
১. ভূমিকা
এই ল্যাবে, আপনি শিখবেন কীভাবে রিমোট মডেল ( জেমিনি মডেল ) ব্যবহার করে ইনফারেন্সের জন্য বিগকোয়েরি মেশিন লার্নিংয়ের মাধ্যমে সিনেমার পোস্টারের ছবি বিশ্লেষণ করতে হয় এবং সেই পোস্টারগুলোর উপর ভিত্তি করে সরাসরি আপনার বিগকোয়েরি ডেটা ওয়্যারহাউসে সিনেমার সারাংশ তৈরি করতে হয়।

উপরে প্রদর্শিত: সিনেমার পোস্টারের কিছু নমুনা যা আপনি বিশ্লেষণ করবেন।
BigQuery হলো একটি সম্পূর্ণভাবে পরিচালিত, এআই-সক্ষম ডেটা অ্যানালিটিক্স প্ল্যাটফর্ম যা আপনাকে আপনার ডেটা থেকে সর্বোচ্চ সুবিধা পেতে সাহায্য করে এবং এটি মাল্টি-ইঞ্জিন, মাল্টি-ফরম্যাট ও মাল্টি-ক্লাউড হিসেবে ডিজাইন করা হয়েছে। এর অন্যতম প্রধান বৈশিষ্ট্য হলো ইনফারেন্সের জন্য BigQuery মেশিন লার্নিং , যা আপনাকে GoogleSQL কোয়েরি ব্যবহার করে মেশিন লার্নিং (ML) মডেল তৈরি ও চালাতে দেয়।
জেমিনি হলো গুগল দ্বারা তৈরি জেনারেটিভ এআই মডেলের একটি পরিবার, যা মাল্টিমোডাল ব্যবহারের জন্য ডিজাইন করা হয়েছে।
GoogleSQL কোয়েরি ব্যবহার করে এমএল মডেল চালানো
সাধারণত, বৃহৎ ডেটাসেটে এমএল বা কৃত্রিম বুদ্ধিমত্তা (এআই) প্রয়োগ করার জন্য ব্যাপক প্রোগ্রামিং এবং এমএল ফ্রেমওয়ার্ক সম্পর্কে জ্ঞানের প্রয়োজন হয়। এটি প্রতিটি কোম্পানির মধ্যে অল্প সংখ্যক বিশেষজ্ঞের একটি ছোট দলের মধ্যেই সমাধান তৈরির কাজকে সীমাবদ্ধ করে রাখে। ইনফারেন্সের জন্য বিগকোয়েরি মেশিন লার্নিং ব্যবহার করে, এসকিউএল বিশেষজ্ঞরা বিদ্যমান এসকিউএল টুল ও দক্ষতা কাজে লাগিয়ে মডেল তৈরি করতে পারেন এবং এলএলএম ও ক্লাউড এআই এপিআই থেকে ফলাফল তৈরি করতে পারেন।
পূর্বশর্ত
- গুগল ক্লাউড কনসোল সম্পর্কে প্রাথমিক ধারণা
- BigQuery- তে অভিজ্ঞতা থাকলে তা অতিরিক্ত সুবিধা দেবে।
আপনি যা শিখবেন
- এপিআই ব্যবহার করার জন্য আপনার পরিবেশ এবং অ্যাকাউন্ট কীভাবে কনফিগার করবেন
- BigQuery-তে কীভাবে ক্লাউড রিসোর্স সংযোগ তৈরি করবেন
- বিগকোয়েরিতে মুভি পোস্টার ইমেজের জন্য ডেটাসেট এবং অবজেক্ট টেবিল কীভাবে তৈরি করবেন
- BigQuery-তে Gemini রিমোট মডেলগুলি কীভাবে তৈরি করবেন
- প্রতিটি পোস্টারের জন্য সিনেমার সারাংশ সরবরাহ করতে জেমিনি মডেলকে কীভাবে নির্দেশ দেবেন
- প্রতিটি পোস্টারে প্রদর্শিত সিনেমার জন্য কীভাবে টেক্সট এমবেডিং তৈরি করবেন
- ডেটা সেটে থাকা সিনেমার পোস্টারের ছবির সাথে ঘনিষ্ঠভাবে সম্পর্কিত সিনেমাগুলো মেলানোর জন্য BigQuery
VECTOR_SEARCHকীভাবে ব্যবহার করবেন
আপনার যা যা লাগবে
- বিলিং সক্ষম করা একটি গুগল ক্লাউড অ্যাকাউন্ট এবং গুগল ক্লাউড প্রজেক্ট।
- ক্রোমের মতো একটি ওয়েব ব্রাউজার
২. সেটআপ এবং প্রয়োজনীয়তা
স্ব-গতিতে পরিবেশ সেটআপ
- Google Cloud Console- এ সাইন-ইন করুন এবং একটি নতুন প্রজেক্ট তৈরি করুন অথবা বিদ্যমান কোনো প্রজেক্ট পুনরায় ব্যবহার করুন। যদি আপনার আগে থেকে Gmail বা Google Workspace অ্যাকাউন্ট না থাকে, তবে আপনাকে অবশ্যই একটি তৈরি করতে হবে।


- প্রজেক্টের নামটি হলো এই প্রজেক্টের অংশগ্রহণকারীদের প্রদর্শিত নাম। এটি একটি ক্যারেক্টার স্ট্রিং যা গুগল এপিআই ব্যবহার করে না। আপনি যেকোনো সময় এটি আপডেট করতে পারেন।
- প্রজেক্ট আইডি সমস্ত গুগল ক্লাউড প্রজেক্ট জুড়ে অনন্য এবং অপরিবর্তনীয় (একবার সেট করার পর এটি পরিবর্তন করা যায় না)। ক্লাউড কনসোল স্বয়ংক্রিয়ভাবে একটি অনন্য স্ট্রিং তৈরি করে; সাধারণত এটি কী তা নিয়ে আপনার মাথা ঘামানোর দরকার নেই। বেশিরভাগ কোডল্যাবে, আপনাকে আপনার প্রজেক্ট আইডি উল্লেখ করতে হবে (যা সাধারণত
PROJECT_IDহিসাবে চিহ্নিত করা হয়)। তৈরি করা আইডিটি আপনার পছন্দ না হলে, আপনি এলোমেলোভাবে আরেকটি তৈরি করতে পারেন। বিকল্পভাবে, আপনি আপনার নিজের আইডি দিয়ে চেষ্টা করে দেখতে পারেন যে সেটি উপলব্ধ আছে কিনা। এই ধাপের পরে এটি পরিবর্তন করা যাবে না এবং প্রজেক্টের পুরো সময়কাল জুড়ে এটি অপরিবর্তিত থাকবে। - আপনার অবগতির জন্য জানাচ্ছি যে, তৃতীয় একটি ভ্যালু রয়েছে, যা হলো প্রজেক্ট নম্বর , এবং কিছু এপিআই এটি ব্যবহার করে থাকে। ডকুমেন্টেশনে এই তিনটি ভ্যালু সম্পর্কে আরও বিস্তারিত জানুন।
- এরপর, ক্লাউড রিসোর্স/এপিআই ব্যবহার করার জন্য আপনাকে ক্লাউড কনসোলে বিলিং চালু করতে হবে। এই কোডল্যাবটি সম্পন্ন করতে খুব বেশি খরচ হবে না, এমনকি আদৌ কোনো খরচ নাও হতে পারে। এই টিউটোরিয়ালের পর বিলিং এড়াতে রিসোর্সগুলো বন্ধ করার জন্য, আপনি আপনার তৈরি করা রিসোর্সগুলো অথবা প্রজেক্টটি ডিলিট করে দিতে পারেন। নতুন গুগল ক্লাউড ব্যবহারকারীরা ৩০০ মার্কিন ডলারের ফ্রি ট্রায়াল প্রোগ্রামের জন্য যোগ্য।
ক্লাউড শেল শুরু করুন
যদিও গুগল ক্লাউড আপনার ল্যাপটপ থেকে দূরবর্তীভাবে পরিচালনা করা যায়, এই কোডল্যাবে আপনি গুগল ক্লাউড শেল ব্যবহার করবেন, যা ক্লাউডে চালিত একটি কমান্ড লাইন পরিবেশ।
গুগল ক্লাউড কনসোল থেকে, উপরের ডানদিকের টুলবারে থাকা ক্লাউড শেল আইকনটিতে ক্লিক করুন:

পরিবেশটি প্রস্তুত করতে এবং এর সাথে সংযোগ স্থাপন করতে মাত্র কয়েক মুহূর্ত সময় লাগবে। এটি শেষ হলে, আপনি এইরকম কিছু দেখতে পাবেন:

এই ভার্চুয়াল মেশিনটিতে আপনার প্রয়োজনীয় সমস্ত ডেভেলপমেন্ট টুলস লোড করা আছে। এটি একটি স্থায়ী ৫ জিবি হোম ডিরেক্টরি প্রদান করে এবং গুগল ক্লাউডে চলে, যা নেটওয়ার্ক পারফরম্যান্স ও অথেনটিকেশনকে ব্যাপকভাবে উন্নত করে। এই কোডল্যাবে আপনার সমস্ত কাজ একটি ব্রাউজারের মধ্যেই করা যাবে। আপনাকে কিছুই ইনস্টল করতে হবে না।
৩. শুরু করার আগে
BigQuery-তে Gemini মডেল নিয়ে কাজ করার জন্য কয়েকটি সেটআপ ধাপ রয়েছে, যার মধ্যে API সক্রিয় করা, একটি ক্লাউড রিসোর্স সংযোগ তৈরি করা এবং ক্লাউড রিসোর্স সংযোগের জন্য পরিষেবা অ্যাকাউন্টকে নির্দিষ্ট অনুমতি প্রদান করা অন্তর্ভুক্ত। এই ধাপগুলো প্রতি প্রোজেক্টে একবারই করতে হয় এবং পরবর্তী কয়েকটি বিভাগে এগুলো আলোচনা করা হবে।
এপিআই সক্ষম করুন
ক্লাউড শেলের ভিতরে, নিশ্চিত করুন যে আপনার প্রজেক্ট আইডি সেটআপ করা আছে:
gcloud config set project [YOUR-PROJECT-ID]
পরিবেশ ভেরিয়েবল PROJECT_ID সেট করুন:
PROJECT_ID=$(gcloud config get-value project)
Vertex AI মডেলগুলির জন্য আপনার ডিফল্ট অঞ্চল কনফিগার করুন। Vertex AI-এর জন্য উপলব্ধ অবস্থানগুলি সম্পর্কে আরও পড়ুন। এই উদাহরণে আমরা us-central1 অঞ্চলটি ব্যবহার করছি।
gcloud config set compute/region us-central1
পরিবেশ ভেরিয়েবল REGION সেট করুন:
REGION=$(gcloud config get-value compute/region)
সকল প্রয়োজনীয় পরিষেবা সক্রিয় করুন:
gcloud services enable bigqueryconnection.googleapis.com \
aiplatform.googleapis.com
উপরের সমস্ত কমান্ড চালানোর পর প্রত্যাশিত আউটপুট:
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable bigqueryconnection.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
৪. একটি ক্লাউড রিসোর্স সংযোগ তৈরি করুন
এই টাস্কে, আপনি একটি ক্লাউড রিসোর্স কানেকশন তৈরি করবেন, যা BigQuery-কে ক্লাউড স্টোরেজে থাকা ইমেজ ফাইল অ্যাক্সেস করতে এবং Vertex AI-তে কল করতে সক্ষম করবে।
- গুগল ক্লাউড কনসোলে, নেভিগেশন মেনুতে (
 ), BigQuery-তে ক্লিক করুন।
), BigQuery-তে ক্লিক করুন।

- একটি সংযোগ তৈরি করতে, + ADD-এ ক্লিক করুন এবং তারপরে Connections to external data sources-এ ক্লিক করুন।
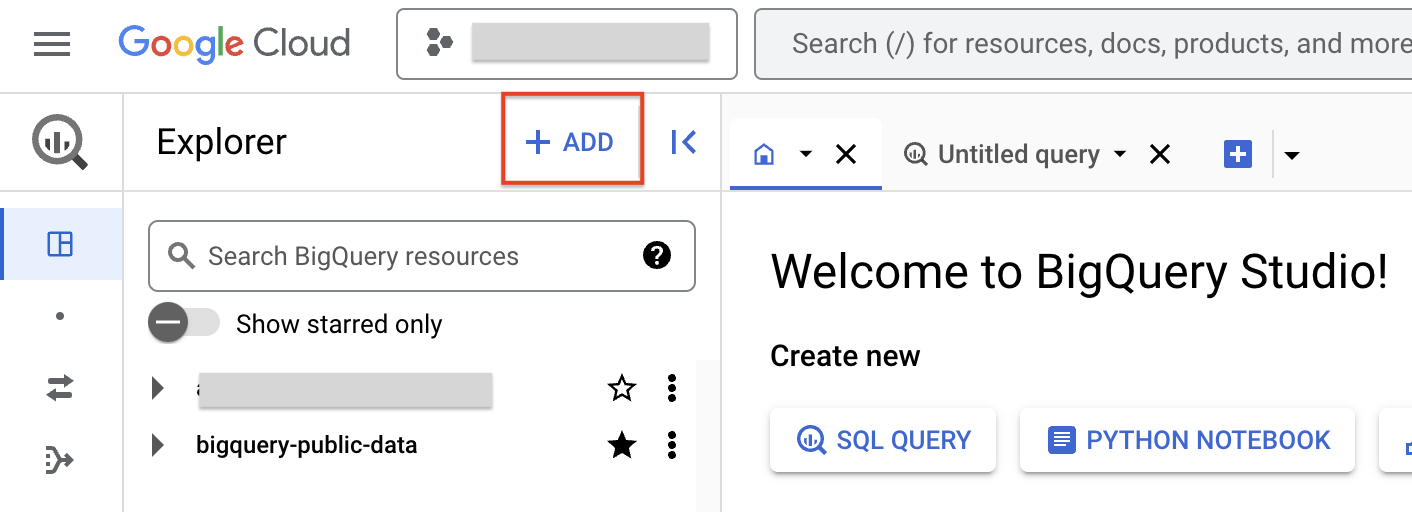
- কানেকশন টাইপ তালিকা থেকে ভার্টেক্স এআই রিমোট মডেল, রিমোট ফাংশন এবং বিগলেক (ক্লাউড রিসোর্স) নির্বাচন করুন।
- কানেকশন আইডি ফিল্ডে আপনার কানেকশনের জন্য gemini_conn লিখুন।
- অবস্থানের ধরণ হিসেবে মাল্টি-রিজিওন নির্বাচন করুন এবং তারপর ড্রপডাউন থেকে ইউএস মাল্টি-রিজিওন নির্বাচন করুন।
- Use the defaults for the other settings.
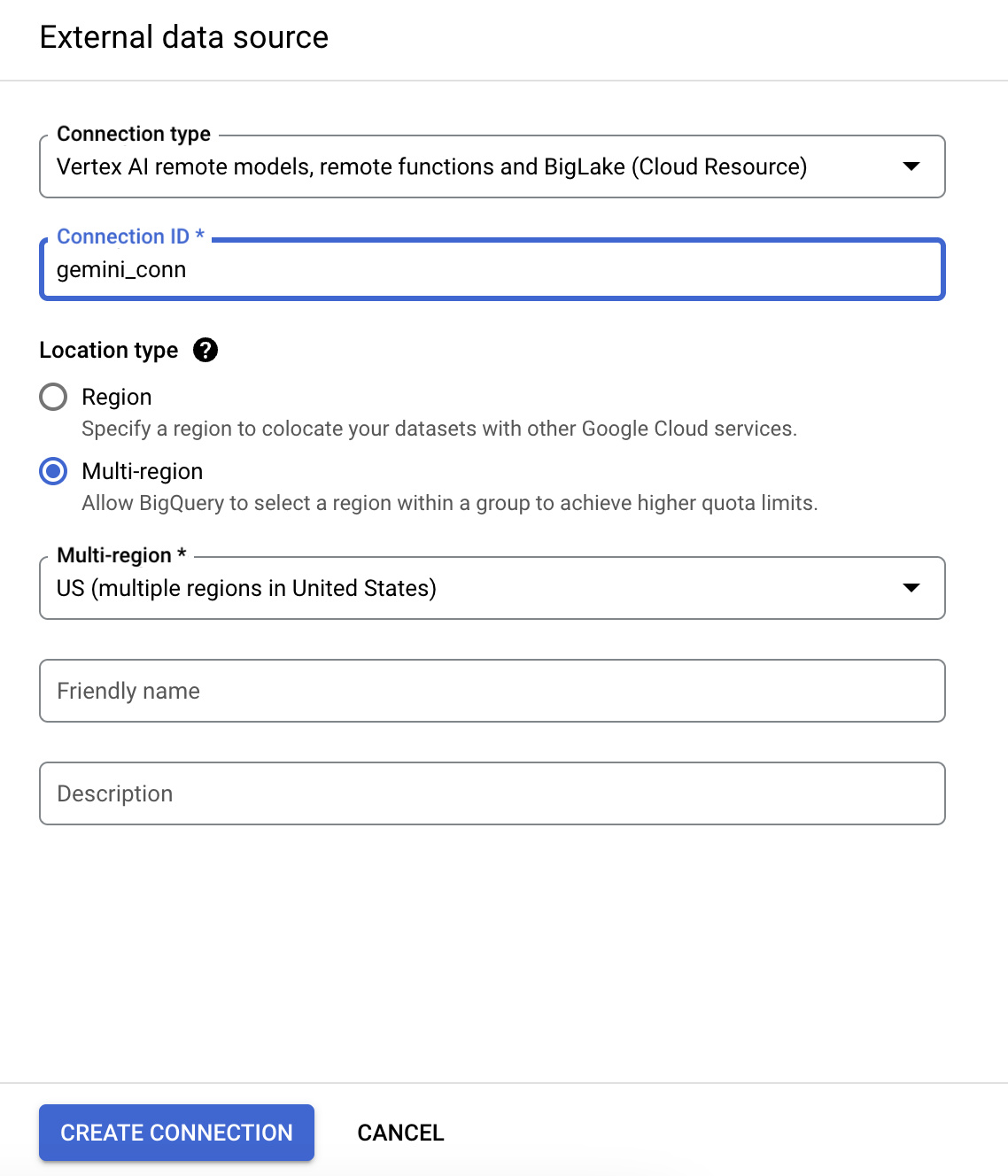
- সংযোগ তৈরি করুন -এ ক্লিক করুন।
- সংযোগে যান-এ ক্লিক করুন।
- কানেকশন ইনফো প্যানে, পরবর্তী কাজের জন্য সার্ভিস অ্যাকাউন্ট আইডিটি একটি টেক্সট ফাইলে কপি করুন। এছাড়াও আপনি BigQuery Explorer-এ আপনার প্রোজেক্টের এক্সটার্নাল কানেকশনস সেকশনের অধীনে কানেকশনটি যুক্ত হতে দেখবেন।
৫. কানেকশনের সার্ভিস অ্যাকাউন্টকে IAM অনুমতি প্রদান করুন।
এই টাস্কে, আপনি একটি রোলের মাধ্যমে ক্লাউড রিসোর্স কানেকশনের সার্ভিস অ্যাকাউন্টকে IAM পারমিশন প্রদান করেন, যাতে এটি ভার্টেক্স এআই সার্ভিসগুলো অ্যাক্সেস করতে পারে।
- Google Cloud কনসোলে, নেভিগেশন মেনুতে , IAM & Admin-এ ক্লিক করুন।
- অ্যাক্সেস মঞ্জুর করুন-এ ক্লিক করুন।
- 'New principals' ফিল্ডে, পূর্বে কপি করা সার্ভিস অ্যাকাউন্ট আইডিটি প্রবেশ করান।
- 'Select a role' ফিল্ডে Vertex AI লিখুন, এবং তারপর Vertex AI User role নির্বাচন করুন।
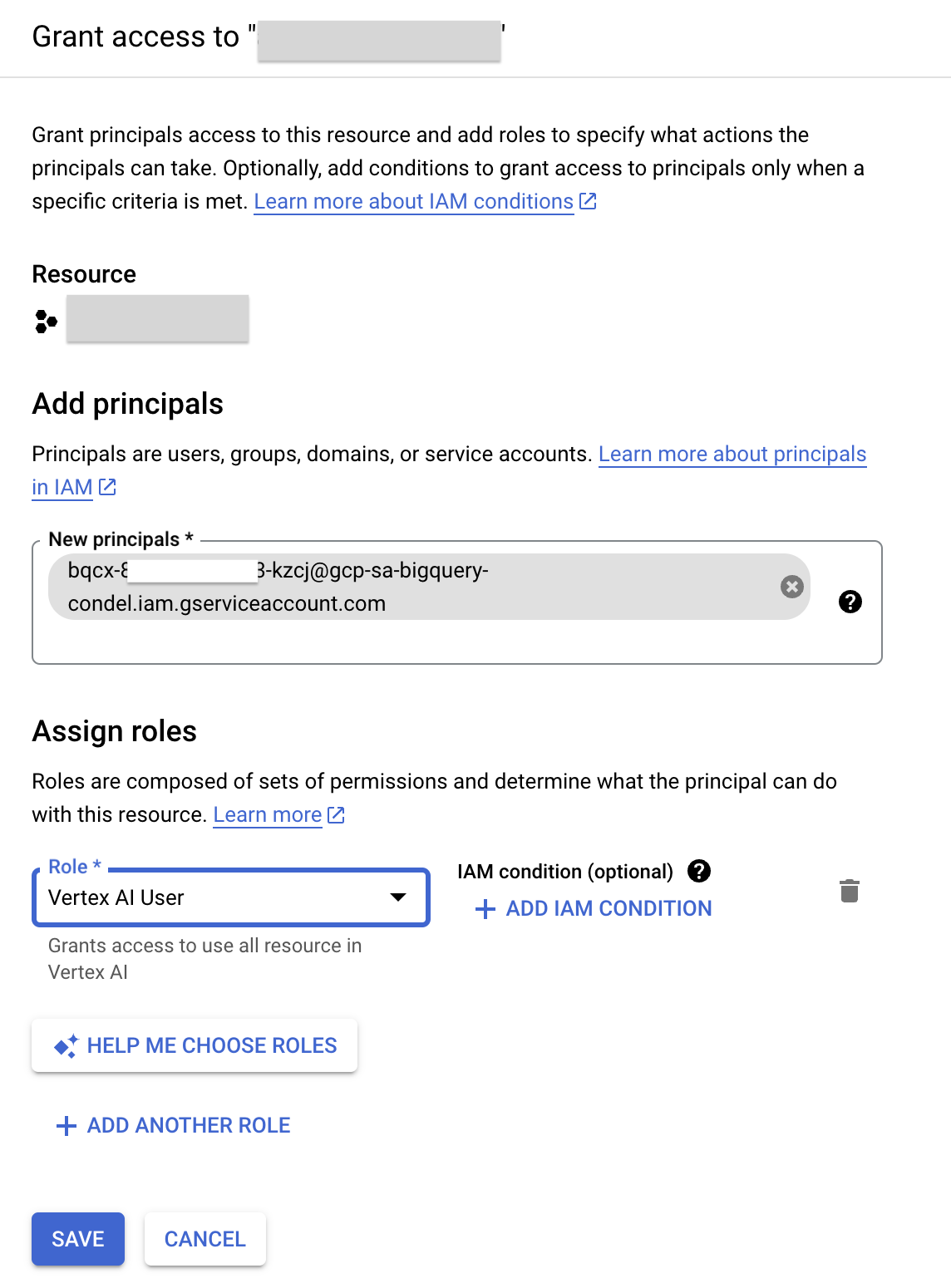
- সেভ-এ ক্লিক করুন। এর ফলে সার্ভিস অ্যাকাউন্ট আইডিতে এখন ভার্টেক্স এআই ইউজার রোলটি অন্তর্ভুক্ত হবে।
৬. বিগকোয়েরিতে সিনেমার পোস্টারের ছবিগুলোর জন্য ডেটাসেট এবং অবজেক্ট টেবিল তৈরি করুন।
এই টাস্কে, আপনাকে প্রজেক্টটির জন্য একটি ডেটাসেট এবং এর মধ্যে পোস্টারের ছবিগুলো সংরক্ষণের জন্য একটি অবজেক্ট টেবিল তৈরি করতে হবে।
এই টিউটোরিয়ালে ব্যবহৃত সিনেমার পোস্টারের ছবির ডেটাসেটটি একটি পাবলিক গুগল ক্লাউড স্টোরেজ বাকেটে সংরক্ষিত আছে: gs://cloud-samples-data/vertex-ai/dataset-management/datasets/classic-movie-posters
একটি ডেটাসেট তৈরি করুন
এই টিউটোরিয়ালে ব্যবহৃত টেবিল এবং মডেল সহ ডাটাবেস অবজেক্টগুলো সংরক্ষণের জন্য আপনি একটি ডেটা সেট তৈরি করবেন।
- Google Cloud কনসোলে, নেভিগেশন মেনু নির্বাচন করুন ( ), এবং তারপর BigQuery নির্বাচন করুন।
- এক্সপ্লোরার প্যানেলে, আপনার প্রোজেক্টের নামের পাশে, 'View actions' নির্বাচন করুন (
 ), এবং তারপর ডেটাসেট তৈরি করুন নির্বাচন করুন।
), এবং তারপর ডেটাসেট তৈরি করুন নির্বাচন করুন। - ডেটা সেট তৈরি করার প্যানে, নিম্নলিখিত তথ্যগুলো প্রবেশ করান:
- Dataset ID: gemini_demo
- অবস্থানের ধরণ: বহু-অঞ্চল নির্বাচন করুন
- বহু-অঞ্চল: মার্কিন যুক্তরাষ্ট্র নির্বাচন করুন
- অন্যান্য ফিল্ডগুলো ডিফল্ট অবস্থায় রাখুন।

- ডেটা সেট তৈরি করুন- এ ক্লিক করুন।
এর ফলে gemini_demo ডেটাসেটটি তৈরি হয় এবং BigQuery Explorer-এ আপনার প্রজেক্টের অধীনে তালিকাভুক্ত হয়।
অবজেক্ট টেবিল তৈরি করুন
BigQuery শুধু স্ট্রাকচার্ড ডেটাই ধারণ করে না, এটি অবজেক্ট টেবিলের মাধ্যমে আনস্ট্রাকচার্ড ডেটাও (যেমন পোস্টারের ছবি) অ্যাক্সেস করতে পারে।
আপনি একটি ক্লাউড স্টোরেজ বাকেট নির্দেশ করে একটি অবজেক্ট টেবিল তৈরি করেন, এবং ফলস্বরূপ তৈরি হওয়া অবজেক্ট টেবিলটিতে বাকেটটির প্রতিটি অবজেক্টের জন্য তার স্টোরেজ পাথ এবং মেটাডেটা সহ একটি করে সারি থাকে।
অবজেক্ট টেবিল তৈরি করতে আপনাকে একটি SQL কোয়েরি ব্যবহার করতে হবে।
- নতুন SQL কোয়েরি তৈরি করতে + চিহ্নে ক্লিক করুন।
- কোয়েরি এডিটরে নিচের কোয়েরিটি পেস্ট করুন।
CREATE OR REPLACE EXTERNAL TABLE
`gemini_demo.movie_posters`
WITH CONNECTION `us.gemini_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://cloud-samples-data/vertex-ai/dataset-management/datasets/classic-movie-posters/*']
);
- কোয়েরিটি চালান। এর ফলে
gemini_demoডেটাসেটে একটিmovie_postersঅবজেক্ট টেবিল যুক্ত হবে এবং প্রতিটি মুভি পোস্টার ইমেজেরURI(ক্লাউড স্টোরেজের অবস্থান) দিয়ে তা লোড করা হবে। - এক্সপ্লোরারে,
movie_postersএ ক্লিক করুন এবং স্কিমা ও বিবরণ পর্যালোচনা করুন। নির্দিষ্ট রেকর্ড পর্যালোচনা করার জন্য নির্দ্বিধায় টেবিলটি কোয়েরি করতে পারেন।
৭. BigQuery-তে Gemini রিমোট মডেল তৈরি করুন।
অবজেক্ট টেবিলটি তৈরি হয়ে গেলে, আপনি এটি নিয়ে কাজ শুরু করতে পারেন। এই টাস্কে, আপনি BigQuery-তে উপলব্ধ করার জন্য Gemini 1.5 Flash-এর একটি রিমোট মডেল তৈরি করবেন।
জেমিনি ১.৫ ফ্ল্যাশ রিমোট মডেলটি তৈরি করুন
- নতুন SQL কোয়েরি তৈরি করতে + চিহ্নে ক্লিক করুন।
- কোয়েরি এডিটরে নিচের কোয়েরিটি পেস্ট করে রান করুন।
CREATE OR REPLACE MODEL `gemini_demo.gemini_1_5_flash`
REMOTE WITH CONNECTION `us.gemini_conn`
OPTIONS (endpoint = 'gemini-1.5-flash')
এর ফলে gemini_1_5_flash মডেলটি তৈরি হয় এবং আপনি এটিকে gemini_demo ডেটাসেটের models সেকশনে যুক্ত হতে দেখবেন।
- এক্সপ্লোরারে
gemini_1_5_flashমডেলটিতে ক্লিক করুন এবং এর বিবরণ পর্যালোচনা করুন।
৮. জেমিনি মডেলকে প্রতিটি পোস্টারের জন্য চলচ্চিত্রের সারাংশ প্রদান করতে বলুন।
এই টাস্কে, আপনি এইমাত্র তৈরি করা জেমিনি রিমোট মডেলটি ব্যবহার করে সিনেমার পোস্টারের ছবিগুলো বিশ্লেষণ করবেন এবং প্রতিটি সিনেমার জন্য সারসংক্ষেপ তৈরি করবেন।
আপনি প্যারামিটারে মডেলটিকে উল্লেখ করে ML.GENERATE_TEXT ফাংশনটি ব্যবহার করে মডেলে অনুরোধ পাঠাতে পারেন।
জেমিনি ১.৫ ফ্ল্যাশ মডেল দিয়ে ছবিগুলো বিশ্লেষণ করুন।
- নিম্নলিখিত SQL স্টেটমেন্ট ব্যবহার করে একটি নতুন কোয়েরি তৈরি করুন এবং চালান:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results` AS (
SELECT
uri,
ml_generate_text_llm_result
FROM
ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_1_5_flash`,
TABLE `gemini_demo.movie_posters`,
STRUCT( 0.2 AS temperature,
'For the movie represented by this poster, what is the movie title and year of release? Answer in JSON format with two keys: title, year. title should be string, year should be integer. Do not use JSON decorators.' AS PROMPT,
TRUE AS FLATTEN_JSON_OUTPUT)));
যখন কোয়েরিটি চলে, BigQuery অবজেক্ট টেবিলের প্রতিটি সারির জন্য Gemini মডেলকে প্রম্পট করে এবং ছবিটিকে নির্দিষ্ট স্ট্যাটিক প্রম্পটের সাথে একত্রিত করে। এর ফলে movie_posters_results টেবিলটি তৈরি হয়।
- এবার ফলাফলগুলো দেখা যাক। নিচের SQL স্টেটমেন্টটি ব্যবহার করে একটি নতুন কোয়েরি তৈরি করুন এবং চালান:
SELECT * FROM `gemini_demo.movie_posters_results`
জেমিনি ১.৫ ফ্ল্যাশ মডেল থেকে প্রাপ্ত ফলাফলে প্রতিটি মুভি পোস্টারের জন্য আলাদা সারি থাকে, যেখানে URI (মুভি পোস্টার ইমেজটির ক্লাউড স্টোরেজ লোকেশন) এবং একটি JSON ফলাফল অন্তর্ভুক্ত থাকে, যাতে সিনেমার শিরোনাম এবং মুক্তির বছরটি থাকে।
পরবর্তী কোয়েরিটি ব্যবহার করে আপনি এই ফলাফলগুলো আরও সহজে পাঠযোগ্য উপায়ে পেতে পারেন। এই কোয়েরিটি SQL ব্যবহার করে প্রাপ্ত রেসপন্সগুলো থেকে সিনেমার নাম এবং মুক্তির বছর বের করে নতুন কলামে নিয়ে আসে।
- নিম্নলিখিত SQL স্টেটমেন্ট ব্যবহার করে একটি নতুন কোয়েরি তৈরি করুন এবং চালান:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results_formatted` AS (
SELECT
uri,
JSON_VALUE(ml_generate_text_llm_result, "$.title") AS title,
JSON_VALUE(ml_generate_text_llm_result, "$.year") AS year
FROM
`gemini_demo.movie_posters_results` results )
এর ফলে movie_posters_result_formatted টেবিলটি তৈরি হয়।
- তৈরি হওয়া সারিগুলো দেখতে, আপনি নিচের কোয়েরিটি ব্যবহার করে টেবিলটি কোয়েরি করতে পারেন।
SELECT * FROM `gemini_demo.movie_posters_results_formatted`
লক্ষ্য করুন, URI কলামের ফলাফল একই থাকছে, কিন্তু JSON এখন প্রতিটি সারির জন্য title এবং year কলামে রূপান্তরিত হয়েছে।
চলচ্চিত্রের সারাংশ প্রদানের জন্য প্রম্পট জেমিনি ১.৫ ফ্ল্যাশ মডেল
ধরুন, আপনি এই সিনেমাগুলোর প্রত্যেকটি সম্পর্কে আরও কিছু তথ্য চান, যেমন প্রতিটি সিনেমার একটি টেক্সট সারাংশ? এই ধরনের কন্টেন্ট তৈরির ক্ষেত্রটি জেমিনি ১.৫ ফ্ল্যাশ মডেলের মতো একটি এলএলএম মডেলের জন্য একদম উপযুক্ত।
- নিচের কোয়েরিটি চালিয়ে আপনি জেমিনি ১.৫ ফ্ল্যাশ ব্যবহার করে প্রতিটি পোস্টারের জন্য সিনেমার সারাংশ প্রদান করতে পারেন:
SELECT
uri,
title,
year,
prompt,
ml_generate_text_llm_result
FROM
ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_1_5_flash`,
(
SELECT
CONCAT('Provide a short summary of movie titled ',title, ' from the year ',year,'.') AS prompt,
uri,
title,
year
FROM
`gemini_demo.movie_posters_results_formatted`
LIMIT
20 ),
STRUCT(0.2 AS temperature,
TRUE AS FLATTEN_JSON_OUTPUT));
ফলাফলের ml_generate_text_llm_result ফিল্ডটি লক্ষ্য করুন; এতে সিনেমাটির একটি সংক্ষিপ্ত সারাংশ রয়েছে।
৯. একটি রিমোট মডেল ব্যবহার করে টেক্সট এমবেডিং তৈরি করুন
এখন আপনি আপনার তৈরি করা স্ট্রাকচার্ড ডেটা আপনার ডেটা ওয়্যারহাউসের অন্যান্য স্ট্রাকচার্ড ডেটার সাথে যুক্ত করতে পারেন। BigQuery-তে উপলব্ধ IMDB পাবলিক ডেটাসেটে সিনেমা সম্পর্কে প্রচুর তথ্য রয়েছে, যার মধ্যে দর্শকদের দেওয়া রেটিং এবং কিছু নমুনা ফ্রিফর্ম ব্যবহারকারী রিভিউও অন্তর্ভুক্ত। এই ডেটা আপনাকে সিনেমার পোস্টারগুলির বিশ্লেষণ আরও গভীর করতে এবং এই সিনেমাগুলি কীভাবে গৃহীত হয়েছিল তা বুঝতে সাহায্য করতে পারে।
ডেটা যুক্ত করার জন্য আপনার একটি কী (key) প্রয়োজন হবে। এক্ষেত্রে, জেমিনি মডেল দ্বারা তৈরি সিনেমার শিরোনামগুলো আইএমডিবি ডেটাসেটের শিরোনামগুলোর সাথে হুবহু নাও মিলতে পারে।
এই টাস্কে, আপনি উভয় ডেটাসেট থেকে সিনেমার শিরোনাম এবং বছরের টেক্সট এমবেডিং তৈরি করবেন এবং তারপর এই এমবেডিংগুলোর মধ্যকার দূরত্ব ব্যবহার করে আপনার নতুন তৈরি করা ডেটাসেটের সিনেমার পোস্টারের শিরোনামগুলোর সাথে সবচেয়ে কাছের IMDB শিরোনামটিকে যুক্ত করবেন।
রিমোট মডেল তৈরি করুন
টেক্সট এমবেডিংগুলো তৈরি করতে, আপনাকে text-multilingual-embedding-002 এন্ডপয়েন্টটির দিকে নির্দেশ করে একটি নতুন রিমোট মডেল তৈরি করতে হবে।
- নিম্নলিখিত SQL স্টেটমেন্ট ব্যবহার করে একটি নতুন কোয়েরি তৈরি করুন এবং চালান:
CREATE OR REPLACE MODEL `gemini_demo.text_embedding`
REMOTE WITH CONNECTION `us.gemini_conn`
OPTIONS (endpoint = 'text-multilingual-embedding-002')
এর ফলে text_embedding মডেলটি তৈরি হয় এবং এক্সপ্লোরারে gemini_demo ডেটাসেটের নিচে প্রদর্শিত হয়।
পোস্টারগুলির সাথে সম্পর্কিত শিরোনাম এবং বছরের জন্য টেক্সট এমবেডিং তৈরি করুন।
এখন আপনি এই রিমোট মডেলটি ব্যবহার করে ML.GENERATE_EMBEDDING ফাংশনের মাধ্যমে প্রতিটি সিনেমার পোস্টারের শিরোনাম ও বছরের জন্য একটি এমবেডিং তৈরি করবেন।
- নিম্নলিখিত SQL স্টেটমেন্ট ব্যবহার করে একটি নতুন কোয়েরি তৈরি করুন এবং চালান:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results_embeddings` AS (
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
MODEL `gemini_demo.text_embedding`,
(
SELECT
CONCAT('The movie titled ', title, ' from the year ', year,'.') AS content,
title,
year,
uri
FROM
`gemini_demo.movie_posters_results_formatted` ),
STRUCT(TRUE AS flatten_json_output)));
এর ফলে movie_poster_results_embeddings নামের একটি টেবিল তৈরি হয়, যেখানে gemini_demo.movie_posters_results_formatted টেবিলের প্রতিটি সারির জন্য সংযুক্ত টেক্সট কন্টেন্টের এমবেডিংগুলো থাকে।
- নিচের নতুন কোয়েরিটি ব্যবহার করে আপনি কোয়েরিটির ফলাফল দেখতে পারেন:
SELECT * FROM `gemini_demo.movie_posters_results_embeddings`
এখানে আপনি মডেল দ্বারা তৈরি প্রতিটি চলচ্চিত্রের এমবেডিংগুলো (সংখ্যা দ্বারা উপস্থাপিত ভেক্টর) দেখতে পাচ্ছেন।
IMDB ডেটাসেটের একটি উপসেটের জন্য টেক্সট এমবেডিং তৈরি করুন।
আপনি একটি পাবলিক আইএমডিবি ডেটাসেট থেকে ডেটার একটি নতুন ভিউ তৈরি করবেন, যেটিতে শুধুমাত্র ১৯৩৫ সালের আগে মুক্তিপ্রাপ্ত চলচ্চিত্রগুলো রয়েছে (পোস্টারের ছবি থেকে চলচ্চিত্রগুলোর এই সময়কালটিই জানা যায়)।
- নিম্নলিখিত SQL স্টেটমেন্ট ব্যবহার করে একটি নতুন কোয়েরি তৈরি করুন এবং চালান:
CREATE OR REPLACE VIEW
`gemini_demo.imdb_movies` AS (
WITH
reviews AS (
SELECT
reviews.movie_id AS movie_id,
title.primary_title AS title,
title.start_year AS year,
reviews.review AS review
FROM
`bigquery-public-data.imdb.reviews` reviews
LEFT JOIN
`bigquery-public-data.imdb.title_basics` title
ON
reviews.movie_id = title.tconst)
SELECT
DISTINCT(movie_id),
title,
year
FROM
reviews
WHERE
year < 1935)
এর ফলে একটি নতুন ভিউ তৈরি হয়, যেখানে ডেটাসেটের ১৯৩৫ সালের আগে মুক্তিপ্রাপ্ত সমস্ত সিনেমার জন্য bigquery-public-data.imdb.reviews টেবিল থেকে নেওয়া স্বতন্ত্র মুভি আইডি, শিরোনাম এবং মুক্তির বছরের একটি তালিকা থাকে।
- এখন আপনি পূর্ববর্তী অংশের অনুরূপ প্রক্রিয়া ব্যবহার করে IMDB থেকে সিনেমার উপসেটের জন্য এমবেডিং তৈরি করবেন। নিম্নলিখিত SQL স্টেটমেন্ট সহ একটি নতুন কোয়েরি তৈরি করুন এবং চালান:
CREATE OR REPLACE TABLE
`gemini_demo.imdb_movies_embeddings` AS (
SELECT
*
FROM
ML.GENERATE_EMBEDDING( MODEL `gemini_demo.text_embedding`,
(
SELECT
CONCAT('The movie titled ', title, ' from the year ', year,'.') AS content,
title,
year,
movie_id
FROM
`gemini_demo.imdb_movies` ),
STRUCT(TRUE AS flatten_json_output) )
WHERE
ml_generate_embedding_status = '' );
কোয়েরিটির ফলাফল হলো একটি টেবিল, যেটিতে gemini_demo.imdb_movies টেবিলের টেক্সট কন্টেন্টের এমবেডিংগুলো থাকে।
BigQuery VECTOR_SEARCH ব্যবহার করে সিনেমার পোস্টারের ছবিগুলোকে IMDB movie_id সাথে মেলান।
এখন, আপনি VECTOR_SEARCH ফাংশন ব্যবহার করে টেবিল দুটিকে যুক্ত করতে পারেন।
- নিম্নলিখিত SQL স্টেটমেন্ট ব্যবহার করে একটি নতুন কোয়েরি তৈরি করুন এবং চালান:
SELECT
query.uri AS poster_uri,
query.title AS poster_title,
query.year AS poster_year,
base.title AS imdb_title,
base.year AS imdb_year,
base.movie_id AS imdb_movie_id,
distance
FROM
VECTOR_SEARCH( TABLE `gemini_demo.imdb_movies_embeddings`,
'ml_generate_embedding_result',
TABLE `gemini_demo.movie_posters_results_embeddings`,
'ml_generate_embedding_result',
top_k => 1,
distance_type => 'COSINE');
কোয়েরিটি gemini_demo.movie_posters_results_embeddings টেবিলের প্রতিটি সারির জন্য gemini_demo.imdb_movies_embeddings টেবিলে নিকটতম প্রতিবেশী খুঁজে বের করতে VECTOR_SEARCH ফাংশন ব্যবহার করে। নিকটতম প্রতিবেশীটি কোসাইন ডিসটেন্স মেট্রিক ব্যবহার করে খুঁজে বের করা হয়, যা দুটি এমবেডিং কতটা সাদৃশ্যপূর্ণ তা নির্ধারণ করে।
জেমিনি ১.৫ ফ্ল্যাশ দ্বারা মুভি পোস্টারে চিহ্নিত প্রতিটি সিনেমার জন্য আইএমডিবি ডেটাসেটে সবচেয়ে সাদৃশ্যপূর্ণ সিনেমাটি খুঁজে বের করতে এই কোয়েরিটি ব্যবহার করা যেতে পারে। উদাহরণস্বরূপ, আপনি আইএমডিবি পাবলিক ডেটাসেটে "Au Secours!" সিনেমার জন্য সবচেয়ে কাছের মিল খুঁজে পেতে এই কোয়েরিটি ব্যবহার করতে পারেন, যেখানে সিনেমাটিকে এর ইংরেজি শিরোনাম "Help!" দ্বারা উল্লেখ করা হয়েছে।
- IMDB পাবলিক ডেটাসেটে প্রদত্ত সিনেমার রেটিং সম্পর্কিত কিছু অতিরিক্ত তথ্য যুক্ত করতে একটি নতুন কোয়েরি তৈরি করে চালান:
SELECT
query.uri AS poster_uri,
query.title AS poster_title,
query.year AS poster_year,
base.title AS imdb_title,
base.year AS imdb_year,
base.movie_id AS imdb_movie_id,
distance,
imdb.average_rating,
imdb.num_votes
FROM
VECTOR_SEARCH( TABLE `gemini_demo.imdb_movies_embeddings`,
'ml_generate_embedding_result',
TABLE `gemini_demo.movie_posters_results_embeddings`,
'ml_generate_embedding_result',
top_k => 1,
distance_type => 'COSINE') DATA
LEFT JOIN
`bigquery-public-data.imdb.title_ratings` imdb
ON
base.movie_id = imdb.tconst
ORDER BY
imdb.average_rating DESC
এই কোয়েরিটি আগের কোয়েরিটির মতোই। এটিও একটি প্রদত্ত মুভি পোস্টারের অনুরূপ মুভি খুঁজে বের করার জন্য ভেক্টর এমবেডিং নামক বিশেষ সাংখ্যিক উপস্থাপনা ব্যবহার করে। তবে, এটি IMDB পাবলিক ডেটাসেটের একটি পৃথক টেবিল থেকে প্রতিটি নিকটতম প্রতিবেশী মুভির গড় রেটিং এবং ভোটের সংখ্যাও যুক্ত করে।
১০. অভিনন্দন
কোডল্যাবটি সফলভাবে সম্পন্ন করার জন্য অভিনন্দন। আপনি BigQuery-তে আপনার পোস্টার ইমেজগুলোর জন্য সফলভাবে একটি অবজেক্ট টেবিল তৈরি করেছেন, একটি রিমোট Gemini মডেল তৈরি করেছেন, সেই মডেলটি ব্যবহার করে ইমেজ ও প্রদত্ত মুভির সারাংশ বিশ্লেষণ করেছেন, মুভির শিরোনামের জন্য টেক্সট এমবেডিং তৈরি করেছেন এবং সেই এমবেডিংগুলো ব্যবহার করে IMDB ডেটাসেটে থাকা সংশ্লিষ্ট মুভির শিরোনামের সাথে মুভি পোস্টারের ইমেজগুলো মিলিয়েছেন।
আমরা যা আলোচনা করেছি
- এপিআই ব্যবহার করার জন্য আপনার পরিবেশ এবং অ্যাকাউন্ট কীভাবে কনফিগার করবেন
- BigQuery-তে কীভাবে ক্লাউড রিসোর্স সংযোগ তৈরি করবেন
- বিগকোয়েরিতে মুভি পোস্টার ইমেজের জন্য ডেটাসেট এবং অবজেক্ট টেবিল কীভাবে তৈরি করবেন
- BigQuery-তে Gemini রিমোট মডেলগুলি কীভাবে তৈরি করবেন
- প্রতিটি পোস্টারের জন্য সিনেমার সারাংশ সরবরাহ করতে জেমিনি মডেলকে কীভাবে নির্দেশ দেবেন
- প্রতিটি পোস্টারে প্রদর্শিত সিনেমার জন্য কীভাবে টেক্সট এমবেডিং তৈরি করবেন
- ডেটা সেটে থাকা সিনেমার পোস্টারের ছবির সাথে ঘনিষ্ঠভাবে সম্পর্কিত সিনেমাগুলো মেলানোর জন্য BigQuery
VECTOR_SEARCHকীভাবে ব্যবহার করবেন
পরবর্তী পদক্ষেপ / আরও জানুন