
1. Introduction
Bonjour ! Vous aimez l'idée des agents, ces petits assistants qui peuvent faire des choses pour vous sans que vous ayez à lever le petit doigt, n'est-ce pas ? Formidable ! Mais soyons réalistes : un seul agent ne suffit pas toujours, surtout lorsque vous vous attaquez à des projets plus importants et plus complexes. Vous aurez probablement besoin de toute une équipe ! C'est là que les systèmes multi-agents entrent en jeu.
Les agents, lorsqu'ils sont optimisés par des LLM, vous offrent une flexibilité incroyable par rapport à l'ancien codage en dur. Mais, et il y a toujours un "mais", elles présentent des défis complexes. C'est exactement ce que nous allons aborder dans cet atelier.

Voici ce que vous pouvez vous attendre à apprendre (pensez-y comme à une amélioration de votre jeu d'agent) :
Créer votre premier agent avec LangGraph : nous allons nous salir les mains en créant votre propre agent à l'aide de LangGraph, un framework populaire. Vous apprendrez à créer des outils qui se connectent à des bases de données, à exploiter la dernière API Gemini 2 pour effectuer des recherches sur Internet et à optimiser les requêtes et les réponses. Votre agent pourra ainsi interagir non seulement avec les LLM, mais aussi avec les services existants. Nous vous montrerons également comment fonctionne l'appel de fonction.
Orchestration d'agents, à votre façon : nous allons explorer différentes façons d'orchestrer vos agents, des chemins simples et directs aux scénarios multipath plus complexes. Considérez-le comme le chef d'orchestre de votre équipe d'agents.
Systèmes multi-agents : vous découvrirez comment configurer un système dans lequel vos agents peuvent collaborer et accomplir des tâches ensemble, le tout grâce à une architecture événementielle.
Liberté des LLM : utilisez le meilleur outil pour chaque tâche. Nous ne sommes pas limités à un seul LLM ! Vous découvrirez comment utiliser plusieurs LLM en leur attribuant différents rôles pour améliorer la résolution de problèmes à l'aide de "modèles de pensée" intéressants.
Contenu dynamique ? Pas de problème ! : Imaginez votre agent créant du contenu dynamique adapté spécifiquement à chaque utilisateur, en temps réel. Nous allons vous montrer comment faire.
Passer au cloud avec Google Cloud : oubliez les simples manipulations dans un notebook. Nous vous montrerons comment concevoir et déployer votre système multi-agent sur Google Cloud pour qu'il soit prêt à être utilisé dans le monde réel.
Ce projet sera un bon exemple de la façon d'utiliser toutes les techniques dont nous avons parlé.
2. Architecture
Être enseignant ou travailler dans le secteur de l'éducation peut être très gratifiant, mais soyons honnêtes, la charge de travail, en particulier tout le travail de préparation, peut être difficile ! De plus, le personnel est souvent insuffisant et les cours particuliers peuvent être coûteux. C'est pourquoi nous proposons un assistant d'enseignement basé sur l'IA. Cet outil peut alléger la charge de travail des enseignants et combler le manque de personnel et de tutorat abordable.
Notre assistant pédagogique IA peut générer des plans de cours détaillés, des quiz amusants, des résumés audio faciles à suivre et des devoirs personnalisés. Les enseignants peuvent ainsi se concentrer sur ce qu'ils font de mieux : échanger avec les élèves et les aider à aimer apprendre.
Le système comporte deux sites : l'un permet aux enseignants de créer des plans de cours pour les semaines à venir,

et un autre pour que les élèves puissent accéder aux quiz, aux résumés audio et aux devoirs. 
Très bien, examinons l'architecture qui alimente notre assistant pédagogique, Aidemy. Comme vous pouvez le voir, nous l'avons décomposé en plusieurs composants clés qui fonctionnent tous ensemble pour y parvenir.

Principaux éléments et technologies de l'architecture :
Google Cloud Platform (GCP) : élément central de l'ensemble du système :
- Vertex AI : accède aux LLM Gemini de Google.
- Cloud Run : plate-forme sans serveur permettant de déployer des agents et des fonctions conteneurisés.
- Cloud SQL : base de données PostgreSQL pour les données du programme.
- Pub/Sub et Eventarc : base de l'architecture basée sur les événements, qui permet la communication asynchrone entre les composants.
- Cloud Storage : stocke les résumés audio et les fichiers de devoirs.
- Secret Manager : gère de manière sécurisée les identifiants de base de données.
- Artifact Registry : stocke les images Docker pour les agents.
- Compute Engine : pour déployer un LLM auto-hébergé au lieu de s'appuyer sur des solutions de fournisseurs
LLM : le "cerveau" du système :
- Modèles Gemini de Google : (Gemini x Pro, Gemini x Flash, Gemini x Flash Thinking) utilisés pour la planification des cours, la génération de contenu, la création de HTML dynamique, l'explication des quiz et la combinaison des devoirs.
- DeepSeek : utilisé pour la tâche spécialisée de génération de devoirs d'autoformation
LangChain et LangGraph : frameworks pour le développement d'applications LLM
- Facilite la création de workflows multi-agents complexes.
- Permet l'orchestration intelligente des outils (appels d'API, requêtes de base de données, recherches sur le Web).
- Implémente une architecture basée sur des événements pour l'évolutivité et la flexibilité du système.
En substance, notre architecture combine la puissance des LLM avec des données structurées et une communication basée sur les événements, le tout fonctionnant sur Google Cloud. Cela nous permet de créer un assistant pédagogique évolutif, fiable et efficace.
3. Avant de commencer
Dans la console Google Cloud, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud. Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
Activer Gemini Code Assist dans Cloud Shell IDE
👉 Dans la console Google Cloud, accédez aux outils Gemini Code Assist, puis activez Gemini Code Assist sans frais en acceptant les conditions d'utilisation.
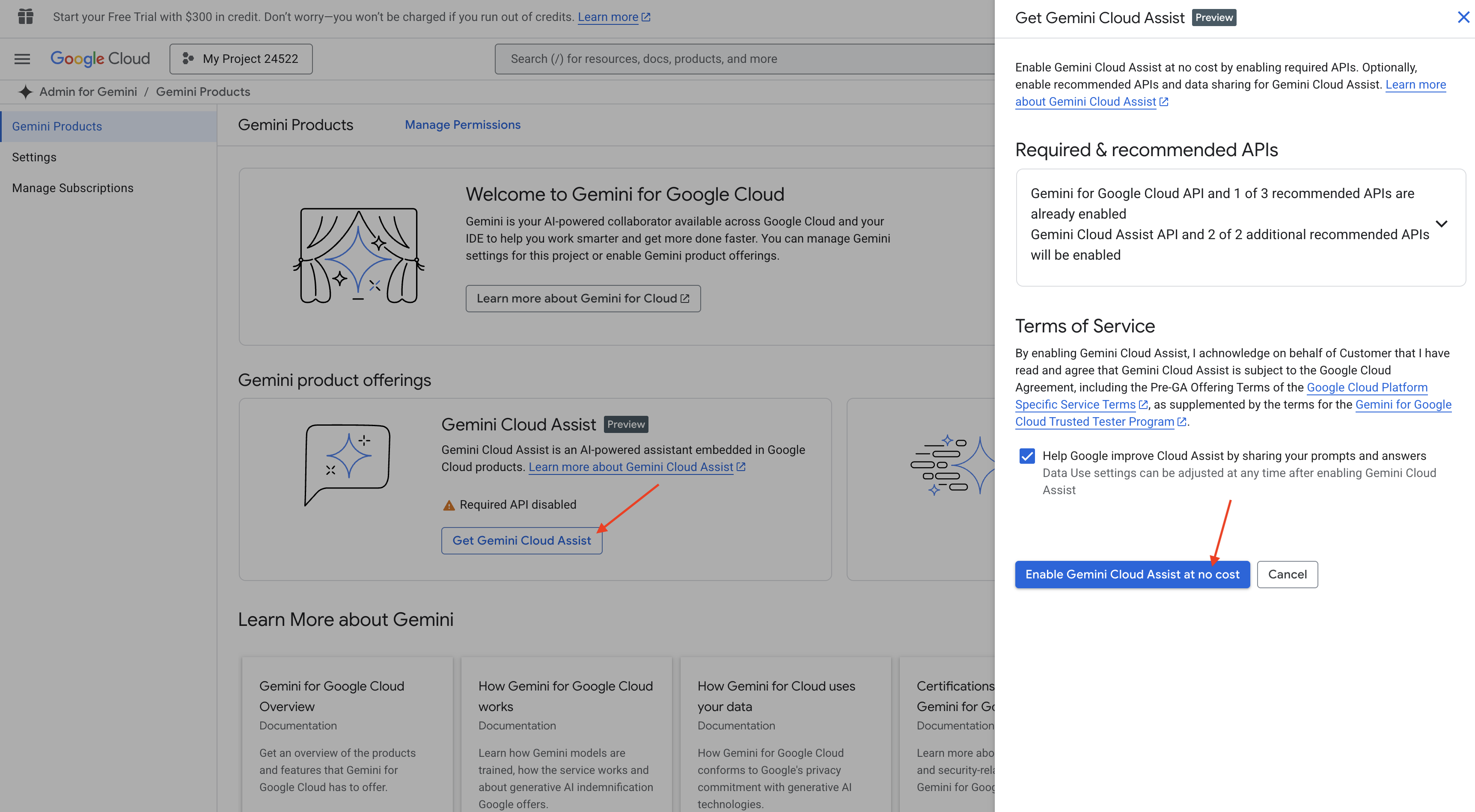
Ignorez la configuration des autorisations et quittez cette page.
Travailler dans l'éditeur Cloud Shell
👉 Cliquez sur Activer Cloud Shell en haut de la console Google Cloud (icône en forme de terminal en haut du volet Cloud Shell), puis sur le bouton Ouvrir l'éditeur (icône en forme de dossier ouvert avec un crayon). L'éditeur de code Cloud Shell s'ouvre dans la fenêtre. Un explorateur de fichiers s'affiche sur la gauche.

👉 Cliquez sur le bouton Cloud Code – Se connecter dans la barre d'état inférieure (voir ci-dessous). Autorisez le plug-in comme indiqué. Si Cloud Code – Aucun projet est affiché dans la barre d'état, cliquez dessus. Dans le menu déroulant "Sélectionner un projet Google Cloud", sélectionnez le projet Google Cloud que vous avez créé.

👉 Ouvrez le terminal dans l'IDE cloud,  ou
ou  .
.
👉 Dans le terminal, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
👉 Exécutez la commande en veillant à remplacer <YOUR_PROJECT_ID> par l'ID de votre projet :
echo <YOUR_PROJECT_ID> > ~/project_id.txt
gcloud config set project $(cat ~/project_id.txt)
👉 Exécutez la commande suivante pour activer les API Google Cloud nécessaires :
gcloud services enable compute.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
sqladmin.googleapis.com \
secretmanager.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudfunctions.googleapis.com \
cloudaicompanion.googleapis.com
Cette opération peut prendre quelques minutes.
Configurer les autorisations
👉 Configurez les autorisations du compte de service. Dans le terminal, exécutez la commande suivante :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
echo "Here's your SERVICE_ACCOUNT_NAME $SERVICE_ACCOUNT_NAME"
👉 Accorder des autorisations. Dans le terminal, exécutez la commande suivante :
#Cloud Storage (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.objectAdmin"
#Pub/Sub (Publish/Receive):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.publisher"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.subscriber"
#Cloud SQL (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.editor"
#Eventarc (Receive Events):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountTokenCreator"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/eventarc.eventReceiver"
#Vertex AI (User):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
#Secret Manager (Read):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/secretmanager.secretAccessor"
👉 Validez le résultat dans votre console IAM.
👉 Exécutez les commandes suivantes dans le terminal pour créer une instance Cloud SQL nommée aidemy. Nous en aurons besoin plus tard, mais comme ce processus peut prendre un certain temps, nous allons le faire maintenant.
gcloud sql instances create aidemy \
--database-version=POSTGRES_14 \
--cpu=2 \
--memory=4GB \
--region=us-central1 \
--root-password=1234qwer \
--storage-size=10GB \
--storage-auto-increase
4. Créer le premier agent
Avant de nous plonger dans les systèmes multi-agents complexes, nous devons établir un bloc de construction fondamental : un agent unique et fonctionnel. Dans cette section, nous allons commencer par créer un agent simple de "fournisseur de livres". L'agent fournisseur de livres prend une catégorie en entrée et utilise un LLM Gemini pour générer une représentation JSON d'un livre dans cette catégorie. Il diffuse ensuite ces recommandations de livres en tant que point de terminaison d'API REST .

👉 Dans un autre onglet de navigateur, ouvrez la console Google Cloud dans votre navigateur Web. Dans le menu de navigation (☰), accédez à "Cloud Run". Cliquez sur le bouton "+ … ÉCRIRE UNE FONCTION".

👉 Nous allons ensuite configurer les paramètres de base de la fonction Cloud Run :
- Nom du service :
book-provider - Région :
us-central1 - Environnement d'exécution :
Python 3.12 - Authentification : définissez
Allow unauthenticated invocationssur "Activée".
👉 Conservez les autres paramètres par défaut, puis cliquez sur Créer. Vous êtes redirigé vers l'éditeur de code source.
Vous verrez des fichiers main.py et requirements.txt préremplis.
main.py contiendra la logique métier de la fonction, et requirements.txt contiendra les packages nécessaires.
👉 Nous sommes maintenant prêts à écrire du code ! Mais avant de nous lancer, voyons si Gemini Code Assist peut nous donner un coup de pouce. Revenez à l'éditeur Cloud Shell, puis cliquez sur l'icône Gemini Code Assist en haut de l'écran pour ouvrir le chat Gemini Code Assist.

👉 Collez la requête suivante dans le champ de requête :
Use the functions_framework library to be deployable as an HTTP function.
Accept a request with category and number_of_book parameters (either in JSON body or query string).
Use langchain and gemini to generate the data for book with fields bookname, author, publisher, publishing_date.
Use pydantic to define a Book model with the fields: bookname (string, description: "Name of the book"), author (string, description: "Name of the author"), publisher (string, description: "Name of the publisher"), and publishing_date (string, description: "Date of publishing").
Use langchain and gemini model to generate book data. the output should follow the format defined in Book model.
The logic should use JsonOutputParser from langchain to enforce output format defined in Book Model.
Have a function get_recommended_books(category) that internally uses langchain and gemini to return a single book object.
The main function, exposed as the Cloud Function, should call get_recommended_books() multiple times (based on number_of_book) and return a JSON list of the generated book objects.
Handle the case where category or number_of_book are missing by returning an error JSON response with a 400 status code.
return a JSON string representing the recommended books. use os library to retrieve GOOGLE_CLOUD_PROJECT env var. Use ChatVertexAI from langchain for the LLM call
Code Assist génère ensuite une solution potentielle, en fournissant à la fois le code source et un fichier de dépendances requirements.txt. (NE PAS UTILISER CE CODE)
Nous vous encourageons à comparer le code généré par l'assistance au code avec la solution testée et correcte fournie ci-dessous. Cela vous permet d'évaluer l'efficacité de l'outil et d'identifier les éventuelles incohérences. Bien qu'il ne faille jamais faire aveuglément confiance aux LLM, Code Assist peut être un excellent outil pour le prototypage rapide et la génération de structures de code initiales. Il doit être utilisé pour prendre un bon départ.
Comme il s'agit d'un atelier, nous allons utiliser le code validé fourni ci-dessous. Toutefois, n'hésitez pas à tester le code généré par Code Assist à votre rythme pour mieux comprendre ses capacités et ses limites.
👉 Revenez à l'éditeur de code source de la fonction Cloud Run (dans l'autre onglet du navigateur). Remplacez soigneusement le contenu existant de main.py par le code fourni ci-dessous :
import functions_framework
import json
from flask import Flask, jsonify, request
from langchain_google_vertexai import ChatVertexAI
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from pydantic import BaseModel, Field
import os
class Book(BaseModel):
bookname: str = Field(description="Name of the book")
author: str = Field(description="Name of the author")
publisher: str = Field(description="Name of the publisher")
publishing_date: str = Field(description="Date of publishing")
project_id = os.environ.get("GOOGLE_CLOUD_PROJECT")
llm = ChatVertexAI(model_name="gemini-2.0-flash-lite-001")
def get_recommended_books(category):
"""
A simple book recommendation function.
Args:
category (str): category
Returns:
str: A JSON string representing the recommended books.
"""
parser = JsonOutputParser(pydantic_object=Book)
question = f"Generate a random made up book on {category} with bookname, author and publisher and publishing_date"
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | llm | parser
response = chain.invoke({"query": question})
return json.dumps(response)
@functions_framework.http
def recommended(request):
request_json = request.get_json(silent=True) # Get JSON data
if request_json and 'category' in request_json and 'number_of_book' in request_json:
category = request_json['category']
number_of_book = int(request_json['number_of_book'])
elif request.args and 'category' in request.args and 'number_of_book' in request.args:
category = request.args.get('category')
number_of_book = int(request.args.get('number_of_book'))
else:
return jsonify({'error': 'Missing category or number_of_book parameters'}), 400
recommendations_list = []
for i in range(number_of_book):
book_dict = json.loads(get_recommended_books(category))
print(f"book_dict=======>{book_dict}")
recommendations_list.append(book_dict)
return jsonify(recommendations_list)
👉 Remplacez le contenu de requirements.txt par ce qui suit :
functions-framework==3.*
google-genai==1.0.0
flask==3.1.0
jsonify==0.5
langchain_google_vertexai==2.0.13
langchain_core==0.3.34
pydantic==2.10.5
👉 Nous allons définir le point d'entrée de la fonction : recommended

👉 Cliquez sur ENREGISTRER ET DÉPLOYER (ou ENREGISTRER ET REDÉPLOYER) pour déployer la fonction. Attendez la fin du processus de déploiement. L'état s'affiche dans la console Cloud. Cette opération peut prendre plusieurs minutes.
 👉 Une fois le déploiement effectué, revenez à l'éditeur Cloud Shell et exécutez la commande suivante dans le terminal :
👉 Une fois le déploiement effectué, revenez à l'éditeur Cloud Shell et exécutez la commande suivante dans le terminal :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export BOOK_PROVIDER_URL=$(gcloud run services describe book-provider --region=us-central1 --project=$PROJECT_ID --format="value(status.url)")
curl -X POST -H "Content-Type: application/json" -d '{"category": "Science Fiction", "number_of_book": 2}' $BOOK_PROVIDER_URL
Il devrait afficher des données de livres au format JSON.
[
{"author":"Anya Sharma","bookname":"Echoes of the Singularity","publisher":"NovaLight Publishing","publishing_date":"2077-03-15"},
{"author":"Anya Sharma","bookname":"Echoes of the Quantum Dawn","publisher":"Nova Genesis Publishing","publishing_date":"2077-03-15"}
]
Félicitations ! Vous avez déployé une fonction Cloud Run avec succès. Il s'agit de l'un des services que nous intégrerons lors du développement de notre agent Aidemy.
5. Outils de création : connecter des agents à un service RESTFUL et à des données
Téléchargeons le projet Bootstrap Skeleton. Assurez-vous d'être dans l'éditeur Cloud Shell. Dans le terminal, exécutez
git clone https://github.com/weimeilin79/aidemy-bootstrap.git
Après avoir exécuté cette commande, un nouveau dossier nommé aidemy-bootstrap sera créé dans votre environnement Cloud Shell.
Dans le volet "Explorateur" de l'éditeur Cloud Shell (généralement sur la gauche), vous devriez maintenant voir le dossier créé lorsque vous avez cloné le dépôt Git aidemy-bootstrap. Ouvrez le dossier racine de votre projet dans l'explorateur. Vous y trouverez un sous-dossier planner. Ouvrez-le également. 
Commençons à créer les outils que nos agents utiliseront pour devenir vraiment utiles. Comme vous le savez, les LLM sont excellents pour raisonner et générer du texte, mais ils ont besoin d'accéder à des ressources externes pour effectuer des tâches concrètes et fournir des informations précises et à jour. Considérez ces outils comme le "couteau suisse" de l'agent, qui lui permet d'interagir avec le monde.
Lorsque vous créez un agent, il est facile de tomber dans le piège du codage en dur d'une multitude de détails. Cela crée un agent qui n'est pas flexible. Au lieu de cela, en créant et en utilisant des outils, l'agent a accès à une logique ou à des systèmes externes, ce qui lui confère les avantages du LLM et de la programmation traditionnelle.
Dans cette section, nous allons créer la base de l'agent de planification, que les enseignants utiliseront pour générer des plans de cours. Avant que l'agent ne commence à générer un plan, nous voulons définir des limites en fournissant plus de détails sur le sujet et le thème. Nous allons créer trois outils :
- Appel d'API RESTful : interaction avec une API préexistante pour récupérer des données.
- Requête de base de données : récupération de données structurées à partir d'une base de données Cloud SQL.
- Recherche Google : accédez à des informations en temps réel sur le Web.
Récupérer des recommandations de livres à partir d'une API
Commençons par créer un outil qui récupère les recommandations de livres à partir de l'API book-provider que nous avons déployée dans la section précédente. Cet exemple montre comment un agent peut exploiter des services existants.

Dans l'éditeur Cloud Shell, ouvrez le projet aidemy-bootstrap que vous avez cloné dans la section précédente.
👉 Modifiez le fichier book.py dans le dossier planner, puis collez le code suivant à la fin du fichier :
def recommend_book(query: str):
"""
Get a list of recommended book from an API endpoint
Args:
query: User's request string
"""
region = get_next_region();
llm = VertexAI(model_name="gemini-1.5-pro", location=region)
query = f"""The user is trying to plan a education course, you are the teaching assistant. Help define the category of what the user requested to teach, respond the categroy with no more than two word.
user request: {query}
"""
print(f"-------->{query}")
response = llm.invoke(query)
print(f"CATEGORY RESPONSE------------>: {response}")
# call this using python and parse the json back to dict
category = response.strip()
headers = {"Content-Type": "application/json"}
data = {"category": category, "number_of_book": 2}
books = requests.post(BOOK_PROVIDER_URL, headers=headers, json=data)
return books.text
if __name__ == "__main__":
print(recommend_book("I'm doing a course for my 5th grade student on Math Geometry, I'll need to recommend few books come up with a teach plan, few quizes and also a homework assignment."))
Explication :
- recommend_book(query: str) : cette fonction prend la requête d'un utilisateur en entrée.
- Interaction avec le LLM : utilise le LLM pour extraire la catégorie de la requête. Cela montre comment vous pouvez utiliser le LLM pour créer des paramètres pour les outils.
- Appel d'API : il envoie une requête POST à l'API du fournisseur de livres, en transmettant la catégorie et le nombre de livres souhaités.
👉 Pour tester cette nouvelle fonction, définissez la variable d'environnement et exécutez la commande suivante :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
cd ~/aidemy-bootstrap/planner/
export BOOK_PROVIDER_URL=$(gcloud run services describe book-provider --region=us-central1 --project=$PROJECT_ID --format="value(status.url)")
👉 Installez les dépendances et exécutez le code pour vous assurer qu'il fonctionne :
cd ~/aidemy-bootstrap/planner/
python -m venv env
source env/bin/activate
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
pip install -r requirements.txt
python book.py
Une chaîne JSON contenant des recommandations de livres récupérées à partir de l'API book-provider doit s'afficher. Les résultats sont générés de manière aléatoire. Vos livres ne seront peut-être pas les mêmes, mais vous devriez recevoir deux recommandations de livres au format JSON.
[{"author":"Anya Sharma","bookname":"Echoes of the Singularity","publisher":"NovaLight Publishing","publishing_date":"2077-03-15"},{"author":"Anya Sharma","bookname":"Echoes of the Quantum Dawn","publisher":"Nova Genesis Publishing","publishing_date":"2077-03-15"}]
Si vous voyez ce message, cela signifie que le premier outil fonctionne correctement.
Au lieu de créer explicitement un appel d'API RESTful avec des paramètres spécifiques, nous utilisons le langage naturel ("Je suis un cours..."). L'agent extrait ensuite intelligemment les paramètres nécessaires (comme la catégorie) à l'aide du traitement du langage naturel (NLP, Natural Language Processing), ce qui montre comment l'agent exploite la compréhension du langage naturel pour interagir avec l'API.

👉 Supprimez le code de test suivant de book.py.
if __name__ == "__main__":
print(recommend_book("I'm doing a course for my 5th grade student on Math Geometry, I'll need to recommend few books come up with a teach plan, few quizes and also a homework assignment."))
Obtenir des données de programme à partir d'une base de données
Ensuite, nous allons créer un outil qui récupère les données structurées du programme à partir d'une base de données Cloud SQL PostgreSQL. Cela permet à l'agent d'accéder à une source d'informations fiable pour la planification des cours.

Vous souvenez-vous de l'instance Cloud SQL aidemy que vous avez créée à l'étape précédente ? Voici où il sera utilisé.
👉 Dans le terminal, exécutez la commande suivante pour créer une base de données nommée aidemy-db dans la nouvelle instance.
gcloud sql databases create aidemy-db \
--instance=aidemy
Vérifions l'instance dans Cloud SQL de la console Google Cloud. Vous devriez voir une instance Cloud SQL nommée aidemy.
👉 Cliquez sur le nom de l'instance pour afficher ses détails. 👉 Sur la page "Détails de l'instance Cloud SQL", cliquez sur Cloud SQL Studio dans le menu de navigation de gauche. Un nouvel onglet s'affiche.
Sélectionnez aidemy-db comme base de données, saisissez postgres comme utilisateur et 1234qwer comme mot de passe.
Cliquez sur Authentifier.

👉 Dans l'éditeur de requête SQL Studio, accédez à l'onglet Éditeur 1, puis collez le code SQL suivant :
CREATE TABLE curriculums (
id SERIAL PRIMARY KEY,
year INT,
subject VARCHAR(255),
description TEXT
);
-- Inserting detailed curriculum data for different school years and subjects
INSERT INTO curriculums (year, subject, description) VALUES
-- Year 5
(5, 'Mathematics', 'Introduction to fractions, decimals, and percentages, along with foundational geometry and problem-solving techniques.'),
(5, 'English', 'Developing reading comprehension, creative writing, and basic grammar, with a focus on storytelling and poetry.'),
(5, 'Science', 'Exploring basic physics, chemistry, and biology concepts, including forces, materials, and ecosystems.'),
(5, 'Computer Science', 'Basic coding concepts using block-based programming and an introduction to digital literacy.'),
-- Year 6
(6, 'Mathematics', 'Expanding on fractions, ratios, algebraic thinking, and problem-solving strategies.'),
(6, 'English', 'Introduction to persuasive writing, character analysis, and deeper comprehension of literary texts.'),
(6, 'Science', 'Forces and motion, the human body, and introductory chemical reactions with hands-on experiments.'),
(6, 'Computer Science', 'Introduction to algorithms, logical reasoning, and basic text-based programming (Python, Scratch).'),
-- Year 7
(7, 'Mathematics', 'Algebraic expressions, geometry, and introduction to statistics and probability.'),
(7, 'English', 'Analytical reading of classic and modern literature, essay writing, and advanced grammar skills.'),
(7, 'Science', 'Introduction to cells and organisms, chemical reactions, and energy transfer in physics.'),
(7, 'Computer Science', 'Building on programming skills with Python, introduction to web development, and cyber safety.');
Ce code SQL crée une table nommée curriculums et insère des exemples de données.
👉 Cliquez sur Exécuter pour exécuter le code SQL. Un message de confirmation doit vous indiquer que les instructions ont bien été exécutées.
👉 Développez l'explorateur, recherchez la table curriculums que vous venez de créer, puis cliquez sur Requête. Un nouvel onglet de l'éditeur doit s'ouvrir avec le code SQL généré pour vous.

SELECT * FROM
"public"."curriculums" LIMIT 1000;
👉 Cliquez sur Exécuter.
Le tableau de résultats doit afficher les lignes de données que vous avez insérées à l'étape précédente, ce qui confirme que la table et les données ont été créées correctement.
Maintenant que vous avez créé une base de données avec des exemples de données de programme, nous allons créer un outil pour les récupérer.
👉 Dans l'éditeur Cloud Code, modifiez le fichier curriculums.py dans le dossier aidemy-bootstrap et collez le code suivant à la fin du fichier :
def connect_with_connector() -> sqlalchemy.engine.base.Engine:
db_user = os.environ["DB_USER"]
db_pass = os.environ["DB_PASS"]
db_name = os.environ["DB_NAME"]
print(f"--------------------------->db_user: {db_user!r}")
print(f"--------------------------->db_pass: {db_pass!r}")
print(f"--------------------------->db_name: {db_name!r}")
connector = Connector()
pool = sqlalchemy.create_engine(
"postgresql+pg8000://",
creator=lambda: connector.connect(
instance_connection_name,
"pg8000",
user=db_user,
password=db_pass,
db=db_name,
),
pool_size=2,
max_overflow=2,
pool_timeout=30, # 30 seconds
pool_recycle=1800, # 30 minutes
)
return pool
def get_curriculum(year: int, subject: str):
"""
Get school curriculum
Args:
subject: User's request subject string
year: User's request year int
"""
try:
stmt = sqlalchemy.text(
"SELECT description FROM curriculums WHERE year = :year AND subject = :subject"
)
with db.connect() as conn:
result = conn.execute(stmt, parameters={"year": year, "subject": subject})
row = result.fetchone()
if row:
return row[0]
else:
return None
except Exception as e:
print(e)
return None
db = connect_with_connector()
Explication :
- Variables d'environnement : le code récupère les identifiants de base de données et les informations de connexion à partir des variables d'environnement (plus d'informations ci-dessous).
- connect_with_connector() : cette fonction utilise le connecteur Cloud SQL pour établir une connexion sécurisée à la base de données.
- get_curriculum(year: int, subject: str) : cette fonction prend l'année et la matière comme entrée, interroge la table des programmes et renvoie la description du programme correspondant.
👉 Avant d'exécuter le code, nous devons définir certaines variables d'environnement. Dans le terminal, exécutez la commande suivante :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export INSTANCE_NAME="aidemy"
export REGION="us-central1"
export DB_USER="postgres"
export DB_PASS="1234qwer"
export DB_NAME="aidemy-db"
👉 Pour tester, ajoutez le code suivant à la fin de curriculums.py :
if __name__ == "__main__":
print(get_curriculum(6, "Mathematics"))
👉 Exécutez le code :
cd ~/aidemy-bootstrap/planner/
source env/bin/activate
python curriculums.py
La description du programme de mathématiques de 6e année devrait s'afficher dans la console.
Expanding on fractions, ratios, algebraic thinking, and problem-solving strategies.
Si la description du programme s'affiche, cela signifie que l'outil de base de données fonctionne correctement. Arrêtez le script en appuyant sur Ctrl+C s'il est toujours en cours d'exécution.
👉 Supprimez le code de test suivant de curriculums.py.
if __name__ == "__main__":
print(get_curriculum(6, "Mathematics"))
👉 Pour quitter l'environnement virtuel, exécutez la commande suivante dans le terminal :
deactivate
6. Outils de création : accéder à des informations en temps réel sur le Web
Enfin, nous allons créer un outil qui utilise l'intégration de Gemini 2 et de la recherche Google pour accéder à des informations en temps réel sur le Web. Cela permet à l'agent de rester à jour et de fournir des résultats pertinents.
L'intégration de Gemini 2 à l'API Recherche Google améliore les capacités de l'agent en fournissant des résultats de recherche plus précis et contextuels. Les agents peuvent ainsi accéder à des informations à jour et ancrer leurs réponses dans des données réelles, ce qui minimise les hallucinations. L'intégration améliorée de l'API facilite également les requêtes en langage naturel, ce qui permet aux agents de formuler des demandes de recherche complexes et nuancées.

Cette fonction prend en entrée une requête de recherche, un programme, une matière et une année, et utilise l'API Gemini et l'outil de recherche Google pour récupérer des informations pertinentes sur Internet. Si vous regardez attentivement, vous verrez qu'il utilise le SDK Google Generative AI pour appeler des fonctions sans utiliser d'autre framework.
👉 Modifiez search.py dans le dossier aidemy-bootstrap et collez le code suivant à la fin du fichier :
model_id = "gemini-2.0-flash-001"
google_search_tool = Tool(
google_search = GoogleSearch()
)
def search_latest_resource(search_text: str, curriculum: str, subject: str, year: int):
"""
Get latest information from the internet
Args:
search_text: User's request category string
subject: "User's request subject" string
year: "User's request year" integer
"""
search_text = "%s in the context of year %d and subject %s with following curriculum detail %s " % (search_text, year, subject, curriculum)
region = get_next_region()
client = genai.Client(vertexai=True, project=PROJECT_ID, location=region)
print(f"search_latest_resource text-----> {search_text}")
response = client.models.generate_content(
model=model_id,
contents=search_text,
config=GenerateContentConfig(
tools=[google_search_tool],
response_modalities=["TEXT"],
)
)
print(f"search_latest_resource response-----> {response}")
return response
if __name__ == "__main__":
response = search_latest_resource("What are the syllabus for Year 6 Mathematics?", "Expanding on fractions, ratios, algebraic thinking, and problem-solving strategies.", "Mathematics", 6)
for each in response.candidates[0].content.parts:
print(each.text)
Explication :
- Définition de l'outil google_search_tool : encapsuler l'objet GoogleSearch dans un outil
- search_latest_resource(search_text: str, subject: str, year: int) : cette fonction prend une requête de recherche, un sujet et une année en entrée, puis utilise l'API Gemini pour effectuer une recherche Google.
- GenerateContentConfig : définissez qu'il a accès à l'outil GoogleSearch.
Le modèle Gemini analyse en interne le search_text et détermine s'il peut répondre directement à la question ou s'il doit utiliser l'outil GoogleSearch. Il s'agit d'une étape essentielle du processus de raisonnement du LLM. Le modèle a été entraîné à reconnaître les situations où des outils externes sont nécessaires. Si le modèle décide d'utiliser l'outil GoogleSearch, le SDK Google Generative AI gère l'invocation proprement dite. Le SDK prend la décision du modèle et les paramètres qu'il génère, puis les envoie à l'API Google Search. Cette partie est masquée pour l'utilisateur dans le code.
Le modèle Gemini intègre ensuite les résultats de recherche dans sa réponse. Il peut utiliser ces informations pour répondre à la question de l'utilisateur, générer un résumé ou effectuer une autre tâche.
👉 Pour tester, exécutez le code :
cd ~/aidemy-bootstrap/planner/
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
source env/bin/activate
python search.py
Vous devriez voir la réponse de l'API Gemini Search contenant les résultats de recherche liés à "Programme de mathématiques de 5e année". Le résultat exact dépendra des résultats de recherche, mais il s'agira d'un objet JSON contenant des informations sur la recherche.
Si des résultats de recherche s'affichent, cela signifie que l'outil de recherche Google fonctionne correctement. Si le script est toujours en cours d'exécution, arrêtez-le en appuyant sur Ctrl+C.
👉 Supprimez la dernière partie du code.
if __name__ == "__main__":
response = search_latest_resource("What are the syllabus for Year 6 Mathematics?", "Expanding on fractions, ratios, algebraic thinking, and problem-solving strategies.", "Mathematics", 6)
for each in response.candidates[0].content.parts:
print(each.text)
👉 Quittez l'environnement virtuel en exécutant la commande suivante dans le terminal :
deactivate
Félicitations ! Vous avez maintenant créé trois outils puissants pour votre agent de planification : un connecteur d'API, un connecteur de base de données et un outil de recherche Google. Ces outils permettront à l'agent d'accéder aux informations et aux fonctionnalités dont il a besoin pour créer des plans d'enseignement efficaces.
7. Orchestrer avec LangGraph
Maintenant que nous avons créé nos outils individuels, il est temps de les orchestrer à l'aide de LangGraph. Cela nous permettra de créer un agent de planification plus sophistiqué, capable de décider intelligemment quels outils utiliser et quand, en fonction de la demande de l'utilisateur.
LangGraph est une bibliothèque Python conçue pour faciliter la création d'applications avec état et multi-acteurs à l'aide de grands modèles de langage (LLM). Considérez-le comme un framework permettant d'orchestrer des conversations et des workflows complexes impliquant des LLM, des outils et d'autres agents.
Concepts clés
- Structure du graphique : LangGraph représente la logique de votre application sous forme de graphique orienté. Chaque nœud du graphique représente une étape du processus (par exemple, un appel à un LLM, une invocation d'outil ou une vérification conditionnelle). Les arêtes définissent le flux d'exécution entre les nœuds.
- État : LangGraph gère l'état de votre application à mesure qu'elle progresse dans le graphique. Cet état peut inclure des variables telles que la saisie de l'utilisateur, les résultats des appels d'outils, les sorties intermédiaires des LLM et toute autre information qui doit être conservée entre les étapes.
- Nœuds : chaque nœud représente un calcul ou une interaction. Elles peuvent être :
- Nœuds d'outil : utiliser un outil (par exemple, effectuer une recherche sur le Web ou interroger une base de données)
- Nœuds de fonction : exécutent une fonction Python.
- Arêtes : elles relient les nœuds et définissent le flux d'exécution. Elles peuvent être :
- Arêtes directes : flux simple et inconditionnel d'un nœud à un autre.
- Arêtes conditionnelles : le flux dépend du résultat d'un nœud conditionnel.

Nous allons utiliser LangGraph pour implémenter l'orchestration. Modifions le fichier aidemy.py sous le dossier aidemy-bootstrap pour définir notre logique LangGraph.
👉 Ajoutez le code suivant à la fin de .
aidemy.py :
tools = [get_curriculum, search_latest_resource, recommend_book]
def determine_tool(state: MessagesState):
llm = ChatVertexAI(model_name="gemini-2.0-flash-001", location=get_next_region())
sys_msg = SystemMessage(
content=(
f"""You are a helpful teaching assistant that helps gather all needed information.
Your ultimate goal is to create a detailed 3-week teaching plan.
You have access to tools that help you gather information.
Based on the user request, decide which tool(s) are needed.
"""
)
)
llm_with_tools = llm.bind_tools(tools)
return {"messages": llm_with_tools.invoke([sys_msg] + state["messages"])}
Cette fonction est chargée de prendre l'état actuel de la conversation, de fournir un message système au LLM, puis de lui demander de générer une réponse. Le LLM peut soit répondre directement à l'utilisateur, soit choisir d'utiliser l'un des outils disponibles.
tools : cette liste représente l'ensemble des outils dont dispose l'agent. Il contient trois fonctions d'outil que nous avons définies dans les étapes précédentes : get_curriculum, search_latest_resource et recommend_book. llm.bind_tools(tools) : "lie" la liste des outils à l'objet llm. L'association des outils indique au LLM que ces outils sont disponibles et lui fournit des informations sur la façon de les utiliser (par exemple, les noms des outils, les paramètres qu'ils acceptent et ce qu'ils font).
Nous allons utiliser LangGraph pour implémenter l'orchestration.
👉 Ajoutez le code suivant à la fin de .
aidemy.py :
def prep_class(prep_needs):
builder = StateGraph(MessagesState)
builder.add_node("determine_tool", determine_tool)
builder.add_node("tools", ToolNode(tools))
builder.add_edge(START, "determine_tool")
builder.add_conditional_edges("determine_tool",tools_condition)
builder.add_edge("tools", "determine_tool")
memory = MemorySaver()
graph = builder.compile(checkpointer=memory)
config = {"configurable": {"thread_id": "1"}}
messages = graph.invoke({"messages": prep_needs},config)
print(messages)
for m in messages['messages']:
m.pretty_print()
teaching_plan_result = messages["messages"][-1].content
return teaching_plan_result
if __name__ == "__main__":
prep_class("I'm doing a course for year 5 on subject Mathematics in Geometry, , get school curriculum, and come up with few books recommendation plus search latest resources on the internet base on the curriculum outcome. And come up with a 3 week teaching plan")
Explication :
StateGraph(MessagesState): crée un objetStateGraph. UnStateGraphest un concept fondamental dans LangGraph. Il représente le workflow de votre agent sous la forme d'un graphique, où chaque nœud du graphique représente une étape du processus. Considérez-le comme un plan définissant la façon dont l'agent raisonnera et agira.- Périphérie conditionnelle : à partir du nœud
"determine_tool", l'argumenttools_conditionest probablement une fonction qui détermine la périphérie à suivre en fonction du résultat de la fonctiondetermine_tool. Les arêtes conditionnelles permettent au graphique de se ramifier en fonction de la décision du LLM concernant l'outil à utiliser (ou s'il doit répondre directement à l'utilisateur). C'est là que l'intelligence de l'agent entre en jeu : il peut adapter son comportement de manière dynamique en fonction de la situation. - Boucle : ajoute une arête au graphique qui relie le nœud
"tools"au nœud"determine_tool". Cela crée une boucle dans le graphique, ce qui permet à l'agent d'utiliser les outils de manière répétée jusqu'à ce qu'il ait recueilli suffisamment d'informations pour accomplir la tâche et fournir une réponse satisfaisante. Cette boucle est essentielle pour les tâches complexes qui nécessitent plusieurs étapes de raisonnement et de collecte d'informations.
Maintenant, testons notre agent de planification pour voir comment il orchestre les différents outils.
Ce code exécutera la fonction prep_class avec une entrée utilisateur spécifique, simulant une demande de création d'un plan d'enseignement pour les mathématiques de 5e année en géométrie, en utilisant le programme, des recommandations de livres et les dernières ressources Internet.
👉 Dans votre terminal, si vous l'avez fermé ou si les variables d'environnement ne sont plus définies, réexécutez les commandes suivantes.
export BOOK_PROVIDER_URL=$(gcloud run services describe book-provider --region=us-central1 --project=$PROJECT_ID --format="value(status.url)")
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export INSTANCE_NAME="aidemy"
export REGION="us-central1"
export DB_USER="postgres"
export DB_PASS="1234qwer"
export DB_NAME="aidemy-db"
👉 Exécutez le code :
cd ~/aidemy-bootstrap/planner/
source env/bin/activate
pip install -r requirements.txt
python aidemy.py
Consultez le journal dans le terminal. Vous devez voir la preuve que l'agent appelle les trois outils (obtenir le programme scolaire, obtenir des recommandations de livres et rechercher les dernières ressources) avant de fournir le plan d'enseignement final. Cela montre que l'orchestration LangGraph fonctionne correctement et que l'agent utilise intelligemment tous les outils disponibles pour répondre à la demande de l'utilisateur.
================================ Human Message =================================
I'm doing a course for year 5 on subject Mathematics in Geometry, , get school curriculum, and come up with few books recommendation plus search latest resources on the internet base on the curriculum outcome. And come up with a 3 week teaching plan
================================== Ai Message ==================================
Tool Calls:
get_curriculum (xxx)
Call ID: xxx
Args:
year: 5.0
subject: Mathematics
================================= Tool Message =================================
Name: get_curriculum
Introduction to fractions, decimals, and percentages, along with foundational geometry and problem-solving techniques.
================================== Ai Message ==================================
Tool Calls:
search_latest_resource (xxxx)
Call ID: xxxx
Args:
year: 5.0
search_text: Geometry
curriculum: {"content": "Introduction to fractions, decimals, and percentages, along with foundational geometry and problem-solving techniques."}
subject: Mathematics
================================= Tool Message =================================
Name: search_latest_resource
candidates=[Candidate(content=Content(parts=[Part(.....) automatic_function_calling_history=[] parsed=None
================================== Ai Message ==================================
Tool Calls:
recommend_book (93b48189-4d69-4c09-a3bd-4e60cdc5f1c6)
Call ID: 93b48189-4d69-4c09-a3bd-4e60cdc5f1c6
Args:
query: Mathematics Geometry Year 5
================================= Tool Message =================================
Name: recommend_book
[{.....}]
================================== Ai Message ==================================
Based on the curriculum outcome, here is a 3-week teaching plan for year 5 Mathematics Geometry:
**Week 1: Introduction to Shapes and Properties**
.........
Arrêtez le script en appuyant sur Ctrl+C s'il est toujours en cours d'exécution.
👉 (FACULTATIF) Remplacez le code de test par une autre requête, qui nécessite l'appel d'autres outils.
if __name__ == "__main__":
prep_class("I'm doing a course for year 5 on subject Mathematics in Geometry, search latest resources on the internet base on the subject. And come up with a 3 week teaching plan")
👉 Si vous avez fermé votre terminal ou si les variables d'environnement ne sont plus définies, réexécutez les commandes suivantes.
gcloud config set project $(cat ~/project_id.txt)
export BOOK_PROVIDER_URL=$(gcloud run services describe book-provider --region=us-central1 --project=$PROJECT_ID --format="value(status.url)")
export PROJECT_ID=$(gcloud config get project)
export INSTANCE_NAME="aidemy"
export REGION="us-central1"
export DB_USER="postgres"
export DB_PASS="1234qwer"
export DB_NAME="aidemy-db"
👉 (CETTE ÉTAPE EST FACULTATIVE. NE L'EFFECTUEZ QUE SI VOUS AVEZ EXÉCUTÉ L'ÉTAPE PRÉCÉDENTE.) Exécutez à nouveau le code :
cd ~/aidemy-bootstrap/planner/
source env/bin/activate
python aidemy.py
Qu'avez-vous remarqué cette fois-ci ? À quels outils l'agent a-t-il fait appel ? Vous devriez constater que l'agent n'appelle que l'outil search_latest_resource cette fois-ci. En effet, la requête ne précise pas qu'elle a besoin des deux autres outils, et notre LLM est suffisamment intelligent pour ne pas les appeler.
================================ Human Message =================================
I'm doing a course for year 5 on subject Mathematics in Geometry, search latest resources on the internet base on the subject. And come up with a 3 week teaching plan
================================== Ai Message ==================================
Tool Calls:
get_curriculum (xxx)
Call ID: xxx
Args:
year: 5.0
subject: Mathematics
================================= Tool Message =================================
Name: get_curriculum
Introduction to fractions, decimals, and percentages, along with foundational geometry and problem-solving techniques.
================================== Ai Message ==================================
Tool Calls:
search_latest_resource (xxx)
Call ID: xxxx
Args:
year: 5.0
subject: Mathematics
curriculum: {"content": "Introduction to fractions, decimals, and percentages, along with foundational geometry and problem-solving techniques."}
search_text: Geometry
================================= Tool Message =================================
Name: search_latest_resource
candidates=[Candidate(content=Content(parts=[Part(.......token_count=40, total_token_count=772) automatic_function_calling_history=[] parsed=None
================================== Ai Message ==================================
Based on the information provided, a 3-week teaching plan for Year 5 Mathematics focusing on Geometry could look like this:
**Week 1: Introducing 2D Shapes**
........
* Use visuals, manipulatives, and real-world examples to make the learning experience engaging and relevant.
Arrêtez le script en appuyant sur Ctrl+C.
👉 (NE PAS PASSER CETTE ÉTAPE !) Supprimez le code de test pour que votre fichier aidemy.py reste propre :
if __name__ == "__main__":
prep_class("I'm doing a course for year 5 on subject Mathematics in Geometry, search latest resources on the internet base on the subject. And come up with a 3 week teaching plan")
Maintenant que la logique de notre agent est définie, lançons l'application Web Flask. Les enseignants pourront ainsi interagir avec l'agent à l'aide d'une interface basée sur des formulaires qui leur est familière. Bien que les interactions avec les chatbots soient courantes avec les LLM, nous optons pour une UI d'envoi de formulaire traditionnelle, car elle peut être plus intuitive pour de nombreux enseignants.
👉 Si vous avez fermé votre terminal ou si les variables d'environnement ne sont plus définies, réexécutez les commandes suivantes.
export BOOK_PROVIDER_URL=$(gcloud run services describe book-provider --region=us-central1 --project=$PROJECT_ID --format="value(status.url)")
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export INSTANCE_NAME="aidemy"
export REGION="us-central1"
export DB_USER="postgres"
export DB_PASS="1234qwer"
export DB_NAME="aidemy-db"
👉 Lancez maintenant l'UI Web.
cd ~/aidemy-bootstrap/planner/
source env/bin/activate
python app.py
Recherchez les messages de démarrage dans la sortie du terminal Cloud Shell. Flask affiche généralement des messages indiquant qu'il est en cours d'exécution et sur quel port.
Running on http://127.0.0.1:8080
Running on http://127.0.0.1:8080
The application needs to keep running to serve requests.
👉 Dans le menu "Aperçu sur le Web" en haut à droite, sélectionnez Prévisualiser sur le port 8080. Cloud Shell ouvre un nouvel onglet ou une nouvelle fenêtre de navigateur avec l'aperçu Web de votre application.

Dans l'interface de l'application, sélectionnez 5 pour l'année, sélectionnez le sujet Mathematics et saisissez Geometry dans la demande de module complémentaire.
👉 Si vous avez quitté l'interface utilisateur de votre application, revenez-y. Vous devriez voir le résultat généré.
👉 Dans votre terminal, arrêtez le script en appuyant sur Ctrl+C.
👉 Dans votre terminal, quittez l'environnement virtuel :
deactivate
8. Déployer l'agent de planification dans le cloud
Créer et transférer l'image vers le registre

Il est temps de déployer cela dans le cloud.
👉 Dans le terminal, créez un dépôt d'artefacts pour stocker l'image Docker que nous allons créer.
gcloud artifacts repositories create agent-repository \
--repository-format=docker \
--location=us-central1 \
--description="My agent repository"
Le message "Dépôt [agent-repository] créé" devrait s'afficher.
👉 Exécutez la commande suivante pour créer l'image Docker.
cd ~/aidemy-bootstrap/planner/
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/aidemy-planner .
👉 Nous devons ajouter un tag à l'image pour qu'elle soit hébergée dans Artifact Registry au lieu de GCR, puis transférer l'image taguée vers Artifact Registry :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/aidemy-planner us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-planner
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-planner
Une fois le transfert terminé, vous pouvez vérifier que l'image est bien stockée dans Artifact Registry.
👉 Accédez à Artifact Registry dans la console Google Cloud. Vous devriez trouver l'image aidemy-planner dans le dépôt agent-repository. 
Sécuriser les identifiants de base de données avec Secret Manager
Pour gérer et accéder aux identifiants de base de données de manière sécurisée, nous allons utiliser Google Cloud Secret Manager. Cela permet d'éviter d'encoder en dur des informations sensibles dans le code de notre application et renforce la sécurité.
Nous allons créer des secrets individuels pour le nom d'utilisateur, le mot de passe et le nom de la base de données. Cette approche nous permet de gérer chaque identifiant de manière indépendante.
👉 Dans le terminal, exécutez la commande suivante :
gcloud secrets create db-user
printf "postgres" | gcloud secrets versions add db-user --data-file=-
gcloud secrets create db-pass
printf "1234qwer" | gcloud secrets versions add db-pass --data-file=-
gcloud secrets create db-name
printf "aidemy-db" | gcloud secrets versions add db-name --data-file=-
L'utilisation de Secret Manager est une étape importante pour sécuriser votre application et éviter l'exposition accidentelle d'identifiants sensibles. Il respecte les bonnes pratiques de sécurité pour les déploiements cloud.
Déployer dans Cloud Run
Cloud Run est une plate-forme sans serveur entièrement gérée qui vous permet de déployer des applications conteneurisées rapidement et facilement. Elle élimine la gestion de l'infrastructure, ce qui vous permet de vous concentrer sur l'écriture et le déploiement de votre code. Nous allons déployer notre planificateur en tant que service Cloud Run.
👉 Dans la console Google Cloud, accédez à Cloud Run. Cliquez sur DÉPLOYER UN CONTENEUR, puis sélectionnez SERVICE. Configurez votre service Cloud Run :

- Image de conteneur : cliquez sur "Sélectionner" dans le champ de l'URL. Recherchez l'URL de l'image que vous avez transférée vers Artifact Registry (par exemple, us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repository/aidemy-planner/YOUR_IMG).
- Service name (Nom du service) :
aidemy-planner - Région : sélectionnez la région
us-central1. - Authentification : pour cet atelier, vous pouvez autoriser les appels non authentifiés. Pour la production, vous souhaiterez probablement limiter l'accès.
- Développez la section "Conteneur(s), volumes, mise en réseau, sécurité", puis définissez les éléments suivants dans l'onglet Conteneur(s) :
- Onglet "Paramètres" :
- Ressources
- memory : 2 Gio
- Ressources
- Onglet "Variables et secrets" :
- Variables d'environnement : ajoutez les variables suivantes en cliquant sur le bouton + Ajouter une variable :
- Ajoutez le nom
GOOGLE_CLOUD_PROJECTet la valeur <YOUR_PROJECT_ID>. - Ajoutez le nom
BOOK_PROVIDER_URLet définissez la valeur sur l'URL de votre fonction de fournisseur de livres, que vous pouvez déterminer à l'aide de la commande suivante dans le terminal :gcloud config set project $(cat ~/project_id.txt) gcloud run services describe book-provider \ --region=us-central1 \ --project=$PROJECT_ID \ --format="value(status.url)"
- Ajoutez le nom
- Dans la section Secrets exposés en tant que variables d'environnement, ajoutez les secrets suivants en cliquant sur le bouton + Référencer en tant que secret :
- Ajouter un nom :
DB_USER, secret : sélectionnezdb-useret version :latest - Ajouter un nom :
DB_PASS, secret : sélectionnezdb-passet version :latest - Ajouter un nom :
DB_NAME, secret : sélectionnezdb-nameet version :latest
- Ajouter un nom :
- Variables d'environnement : ajoutez les variables suivantes en cliquant sur le bouton + Ajouter une variable :
- Onglet "Paramètres" :

Conservez les valeurs par défaut des autres options.
👉 Cliquez sur CRÉER.
Cloud Run déploie votre service.
Une fois le service déployé, si vous n'êtes pas déjà sur la page d'informations, cliquez sur son nom pour y accéder. L'URL déployée est disponible en haut de la page.

👉 Dans l'interface de l'application, sélectionnez 7 pour l'année, choisissez Mathematics comme sujet et saisissez Algebra dans le champ "Demande de module complémentaire".
👉 Cliquez sur Générer un plan. L'agent disposera ainsi du contexte nécessaire pour générer un plan de cours personnalisé.
Félicitations ! Vous avez créé un plan de cours à l'aide de notre puissant agent d'IA. Cela montre le potentiel des agents pour réduire considérablement la charge de travail et simplifier les tâches, ce qui améliore l'efficacité et facilite la vie des enseignants.
9. Systèmes multi-agents
Maintenant que nous avons implémenté l'outil de création de plans de cours, concentrons-nous sur la création du portail des élèves. Ce portail permettra aux élèves d'accéder aux quiz, aux résumés audio et aux devoirs liés à leurs cours. Compte tenu de l'étendue de cette fonctionnalité, nous allons exploiter la puissance des systèmes multi-agents pour créer une solution modulaire et évolutive.
Comme nous l'avons vu précédemment, au lieu de s'appuyer sur un seul agent pour tout gérer, un système multi-agents nous permet de répartir la charge de travail en tâches plus petites et spécialisées, chacune étant gérée par un agent dédié. Cette approche présente plusieurs avantages clés :
Modularité et maintenabilité : au lieu de créer un seul agent qui fait tout, créez des agents plus petits et spécialisés avec des responsabilités bien définies. Cette modularité facilite la compréhension, la maintenance et le débogage du système. Lorsqu'un problème survient, vous pouvez l'isoler sur un agent spécifique, au lieu d'avoir à parcourir un codebase volumineux.
Évolutivité : la mise à l'échelle d'un agent unique et complexe peut constituer un goulot d'étranglement. Avec un système multi-agents, vous pouvez mettre à l'échelle des agents individuels en fonction de leurs besoins spécifiques. Par exemple, si un agent traite un volume élevé de requêtes, vous pouvez facilement créer d'autres instances de cet agent sans affecter le reste du système.
Spécialisation des équipes : imaginez que vous ne demanderiez pas à un seul ingénieur de créer une application entière à partir de zéro. Au lieu de cela, vous constituez une équipe de spécialistes, chacun ayant une expertise dans un domaine particulier. De même, un système multi-agents vous permet d'exploiter les points forts de différents LLM et outils, en les attribuant à des agents les mieux adaptés à des tâches spécifiques.
Développement en parallèle : différentes équipes peuvent travailler simultanément sur différents agents, ce qui accélère le processus de développement. Comme les agents sont indépendants, les modifications apportées à l'un d'eux sont moins susceptibles d'avoir un impact sur les autres.
Architecture basée sur des événements
Pour permettre une communication et une coordination efficaces entre ces agents, nous utiliserons une architecture basée sur les événements. Cela signifie que les agents réagissent aux "événements" qui se produisent dans le système.
Les agents s'abonnent à des types d'événements spécifiques (par exemple, "plan de cours généré", "devoir créé"). Lorsqu'un événement se produit, les agents concernés sont avertis et peuvent réagir en conséquence. Ce découplage favorise la flexibilité, l'évolutivité et la réactivité en temps réel.

Pour commencer, nous avons besoin d'un moyen de diffuser ces événements. Pour ce faire, nous allons configurer un sujet Pub/Sub. Commençons par créer un thème appelé plan.
👉 Accédez à Google Cloud Console Pub/Sub.
👉 Cliquez sur le bouton Créer un sujet.
👉 Configurez le sujet avec l'ID/le nom plan et décochezAdd a default subscription. Conservez les autres paramètres par défaut, puis cliquez sur Créer.
La page Pub/Sub s'actualise et le sujet que vous venez de créer doit maintenant figurer dans le tableau. 
Nous allons maintenant intégrer la fonctionnalité de publication d'événements Pub/Sub à notre agent de planification. Nous allons ajouter un outil qui envoie un événement "plan" au sujet Pub/Sub que nous venons de créer. Cet événement signalera aux autres agents du système (comme ceux du portail des élèves) qu'un nouveau plan d'enseignement est disponible.
👉 Revenez à l'éditeur Cloud Code et ouvrez le fichier app.py situé dans le dossier planner. Nous allons ajouter une fonction qui publie l'événement. Remplacer :
##ADD SEND PLAN EVENT FUNCTION HERE
par le code suivant
def send_plan_event(teaching_plan:str):
"""
Send the teaching event to the topic called plan
Args:
teaching_plan: teaching plan
"""
publisher = pubsub_v1.PublisherClient()
print(f"-------------> Sending event to topic plan: {teaching_plan}")
topic_path = publisher.topic_path(PROJECT_ID, "plan")
message_data = {"teaching_plan": teaching_plan}
data = json.dumps(message_data).encode("utf-8")
future = publisher.publish(topic_path, data)
return f"Published message ID: {future.result()}"
- send_plan_event : cette fonction prend le programme d'enseignement généré en entrée, crée un client d'éditeur Pub/Sub, construit le chemin du sujet, convertit le programme d'enseignement en chaîne JSON et publie le message dans le sujet.
Dans le même fichier app.py
👉 Modifiez l'invite pour demander à l'agent d'envoyer l'événement du programme pédagogique au sujet Pub/Sub après avoir généré le programme pédagogique. *Remplacer
### ADD send_plan_event CALL
avec les éléments suivants :
send_plan_event(teaching_plan)
En ajoutant l'outil send_plan_event et en modifiant l'invite, nous avons permis à notre agent de planification de publier des événements sur Pub/Sub, ce qui permet aux autres composants de notre système de réagir à la création de nouveaux plans d'enseignement. Nous disposerons désormais d'un système multi-agents fonctionnel dans les sections suivantes.
10. Aider les élèves grâce aux quiz à la demande
Imaginez un environnement d'apprentissage où les élèves ont accès à une infinité de quiz adaptés à leurs plans d'apprentissage spécifiques. Ces quiz fournissent des commentaires immédiats, y compris des réponses et des explications, ce qui favorise une meilleure compréhension du contenu. C'est le potentiel que nous souhaitons exploiter avec notre portail de quiz optimisé par l'IA.
Pour concrétiser cette vision, nous allons créer un composant de génération de quiz capable de créer des questions à choix multiples en fonction du contenu du programme d'enseignement.

👉 Dans le volet "Explorateur" de l'éditeur Cloud Code, accédez au dossier portal. Ouvrez le fichier quiz.py, puis copiez et collez le code suivant à la fin du fichier.
def generate_quiz_question(file_name: str, difficulty: str, region:str ):
"""Generates a single multiple-choice quiz question using the LLM.
```json
{
"question": "The question itself",
"options": ["Option A", "Option B", "Option C", "Option D"],
"answer": "The correct answer letter (A, B, C, or D)"
}
```
"""
print(f"region: {region}")
# Connect to resourse needed from Google Cloud
llm = VertexAI(model_name="gemini-2.5-flash-preview-04-17", location=region)
plan=None
#load the file using file_name and read content into string call plan
with open(file_name, 'r') as f:
plan = f.read()
parser = JsonOutputParser(pydantic_object=QuizQuestion)
instruction = f"You'll provide one question with difficulty level of {difficulty}, 4 options as multiple choices and provide the anwsers, the quiz needs to be related to the teaching plan {plan}"
prompt = PromptTemplate(
template="Generates a single multiple-choice quiz question\n {format_instructions}\n {instruction}\n",
input_variables=["instruction"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | llm | parser
response = chain.invoke({"instruction": instruction})
print(f"{response}")
return response
Dans l'agent, il crée un analyseur de sortie JSON spécialement conçu pour comprendre et structurer la sortie du LLM. Il utilise le modèle QuizQuestion que nous avons défini précédemment pour s'assurer que le résultat analysé est conforme au format correct (question, options et réponse).
👉 Dans votre terminal, exécutez les commandes suivantes pour configurer un environnement virtuel, installer les dépendances et démarrer l'agent :
gcloud config set project $(cat ~/project_id.txt)
cd ~/aidemy-bootstrap/portal/
python -m venv env
source env/bin/activate
pip install -r requirements.txt
python app.py
👉 Dans le menu "Aperçu sur le Web" en haut à droite, sélectionnez Prévisualiser sur le port 8080. Cloud Shell ouvre un nouvel onglet ou une nouvelle fenêtre de navigateur avec l'aperçu Web de votre application.
👉 Dans l'application Web, cliquez sur le lien "Quiz", soit dans la barre de navigation supérieure, soit dans la fiche de la page d'index. Trois quiz générés de manière aléatoire devraient s'afficher pour l'élève. Ces quiz sont basés sur le programme d'enseignement et démontrent la puissance de notre système de génération de quiz basé sur l'IA.

👉 Pour arrêter le processus en cours d'exécution en local, appuyez sur Ctrl+C dans le terminal.
Gemini 2 Thinking pour les explications
Nous avons donc des quiz, ce qui est un bon début. Mais que se passe-t-il si les élèves font une erreur ? C'est là que l'apprentissage se fait vraiment, n'est-ce pas ? Si nous pouvons expliquer pourquoi leur réponse était incorrecte et comment trouver la bonne, ils ont beaucoup plus de chances de s'en souvenir. Cela permet également de dissiper toute confusion et de renforcer leur confiance.
C'est pourquoi nous allons faire appel à la crème de la crème : le modèle de "réflexion" de Gemini 2 ! C'est comme si vous donniez à l'IA un peu plus de temps pour réfléchir avant de vous donner une explication. Il peut ainsi fournir des commentaires plus détaillés et de meilleure qualité.
Nous voulons voir si elle peut aider les élèves en leur fournissant une assistance, en répondant à leurs questions et en leur donnant des explications détaillées. Pour le tester, nous allons commencer par un sujet notoirement difficile : le calcul.

👉 Commencez par accéder à l'éditeur Cloud Code, dans answer.py à l'intérieur du dossier portal. Remplacer le code de fonction suivant
def answer_thinking(question, options, user_response, answer, region):
return ""
avec l'extrait de code suivant :
def answer_thinking(question, options, user_response, answer, region):
try:
llm = VertexAI(model_name="gemini-2.0-flash-001",location=region)
input_msg = HumanMessage(content=[f"Here the question{question}, here are the available options {options}, this student's answer {user_response}, whereas the correct answer is {answer}"])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful teacher trying to teach the student on question, you were given the question and a set of multiple choices "
"what's the correct answer. use friendly tone"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
if __name__ == "__main__":
question = "Evaluate the limit: lim (x→0) [(sin(5x) - 5x) / x^3]"
options = ["A) -125/6", "B) -5/3 ", "C) -25/3", "D) -5/6"]
user_response = "B"
answer = "A"
region = "us-central1"
result = answer_thinking(question, options, user_response, answer, region)
Il s'agit d'une application Langchain très simple qui initialise le modèle Gemini 2 Flash, où nous lui demandons d'agir comme un enseignant utile et de fournir des explications.
👉 Exécutez la commande suivante dans le terminal :
gcloud config set project $(cat ~/project_id.txt)
cd ~/aidemy-bootstrap/portal/
source env/bin/activate
python answer.py
Un résultat semblable à l'exemple fourni dans les instructions d'origine doit s'afficher. Le modèle actuel peut ne pas fournir d'explication complète.
Okay, I see the question and the choices. The question is to evaluate the limit:
lim (x→0) [(sin(5x) - 5x) / x^3]
You chose option B, which is -5/3, but the correct answer is A, which is -125/6.
It looks like you might have missed a step or made a small error in your calculations. This type of limit often involves using L'Hôpital's Rule or Taylor series expansion. Since we have the form 0/0, L'Hôpital's Rule is a good way to go! You need to apply it multiple times. Alternatively, you can use the Taylor series expansion of sin(x) which is:
sin(x) = x - x^3/3! + x^5/5! - ...
So, sin(5x) = 5x - (5x)^3/3! + (5x)^5/5! - ...
Then, (sin(5x) - 5x) = - (5x)^3/3! + (5x)^5/5! - ...
Finally, (sin(5x) - 5x) / x^3 = - 5^3/3! + (5^5 * x^2)/5! - ...
Taking the limit as x approaches 0, we get -125/6.
Keep practicing, you'll get there!
👉 Dans le fichier answer.py, remplacez
model_name de gemini-2.0-flash-001 à gemini-2.0-flash-thinking-exp-01-21 dans la fonction answer_thinking.
Le LLM est remplacé par un autre qui est plus performant en matière de raisonnement. Cela aidera le modèle à générer de meilleures explications.
👉 Exécutez à nouveau le script answer.py pour tester le nouveau modèle de réflexion :
gcloud config set project $(cat ~/project_id.txt)
cd ~/aidemy-bootstrap/portal/
source env/bin/activate
python answer.py
Voici un exemple de réponse du modèle de réflexion, qui est beaucoup plus complète et détaillée, et qui fournit une explication étape par étape de la façon de résoudre le problème de calcul. Cela souligne la puissance des modèles de "réflexion" pour générer des explications de haute qualité. Le résultat doit ressembler à ce qui suit :
Hey there! Let's take a look at this limit problem together. You were asked to evaluate:
lim (x→0) [(sin(5x) - 5x) / x^3]
and you picked option B, -5/3, but the correct answer is actually A, -125/6. Let's figure out why!
It's a tricky one because if we directly substitute x=0, we get (sin(0) - 0) / 0^3 = (0 - 0) / 0 = 0/0, which is an indeterminate form. This tells us we need to use a more advanced technique like L'Hopital's Rule or Taylor series expansion.
Let's use the Taylor series expansion for sin(y) around y=0. Do you remember it? It looks like this:
sin(y) = y - y^3/3! + y^5/5! - ...
where 3! (3 factorial) is 3 × 2 × 1 = 6, 5! is 5 × 4 × 3 × 2 × 1 = 120, and so on.
In our problem, we have sin(5x), so we can substitute y = 5x into the Taylor series:
sin(5x) = (5x) - (5x)^3/3! + (5x)^5/5! - ...
sin(5x) = 5x - (125x^3)/6 + (3125x^5)/120 - ...
Now let's plug this back into our limit expression:
[(sin(5x) - 5x) / x^3] = [ (5x - (125x^3)/6 + (3125x^5)/120 - ...) - 5x ] / x^3
Notice that the '5x' and '-5x' cancel out! So we are left with:
= [ - (125x^3)/6 + (3125x^5)/120 - ... ] / x^3
Now, we can divide every term in the numerator by x^3:
= -125/6 + (3125x^2)/120 - ...
Finally, let's take the limit as x approaches 0. As x gets closer and closer to zero, terms with x^2 and higher powers will become very, very small and approach zero. So, we are left with:
lim (x→0) [ -125/6 + (3125x^2)/120 - ... ] = -125/6
Therefore, the correct answer is indeed **A) -125/6**.
It seems like your answer B, -5/3, might have come from perhaps missing a factor somewhere during calculation or maybe using an incorrect simplification. Double-check your steps when you were trying to solve it!
Don't worry, these limit problems can be a bit tricky sometimes! Keep practicing and you'll get the hang of it. Let me know if you want to go through another similar example or if you have any more questions! 😊
Now that we have confirmed it works, let's use the portal.
👉 SUPPRIMEZ le code de test suivant de answer.py :
if __name__ == "__main__":
question = "Evaluate the limit: lim (x→0) [(sin(5x) - 5x) / x^3]"
options = ["A) -125/6", "B) -5/3 ", "C) -25/3", "D) -5/6"]
user_response = "B"
answer = "A"
region = "us-central1"
result = answer_thinking(question, options, user_response, answer, region)
👉 Exécutez les commandes suivantes dans le terminal pour configurer un environnement virtuel, installer les dépendances et démarrer l'agent :
gcloud config set project $(cat ~/project_id.txt)
cd ~/aidemy-bootstrap/portal/
source env/bin/activate
python app.py
👉 Dans le menu "Aperçu sur le Web" en haut à droite, sélectionnez Prévisualiser sur le port 8080. Cloud Shell ouvre un nouvel onglet ou une nouvelle fenêtre de navigateur avec l'aperçu Web de votre application.
👉 Dans l'application Web, cliquez sur le lien "Quiz", soit dans la barre de navigation supérieure, soit dans la fiche de la page d'index.
👉 Répondez à tous les quiz et assurez-vous de faire au moins une erreur, puis cliquez sur Envoyer.

Plutôt que de rester les bras croisés en attendant la réponse, passez au terminal de l'éditeur Cloud. Vous pouvez observer la progression et les éventuels messages de sortie ou d'erreur générés par votre fonction dans le terminal de l'émulateur. 😁
👉 Dans votre terminal, arrêtez le processus en cours d'exécution en local en appuyant sur Ctrl+C.
11. FACULTATIF : Orchestrer les agents avec Eventarc
Jusqu'à présent, le portail des élèves générait des quiz basés sur un ensemble par défaut de plans de cours. C'est utile, mais cela signifie que notre agent de planification et l'agent de quiz du portail ne communiquent pas vraiment entre eux. Vous vous souvenez de la fonctionnalité que nous avons ajoutée et qui permet à l'agent de planification de publier ses plans d'enseignement nouvellement générés dans un sujet Pub/Sub ? Il est maintenant temps de le connecter à notre agent de portail.

Nous souhaitons que le portail mette à jour automatiquement le contenu de ses quiz chaque fois qu'un nouveau programme d'enseignement est généré. Pour ce faire, nous allons créer un point de terminaison dans le portail qui pourra recevoir ces nouveaux forfaits.
👉 Dans le volet de l'explorateur de l'éditeur Cloud Code, accédez au dossier portal.
👉 Ouvrez le fichier app.py pour le modifier. Remplacez la ligne REPLACE ## REPLACE ME! NEW TEACHING PLAN par le code suivant :
@app.route('/new_teaching_plan', methods=['POST'])
def new_teaching_plan():
try:
# Get data from Pub/Sub message delivered via Eventarc
envelope = request.get_json()
if not envelope:
return jsonify({'error': 'No Pub/Sub message received'}), 400
if not isinstance(envelope, dict) or 'message' not in envelope:
return jsonify({'error': 'Invalid Pub/Sub message format'}), 400
pubsub_message = envelope['message']
print(f"data: {pubsub_message['data']}")
data = pubsub_message['data']
data_str = base64.b64decode(data).decode('utf-8')
data = json.loads(data_str)
teaching_plan = data['teaching_plan']
print(f"File content: {teaching_plan}")
with open("teaching_plan.txt", "w") as f:
f.write(teaching_plan)
print(f"Teaching plan saved to local file: teaching_plan.txt")
return jsonify({'message': 'File processed successfully'})
except Exception as e:
print(f"Error processing file: {e}")
return jsonify({'error': 'Error processing file'}), 500
Recompiler et déployer sur Cloud Run
Vous devrez mettre à jour et redéployer nos agents de planification et de portail sur Cloud Run. Cela garantit qu'ils disposent du code le plus récent et qu'ils sont configurés pour communiquer via des événements.

👉 Tout d'abord, nous allons recompiler et transférer l'image de l'agent planner. Pour cela, exécutez la commande suivante dans le terminal :
cd ~/aidemy-bootstrap/planner/
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/aidemy-planner .
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/aidemy-planner us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-planner
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-planner
👉 Nous allons faire de même, créer et transférer l'image de l'agent portal :
cd ~/aidemy-bootstrap/portal/
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/aidemy-portal .
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/aidemy-portal us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-portal
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-portal
👉 Accédez à Artifact Registry. Les images de conteneur aidemy-planner et aidemy-portal devraient s'afficher sous agent-repository.

👉 De retour dans le terminal, exécutez la commande suivante pour mettre à jour l'image Cloud Run de l'agent de planification :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services update aidemy-planner \
--region=us-central1 \
--image=us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-planner:latest
Le résultat doit ressembler à ce qui suit :
OK Deploying... Done.
OK Creating Revision...
OK Routing traffic...
Done.
Service [aidemy-planner] revision [aidemy-planner-xxxxx] has been deployed and is serving 100 percent of traffic.
Service URL: https://aidemy-planner-xxx.us-central1.run.app
Notez l'URL du service. Il s'agit du lien vers l'agent de planification que vous avez déployé. Si vous devez déterminer ultérieurement l'URL du service de l'agent de planification, utilisez la commande suivante :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services describe aidemy-planner \
--region=us-central1 \
--format 'value(status.url)'
👉 Exécutez cette commande pour créer l'instance Cloud Run pour l'agent portal.
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run deploy aidemy-portal \
--image=us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-portal:latest \
--region=us-central1 \
--platform=managed \
--allow-unauthenticated \
--memory=2Gi \
--cpu=2 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID}
Le résultat doit ressembler à ce qui suit :
Deploying container to Cloud Run service [aidemy-portal] in project [xxxx] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [aidemy-portal] revision [aidemy-portal-xxxx] has been deployed and is serving 100 percent of traffic.
Service URL: https://aidemy-portal-xxxx.us-central1.run.app
Notez l'URL du service. Il s'agit du lien vers le portail des élèves que vous avez déployé. Si vous devez déterminer ultérieurement l'URL du service du portail des élèves, utilisez la commande suivante :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services describe aidemy-portal \
--region=us-central1 \
--format 'value(status.url)'
Créer le déclencheur Eventarc
Mais voici la grande question : comment ce point de terminaison est-il averti lorsqu'un nouveau plan est disponible dans le sujet Pub/Sub ? C'est là qu'Eventarc intervient pour vous sauver la mise.
Eventarc sert de pont, en écoutant des événements spécifiques (comme l'arrivée d'un nouveau message dans notre sujet Pub/Sub) et en déclenchant automatiquement des actions en réponse. Dans notre cas, il détectera la publication d'un nouveau programme d'enseignement, puis enverra un signal au point de terminaison de notre portail pour l'informer qu'il est temps de mettre à jour.
Grâce à Eventarc qui gère la communication basée sur les événements, nous pouvons connecter de manière fluide notre agent de planification et notre agent de portail, créant ainsi un système d'apprentissage véritablement dynamique et réactif. C'est comme avoir un outil de messagerie intelligent qui envoie automatiquement les derniers plans de cours au bon endroit.
👉 Dans la console, accédez à Eventarc.
👉 Cliquez sur le bouton "+ CRÉER UN DÉCLENCHEUR".
Configurer le déclencheur (principes de base) :
- Nom du déclencheur :
plan-topic-trigger - Type de déclencheur : sources Google
- Fournisseur d'événements : Cloud Pub/Sub
- Type d'événement :
google.cloud.pubsub.topic.v1.messagePublished - Sujet Cloud Pub/Sub : sélectionnez
projects/PROJECT_ID/topics/plan. - Région :
us-central1. - Compte de service :
- ATTRIBUER le rôle
roles/iam.serviceAccountTokenCreatorau compte de service - Utiliser la valeur par défaut : compte de service Compute par défaut
- ATTRIBUER le rôle
- Destination de l'événement : Cloud Run
- Service Cloud Run :
aidemy-portal - Ignorer le message d'erreur : "Autorisation refusée pour 'locations/me-central2' (ou celle-ci n'existe peut-être pas)."
- Chemin de l'URL du service :
/new_teaching_plan
👉 Cliquez sur "Créer".
La page "Déclencheurs Eventarc" s'actualise. Le déclencheur que vous venez de créer doit maintenant figurer dans le tableau.
Accédez maintenant à l'agent planner à l'aide de son URL de service pour demander un nouveau plan d'enseignement.
👉 Exécutez cette commande dans le terminal pour déterminer l'URL du service de l'agent de planification :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services list --platform=managed --region=us-central1 --format='value(URL)' | grep planner
👉 Accédez à l'URL générée et essayez cette fois-ci les valeurs suivantes : Année 5, Sujet Science et Demande de module complémentaire atoms.
Attendez ensuite une ou deux minutes. Ce délai a été introduit en raison des limites de facturation de cet atelier. En temps normal, il ne devrait pas y avoir de délai.
Enfin, accédez au portail des élèves à l'aide de son URL de service.
Exécutez cette commande dans le terminal pour déterminer l'URL du service de l'agent du portail des élèves :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services list --platform=managed --region=us-central1 --format='value(URL)' | grep portal
Vous devriez voir que les quiz ont été mis à jour et qu'ils correspondent désormais au nouveau programme d'enseignement que vous venez de générer. Cela démontre l'intégration réussie d'Eventarc dans le système Aidemy.

Félicitations ! Vous avez créé un système multi-agents sur Google Cloud, en tirant parti de l'architecture basée sur les événements pour une évolutivité et une flexibilité améliorées. Vous avez acquis des bases solides, mais il y a encore bien plus à découvrir. Pour en savoir plus sur les avantages concrets de cette architecture, découvrir la puissance de l'API Live multimodale de Gemini 2 et apprendre à implémenter l'orchestration à chemin unique avec LangGraph, n'hésitez pas à passer aux deux chapitres suivants.
12. FACULTATIF : Résumés audio avec Gemini
Gemini peut comprendre et traiter des informations provenant de diverses sources, comme du texte, des images et même de l'audio. Il ouvre ainsi de nouvelles perspectives en termes d'apprentissage et de création de contenu. La capacité de Gemini à "voir", "entendre" et "lire" permet de créer des expériences utilisateur créatives et engageantes.
Au-delà de la simple création de visuels ou de texte, une autre étape importante de l'apprentissage est la synthèse et le récapitulatif efficaces. Pensez-y : combien de fois vous souvenez-vous plus facilement des paroles d'une chanson entraînante que d'un passage d'un manuel scolaire ? Le son peut être incroyablement mémorable ! C'est pourquoi nous allons exploiter les capacités multimodales de Gemini pour générer des résumés audio de nos plans de cours. Les élèves pourront ainsi réviser les contenus de manière pratique et stimulante, ce qui pourrait améliorer leur mémorisation et leur compréhension grâce à l'apprentissage auditif.

Nous avons besoin d'un emplacement pour stocker les fichiers audio générés. Cloud Storage fournit une solution évolutive et fiable.
👉 Accédez à Stockage dans la console. Cliquez sur "Buckets" dans le menu de gauche. Cliquez sur le bouton "+ CRÉER" en haut de la page.
👉 Configurez votre nouveau bucket :
- Nom du bucket :
aidemy-recap-UNIQUE_NAME.- IMPORTANT : Assurez-vous de définir un nom de bucket unique commençant par
aidemy-recap-. Ce préfixe unique est essentiel pour éviter les conflits de noms lors de la création de votre bucket Cloud Storage.
- IMPORTANT : Assurez-vous de définir un nom de bucket unique commençant par
- Région :
us-central1. - Classe de stockage : "Standard". Le stockage standard convient aux données auxquelles vous accédez fréquemment.
- Contrôle des accès : laissez le contrôle des accès "Uniforme" sélectionné par défaut. Cela permet un contrôle des accès cohérent au niveau du bucket.
- Options avancées : pour cet atelier, les paramètres par défaut sont généralement suffisants.
Cliquez sur le bouton CRÉER pour créer votre bucket.
- Un pop-up concernant la protection contre l'accès public peut s'afficher. Laissez la case "Appliquer la protection contre l'accès public sur ce bucket" cochée, puis cliquez sur
Confirm.
Vous devriez maintenant voir le bucket que vous venez de créer dans la liste des buckets. Mémorisez le nom de votre bucket, car vous en aurez besoin plus tard.
👉 Dans le terminal de l'éditeur Cloud Code, exécutez les commandes suivantes pour accorder au compte de service l'accès au bucket :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
gcloud storage buckets add-iam-policy-binding gs://$COURSE_BUCKET_NAME \
--member "serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role "roles/storage.objectViewer"
gcloud storage buckets add-iam-policy-binding gs://$COURSE_BUCKET_NAME \
--member "serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role "roles/storage.objectCreator"
👉 Dans l'éditeur Cloud Code, ouvrez audio.py dans le dossier courses. Collez le code suivant à la fin du fichier :
config = LiveConnectConfig(
response_modalities=["AUDIO"],
speech_config=SpeechConfig(
voice_config=VoiceConfig(
prebuilt_voice_config=PrebuiltVoiceConfig(
voice_name="Charon",
)
)
),
)
async def process_weeks(teaching_plan: str):
region = "us-east5" #To workaround onRamp quota limits
client = genai.Client(vertexai=True, project=PROJECT_ID, location=region)
clientAudio = genai.Client(vertexai=True, project=PROJECT_ID, location="us-central1")
async with clientAudio.aio.live.connect(
model=MODEL_ID,
config=config,
) as session:
for week in range(1, 4):
response = client.models.generate_content(
model="gemini-2.0-flash-001",
contents=f"Given the following teaching plan: {teaching_plan}, Extrace content plan for week {week}. And return just the plan, nothingh else " # Clarified prompt
)
prompt = f"""
Assume you are the instructor.
Prepare a concise and engaging recap of the key concepts and topics covered.
This recap should be suitable for generating a short audio summary for students.
Focus on the most important learnings and takeaways, and frame it as a direct address to the students.
Avoid overly formal language and aim for a conversational tone, tell a few jokes.
Teaching plan: {response.text} """
print(f"prompt --->{prompt}")
await session.send(input=prompt, end_of_turn=True)
with open(f"temp_audio_week_{week}.raw", "wb") as temp_file:
async for message in session.receive():
if message.server_content.model_turn:
for part in message.server_content.model_turn.parts:
if part.inline_data:
temp_file.write(part.inline_data.data)
data, samplerate = sf.read(f"temp_audio_week_{week}.raw", channels=1, samplerate=24000, subtype='PCM_16', format='RAW')
sf.write(f"course-week-{week}.wav", data, samplerate)
storage_client = storage.Client()
bucket = storage_client.bucket(BUCKET_NAME)
blob = bucket.blob(f"course-week-{week}.wav") # Or give it a more descriptive name
blob.upload_from_filename(f"course-week-{week}.wav")
print(f"Audio saved to GCS: gs://{BUCKET_NAME}/course-week-{week}.wav")
await session.close()
def breakup_sessions(teaching_plan: str):
asyncio.run(process_weeks(teaching_plan))
- Connexion de streaming : une connexion persistante est d'abord établie avec le point de terminaison de l'API Live. Contrairement à un appel d'API standard où vous envoyez une requête et obtenez une réponse, cette connexion reste ouverte pour un échange continu de données.
- Configuration multimodale : utilisez la configuration pour spécifier le type de sortie souhaité (dans ce cas, audio). Vous pouvez même spécifier les paramètres que vous souhaitez utiliser (par exemple, la sélection de la voix, l'encodage audio).
- Traitement asynchrone : cette API fonctionne de manière asynchrone, ce qui signifie qu'elle ne bloque pas le thread principal en attendant la fin de la génération audio. En traitant les données en temps réel et en envoyant le résultat par blocs, il offre une expérience quasi instantanée.
La question clé est maintenant de savoir quand ce processus de génération audio doit s'exécuter. Idéalement, nous souhaitons que les résumés audio soient disponibles dès qu'un nouveau plan de cours est créé. Comme nous avons déjà implémenté une architecture basée sur les événements en publiant le programme d'enseignement dans un sujet Pub/Sub, nous pouvons simplement nous abonner à ce sujet.
Toutefois, nous ne générons pas de nouveaux plans de cours très souvent. Il ne serait pas efficace d'avoir un agent en cours d'exécution et en attente de nouveaux plans en permanence. C'est pourquoi il est tout à fait logique de déployer cette logique de génération audio en tant que fonction Cloud Run.
En le déployant en tant que fonction, il reste inactif jusqu'à ce qu'un nouveau message soit publié dans le sujet Pub/Sub. Dans ce cas, la fonction est automatiquement déclenchée, ce qui génère les résumés audio et les stocke dans notre bucket.
👉 Sous le dossier courses du fichier main.py, ce fichier définit la fonction Cloud Run qui sera déclenchée lorsqu'un nouveau programme d'enseignement sera disponible. Il reçoit le plan et lance la génération du récapitulatif audio. Ajoutez l'extrait de code suivant à la fin du fichier.
@functions_framework.cloud_event
def process_teaching_plan(cloud_event):
print(f"CloudEvent received: {cloud_event.data}")
time.sleep(60)
try:
if isinstance(cloud_event.data.get('message', {}).get('data'), str): # Check for base64 encoding
data = json.loads(base64.b64decode(cloud_event.data['message']['data']).decode('utf-8'))
teaching_plan = data.get('teaching_plan') # Get the teaching plan
elif 'teaching_plan' in cloud_event.data: # No base64
teaching_plan = cloud_event.data["teaching_plan"]
else:
raise KeyError("teaching_plan not found") # Handle error explicitly
#Load the teaching_plan as string and from cloud event, call audio breakup_sessions
breakup_sessions(teaching_plan)
return "Teaching plan processed successfully", 200
except (json.JSONDecodeError, AttributeError, KeyError) as e:
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500
except Exception as e:
print(f"Error processing teaching plan: {e}")
return "Error processing teaching plan", 500
@functions_framework.cloud_event : ce décorateur marque la fonction comme fonction Cloud Run qui sera déclenchée par des CloudEvents.
Tester localement
👉 Nous allons exécuter cette opération dans un environnement virtuel et installer les bibliothèques Python nécessaires pour la fonction Cloud Run.
cd ~/aidemy-bootstrap/courses
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉 L'émulateur Cloud Run Functions nous permet de tester notre fonction localement avant de la déployer sur Google Cloud. Démarrez un émulateur local en exécutant la commande suivante :
functions-framework --target process_teaching_plan --signature-type=cloudevent --source main.py
👉 Pendant que l'émulateur est en cours d'exécution, vous pouvez lui envoyer des CloudEvents de test pour simuler la publication d'un nouveau programme d'enseignement. Dans un nouveau terminal :

👉 Exécuter :
curl -X POST \
http://localhost:8080/ \
-H "Content-Type: application/json" \
-H "ce-id: event-id-01" \
-H "ce-source: planner-agent" \
-H "ce-specversion: 1.0" \
-H "ce-type: google.cloud.pubsub.topic.v1.messagePublished" \
-d '{
"message": {
"data": "eyJ0ZWFjaGluZ19wbGFuIjogIldlZWsgMTogMkQgU2hhcGVzIGFuZCBBbmdsZXMgLSBEYXkgMTogUmV2aWV3IG9mIGJhc2ljIDJEIHNoYXBlcyAoc3F1YXJlcywgcmVjdGFuZ2xlcywgdHJpYW5nbGVzLCBjaXJjbGVzKS4gRGF5IDI6IEV4cGxvcmluZyBkaWZmZXJlbnQgdHlwZXMgb2YgdHJpYW5nbGVzIChlcXVpbGF0ZXJhbCwgaXNvc2NlbGVzLCBzY2FsZW5lLCByaWdodC1hbmdsZWQpLiBEYXkgMzogRXhwbG9yaW5nIHF1YWRyaWxhdGVyYWxzIChzcXVhcmUsIHJlY3RhbmdsZSwgcGFyYWxsZWxvZ3JhbSwgcmhvbWJ1cywgdHJhcGV6aXVtKS4gRGF5IDQ6IEludHJvZHVjdGlvbiB0byBhbmdsZXM6IHJpZ2h0IGFuZ2xlcywgYWN1dGUgYW5nbGVzLCBhbmQgb2J0dXNlIGFuZ2xlcy4gRGF5IDU6IE1lYXN1cmluZyBhbmdsZXMgdXNpbmcgYSBwcm90cmFjdG9yLiBXZWVrIDI6IDNEIFNoYXBlcyBhbmQgU3ltbWV0cnkgLSBEYXkgNjogSW50cm9kdWN0aW9uIHRvIDNEIHNoYXBlczogY3ViZXMsIGN1Ym9pZHMsIHNwaGVyZXMsIGN5bGluZGVycywgY29uZXMsIGFuZCBweXJhbWlkcy4gRGF5IDc6IERlc2NyaWJpbmcgM0Qgc2hhcGVzIHVzaW5nIGZhY2VzLCBlZGdlcywgYW5kIHZlcnRpY2VzLiBEYXkgODogUmVsYXRpbmcgMkQgc2hhcGVzIHRvIDNEIHNoYXBlcy4gRGF5IDk6IElkZW50aWZ5aW5nIGxpbmVzIG9mIHN5bW1ldHJ5IGluIDJEIHNoYXBlcy4gRGF5IDEwOiBDb21wbGV0aW5nIHN5bW1ldHJpY2FsIGZpZ3VyZXMuIFdlZWsgMzogUG9zaXRpb24sIERpcmVjdGlvbiwgYW5kIFByb2JsZW0gU29sdmluZyAtIERheSAxMTogRGVzY3JpYmluZyBwb3NpdGlvbiB1c2luZyBjb29yZGluYXRlcyBpbiB0aGUgZmlyc3QgcXVhZHJhbnQuIERheSAxMjogUGxvdHRpbmcgY29vcmRpbmF0ZXMgdG8gZHJhdyBzaGFwZXMuIERheSAxMzogVW5kZXJzdGFuZGluZyB0cmFuc2xhdGlvbiAoc2xpZGluZyBhIHNoYXBlKS4gRGF5IDE0OiBVbmRlcnN0YW5kaW5nIHJlZmxlY3Rpb24gKGZsaXBwaW5nIGEgc2hhcGUpLiBEYXkgMTU6IFByb2JsZW0tc29sdmluZyBhY3Rpdml0aWVzIGludm9sdmluZyBwZXJpbWV0ZXIsIGFyZWEsIGFuZCBtaXNzaW5nIGFuZ2xlcy4ifQ=="
}
}'
Plutôt que de rester les bras croisés en attendant la réponse, passez à l'autre terminal Cloud Shell. Vous pouvez observer la progression et les éventuels messages de sortie ou d'erreur générés par votre fonction dans le terminal de l'émulateur. 😁
Dans le deuxième terminal, vous devriez voir que OK a été renvoyé.
👉 Pour vérifier les données du bucket, accédez à Cloud Storage, sélectionnez l'onglet "Bucket", puis aidemy-recap-UNIQUE_NAME.

👉 Dans le terminal exécutant l'émulateur, saisissez ctrl+c pour quitter. Fermez le deuxième terminal. Fermez le deuxième terminal et exécutez "deactivate" pour quitter l'environnement virtuel.
deactivate
Déployer sur Google Cloud
 👉 Après avoir effectué des tests en local, il est temps de déployer l'agent de cours sur Google Cloud. Dans le terminal, exécutez les commandes suivantes :
👉 Après avoir effectué des tests en local, il est temps de déployer l'agent de cours sur Google Cloud. Dans le terminal, exécutez les commandes suivantes :
cd ~/aidemy-bootstrap/courses
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
gcloud functions deploy courses-agent \
--region=us-central1 \
--gen2 \
--source=. \
--runtime=python312 \
--trigger-topic=plan \
--entry-point=process_teaching_plan \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID},COURSE_BUCKET_NAME=$COURSE_BUCKET_NAME
Vérifiez le déploiement en accédant à Cloud Run dans la console Google Cloud.Un nouveau service nommé "courses-agent" devrait s'afficher.

Pour vérifier la configuration du déclencheur, cliquez sur le service courses-agent pour afficher ses détails. Accédez à l'onglet "DÉCLENCHEURS".
Un déclencheur configuré pour écouter les messages publiés dans le sujet du plan doit s'afficher.

Enfin, voyons comment l'exécuter de bout en bout.
👉 Nous devons configurer l'agent du portail pour qu'il sache où trouver les fichiers audio générés. Dans le terminal, exécutez la commande suivante :
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud run services update aidemy-portal \
--region=us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID},COURSE_BUCKET_NAME=$COURSE_BUCKET_NAME
👉 Essayez de générer un nouveau plan d'enseignement à l'aide de la page Web de l'agent de planification. Le démarrage peut prendre quelques minutes. Ne vous inquiétez pas, il s'agit d'un service sans serveur.
Pour accéder à l'agent de planification, obtenez son URL de service en exécutant la commande suivante dans le terminal :
gcloud run services list \
--platform=managed \
--region=us-central1 \
--format='value(URL)' | grep planner
Après avoir généré le nouveau plan, attendez deux à trois minutes que l'audio soit généré. Cette opération prendra quelques minutes de plus en raison des limites de facturation de ce compte d'atelier.
Pour vérifier si la fonction courses-agent a reçu le programme d'enseignement, consultez l'onglet "DÉCLENCHEURS" de la fonction. Actualisez régulièrement la page. Vous devriez finir par voir que la fonction a été appelée. Si la fonction n'a pas été appelée au bout de deux minutes, vous pouvez essayer de générer à nouveau le plan pédagogique. Toutefois, évitez de générer des plans de manière répétée et rapide, car chaque plan généré sera consommé et traité séquentiellement par l'agent, ce qui pourrait créer un backlog.

👉 Accédez au portail et cliquez sur "Cours". Trois cartes devraient s'afficher, chacune présentant un récap audio. Pour trouver l'URL de votre agent de portail :
gcloud run services list \
--platform=managed \
--region=us-central1 \
--format='value(URL)' | grep portal
Cliquez sur "Lecture" pour chaque cours afin de vous assurer que les résumés audio correspondent au programme pédagogique que vous venez de générer. 
Quittez l'environnement virtuel.
deactivate
13. FACULTATIF : Collaboration basée sur les rôles avec Gemini et DeepSeek
Il est essentiel de recueillir plusieurs points de vue, surtout lorsque vous créez des devoirs intéressants et réfléchis. Nous allons maintenant créer un système multi-agents qui exploite deux modèles différents avec des rôles distincts pour générer des devoirs : l'un favorise la collaboration et l'autre encourage l'étude autonome. Nous allons utiliser une architecture "single-shot", où le workflow suit un itinéraire fixe.
Générateur de devoirs Gemini
 Nous allons commencer par configurer la fonction Gemini pour générer des devoirs axés sur la collaboration. Modifiez le fichier
Nous allons commencer par configurer la fonction Gemini pour générer des devoirs axés sur la collaboration. Modifiez le fichier gemini.py situé dans le dossier assignment.
👉 Collez le code suivant à la fin du fichier gemini.py :
def gen_assignment_gemini(state):
region=get_next_region()
client = genai.Client(vertexai=True, project=PROJECT_ID, location=region)
print(f"---------------gen_assignment_gemini")
response = client.models.generate_content(
model=MODEL_ID, contents=f"""
You are an instructor
Develop engaging and practical assignments for each week, ensuring they align with the teaching plan's objectives and progressively build upon each other.
For each week, provide the following:
* **Week [Number]:** A descriptive title for the assignment (e.g., "Data Exploration Project," "Model Building Exercise").
* **Learning Objectives Assessed:** List the specific learning objectives from the teaching plan that this assignment assesses.
* **Description:** A detailed description of the task, including any specific requirements or constraints. Provide examples or scenarios if applicable.
* **Deliverables:** Specify what students need to submit (e.g., code, report, presentation).
* **Estimated Time Commitment:** The approximate time students should dedicate to completing the assignment.
* **Assessment Criteria:** Briefly outline how the assignment will be graded (e.g., correctness, completeness, clarity, creativity).
The assignments should be a mix of individual and collaborative work where appropriate. Consider different learning styles and provide opportunities for students to apply their knowledge creatively.
Based on this teaching plan: {state["teaching_plan"]}
"""
)
print(f"---------------gen_assignment_gemini answer {response.text}")
state["model_one_assignment"] = response.text
return state
import unittest
class TestGenAssignmentGemini(unittest.TestCase):
def test_gen_assignment_gemini(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assigmodel_one_assignmentnment": "", "final_assignment": ""}
updated_state = gen_assignment_gemini(initial_state)
self.assertIn("model_one_assignment", updated_state)
self.assertIsNotNone(updated_state["model_one_assignment"])
self.assertIsInstance(updated_state["model_one_assignment"], str)
self.assertGreater(len(updated_state["model_one_assignment"]), 0)
print(updated_state["model_one_assignment"])
if __name__ == '__main__':
unittest.main()
Il utilise le modèle Gemini pour générer des devoirs.
Nous sommes prêts à tester l'agent Gemini.
👉 Exécutez ces commandes dans le terminal pour configurer l'environnement :
cd ~/aidemy-bootstrap/assignment
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉 Vous pouvez exécuter le test :
python gemini.py
Vous devriez voir dans le résultat un devoir qui comporte plus de travaux de groupe. Le test d'assertion à la fin affichera également les résultats.
Here are some engaging and practical assignments for each week, designed to build progressively upon the teaching plan's objectives:
**Week 1: Exploring the World of 2D Shapes**
* **Learning Objectives Assessed:**
* Identify and name basic 2D shapes (squares, rectangles, triangles, circles).
* .....
* **Description:**
* **Shape Scavenger Hunt:** Students will go on a scavenger hunt in their homes or neighborhoods, taking pictures of objects that represent different 2D shapes. They will then create a presentation or poster showcasing their findings, classifying each shape and labeling its properties (e.g., number of sides, angles, etc.).
* **Triangle Trivia:** Students will research and create a short quiz or presentation about different types of triangles, focusing on their properties and real-world examples.
* **Angle Exploration:** Students will use a protractor to measure various angles in their surroundings, such as corners of furniture, windows, or doors. They will record their measurements and create a chart categorizing the angles as right, acute, or obtuse.
....
**Week 2: Delving into the World of 3D Shapes and Symmetry**
* **Learning Objectives Assessed:**
* Identify and name basic 3D shapes.
* ....
* **Description:**
* **3D Shape Construction:** Students will work in groups to build 3D shapes using construction paper, cardboard, or other materials. They will then create a presentation showcasing their creations, describing the number of faces, edges, and vertices for each shape.
* **Symmetry Exploration:** Students will investigate the concept of symmetry by creating a visual representation of various symmetrical objects (e.g., butterflies, leaves, snowflakes) using drawing or digital tools. They will identify the lines of symmetry and explain their findings.
* **Symmetry Puzzles:** Students will be given a half-image of a symmetrical figure and will be asked to complete the other half, demonstrating their understanding of symmetry. This can be done through drawing, cut-out activities, or digital tools.
**Week 3: Navigating Position, Direction, and Problem Solving**
* **Learning Objectives Assessed:**
* Describe position using coordinates in the first quadrant.
* ....
* **Description:**
* **Coordinate Maze:** Students will create a maze using coordinates on a grid paper. They will then provide directions for navigating the maze using a combination of coordinate movements and translation/reflection instructions.
* **Shape Transformations:** Students will draw shapes on a grid paper and then apply transformations such as translation and reflection, recording the new coordinates of the transformed shapes.
* **Geometry Challenge:** Students will solve real-world problems involving perimeter, area, and angles. For example, they could be asked to calculate the perimeter of a room, the area of a garden, or the missing angle in a triangle.
....
Arrêtez-vous à ctl+c et nettoyez le code de test. SUPPRIMEZ le code suivant de gemini.py
import unittest
class TestGenAssignmentGemini(unittest.TestCase):
def test_gen_assignment_gemini(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assigmodel_one_assignmentnment": "", "final_assignment": ""}
updated_state = gen_assignment_gemini(initial_state)
self.assertIn("model_one_assignment", updated_state)
self.assertIsNotNone(updated_state["model_one_assignment"])
self.assertIsInstance(updated_state["model_one_assignment"], str)
self.assertGreater(len(updated_state["model_one_assignment"]), 0)
print(updated_state["model_one_assignment"])
if __name__ == '__main__':
unittest.main()
Configurer le générateur de devoirs DeepSeek
Bien que les plates-formes d'IA basées sur le cloud soient pratiques, l'auto-hébergement des LLM peut être essentiel pour protéger la confidentialité et la souveraineté des données. Nous allons déployer le plus petit modèle DeepSeek (1,5 milliard de paramètres) sur une instance Cloud Compute Engine. Il existe d'autres méthodes, comme l'hébergement sur la plate-forme Vertex AI de Google ou sur votre instance GKE, mais comme il s'agit simplement d'un atelier sur les agents d'IA et que je ne veux pas vous retenir trop longtemps, nous allons utiliser la méthode la plus simple. Toutefois, si vous êtes intéressé et souhaitez explorer d'autres options, consultez le fichier deepseek-vertexai.py dans le dossier des devoirs, qui fournit un exemple de code pour interagir avec les modèles déployés sur Vertex AI.

👉 Exécutez cette commande dans le terminal pour créer une plate-forme LLM auto-hébergée Ollama :
cd ~/aidemy-bootstrap/assignment
gcloud config set project $(cat ~/project_id.txt)
gcloud compute instances create ollama-instance \
--image-family=ubuntu-2204-lts \
--image-project=ubuntu-os-cloud \
--machine-type=e2-standard-4 \
--zone=us-central1-a \
--metadata-from-file startup-script=startup.sh \
--boot-disk-size=50GB \
--tags=ollama \
--scopes=https://www.googleapis.com/auth/cloud-platform
Pour vérifier que l'instance Compute Engine est en cours d'exécution :
Dans la console Google Cloud, accédez à Compute Engine > "Instances de VM". Vous devriez voir ollama-instance avec une coche verte indiquant qu'il est en cours d'exécution. Si vous ne la voyez pas, assurez-vous que la zone est us-central1. Si ce n'est pas le cas, vous devrez peut-être le rechercher.

👉 Nous allons installer le plus petit modèle DeepSeek et le tester. De retour dans l'éditeur Cloud Shell, dans un nouveau terminal, exécutez la commande suivante pour accéder à l'instance GCE via SSH.
gcloud compute ssh ollama-instance --zone=us-central1-a
Une fois la connexion SSH établie, le message suivant peut s'afficher :
"Do you want to continue (Y/n)?" (Voulez-vous continuer (O/N) ?)
Saisissez simplement Y(sans tenir compte de la casse) et appuyez sur Entrée pour continuer.
Vous serez peut-être ensuite invité à créer une phrase secrète pour la clé SSH. Si vous préférez ne pas utiliser de phrase secrète, appuyez simplement deux fois sur Entrée pour accepter la valeur par défaut (aucune phrase secrète).
👉 Maintenant que vous êtes dans la machine virtuelle, extrayez le plus petit modèle DeepSeek R1 et testez son fonctionnement.
ollama pull deepseek-r1:1.5b
ollama run deepseek-r1:1.5b "who are you?"
👉 Quittez l'instance GCE en saisissant la commande suivante dans le terminal SSH :
exit
👉 Ensuite, configurez la règle de réseau pour que d'autres services puissent accéder au LLM. Si vous souhaitez le faire pour la production, veuillez limiter l'accès à l'instance en implémentant une connexion sécurisée pour le service ou en limitant l'accès à l'adresse IP. Exécutez la commande suivante :
gcloud compute firewall-rules create allow-ollama-11434 \
--allow=tcp:11434 \
--target-tags=ollama \
--description="Allow access to Ollama on port 11434"
👉 Pour vérifier que votre stratégie de pare-feu fonctionne correctement, essayez d'exécuter la commande suivante :
export OLLAMA_HOST=http://$(gcloud compute instances describe ollama-instance --zone=us-central1-a --format='value(networkInterfaces[0].accessConfigs[0].natIP)'):11434
curl -X POST "${OLLAMA_HOST}/api/generate" \
-H "Content-Type: application/json" \
-d '{
"prompt": "Hello, what are you?",
"model": "deepseek-r1:1.5b",
"stream": false
}'
Ensuite, nous allons travailler sur la fonction Deepseek dans l'agent de devoirs pour générer des devoirs axés sur le travail individuel.
👉 Modifiez deepseek.py dans le dossier assignment et ajoutez l'extrait suivant à la fin :
def gen_assignment_deepseek(state):
print(f"---------------gen_assignment_deepseek")
template = """
You are an instructor who favor student to focus on individual work.
Develop engaging and practical assignments for each week, ensuring they align with the teaching plan's objectives and progressively build upon each other.
For each week, provide the following:
* **Week [Number]:** A descriptive title for the assignment (e.g., "Data Exploration Project," "Model Building Exercise").
* **Learning Objectives Assessed:** List the specific learning objectives from the teaching plan that this assignment assesses.
* **Description:** A detailed description of the task, including any specific requirements or constraints. Provide examples or scenarios if applicable.
* **Deliverables:** Specify what students need to submit (e.g., code, report, presentation).
* **Estimated Time Commitment:** The approximate time students should dedicate to completing the assignment.
* **Assessment Criteria:** Briefly outline how the assignment will be graded (e.g., correctness, completeness, clarity, creativity).
The assignments should be a mix of individual and collaborative work where appropriate. Consider different learning styles and provide opportunities for students to apply their knowledge creatively.
Based on this teaching plan: {teaching_plan}
"""
prompt = ChatPromptTemplate.from_template(template)
model = OllamaLLM(model="deepseek-r1:1.5b",
base_url=OLLAMA_HOST)
chain = prompt | model
response = chain.invoke({"teaching_plan":state["teaching_plan"]})
state["model_two_assignment"] = response
return state
import unittest
class TestGenAssignmentDeepseek(unittest.TestCase):
def test_gen_assignment_deepseek(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assignment": "", "final_assignment": ""}
updated_state = gen_assignment_deepseek(initial_state)
self.assertIn("model_two_assignment", updated_state)
self.assertIsNotNone(updated_state["model_two_assignment"])
self.assertIsInstance(updated_state["model_two_assignment"], str)
self.assertGreater(len(updated_state["model_two_assignment"]), 0)
print(updated_state["model_two_assignment"])
if __name__ == '__main__':
unittest.main()
👉 Testons-le en exécutant :
cd ~/aidemy-bootstrap/assignment
source env/bin/activate
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export OLLAMA_HOST=http://$(gcloud compute instances describe ollama-instance --zone=us-central1-a --format='value(networkInterfaces[0].accessConfigs[0].natIP)'):11434
python deepseek.py
Vous devriez voir un devoir qui comporte plus de travail d'étude personnelle.
**Assignment Plan for Each Week**
---
### **Week 1: 2D Shapes and Angles**
- **Week Title:** "Exploring 2D Shapes"
Assign students to research and present on various 2D shapes. Include a project where they create models using straws and tape for triangles, draw quadrilaterals with specific measurements, and compare their properties.
### **Week 2: 3D Shapes and Symmetry**
Assign students to create models or nets for cubes and cuboids. They will also predict how folding these nets form the 3D shapes. Include a project where they identify symmetrical properties using mirrors or folding techniques.
### **Week 3: Position, Direction, and Problem Solving**
Assign students to use mirrors or folding techniques for reflections. Include activities where they measure angles, use a protractor, solve problems involving perimeter/area, and create symmetrical designs.
....
👉 Arrêtez le ctl+c et nettoyez le code de test. SUPPRIMEZ le code suivant de deepseek.py
import unittest
class TestGenAssignmentDeepseek(unittest.TestCase):
def test_gen_assignment_deepseek(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assignment": "", "final_assignment": ""}
updated_state = gen_assignment_deepseek(initial_state)
self.assertIn("model_two_assignment", updated_state)
self.assertIsNotNone(updated_state["model_two_assignment"])
self.assertIsInstance(updated_state["model_two_assignment"], str)
self.assertGreater(len(updated_state["model_two_assignment"]), 0)
print(updated_state["model_two_assignment"])
if __name__ == '__main__':
unittest.main()
Nous allons maintenant utiliser le même modèle Gemini pour combiner les deux devoirs en un seul. Modifiez le fichier gemini.py situé dans le dossier assignment.
👉 Collez le code suivant à la fin du fichier gemini.py :
def combine_assignments(state):
print(f"---------------combine_assignments ")
region=get_next_region()
client = genai.Client(vertexai=True, project=PROJECT_ID, location=region)
response = client.models.generate_content(
model=MODEL_ID, contents=f"""
Look at all the proposed assignment so far {state["model_one_assignment"]} and {state["model_two_assignment"]}, combine them and come up with a final assignment for student.
"""
)
state["final_assignment"] = response.text
return state
Pour combiner les points forts des deux modèles, nous allons orchestrer un workflow défini à l'aide de LangGraph. Ce workflow se compose de trois étapes : tout d'abord, le modèle Gemini génère un devoir axé sur la collaboration ; ensuite, le modèle DeepSeek génère un devoir axé sur le travail individuel ; enfin, Gemini synthétise ces deux devoirs en un seul devoir complet. Comme nous prédéfinissons la séquence d'étapes sans prise de décision par le LLM, il s'agit d'une orchestration à chemin unique définie par l'utilisateur.

👉 Collez le code suivant à la fin du fichier main.py dans le dossier assignment :
def create_assignment(teaching_plan: str):
print(f"create_assignment---->{teaching_plan}")
builder = StateGraph(State)
builder.add_node("gen_assignment_gemini", gen_assignment_gemini)
builder.add_node("gen_assignment_deepseek", gen_assignment_deepseek)
builder.add_node("combine_assignments", combine_assignments)
builder.add_edge(START, "gen_assignment_gemini")
builder.add_edge("gen_assignment_gemini", "gen_assignment_deepseek")
builder.add_edge("gen_assignment_deepseek", "combine_assignments")
builder.add_edge("combine_assignments", END)
graph = builder.compile()
state = graph.invoke({"teaching_plan": teaching_plan})
return state["final_assignment"]
import unittest
class TestCreateAssignment(unittest.TestCase):
def test_create_assignment(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assignment": "", "final_assignment": ""}
updated_state = create_assignment(initial_state)
print(updated_state)
if __name__ == '__main__':
unittest.main()
👉 Pour tester initialement la fonction create_assignment et vérifier que le workflow combinant Gemini et DeepSeek est fonctionnel, exécutez la commande suivante :
cd ~/aidemy-bootstrap/assignment
source env/bin/activate
pip install -r requirements.txt
python main.py
Vous devriez voir quelque chose qui combine les deux modèles avec leur perspective individuelle pour les études des élèves et pour les travaux de groupe.
**Tasks:**
1. **Clue Collection:** Gather all the clues left by the thieves. These clues will include:
* Descriptions of shapes and their properties (angles, sides, etc.)
* Coordinate grids with hidden messages
* Geometric puzzles requiring transformation (translation, reflection, rotation)
* Challenges involving area, perimeter, and angle calculations
2. **Clue Analysis:** Decipher each clue using your geometric knowledge. This will involve:
* Identifying the shape and its properties
* Plotting coordinates and interpreting patterns on the grid
* Solving geometric puzzles by applying transformations
* Calculating area, perimeter, and missing angles
3. **Case Report:** Create a comprehensive case report outlining your findings. This report should include:
* A detailed explanation of each clue and its solution
* Sketches and diagrams to support your explanations
* A step-by-step account of how you followed the clues to locate the artifact
* A final conclusion about the thieves and their motives
👉 Arrêtez le ctl+c et nettoyez le code de test. SUPPRIMEZ le code suivant de main.py
import unittest
class TestCreateAssignment(unittest.TestCase):
def test_create_assignment(self):
test_teaching_plan = "Week 1: 2D Shapes and Angles - Day 1: Review of basic 2D shapes (squares, rectangles, triangles, circles). Day 2: Exploring different types of triangles (equilateral, isosceles, scalene, right-angled). Day 3: Exploring quadrilaterals (square, rectangle, parallelogram, rhombus, trapezium). Day 4: Introduction to angles: right angles, acute angles, and obtuse angles. Day 5: Measuring angles using a protractor. Week 2: 3D Shapes and Symmetry - Day 6: Introduction to 3D shapes: cubes, cuboids, spheres, cylinders, cones, and pyramids. Day 7: Describing 3D shapes using faces, edges, and vertices. Day 8: Relating 2D shapes to 3D shapes. Day 9: Identifying lines of symmetry in 2D shapes. Day 10: Completing symmetrical figures. Week 3: Position, Direction, and Problem Solving - Day 11: Describing position using coordinates in the first quadrant. Day 12: Plotting coordinates to draw shapes. Day 13: Understanding translation (sliding a shape). Day 14: Understanding reflection (flipping a shape). Day 15: Problem-solving activities involving perimeter, area, and missing angles."
initial_state = {"teaching_plan": test_teaching_plan, "model_one_assignment": "", "model_two_assignment": "", "final_assignment": ""}
updated_state = create_assignment(initial_state)
print(updated_state)
if __name__ == '__main__':
unittest.main()

Pour automatiser le processus de génération des devoirs et l'adapter aux nouveaux plans d'enseignement, nous allons tirer parti de l'architecture événementielle existante. Le code suivant définit une fonction Cloud Run (generate_assignment) qui se déclenche chaque fois qu'un nouveau programme d'enseignement est publié dans le sujet Pub/Sub plan.
👉 Ajoutez le code suivant à la fin de main.py dans le dossier assignment :
@functions_framework.cloud_event
def generate_assignment(cloud_event):
print(f"CloudEvent received: {cloud_event.data}")
try:
if isinstance(cloud_event.data.get('message', {}).get('data'), str):
data = json.loads(base64.b64decode(cloud_event.data['message']['data']).decode('utf-8'))
teaching_plan = data.get('teaching_plan')
elif 'teaching_plan' in cloud_event.data:
teaching_plan = cloud_event.data["teaching_plan"]
else:
raise KeyError("teaching_plan not found")
assignment = create_assignment(teaching_plan)
print(f"Assignment---->{assignment}")
#Store the return assignment into bucket as a text file
storage_client = storage.Client()
bucket = storage_client.bucket(ASSIGNMENT_BUCKET)
file_name = f"assignment-{random.randint(1, 1000)}.txt"
blob = bucket.blob(file_name)
blob.upload_from_string(assignment)
return f"Assignment generated and stored in {ASSIGNMENT_BUCKET}/{file_name}", 200
except (json.JSONDecodeError, AttributeError, KeyError) as e:
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500
except Exception as e:
print(f"Error generate assignment: {e}")
return "Error generate assignment", 500
Tester localement
Avant de déployer une fonction Cloud Run sur Google Cloud, il est recommandé de la tester localement. Cela permet d'accélérer l'itération et de faciliter le débogage.
Commencez par créer un bucket Cloud Storage pour stocker les fichiers de devoirs générés, puis accordez au compte de service l'accès à ce bucket. Exécutez les commandes suivantes dans le terminal :
👉 IMPORTANT : Veillez à définir un nom ASSIGNMENT_BUCKET unique qui commence par "aidemy-assignment-". Ce nom unique est essentiel pour éviter les conflits de noms lors de la création de votre bucket Cloud Storage. (Remplacez <YOUR_NAME> par un mot aléatoire.)
export ASSIGNMENT_BUCKET=aidemy-assignment-<YOUR_NAME> #Name must be unqiue
👉 Exécutez ensuite la commande ci-dessous :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
gsutil mb -p $PROJECT_ID -l us-central1 gs://$ASSIGNMENT_BUCKET
gcloud storage buckets add-iam-policy-binding gs://$ASSIGNMENT_BUCKET \
--member "serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role "roles/storage.objectViewer"
gcloud storage buckets add-iam-policy-binding gs://$ASSIGNMENT_BUCKET \
--member "serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role "roles/storage.objectCreator"
👉 Démarrez maintenant l'émulateur Cloud Run Functions :
cd ~/aidemy-bootstrap/assignment
functions-framework \
--target generate_assignment \
--signature-type=cloudevent \
--source main.py
👉 Pendant que l'émulateur s'exécute dans un terminal, ouvrez un deuxième terminal dans Cloud Shell. Dans ce deuxième terminal, envoyez un CloudEvent de test à l'émulateur pour simuler la publication d'un nouveau programme d'enseignement :
curl -X POST \
http://localhost:8080/ \
-H "Content-Type: application/json" \
-H "ce-id: event-id-01" \
-H "ce-source: planner-agent" \
-H "ce-specversion: 1.0" \
-H "ce-type: google.cloud.pubsub.topic.v1.messagePublished" \
-d '{
"message": {
"data": "eyJ0ZWFjaGluZ19wbGFuIjogIldlZWsgMTogMkQgU2hhcGVzIGFuZCBBbmdsZXMgLSBEYXkgMTogUmV2aWV3IG9mIGJhc2ljIDJEIHNoYXBlcyAoc3F1YXJlcywgcmVjdGFuZ2xlcywgdHJpYW5nbGVzLCBjaXJjbGVzKS4gRGF5IDI6IEV4cGxvcmluZyBkaWZmZXJlbnQgdHlwZXMgb2YgdHJpYW5nbGVzIChlcXVpbGF0ZXJhbCwgaXNvc2NlbGVzLCBzY2FsZW5lLCByaWdodC1hbmdsZWQpLiBEYXkgMzogRXhwbG9yaW5nIHF1YWRyaWxhdGVyYWxzIChzcXVhcmUsIHJlY3RhbmdsZSwgcGFyYWxsZWxvZ3JhbSwgcmhvbWJ1cywgdHJhcGV6aXVtKS4gRGF5IDQ6IEludHJvZHVjdGlvbiB0byBhbmdsZXM6IHJpZ2h0IGFuZ2xlcywgYWN1dGUgYW5nbGVzLCBhbmQgb2J0dXNlIGFuZ2xlcy4gRGF5IDU6IE1lYXN1cmluZyBhbmdsZXMgdXNpbmcgYSBwcm90cmFjdG9yLiBXZWVrIDI6IDNEIFNoYXBlcyBhbmQgU3ltbWV0cnkgLSBEYXkgNjogSW50cm9kdWN0aW9uIHRvIDNEIHNoYXBlczogY3ViZXMsIGN1Ym9pZHMsIHNwaGVyZXMsIGN5bGluZGVycywgY29uZXMsIGFuZCBweXJhbWlkcy4gRGF5IDc6IERlc2NyaWJpbmcgM0Qgc2hhcGVzIHVzaW5nIGZhY2VzLCBlZGdlcywgYW5kIHZlcnRpY2VzLiBEYXkgODogUmVsYXRpbmcgMkQgc2hhcGVzIHRvIDNEIHNoYXBlcy4gRGF5IDk6IElkZW50aWZ5aW5nIGxpbmVzIG9mIHN5bW1ldHJ5IGluIDJEIHNoYXBlcy4gRGF5IDEwOiBDb21wbGV0aW5nIHN5bW1ldHJpY2FsIGZpZ3VyZXMuIFdlZWsgMzogUG9zaXRpb24sIERpcmVjdGlvbiwgYW5kIFByb2JsZW0gU29sdmluZyAtIERheSAxMTogRGVzY3JpYmluZyBwb3NpdGlvbiB1c2luZyBjb29yZGluYXRlcyBpbiB0aGUgZmlyc3QgcXVhZHJhbnQuIERheSAxMjogUGxvdHRpbmcgY29vcmRpbmF0ZXMgdG8gZHJhdyBzaGFwZXMuIERheSAxMzogVW5kZXJzdGFuZGluZyB0cmFuc2xhdGlvbiAoc2xpZGluZyBhIHNoYXBlKS4gRGF5IDE0OiBVbmRlcnN0YW5kaW5nIHJlZmxlY3Rpb24gKGZsaXBwaW5nIGEgc2hhcGUpLiBEYXkgMTU6IFByb2JsZW0tc29sdmluZyBhY3Rpdml0aWVzIGludm9sdmluZyBwZXJpbWV0ZXIsIGFyZWEsIGFuZCBtaXNzaW5nIGFuZ2xlcy4ifQ=="
}
}'
Plutôt que de rester les bras croisés en attendant la réponse, passez à l'autre terminal Cloud Shell. Vous pouvez observer la progression et les éventuels messages de sortie ou d'erreur générés par votre fonction dans le terminal de l'émulateur. 😁
La commande curl doit afficher "OK" (sans saut de ligne, de sorte que "OK" peut apparaître sur la même ligne que l'invite de commande de votre terminal).
Pour vérifier que l'attribution a bien été générée et stockée, accédez à la console Google Cloud, puis à Stockage > "Cloud Storage". Sélectionnez le bucket aidemy-assignment que vous avez créé. Un fichier texte nommé assignment-{random number}.txt devrait s'afficher dans le bucket. Cliquez sur le fichier pour le télécharger et vérifier son contenu. Cela permet de vérifier qu'un nouveau fichier contient la nouvelle tâche qui vient d'être générée.

👉 Dans le terminal exécutant l'émulateur, saisissez ctrl+c pour quitter. Fermez le deuxième terminal. 👉 Dans le terminal exécutant l'émulateur, quittez l'environnement virtuel.
deactivate
👉 Ensuite, nous allons déployer l'agent d'attribution dans le cloud.
cd ~/aidemy-bootstrap/assignment
export ASSIGNMENT_BUCKET=$(gcloud storage buckets list --format="value(name)" | grep aidemy-assignment)
export OLLAMA_HOST=http://$(gcloud compute instances describe ollama-instance --zone=us-central1-a --format='value(networkInterfaces[0].accessConfigs[0].natIP)'):11434
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud functions deploy assignment-agent \
--gen2 \
--timeout=540 \
--memory=2Gi \
--cpu=1 \
--set-env-vars="ASSIGNMENT_BUCKET=${ASSIGNMENT_BUCKET}" \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${GOOGLE_CLOUD_PROJECT} \
--set-env-vars=OLLAMA_HOST=${OLLAMA_HOST} \
--region=us-central1 \
--runtime=python312 \
--source=. \
--entry-point=generate_assignment \
--trigger-topic=plan
Vérifiez le déploiement en accédant à la console Google Cloud, puis à Cloud Run. Un nouveau service nommé "courses-agent" doit s'afficher. 
Maintenant que le workflow de génération des devoirs est implémenté, testé et déployé, nous pouvons passer à l'étape suivante : rendre ces devoirs accessibles dans le portail des élèves.
14. FACULTATIF : Collaboration basée sur les rôles avec Gemini et DeepSeek (suite)
Génération de sites Web dynamiques
Pour améliorer le portail des élèves et le rendre plus attrayant, nous allons implémenter la génération HTML dynamique pour les pages des devoirs. L'objectif est de mettre à jour automatiquement le portail avec un design moderne et attrayant chaque fois qu'un nouveau devoir est généré. Cela exploite les capacités de codage du LLM pour créer une expérience utilisateur plus dynamique et intéressante.

👉 Dans l'éditeur Cloud Shell, modifiez le fichier render.py dans le dossier portal et remplacez
def render_assignment_page():
return ""
avec l'extrait de code suivant :
def render_assignment_page(assignment: str):
try:
region=get_next_region()
llm = VertexAI(model_name="gemini-2.0-flash-001", location=region)
input_msg = HumanMessage(content=[f"Here the assignment {assignment}"])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"""
As a frontend developer, create HTML to display a student assignment with a creative look and feel. Include the following navigation bar at the top:
```
<nav>
<a href="/">Home</a>
<a href="/quiz">Quizzes</a>
<a href="/courses">Courses</a>
<a href="/assignment">Assignments</a>
</nav>
```
Also include these links in the <head> section:
```
<link rel="stylesheet" href="{{ url_for('static', filename='style.css') }}">
<link rel="preconnect" href="https://fonts.googleapis.com">
<link rel="preconnect" href="https://fonts.gstatic.com" crossorigin>
<link href="https://fonts.googleapis.com/css2?family=Roboto:wght@400;500&display=swap" rel="stylesheet">
```
Do not apply inline styles to the navigation bar.
The HTML should display the full assignment content. In its CSS, be creative with the rainbow colors and aesthetic.
Make it creative and pretty
The assignment content should be well-structured and easy to read.
respond with JUST the html file
"""
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
response = response.replace("```html", "")
response = response.replace("```", "")
with open("templates/assignment.html", "w") as f:
f.write(response)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
Il utilise le modèle Gemini pour générer dynamiquement le code HTML du devoir. Il prend le contenu du devoir comme entrée et utilise une requête pour demander à Gemini de créer une page HTML visuellement attrayante avec un style créatif.
Ensuite, nous allons créer un point de terminaison qui sera déclenché chaque fois qu'un nouveau document sera ajouté au bucket d'attribution :
👉 Dans le dossier du portail, modifiez le fichier app.py et REMPLACEZ la ligne ## REPLACE ME! RENDER ASSIGNMENT par le code suivant :
@app.route('/render_assignment', methods=['POST'])
def render_assignment():
try:
data = request.get_json()
file_name = data.get('name')
bucket_name = data.get('bucket')
if not file_name or not bucket_name:
return jsonify({'error': 'Missing file name or bucket name'}), 400
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_name)
content = blob.download_as_text()
print(f"File content: {content}")
render_assignment_page(content)
return jsonify({'message': 'Assignment rendered successfully'})
except Exception as e:
print(f"Error processing file: {e}")
return jsonify({'error': 'Error processing file'}), 500
Lorsqu'elle est déclenchée, elle récupère le nom du fichier et le nom du bucket à partir des données de la requête, télécharge le contenu du devoir depuis Cloud Storage et appelle la fonction render_assignment_page pour générer le code HTML.
👉 Exécutons-le en local :
cd ~/aidemy-bootstrap/portal
source env/bin/activate
python app.py
👉 Dans le menu "Aperçu sur le Web" en haut de la fenêtre Cloud Shell, sélectionnez "Prévisualiser sur le port 8080". Votre application s'ouvre dans un nouvel onglet du navigateur. Accédez au lien Devoir dans la barre de navigation. À ce stade, vous devriez voir une page vierge. C'est normal, car nous n'avons pas encore établi le pont de communication entre l'agent d'attribution et le portail pour remplir le contenu de manière dynamique.

Arrêtez le script en appuyant sur Ctrl+C.
👉 Pour intégrer ces modifications et déployer le code mis à jour, recréez et transférez l'image de l'agent du portail :
cd ~/aidemy-bootstrap/portal/
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/aidemy-portal .
docker tag gcr.io/${PROJECT_ID}/aidemy-portal us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-portal
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/agent-repository/aidemy-portal
👉 Après avoir transféré la nouvelle image, redéployez le service Cloud Run. Exécutez le script suivant pour forcer la mise à jour de Cloud Run :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
gcloud run services update aidemy-portal \
--region=us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID},COURSE_BUCKET_NAME=$COURSE_BUCKET_NAME
👉 Nous allons maintenant déployer un déclencheur Eventarc qui écoute tout nouvel objet créé (finalisé) dans le bucket d'attribution. Ce déclencheur appellera automatiquement le point de terminaison /render_assignment sur le service de portail lorsqu'un fichier de devoir sera créé.
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$(gcloud storage service-agent --project $PROJECT_ID)" \
--role="roles/pubsub.publisher"
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
gcloud eventarc triggers create portal-assignment-trigger \
--location=us-central1 \
--service-account=$SERVICE_ACCOUNT_NAME \
--destination-run-service=aidemy-portal \
--destination-run-region=us-central1 \
--destination-run-path="/render_assignment" \
--event-filters="bucket=$ASSIGNMENT_BUCKET" \
--event-filters="type=google.cloud.storage.object.v1.finalized"
Pour vérifier que le déclencheur a bien été créé, accédez à la page Déclencheurs Eventarc dans la console Google Cloud. Vous devriez voir portal-assignment-trigger dans le tableau. Cliquez sur le nom du déclencheur pour afficher ses détails. 
Un délai de deux à trois minutes peut être nécessaire pour que le nouveau déclencheur devienne actif.
Pour voir la génération d'attribution dynamique en action, exécutez la commande suivante pour trouver l'URL de votre agent de planification (si vous ne l'avez pas sous la main) :
gcloud run services list --platform=managed --region=us-central1 --format='value(URL)' | grep planner
Trouvez l'URL de votre agent de portail :
gcloud run services list --platform=managed --region=us-central1 --format='value(URL)' | grep portal
Dans l'agent de planification, générez un nouveau plan d'enseignement.

Après quelques minutes (pour permettre la génération audio, la génération des devoirs et le rendu HTML), accédez au portail des élèves.
👉 Cliquez sur le lien "Devoir" dans la barre de navigation. Vous devriez voir un devoir nouvellement créé avec un code HTML généré de manière dynamique. Chaque fois qu'un plan de cours est généré, il doit s'agir d'un devoir dynamique.

Félicitations ! Vous avez terminé le cours Système multi-agents Aidemy. Vous avez acquis de l'expérience pratique et des insights précieux sur :
- Avantages des systèmes multi-agents, y compris la modularité, l'évolutivité, la spécialisation et la maintenance simplifiée.
- L'importance des architectures basées sur des événements pour créer des applications réactives et faiblement couplées.
- L'utilisation stratégique des LLM, en associant le bon modèle à la tâche et en les intégrant à des outils pour un impact concret.
- Pratiques de développement cloud natif utilisant les services Google Cloud pour créer des solutions évolutives et fiables.
- L'importance de prendre en compte la confidentialité des données et les modèles d'auto-hébergement comme alternative aux solutions des fournisseurs.
Vous disposez désormais de bases solides pour créer des applications sophistiquées optimisées par l'IA sur Google Cloud.
15. Défis et prochaines étapes
Félicitations pour avoir créé le système multi-agents Aidemy ! Vous avez posé des bases solides pour l'enseignement optimisé par l'IA. Examinons maintenant quelques défis et améliorations potentielles pour étendre davantage ses capacités et répondre aux besoins concrets :
Apprentissage interactif avec questions/réponses en direct :
- Défi : pouvez-vous exploiter l'API Live de Gemini 2 pour créer une fonctionnalité de questions-réponses en temps réel pour les élèves ? Imaginez une salle de classe virtuelle où les élèves peuvent poser des questions et recevoir des réponses immédiates optimisées par l'IA.
Envoi et notation automatiques des devoirs :
- Défi : concevoir et implémenter un système permettant aux élèves de rendre leurs devoirs au format numérique et de les faire noter automatiquement par l'IA, avec un mécanisme de détection et de prévention du plagiat. Ce défi est une excellente occasion d'explorer la génération augmentée par récupération (RAG) pour améliorer la précision et la fiabilité des processus de notation et de détection du plagiat.

16. Effectuer un nettoyage
Maintenant que nous avons créé et exploré notre système multi-agents Aidemy, il est temps de nettoyer notre environnement Google Cloud.
👉 Supprimer des services Cloud Run
gcloud run services delete aidemy-planner --region=us-central1 --quiet
gcloud run services delete aidemy-portal --region=us-central1 --quiet
gcloud run services delete courses-agent --region=us-central1 --quiet
gcloud run services delete book-provider --region=us-central1 --quiet
gcloud run services delete assignment-agent --region=us-central1 --quiet
👉 Supprimer un déclencheur Eventarc
gcloud eventarc triggers delete portal-assignment-trigger --location=us --quiet
gcloud eventarc triggers delete plan-topic-trigger --location=us-central1 --quiet
gcloud eventarc triggers delete portal-assignment-trigger --location=us-central1 --quiet
ASSIGNMENT_AGENT_TRIGGER=$(gcloud eventarc triggers list --project="$PROJECT_ID" --location=us-central1 --filter="name:assignment-agent" --format="value(name)")
COURSES_AGENT_TRIGGER=$(gcloud eventarc triggers list --project="$PROJECT_ID" --location=us-central1 --filter="name:courses-agent" --format="value(name)")
gcloud eventarc triggers delete $ASSIGNMENT_AGENT_TRIGGER --location=us-central1 --quiet
gcloud eventarc triggers delete $COURSES_AGENT_TRIGGER --location=us-central1 --quiet
👉 Supprimer un sujet Pub/Sub
gcloud pubsub topics delete plan --project="$PROJECT_ID" --quiet
👉 Supprimer une instance Cloud SQL
gcloud sql instances delete aidemy --quiet
👉 Supprimer le dépôt Artifact Registry
gcloud artifacts repositories delete agent-repository --location=us-central1 --quiet
👉 Supprimer les secrets Secret Manager
gcloud secrets delete db-user --quiet
gcloud secrets delete db-pass --quiet
gcloud secrets delete db-name --quiet
👉 Supprimez l'instance Compute Engine (si elle a été créée pour Deepseek).
gcloud compute instances delete ollama-instance --zone=us-central1-a --quiet
👉 Supprimez la règle de pare-feu pour l'instance Deepseek.
gcloud compute firewall-rules delete allow-ollama-11434 --quiet
👉 Supprimer les buckets Cloud Storage
export COURSE_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep aidemy-recap)
export ASSIGNMENT_BUCKET=$(gcloud storage buckets list --format="value(name)" | grep aidemy-assignment)
gsutil rm -r gs://$COURSE_BUCKET_NAME
gsutil rm -r gs://$ASSIGNMENT_BUCKET
