
۱. مقدمه
در این آزمایشگاه، شما یاد خواهید گرفت که چگونه از یادگیری ماشینی BigQuery برای استنتاج با مدلهای از راه دور ( مدلهای Gemini ) استفاده کنید تا تصاویر پوستر فیلم را تجزیه و تحلیل کنید و خلاصههایی از فیلمها را بر اساس پوسترها مستقیماً در انبار داده BigQuery خود تولید کنید.

تصویر بالا: نمونهای از تصاویر پوستر فیلم که تحلیل خواهید کرد.
BigQuery یک پلتفرم تجزیه و تحلیل داده کاملاً مدیریتشده و آماده برای هوش مصنوعی است که به شما کمک میکند تا از دادههای خود حداکثر ارزش را به دست آورید و به گونهای طراحی شده است که چند موتوره، چند فرمته و چند ابری باشد. یکی از ویژگیهای کلیدی آن ، یادگیری ماشینی BigQuery برای استنتاج است که به شما امکان میدهد مدلهای یادگیری ماشینی (ML) را با استفاده از کوئریهای GoogleSQL ایجاد و اجرا کنید.
جمینی (Gemini) خانوادهای از مدلهای هوش مصنوعی مولد است که توسط گوگل توسعه داده شده و برای موارد استفاده چندوجهی طراحی شده است.
اجرای مدلهای یادگیری ماشین با استفاده از کوئریهای GoogleSQL
معمولاً انجام یادگیری ماشینی یا هوش مصنوعی (AI) روی مجموعه دادههای بزرگ نیازمند برنامهنویسی گسترده و دانش چارچوبهای یادگیری ماشینی است. این امر توسعه راهحل را به گروه کوچکی از متخصصان در هر شرکت محدود میکند. با استفاده از یادگیری ماشینی BigQuery برای استنتاج، متخصصان SQL میتوانند از ابزارها و مهارتهای موجود SQL برای ساخت مدلها و تولید نتایج از LLMها و APIهای هوش مصنوعی ابری استفاده کنند.
پیشنیازها
- درک اولیه از کنسول ابری گوگل
- آشنایی با BigQuery مزیت محسوب میشود
آنچه یاد خواهید گرفت
- نحوه پیکربندی محیط و حساب کاربری خود برای استفاده از APIها
- نحوه ایجاد اتصال منابع ابری در BigQuery
- نحوه ایجاد یک مجموعه داده و جدول شیء در BigQuery برای تصاویر پوستر فیلم
- نحوه ایجاد مدلهای از راه دور Gemini در BigQuery
- چگونه مدل Gemini را وادار کنیم تا خلاصه فیلم را برای هر پوستر ارائه دهد
- نحوه ایجاد جاسازی متن برای فیلم نمایش داده شده در هر پوستر
- نحوه استفاده از BigQuery
VECTOR_SEARCHبرای تطبیق تصاویر پوستر فیلم با فیلمهای مرتبط در مجموعه دادهها
آنچه نیاز دارید
- یک حساب کاربری گوگل کلود و پروژه گوگل کلود، با قابلیت پرداخت صورتحساب
- یک مرورگر وب مانند کروم
۲. تنظیمات و الزامات
تنظیم محیط خودتنظیم
- وارد کنسول گوگل کلود شوید و یک پروژه جدید ایجاد کنید یا از یک پروژه موجود دوباره استفاده کنید. اگر از قبل حساب جیمیل یا گوگل ورک اسپیس ندارید، باید یکی ایجاد کنید .

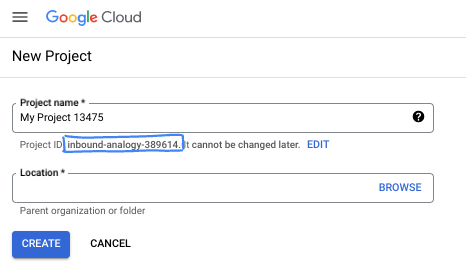
- نام پروژه، نام نمایشی برای شرکتکنندگان این پروژه است. این یک رشته کاراکتری است که توسط APIهای گوگل استفاده نمیشود. شما همیشه میتوانید آن را بهروزرسانی کنید.
- شناسه پروژه در تمام پروژههای گوگل کلود منحصر به فرد است و تغییرناپذیر است (پس از تنظیم، قابل تغییر نیست). کنسول کلود به طور خودکار یک رشته منحصر به فرد تولید میکند؛ معمولاً برای شما مهم نیست که چه باشد. در اکثر آزمایشگاههای کد، باید شناسه پروژه خود را (که معمولاً با عنوان
PROJECT_IDشناخته میشود) ارجاع دهید. اگر شناسه تولید شده را دوست ندارید، میتوانید یک شناسه تصادفی دیگر ایجاد کنید. به عنوان یک جایگزین، میتوانید شناسه خودتان را امتحان کنید و ببینید که آیا در دسترس است یا خیر. پس از این مرحله قابل تغییر نیست و در طول پروژه باقی میماند. - برای اطلاع شما، یک مقدار سوم، شماره پروژه ، وجود دارد که برخی از APIها از آن استفاده میکنند. برای کسب اطلاعات بیشتر در مورد هر سه این مقادیر، به مستندات مراجعه کنید.
- در مرحله بعد، برای استفاده از منابع/API های ابری، باید پرداخت صورتحساب را در کنسول ابری فعال کنید . اجرای این آزمایشگاه کد هزینه زیادی نخواهد داشت، اگر اصلاً هزینهای داشته باشد. برای خاموش کردن منابع به منظور جلوگیری از پرداخت صورتحساب پس از این آموزش، میتوانید منابعی را که ایجاد کردهاید یا پروژه را حذف کنید. کاربران جدید Google Cloud واجد شرایط برنامه آزمایشی رایگان ۳۰۰ دلاری هستند.
شروع پوسته ابری
اگرچه میتوان از راه دور و از طریق لپتاپ، گوگل کلود را مدیریت کرد، اما در این آزمایشگاه کد، از گوگل کلود شل ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده خواهید کرد.
از کنسول گوگل کلود ، روی آیکون Cloud Shell در نوار ابزار بالا سمت راست کلیک کنید:

آمادهسازی و اتصال به محیط فقط چند لحظه طول میکشد. وقتی تمام شد، باید چیزی شبیه به این را ببینید:

این ماشین مجازی با تمام ابزارهای توسعهای که نیاز دارید، مجهز شده است. این ماشین مجازی یک دایرکتوری خانگی پایدار ۵ گیگابایتی ارائه میدهد و روی فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. تمام کارهای شما در این آزمایشگاه کد را میتوان در یک مرورگر انجام داد. نیازی به نصب چیزی ندارید.
۳. قبل از شروع
چند مرحله راهاندازی برای کار با مدلهای Gemini در BigQuery وجود دارد، از جمله فعال کردن APIها، ایجاد یک اتصال به منابع ابری و اعطای مجوزهای خاص به حساب سرویس برای اتصال به منابع ابری. این مراحل برای هر پروژه یک بار انجام میشوند و در چند بخش بعدی به آنها پرداخته خواهد شد.
فعال کردن APIها
در داخل Cloud Shell، مطمئن شوید که شناسه پروژه شما تنظیم شده است:
gcloud config set project [YOUR-PROJECT-ID]
متغیر محیطی PROJECT_ID را تنظیم کنید:
PROJECT_ID=$(gcloud config get-value project)
منطقه پیشفرض خود را برای استفاده در مدلهای Vertex AI پیکربندی کنید. درباره مکانهای موجود برای Vertex AI بیشتر بخوانید. در مثال ما از منطقه us-central1 استفاده میکنیم.
gcloud config set compute/region us-central1
تنظیم متغیر محیطی REGION :
REGION=$(gcloud config get-value compute/region)
فعال کردن تمام سرویسهای لازم:
gcloud services enable bigqueryconnection.googleapis.com \
aiplatform.googleapis.com
خروجی مورد انتظار پس از اجرای تمام دستورات بالا:
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable bigqueryconnection.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
۴. یک اتصال به منابع ابری ایجاد کنید
در این کار، شما یک اتصال Cloud Resource ایجاد خواهید کرد که BigQuery را قادر میسازد به فایلهای تصویری در Cloud Storage دسترسی پیدا کند و با Vertex AI تماس برقرار کند.
- در کنسول ابری گوگل، در منوی ناوبری (
 ) ، روی BigQuery کلیک کنید.
) ، روی BigQuery کلیک کنید.
- برای ایجاد اتصال، روی + ADD کلیک کنید و سپس روی Connections to external data sources کلیک کنید.

- در لیست نوع اتصال، مدلهای از راه دور Vertex AI، توابع از راه دور و BigLake (منبع ابری) را انتخاب کنید.
- در فیلد شناسه اتصال، برای اتصال خود ، gemini_conn را وارد کنید.
- برای نوع موقعیت مکانی ، گزینه Multi-region و سپس از منوی کشویی، گزینه US multi-region را انتخاب کنید.
- برای سایر تنظیمات از مقادیر پیشفرض استفاده کنید.

- روی ایجاد اتصال کلیک کنید.
- روی «برو به اتصال» کلیک کنید.
- در پنل اطلاعات اتصال، شناسه حساب سرویس را برای استفاده در کار بعدی در یک فایل متنی کپی کنید. همچنین خواهید دید که اتصال در بخش اتصالات خارجی پروژه شما در BigQuery Explorer اضافه شده است.
۵. مجوزهای IAM را به حساب سرویس اتصال اعطا کنید
در این وظیفه، شما از طریق یک نقش، مجوزهای IAM حساب سرویس اتصال Cloud Resource را اعطا میکنید تا به سرویسهای Vertex AI دسترسی داشته باشد.
- در کنسول گوگل کلود، در منوی ناوبری ، روی IAM & Admin کلیک کنید.
- Click Grant Access .
- در فیلد New principals ، شناسه حساب سرویس را که قبلاً کپی کردهاید، وارد کنید.
- در فیلد «انتخاب نقش»، عبارت Vertex AI را وارد کنید و سپس نقش کاربر Vertex AI را انتخاب کنید.
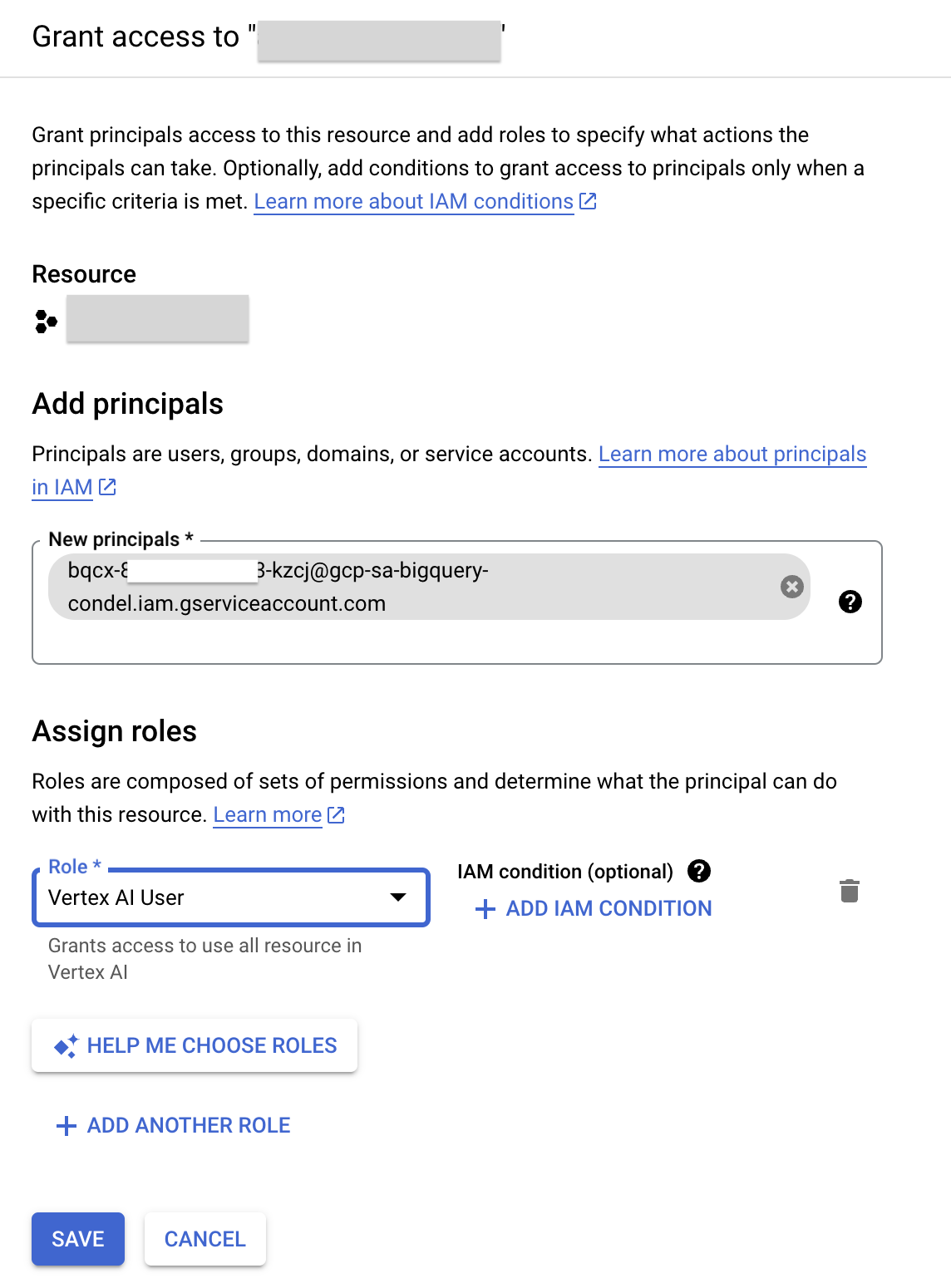
- روی ذخیره کلیک کنید. نتیجه این است که شناسه حساب سرویس اکنون شامل نقش کاربر Vertex AI میشود.
۶. ایجاد مجموعه داده و جدول اشیاء در BigQuery برای تصاویر پوستر فیلم
در این کار، شما یک مجموعه داده برای پروژه و یک جدول شیء درون آن برای ذخیره تصاویر پوستر ایجاد خواهید کرد.
مجموعه دادههای تصاویر پوستر فیلم که در این آموزش استفاده شدهاند، در یک مخزن عمومی ذخیرهسازی ابری گوگل ذخیره میشوند: gs://cloud-samples-data/vertex-ai/dataset-management/datasets/classic-movie-posters
ایجاد مجموعه داده
شما یک مجموعه داده برای ذخیره اشیاء پایگاه داده، از جمله جداول و مدلها، که در این آموزش استفاده شدهاند، ایجاد خواهید کرد.
- در کنسول گوگل کلود، منوی ناوبری (Navigation) را انتخاب کنید. ) و سپس BigQuery را انتخاب کنید.
- در پنل اکسپلورر ، در کنار نام پروژه خود، گزینه View actions (مشاهده اقدامات ) را انتخاب کنید.
 ) و سپس ایجاد مجموعه داده را انتخاب کنید.
) و سپس ایجاد مجموعه داده را انتخاب کنید. - در پنل ایجاد مجموعه داده ، اطلاعات زیر را وارد کنید:
- شناسه مجموعه داده: gemini_demo
- نوع مکان: چند منطقهای را انتخاب کنید
- چند منطقه ای: ایالات متحده را انتخاب کنید
- فیلدهای دیگر را به حالت پیشفرض خود رها کنید.

- روی ایجاد مجموعه داده کلیک کنید.
نتیجه این است که مجموعه داده gemini_demo ایجاد شده و در زیر پروژه شما در BigQuery Explorer فهرست میشود.
جدول اشیاء را ایجاد کنید
بیگکوئری نه تنها دادههای ساختاریافته را در خود نگه میدارد، بلکه میتواند از طریق جداول شیء به دادههای بدون ساختار (مانند تصاویر پوستر) نیز دسترسی داشته باشد.
شما با اشاره به یک سطل ذخیرهسازی ابری، یک جدول شیء ایجاد میکنید و جدول شیء حاصل، برای هر شیء از سطل، یک ردیف به همراه مسیر ذخیرهسازی و فرادادههای آن دارد.
برای ایجاد جدول شیء، از یک پرسوجوی SQL استفاده خواهید کرد.
- برای ایجاد یک کوئری SQL جدید، روی + کلیک کنید.
- در ویرایشگر کوئری، کوئری زیر را وارد کنید.
CREATE OR REPLACE EXTERNAL TABLE
`gemini_demo.movie_posters`
WITH CONNECTION `us.gemini_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://cloud-samples-data/vertex-ai/dataset-management/datasets/classic-movie-posters/*']
);
- کوئری را اجرا کنید. نتیجه، یک جدول شیء
movie_postersاست که به مجموعه دادهgemini_demoاضافه شده و باURI(مکان ذخیرهسازی ابری) هر تصویر پوستر فیلم بارگذاری شده است. - در پنجره اکسپلورر، روی
movie_postersکلیک کنید و طرحواره و جزئیات آن را بررسی کنید. میتوانید برای بررسی رکوردهای خاص، از جدول پرسوجو کنید.
۷. مدل ریموت Gemini را در BigQuery ایجاد کنید
اکنون که جدول اشیاء ایجاد شده است، میتوانید شروع به کار با آن کنید. در این کار، شما یک مدل از راه دور برای Gemini 1.5 Flash ایجاد خواهید کرد تا آن را در BigQuery در دسترس قرار دهید.
مدل ریموت Gemini 1.5 Flash را ایجاد کنید
- برای ایجاد یک کوئری SQL جدید، روی + کلیک کنید.
- در ویرایشگر کوئری، کوئری زیر را وارد کرده و اجرا کنید.
CREATE OR REPLACE MODEL `gemini_demo.gemini_1_5_flash`
REMOTE WITH CONNECTION `us.gemini_conn`
OPTIONS (endpoint = 'gemini-1.5-flash')
نتیجه این است که مدل gemini_1_5_flash ایجاد شده و میتوانید آن را در بخش مدلها، به مجموعه داده gemini_demo اضافه کنید.
- در پنجره اکسپلورر، روی مدل
gemini_1_5_flashکلیک کنید و جزئیات را بررسی کنید.
۸. از مدل Gemini بخواهید خلاصهای از فیلمها را برای هر پوستر ارائه دهد.
در این تکلیف، شما از مدل کنترل از راه دور Gemini که اخیراً ایجاد کردهاید برای تجزیه و تحلیل تصاویر پوستر فیلم و تولید خلاصههایی برای هر فیلم استفاده خواهید کرد.
شما میتوانید با استفاده از تابع ML.GENERATE_TEXT و با ارجاع به مدل در پارامترها، درخواستهایی را به مدل ارسال کنید.
تصاویر را با مدل Gemini 1.5 Flash تجزیه و تحلیل کنید
- یک کوئری جدید با دستور SQL زیر ایجاد و اجرا کنید:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results` AS (
SELECT
uri,
ml_generate_text_llm_result
FROM
ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_1_5_flash`,
TABLE `gemini_demo.movie_posters`,
STRUCT( 0.2 AS temperature,
'For the movie represented by this poster, what is the movie title and year of release? Answer in JSON format with two keys: title, year. title should be string, year should be integer. Do not use JSON decorators.' AS PROMPT,
TRUE AS FLATTEN_JSON_OUTPUT)));
وقتی کوئری اجرا میشود، BigQuery مدل Gemini را برای هر ردیف از جدول اشیاء فراخوانی میکند و تصویر را با اعلان استاتیک مشخص شده ترکیب میکند. نتیجه این میشود که جدول movie_posters_results ایجاد میشود.
- حالا بیایید نتایج را مشاهده کنیم. یک کوئری جدید با دستور SQL زیر ایجاد و اجرا کنید:
SELECT * FROM `gemini_demo.movie_posters_results`
نتیجه، ردیفهایی برای هر پوستر فیلم به همراه URI (محل ذخیرهسازی ابری تصویر پوستر فیلم) و یک نتیجه JSON شامل عنوان فیلم و سال انتشار فیلم از مدل Gemini 1.5 Flash است.
شما میتوانید با استفاده از کوئری بعدی، این نتایج را به روشی خواناتر برای انسان بازیابی کنید. این کوئری از SQL برای استخراج عنوان فیلم و سال انتشار آن از این پاسخها و قرار دادن آنها در ستونهای جدید استفاده میکند.
- یک کوئری جدید با دستور SQL زیر ایجاد و اجرا کنید:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results_formatted` AS (
SELECT
uri,
JSON_VALUE(ml_generate_text_llm_result, "$.title") AS title,
JSON_VALUE(ml_generate_text_llm_result, "$.year") AS year
FROM
`gemini_demo.movie_posters_results` results )
نتیجه این است که جدول movie_posters_result_formatted ایجاد میشود.
- شما میتوانید با استفاده از کوئری زیر، جدول را بررسی کنید تا ردیفهای ایجاد شده را ببینید.
SELECT * FROM `gemini_demo.movie_posters_results_formatted`
توجه کنید که چگونه نتایج ستون URI یکسان باقی میمانند، اما JSON اکنون برای هر ردیف به ستونهای title و year تبدیل میشود.
مدل Gemini 1.5 Flash را وادار به ارائه خلاصه فیلم کنید
اگر اطلاعات بیشتری در مورد هر یک از این فیلمها میخواستید، مثلاً خلاصهای متنی از هر یک از فیلمها، چه؟ این مورد استفاده از تولید محتوا برای یک مدل LLM مانند مدل Gemini 1.5 Flash عالی است.
- شما میتوانید با اجرای کوئری زیر، از Gemini 1.5 Flash برای ارائه خلاصه فیلم برای هر پوستر استفاده کنید:
SELECT
uri,
title,
year,
prompt,
ml_generate_text_llm_result
FROM
ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_1_5_flash`,
(
SELECT
CONCAT('Provide a short summary of movie titled ',title, ' from the year ',year,'.') AS prompt,
uri,
title,
year
FROM
`gemini_demo.movie_posters_results_formatted`
LIMIT
20 ),
STRUCT(0.2 AS temperature,
TRUE AS FLATTEN_JSON_OUTPUT));
به فیلد ml_generate_text_llm_result در نتایج توجه کنید؛ این شامل خلاصهای کوتاه از فیلم است.
۹. ایجاد جاسازیهای متنی با استفاده از یک مدل از راه دور
اکنون میتوانید دادههای ساختاریافتهای که ساختهاید را با سایر دادههای ساختاریافته در انبار داده خود ادغام کنید. مجموعه دادههای عمومی IMDB موجود در BigQuery حاوی اطلاعات غنی در مورد فیلمها، از جمله رتبهبندی بینندگان و برخی از نمونه نظرات کاربران با فرمت آزاد است. این دادهها میتواند به شما در تعمیق تحلیل پوسترهای فیلم و درک چگونگی درک این فیلمها کمک کند.
برای اتصال دادهها، به یک کلید نیاز دارید. در این حالت، عناوین فیلمهای تولید شده توسط مدل Gemini ممکن است کاملاً با عناوین موجود در مجموعه دادههای IMDB مطابقت نداشته باشند.
در این کار، شما جاسازیهای متنی عناوین فیلمها و سالها را از هر دو مجموعه داده ایجاد خواهید کرد و سپس از فاصله بین این جاسازیها برای اتصال نزدیکترین عنوان IMDB به عناوین پوستر فیلم از مجموعه داده تازه ایجاد شده خود استفاده خواهید کرد.
ایجاد مدل از راه دور
برای تولید جاسازیهای متن، باید یک مدل از راه دور جدید ایجاد کنید که به نقطه پایانی text-multilingual-embedding-002 اشاره کند.
- یک کوئری جدید با دستور SQL زیر ایجاد و اجرا کنید:
CREATE OR REPLACE MODEL `gemini_demo.text_embedding`
REMOTE WITH CONNECTION `us.gemini_conn`
OPTIONS (endpoint = 'text-multilingual-embedding-002')
نتیجه این است که مدل text_embedding ایجاد شده و در اکسپلورر زیر مجموعه داده gemini_demo ظاهر میشود.
ایجاد جاسازیهای متنی برای عنوان و سال مرتبط با پوسترها
اکنون از این مدل راه دور به همراه تابع ML.GENERATE_EMBEDDING برای ایجاد جاسازی برای هر عنوان پوستر فیلم و سال انتشار آن استفاده خواهید کرد.
- یک کوئری جدید با دستور SQL زیر ایجاد و اجرا کنید:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results_embeddings` AS (
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
MODEL `gemini_demo.text_embedding`,
(
SELECT
CONCAT('The movie titled ', title, ' from the year ', year,'.') AS content,
title,
year,
uri
FROM
`gemini_demo.movie_posters_results_formatted` ),
STRUCT(TRUE AS flatten_json_output)));
نتیجه این است که جدول movie_poster_results_embeddings ایجاد میشود که شامل جاسازیها برای محتوای متنی است که برای هر سطر از جدول gemini_demo.movie_posters_results_formatted به هم پیوستهاند.
- شما میتوانید نتایج پرسوجو را با استفاده از پرسوجوی جدید زیر مشاهده کنید:
SELECT * FROM `gemini_demo.movie_posters_results_embeddings`
در اینجا شما جاسازیها (بردارهایی که با اعداد نمایش داده میشوند) را برای هر فیلم تولید شده توسط مدل مشاهده میکنید.
ایجاد جاسازیهای متنی برای زیرمجموعهای از مجموعه دادههای IMDB
شما یک نمای جدید از دادهها از یک مجموعه داده عمومی IMDB ایجاد خواهید کرد که فقط شامل فیلمهایی است که قبل از سال ۱۹۳۵ منتشر شدهاند (دوره زمانی شناخته شده فیلمها از تصاویر پوستر).
- یک کوئری جدید با دستور SQL زیر ایجاد و اجرا کنید:
CREATE OR REPLACE VIEW
`gemini_demo.imdb_movies` AS (
WITH
reviews AS (
SELECT
reviews.movie_id AS movie_id,
title.primary_title AS title,
title.start_year AS year,
reviews.review AS review
FROM
`bigquery-public-data.imdb.reviews` reviews
LEFT JOIN
`bigquery-public-data.imdb.title_basics` title
ON
reviews.movie_id = title.tconst)
SELECT
DISTINCT(movie_id),
title,
year
FROM
reviews
WHERE
year < 1935)
نتیجه، یک نمای جدید است که شامل فهرستی از شناسههای متمایز فیلم، عناوین و سال انتشار از جدول bigquery-public-data.imdb.reviews برای همه فیلمهای موجود در مجموعه دادهها است که قبل از سال ۱۹۳۵ منتشر شدهاند.
- اکنون با استفاده از فرآیندی مشابه بخش قبل، جاسازیهایی را برای زیرمجموعهای از فیلمها از IMDB ایجاد خواهید کرد. یک کوئری جدید با دستور SQL زیر ایجاد و اجرا کنید:
CREATE OR REPLACE TABLE
`gemini_demo.imdb_movies_embeddings` AS (
SELECT
*
FROM
ML.GENERATE_EMBEDDING( MODEL `gemini_demo.text_embedding`,
(
SELECT
CONCAT('The movie titled ', title, ' from the year ', year,'.') AS content,
title,
year,
movie_id
FROM
`gemini_demo.imdb_movies` ),
STRUCT(TRUE AS flatten_json_output) )
WHERE
ml_generate_embedding_status = '' );
نتیجهی کوئری، جدولی است که شامل جاسازیهای مربوط به محتوای متنی جدول gemini_demo.imdb_movies است.
تصاویر پوستر فیلم را با استفاده از BigQuery VECTOR_SEARCH با IMDB movie_id مطابقت دهید
اکنون میتوانید با استفاده از تابع VECTOR_SEARCH دو جدول را به هم متصل کنید.
- یک کوئری جدید با دستور SQL زیر ایجاد و اجرا کنید:
SELECT
query.uri AS poster_uri,
query.title AS poster_title,
query.year AS poster_year,
base.title AS imdb_title,
base.year AS imdb_year,
base.movie_id AS imdb_movie_id,
distance
FROM
VECTOR_SEARCH( TABLE `gemini_demo.imdb_movies_embeddings`,
'ml_generate_embedding_result',
TABLE `gemini_demo.movie_posters_results_embeddings`,
'ml_generate_embedding_result',
top_k => 1,
distance_type => 'COSINE');
این پرسوجو از تابع VECTOR_SEARCH برای یافتن نزدیکترین همسایه در جدول gemini_demo.imdb_movies_embeddings برای هر ردیف در جدول gemini_demo.movie_posters_results_embeddings استفاده میکند. نزدیکترین همسایه با استفاده از معیار فاصله کسینوسی پیدا میشود که میزان شباهت دو جاسازی را تعیین میکند.
این پرسوجو میتواند برای یافتن مشابهترین فیلم در مجموعه دادههای IMDB برای هر یک از فیلمهای شناساییشده توسط Gemini 1.5 Flash در پوسترهای فیلم استفاده شود. برای مثال، میتوانید از این پرسوجو برای یافتن نزدیکترین تطابق برای فیلم "Au Secours!" در مجموعه دادههای عمومی IMDB استفاده کنید، که به این فیلم با عنوان انگلیسی آن، "Help!" اشاره دارد.
- یک کوئری جدید ایجاد و اجرا کنید تا اطلاعات اضافی در مورد رتبهبندی فیلمها که در مجموعه دادههای عمومی IMDB ارائه شده است را به هم متصل کنید:
SELECT
query.uri AS poster_uri,
query.title AS poster_title,
query.year AS poster_year,
base.title AS imdb_title,
base.year AS imdb_year,
base.movie_id AS imdb_movie_id,
distance,
imdb.average_rating,
imdb.num_votes
FROM
VECTOR_SEARCH( TABLE `gemini_demo.imdb_movies_embeddings`,
'ml_generate_embedding_result',
TABLE `gemini_demo.movie_posters_results_embeddings`,
'ml_generate_embedding_result',
top_k => 1,
distance_type => 'COSINE') DATA
LEFT JOIN
`bigquery-public-data.imdb.title_ratings` imdb
ON
base.movie_id = imdb.tconst
ORDER BY
imdb.average_rating DESC
این پرسوجو مشابه پرسوجوی قبلی است. هنوز از نمایشهای عددی ویژهای به نام جاسازیهای برداری برای یافتن فیلمهای مشابه با یک پوستر فیلم مشخص استفاده میکند. با این حال، میانگین امتیاز و تعداد آرا برای هر فیلم همسایه نزدیک را نیز از یک جدول جداگانه از مجموعه دادههای عمومی IMDB به هم متصل میکند.
۱۰. تبریک
تبریک بابت تکمیل آزمایشگاه کد. شما با موفقیت یک جدول شیء برای تصاویر پوستر خود در BigQuery ایجاد کردید، یک مدل Gemini از راه دور ایجاد کردید، از این مدل برای وادار کردن مدل Gemini به تجزیه و تحلیل تصاویر و ارائه خلاصه فیلمها استفاده کردید، جاسازیهای متنی برای عناوین فیلم ایجاد کردید و از این جاسازیها برای مطابقت تصاویر پوستر فیلم با عنوان فیلم مرتبط در مجموعه دادههای IMDB استفاده کردید.
آنچه ما پوشش دادهایم
- نحوه پیکربندی محیط و حساب کاربری خود برای استفاده از APIها
- نحوه ایجاد اتصال منابع ابری در BigQuery
- نحوه ایجاد یک مجموعه داده و جدول شیء در BigQuery برای تصاویر پوستر فیلم
- نحوه ایجاد مدلهای از راه دور Gemini در BigQuery
- چگونه مدل Gemini را وادار کنیم تا خلاصه فیلم را برای هر پوستر ارائه دهد
- نحوه ایجاد جاسازی متن برای فیلم نمایش داده شده در هر پوستر
- نحوه استفاده از BigQuery
VECTOR_SEARCHبرای تطبیق تصاویر پوستر فیلم با فیلمهای مرتبط در مجموعه دادهها
مراحل بعدی / اطلاعات بیشتر