB.
10. Félicitations
Bravo ! Vous avez terminé cet atelier de programmation. Vous avez créé une table d'objets pour vos images d'affiches dans BigQuery, créé un modèle Gemini à distance, utilisé le modèle pour inviter le modèle Gemini à analyser des images et à fournir des résumés de films, généré des embeddings de texte pour les titres de films et utilisé ces embeddings pour faire correspondre les images d'affiches de films au titre de film associé dans l'ensemble de données IMDB.
Points abordés
- Configurer votre environnement et votre compte pour utiliser les API
- Créer une connexion à une ressource cloud dans BigQuery
- Créer un ensemble de données et une table d'objets dans BigQuery pour les images d'affiches de films
- Créer les modèles distants Gemini dans BigQuery
- Comment demander au modèle Gemini de fournir un résumé du film pour chaque affiche
- Générer des embeddings textuels pour le film représenté sur chaque affiche
- Utiliser
VECTOR_SEARCHBigQuery pour mettre en correspondance les images des affiches avec des films étroitement liés dans l'ensemble de données
Étapes suivantes et informations supplémentaires