
1. Giới thiệu
Trong lớp học lập trình này, bạn sẽ tìm hiểu cách tăng tốc quy trình khoa học dữ liệu và học máy trên các tập dữ liệu lớn bằng cách sử dụng GPU NVIDIA và các thư viện nguồn mở trên Google Cloud. Bạn sẽ bắt đầu bằng cách thiết lập cơ sở hạ tầng, sau đó tìm hiểu cách áp dụng tính năng tăng tốc GPU.
Bạn sẽ tập trung vào vòng đời khoa học dữ liệu, từ việc chuẩn bị dữ liệu bằng pandas đến huấn luyện mô hình bằng scikit-learn và XGBoost. Bạn sẽ tìm hiểu cách tăng tốc các tác vụ này bằng cách sử dụng các thư viện cuDF và cuML của NVIDIA. Điều tuyệt vời nhất là bạn có thể sử dụng tính năng tăng tốc GPU này mà không cần thay đổi mã pandas hoặc scikit-learn hiện có.
Kiến thức bạn sẽ học được
- Tìm hiểu về Colab Enterprise trên Google Cloud.
- Tuỳ chỉnh môi trường thời gian chạy Colab bằng các cấu hình GPU và bộ nhớ cụ thể.
- Áp dụng tính năng tăng tốc GPU để dự đoán số tiền tiền boa bằng cách sử dụng hàng triệu bản ghi từ một tập dữ liệu về Taxi ở Thành phố New York.
- Tăng tốc
pandasmà không cần thay đổi mã bằng thư việncuDFcủa NVIDIA. - Tăng tốc
scikit-learnmà không cần thay đổi mã bằng cách sử dụng thư việncuMLvà GPU của NVIDIA. - Phân tích mã của bạn để xác định và tối ưu hoá các hạn chế về hiệu suất.
2. Tại sao cần tăng tốc quá trình học máy?
Nhu cầu về việc lặp lại nhanh hơn trong học máy
Việc chuẩn bị dữ liệu tốn nhiều thời gian, và việc huấn luyện hoặc đánh giá mô hình có thể mất nhiều thời gian hơn nữa khi tập dữ liệu tăng lên. Việc huấn luyện các mô hình như rừng ngẫu nhiên hoặc XGBoost trên hàng triệu hàng bằng CPU có thể mất nhiều giờ hoặc nhiều ngày.
Việc sử dụng GPU giúp tăng tốc các lần chạy huấn luyện này bằng các thư viện như cuML và XGBoost tăng tốc bằng GPU. Tính năng tăng tốc này giúp bạn:
- Lặp lại nhanh hơn: Nhanh chóng kiểm thử các tính năng và siêu tham số mới.
- Huấn luyện trên toàn bộ tập dữ liệu: Sử dụng toàn bộ dữ liệu thay vì lấy mẫu xuống để có độ chính xác cao hơn.
- Giảm chi phí: Hoàn thành các khối lượng công việc lớn trong thời gian ngắn hơn để giảm chi phí tính toán.
3. Thiết lập và yêu cầu
Chi phí tiềm ẩn
Lớp học lập trình này sử dụng các tài nguyên của Google Cloud, bao gồm cả môi trường thời gian chạy Colab Enterprise có GPU NVIDIA L4. Xin lưu ý về các khoản phí có thể phát sinh và làm theo phần Dọn dẹp ở cuối lớp học lập trình để tắt các tài nguyên và tránh bị tính phí liên tục. Để biết thông tin chi tiết về giá, hãy tham khảo bài viết Giá của Colab Enterprise và Giá của GPU.
Trước khi bắt đầu
Bạn cần có kiến thức cơ bản về Python, pandas, scikit-learn và các phương pháp học máy tiêu chuẩn (chẳng hạn như xác thực chéo/kết hợp).
- Trong Google Cloud Console, trên trang chọn dự án, hãy chọn hoặc tạo một dự án Google Cloud.
- Đảm bảo bạn đã bật tính năng thanh toán cho dự án trên Google Cloud.
Bật các API
Để sử dụng Colab Enterprise, trước tiên, bạn phải bật các API cần thiết.
- Mở Google Cloud Shell bằng cách nhấp vào biểu tượng Cloud Shell ở trên cùng bên phải của Google Cloud Console.

- Trong Cloud Shell, hãy đặt mã dự án bằng cách thay thế
PROJECT_IDbằng mã dự án của bạn:
gcloud config set project <PROJECT_ID>
- Chạy lệnh sau để bật các API cần thiết:
gcloud services enable \
compute.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com
Khi thực thi thành công, bạn sẽ thấy một thông báo tương tự như thông báo dưới đây:
Operation "operations/..." finished successfully.
4. Chọn môi trường sổ tay
Mặc dù nhiều nhà khoa học dữ liệu đã quen thuộc với Colab cho các dự án cá nhân, nhưng Colab Enterprise mang đến trải nghiệm sổ tay bảo mật, cộng tác và tích hợp được thiết kế cho các doanh nghiệp.
Trên Google Cloud, bạn có 2 lựa chọn chính cho môi trường sổ tay được quản lý: Colab Enterprise và Vertex AI Workbench. Lựa chọn phù hợp phụ thuộc vào các ưu tiên của dự án.
Trường hợp sử dụng Vertex AI Workbench
Chọn Vertex AI Workbench khi bạn ưu tiên khả năng kiểm soát và tuỳ chỉnh chuyên sâu. Đây là lựa chọn lý tưởng nếu bạn cần:
- Quản lý cơ sở hạ tầng cơ bản và vòng đời của máy.
- Sử dụng vùng chứa tuỳ chỉnh và cấu hình mạng.
- Tích hợp với các quy trình MLOps và công cụ vòng đời tuỳ chỉnh.
Trường hợp nên sử dụng Colab Enterprise
Chọn Colab Enterprise khi bạn ưu tiên thiết lập nhanh chóng, dễ sử dụng và cộng tác an toàn. Đây là một giải pháp được quản lý hoàn toàn, cho phép nhóm của bạn tập trung vào việc phân tích thay vì cơ sở hạ tầng.
Colab Enterprise giúp bạn:
- Phát triển quy trình khoa học dữ liệu gắn liền với kho dữ liệu của bạn. Bạn có thể mở và quản lý sổ tay trực tiếp trong BigQuery Studio.
- Huấn luyện các mô hình học máy và tích hợp với các công cụ MLOps trong Vertex AI.
- Tận hưởng trải nghiệm linh hoạt và đồng nhất. Bạn có thể mở và chạy một sổ tay Colab Enterprise được tạo trong BigQuery trong Vertex AI và ngược lại.
Today's lab
Lớp học lập trình này sử dụng Colab Enterprise để tăng tốc quá trình học máy.
Để tìm hiểu thêm về những điểm khác biệt này, hãy xem tài liệu chính thức về cách chọn giải pháp sổ tay phù hợp.
5. Định cấu hình mẫu thời gian chạy
Trong Colab Enterprise, hãy kết nối với một môi trường thời gian chạy dựa trên một mẫu môi trường thời gian chạy được định cấu hình sẵn.
Mẫu thời gian chạy là một cấu hình có thể sử dụng lại, chỉ định môi trường cho sổ tay của bạn, bao gồm:
- Loại máy (CPU, bộ nhớ)
- Trình tăng tốc (loại và số lượng GPU)
- Dung lượng và loại ổ đĩa
- Chế độ cài đặt mạng và chính sách bảo mật
- Quy tắc tự động tắt khi không hoạt động
Lý do mẫu thời gian chạy hữu ích
- Tính nhất quán: Bạn và nhóm của bạn sẽ có cùng một môi trường để đảm bảo công việc có thể lặp lại.
- Bảo mật: Mẫu thực thi các chính sách bảo mật của tổ chức.
- Quản lý chi phí: Tài nguyên được định cỡ trước trong mẫu để giúp ngăn chặn chi phí phát sinh do vô tình.
Tạo mẫu thời gian chạy
Thiết lập một mẫu thời gian chạy có thể sử dụng lại cho phòng thí nghiệm.
- Trong Google Cloud Console, hãy chuyển đến Trình đơn điều hướng > Vertex AI > Colab Enterprise.
- Trong Colab Enterprise, hãy nhấp vào Mẫu thời gian chạy rồi chọn Mẫu mới.

- Trong phần Kiến thức cơ bản về thời gian chạy:
- Đặt Tên hiển thị thành
gpu-template. - Đặt Khu vực mà bạn muốn.
- Đặt Tên hiển thị thành
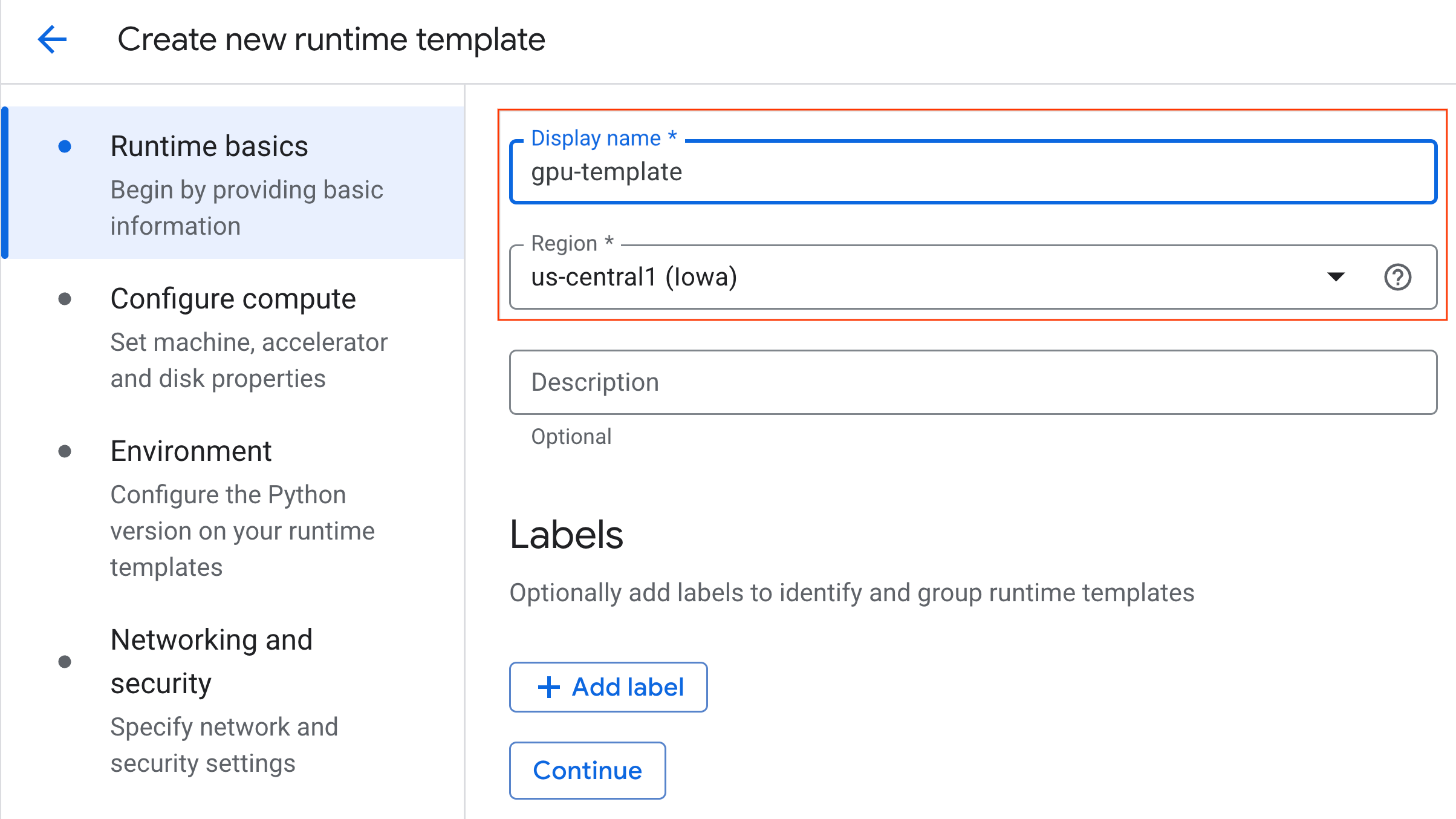
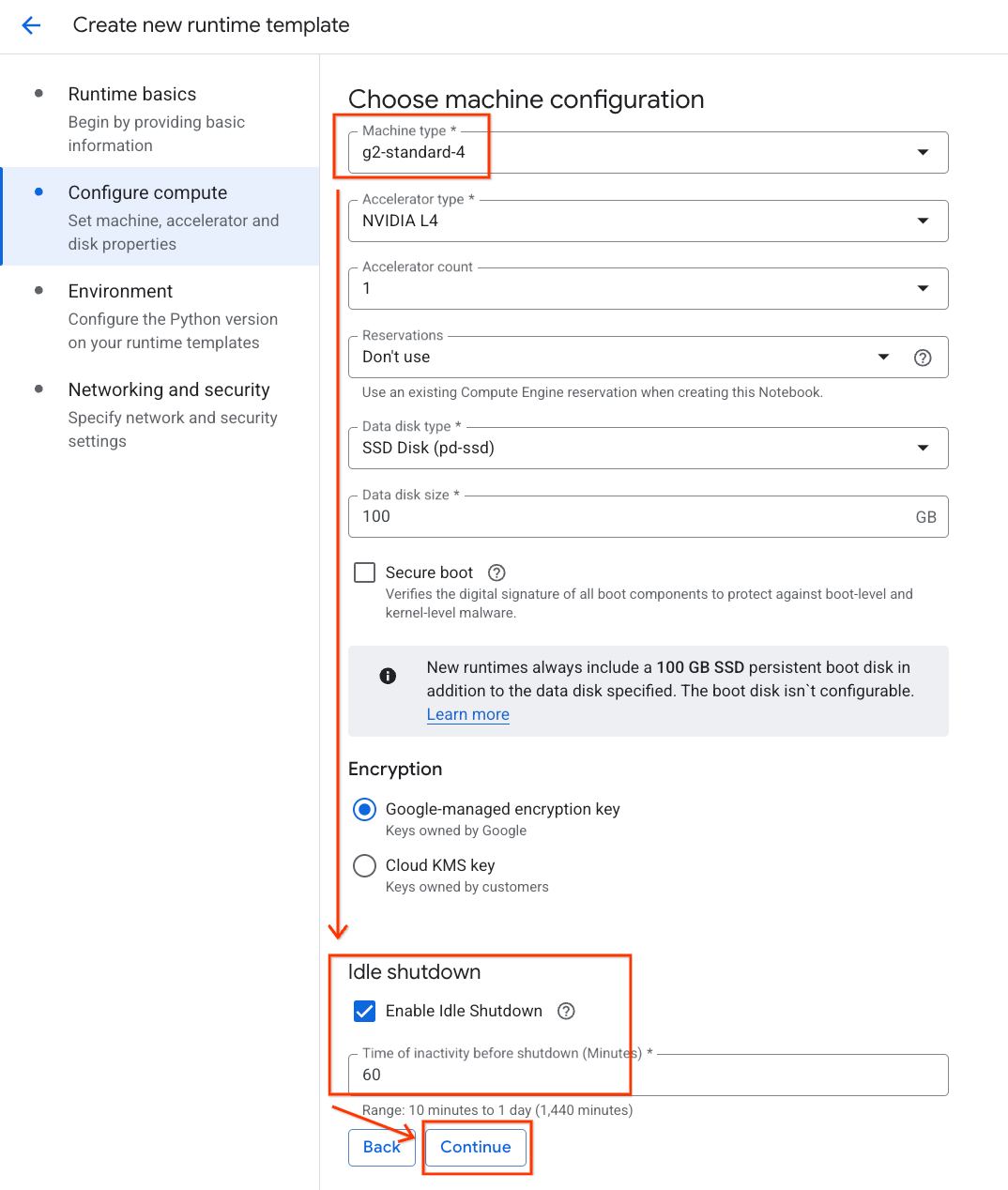
- Trong phần Định cấu hình tài nguyên điện toán:
- Đặt Loại máy thành
g2-standard-4. - Giữ nguyên Loại bộ tăng tốc mặc định là
NVIDIA L4với Số lượng bộ tăng tốc là 1. - Thay đổi chế độ Tắt khi không hoạt động thành 60 phút.
- Nhấp vào Tiếp tục.
- Đặt Loại máy thành
- Trong phần Môi trường:
- Đặt Environment (Môi trường) thành
Python 3.11
- Đặt Environment (Môi trường) thành
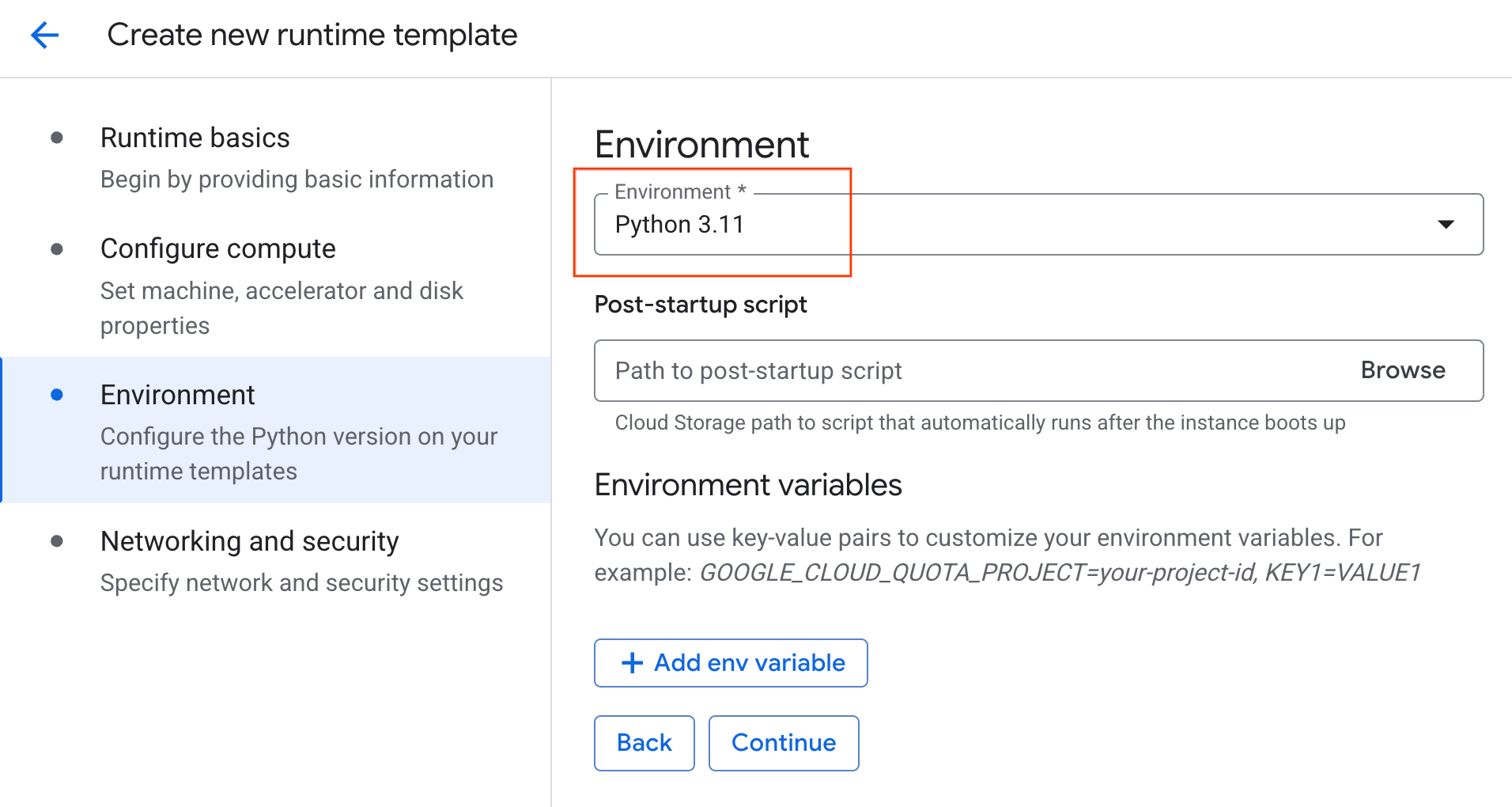
- Nhấp vào Tạo để lưu mẫu thời gian chạy. Trang Mẫu thời gian chạy của bạn giờ đây sẽ hiển thị mẫu mới.
6. Khởi động một môi trường thời gian chạy
Khi đã chuẩn bị xong mẫu, bạn có thể tạo một thời gian chạy mới.
- Trong Colab Enterprise, hãy nhấp vào Thời gian chạy rồi chọn Tạo.

- Trong mục Runtime template (Mẫu thời gian chạy), hãy chọn lựa chọn
gpu-template. Nhấp vào Create (Tạo) rồi đợi cho đến khi thời gian chạy khởi động.
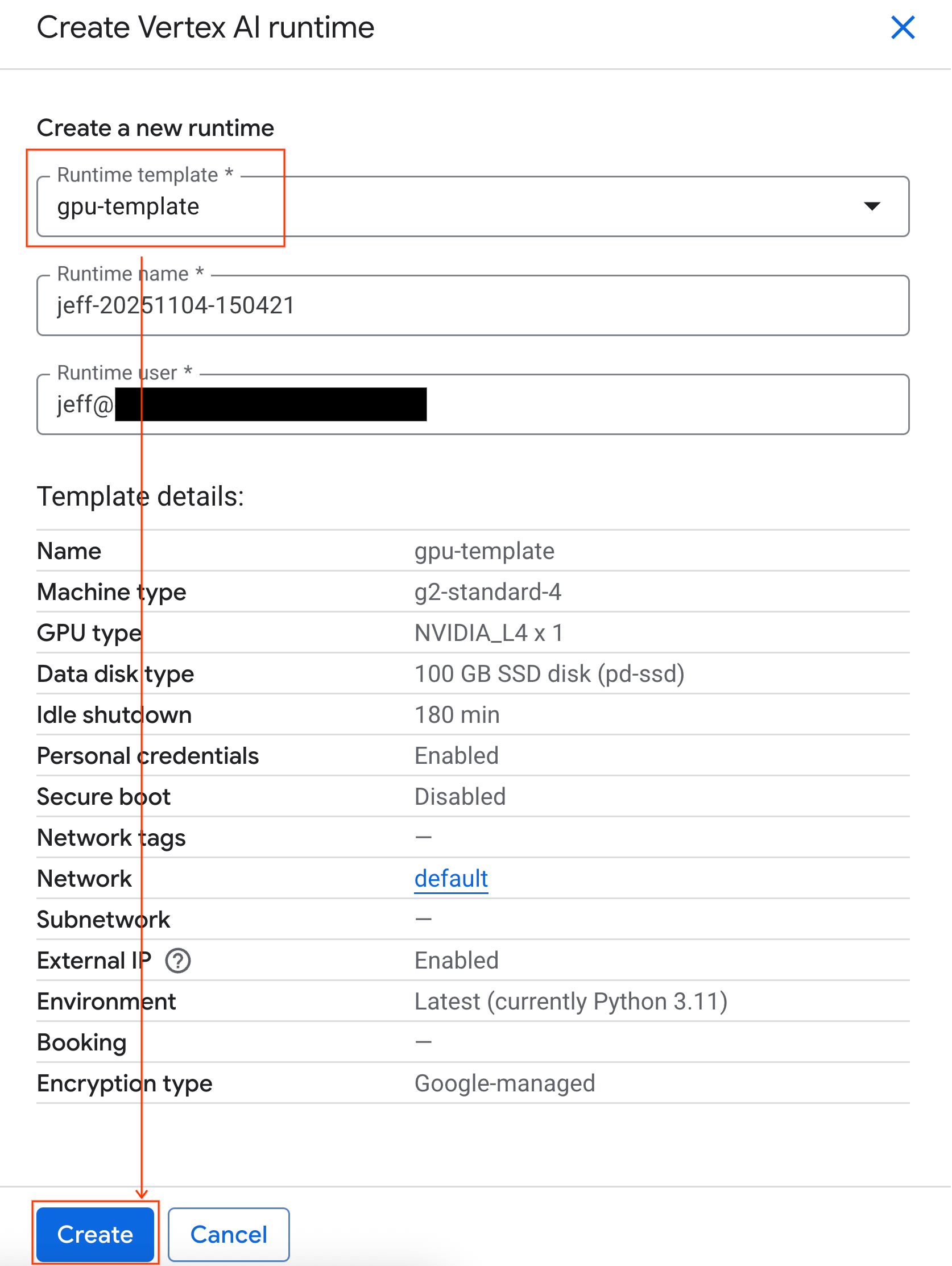
- Sau vài phút, bạn sẽ thấy thời gian chạy có sẵn.

7. Thiết lập sổ tay
Giờ đây, khi cơ sở hạ tầng của bạn đang chạy, bạn cần nhập sổ tay phòng thí nghiệm và kết nối sổ tay đó với thời gian chạy.
Nhập sổ tay
- Trong Colab Enterprise, hãy nhấp vào Sổ tay của tôi rồi nhấp vào Nhập.

- Chọn nút chọn URL rồi nhập URL sau:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/regression/gpu_accelerated_regression/gpu_accelerated_regression.ipynb
- Nhấp vào Nhập. Colab Enterprise sẽ sao chép sổ tay từ GitHub vào môi trường của bạn.

Kết nối với môi trường thời gian chạy
- Mở sổ tay vừa nhập.
- Nhấp vào mũi tên xuống bên cạnh Kết nối.
- Chọn Kết nối với một thời gian chạy.

- Sử dụng trình đơn thả xuống và chọn thời gian chạy mà bạn đã tạo trước đó.
- Nhấp vào Kết nối.

Sổ tay của bạn hiện đã kết nối với một môi trường thời gian chạy có GPU.
Phần phụ thuộc tích hợp
Một lợi ích của việc sử dụng Colab Enterprise là nền tảng này được cài đặt sẵn các thư viện mà bạn cần. Bạn không cần cài đặt hoặc quản lý các phần phụ thuộc như cuDF, cuML hoặc XGBoost theo cách thủ công cho lớp học này.
8. Chuẩn bị tập dữ liệu taxi ở Thành phố New York
Lớp học lập trình này sử dụng Dữ liệu bản ghi chuyến đi của Uỷ ban Taxi và xe limousine của Thành phố New York (TLC). Tập dữ liệu này chứa các bản ghi chuyến đi của taxi màu vàng ở Thành phố New York, bao gồm:
- Ngày, giờ và địa điểm đón và trả khách
- Khoảng cách của chuyến đi
- Số tiền giá vé được phân chia
- Số lượng hành khách
- Số tiền tiền boa (đây là số tiền chúng tôi sẽ dự đoán!)
Định cấu hình GPU và xác nhận tình trạng còn hàng
Bạn có thể xác nhận rằng GPU được nhận dạng bằng cách chạy lệnh nvidia-smi. Thao tác này sẽ hiển thị phiên bản trình điều khiển và thông tin chi tiết về GPU (chẳng hạn như NVIDIA L4).
nvidia-smi
Ô này sẽ trả về GPU được đính kèm vào thời gian chạy của bạn, tương tự như sau:
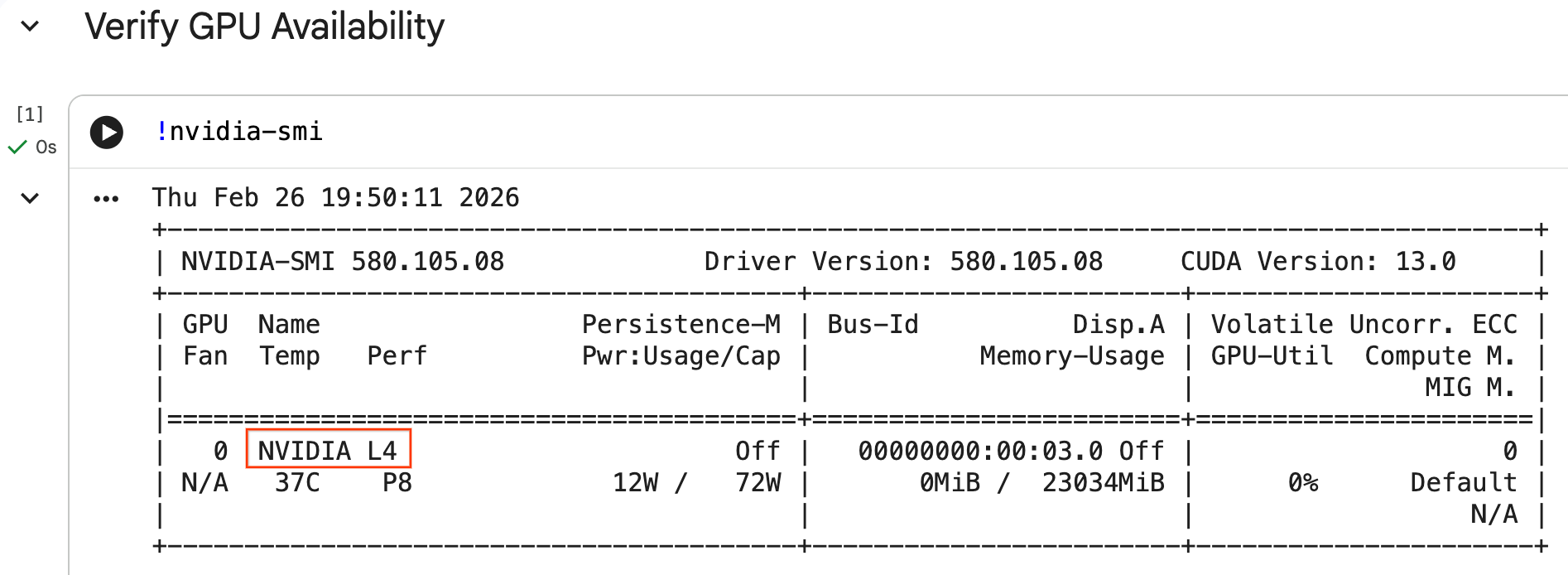
Tải dữ liệu xuống
Tải dữ liệu chuyến đi năm 2024 xuống.
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
Tăng tốc pandas bằng NVIDIA cuDF
Thư viện pandas chạy trên CPU và có thể chậm khi xử lý các tập dữ liệu lớn. Lệnh %load_ext cudf.pandas của NVIDIA sẽ vá pandas một cách linh động để sử dụng tính năng tăng tốc GPU, quay lại CPU nếu cần.
Chúng tôi sử dụng lệnh đặc biệt này thay vì lệnh nhập tiêu chuẩn vì lệnh này giúp tăng tốc độ mà "không cần thay đổi mã". Bạn không phải viết lại bất kỳ mã hiện có nào. Một lệnh tương tự, %load_ext cuml.accel, sẽ làm chính xác điều tương tự cho scikit-learn models! Giải pháp này hoạt động trong mọi môi trường Jupyter có GPU NVIDIA tương thích, chứ không chỉ Colab Enterprise.
%load_ext cudf.pandas
Để xác minh rằng nó đang hoạt động, hãy nhập pandas và kiểm tra loại của nó:
import pandas as pd
pd
Đầu ra sẽ xác nhận rằng bạn hiện đang sử dụng mô-đun cudf.pandas.
Tải và làm sạch dữ liệu
Khi cudf.pandas đang hoạt động, hãy tải các tệp Parquet và thực hiện việc dọn dẹp dữ liệu. Quá trình này tự động chạy trên GPU.
import glob
# Load data into memory
df = pd.concat(
[pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
# Filter for valid trips. We filter for payment_type=1 (credit card)
# because tip amounts are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
Kỹ thuật trích xuất tính chất
Tạo các đặc điểm phái sinh từ ngày và giờ nhận hàng. Sổ tay này có các tính năng khác được dùng trong các bước sau.
import numpy as np
# Time Features
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['is_rush_hour'] = (
((df['hour'] >= 7) & (df['hour'] <= 9)) |
((df['hour'] >= 17) & (df['hour'] <= 19))
).astype(int)
...
# Other features
...
9. Huấn luyện các mô hình riêng lẻ bằng phương pháp xác thực chéo
Để cho thấy cách GPU có thể tăng tốc quá trình học máy, bạn sẽ huấn luyện 3 loại mô hình hồi quy khác nhau để dự đoán tip_amount của một chuyến đi taxi.
Tăng tốc scikit-learn bằng NVIDIA cuML
Chạy các thuật toán scikit-learn trên GPU bằng cuML của NVIDIA mà không cần thay đổi lệnh gọi API. Trước tiên, hãy tải tiện ích cuml.accel.
%load_ext cuml.accel
Thiết lập các tính năng và mục tiêu
Xác định những đặc điểm mà bạn muốn mô hình học hỏi và tách cột mục tiêu (tip_amount).
feature_cols = [
'trip_distance', 'fare_amount', 'passenger_count',
'hour', 'dow', 'is_weekend', 'is_rush_hour',
'fare_log', 'fare_decimal', 'is_round_fare',
'route_frequency', 'pu_tip_mean', 'pu_tip_std',
'PULocationID', 'DOLocationID'
]
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
Thiết lập các phân chia xác thực chéo để đánh giá hiệu suất mô hình một cách mạnh mẽ.
from sklearn.model_selection import KFold
import numpy as np
import time
from sklearn.metrics import mean_squared_error
from tqdm.notebook import tqdm
n_splits = 3
kf = KFold(n_splits=n_splits, shuffle=True, random_state=42)
1. XGBoost
XGBoost được tăng tốc bằng GPU một cách tự nhiên. Truyền tree_method='hist' và device='cuda' để sử dụng GPU trong quá trình huấn luyện.
import xgboost as xgb
start_time = time.perf_counter()
def train_xgb_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# XGBoost handles GPU natively when tree_method='hist' and device='cuda'
model = xgb.XGBRegressor(
objective='reg:squarederror',
max_depth=5,
learning_rate=0.1,
n_estimators=100,
tree_method='hist',
device='cuda',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
xgb_rmse, xgb_preds = train_xgb_cv(X, y)
print(f"\n{'XGBoost RMSE:':<20} ${xgb_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
2. Hồi quy tuyến tính
Huấn luyện mô hình hồi quy tuyến tính. Khi %load_ext cuml.accel đang hoạt động, LinearRegression sẽ tự động ánh xạ đến GPU tương đương.
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
start_time = time.perf_counter()
def train_linreg_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
# Automatically accelerated by cuML
model = LinearRegression()
model.fit(X_train_scaled, y_train)
preds = model.predict(X_val_scaled)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
linreg_rmse, linreg_preds = train_linreg_cv(X, y)
print(f"\n{'Linear Reg RMSE:':<20} ${linreg_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
3. Rừng ngẫu nhiên
Huấn luyện một mô hình kết hợp bằng cách sử dụng RandomForestRegressor. Các mô hình dựa trên cây thường mất nhiều thời gian để huấn luyện trên CPU, nhưng quá trình tăng tốc GPU sẽ xử lý hàng triệu hàng nhanh hơn.
from sklearn.ensemble import RandomForestRegressor
start_time = time.perf_counter()
def train_rf_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Automatically accelerated by cuML
model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
rf_rmse, rf_preds = train_rf_cv(X, y)
print(f"\n{'Random Forest RMSE:':<20} ${rf_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
10. Đánh giá quy trình toàn diện
Kết hợp các dự đoán từ 3 mô hình bằng cách sử dụng một tổ hợp tuyến tính đơn giản. Điều này thường giúp tăng độ chính xác hơn một chút so với các mô hình riêng lẻ.
Điều chỉnh hồi quy tuyến tính cho các dự đoán để tìm ra trọng số tối ưu:
ensemble_weights = LinearRegression(positive=True, fit_intercept=False).fit(
np.c_[xgb_preds, rf_preds, linreg_preds], y
).coef_
# Normalize weights
ensemble_weights = ensemble_weights / ensemble_weights.sum()
ensemble_preds = np.c_[xgb_preds, rf_preds, linreg_preds] @ ensemble_weights
ensemble_rmse = np.sqrt(mean_squared_error(y, ensemble_preds))
So sánh kết quả để xem mức tăng của nhóm:
print(f"\n{'Model':<20} {'RMSE':>10}")
print("-" * 32)
print(f"{'Linear Regression':<20} ${linreg_rmse:>9.4f}")
print(f"{'Random Forest':<20} ${rf_rmse:>9.4f}")
print(f"{'XGBoost':<20} ${xgb_rmse:>9.4f}")
print("-" * 32)
print(f"{'Ensemble':<20} ${ensemble_rmse:>9.4f}")
print(f"\nEnsemble lift: ${xgb_rmse - ensemble_rmse:.4f}")
11. So sánh hiệu suất của CPU và GPU
Để đo điểm chuẩn hiệu suất một cách thích hợp, bạn sẽ khởi động lại nhân để đảm bảo trạng thái thực thi sạch, chạy toàn bộ quy trình khoa học dữ liệu trên CPU, rồi chạy lại trên GPU.
Khởi động lại nhân
Chạy lệnh IPython.Application.instance().kernel.do_shutdown(True) để khởi động lại nhân và giải phóng bộ nhớ.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
Xác định quy trình khoa học dữ liệu
Gói quy trình làm việc cốt lõi (tải dữ liệu, làm sạch, kỹ thuật trích xuất tính chất và huấn luyện mô hình) vào một hàm duy nhất. Hàm này chấp nhận một mô-đun pandas pd_module và một đối số use_gpu để chuyển đổi giữa các môi trường.
def run_ml_pipeline(pd_module, use_gpu=False):
import time
import glob
import numpy as np
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
timings = {}
# 1. Load Data
t0 = time.perf_counter()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
timings['Load Data'] = time.perf_counter() - t0
# 2. Clean Data
t0 = time.perf_counter()
# Filter for payment_type=1 (credit card) because tip amounts
# are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
timings['Clean Data'] = time.perf_counter() - t0
# 3. Feature Engineering
t0 = time.perf_counter()
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['fare_log'] = np.log1p(df['fare_amount'])
timings['Feature Engineering'] = time.perf_counter() - t0
# 4. Modeling Prep
feature_cols = ['trip_distance', 'fare_amount', 'passenger_count', 'hour', 'dow', 'is_weekend', 'fare_log']
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
# Free memory
del df
import gc
gc.collect()
# 5. Train Random Forest
t0 = time.perf_counter()
rf_model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
).fit(X, y)
timings['Train Random Forest'] = time.perf_counter() - t0
# 6. Train XGBoost
t0 = time.perf_counter()
params = {
'objective': 'reg:squarederror',
'max_depth': 5,
'n_estimators': 100,
'random_state': 42
}
if use_gpu:
params['device'] = 'cuda'
params['tree_method'] = 'hist'
xgb_model = xgb.XGBRegressor(**params).fit(X, y)
timings['Train XGBoost'] = time.perf_counter() - t0
del X
del y
gc.collect()
return timings
Chạy trên CPU
Gọi quy trình bằng pandas CPU tiêu chuẩn.
import pandas as pd
print("Running pipeline on CPU...")
cpu_times = run_ml_pipeline(pd, use_gpu=False)
print("CPU Execution Finished.")
Chạy trên GPU
Tải các tiện ích thư viện NVIDIA, truyền mô-đun cudf.pandas được tăng tốc vào quy trình và đặt thiết bị XGBoost thành cuda theo nội bộ.
import IPython.core.magic
if not hasattr(IPython.core.magic, 'output_can_be_silenced'):
IPython.core.magic.output_can_be_silenced = lambda x: x
%load_ext cudf.pandas
%load_ext cuml.accel
import pandas as pd
print("Running pipeline on GPU...")
gpu_times = run_ml_pipeline(pd, use_gpu=True)
print("GPU Execution Finished.")
Trực quan hoá tốc độ tăng hiệu suất
Trực quan hoá thời gian bằng matplotlib. Kết quả cho thấy thời gian tiết kiệm được trong quá trình xử lý dữ liệu và huấn luyện mô hình khi sử dụng GPU.
import matplotlib.pyplot as plt
import numpy as np
labels = list(cpu_times.keys())
cpu_values = list(cpu_times.values())
gpu_values = list(gpu_times.values())
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots(figsize=(10, 6))
rects1 = ax.bar(x - width/2, cpu_values, width, label='CPU', color='#4285F4')
rects2 = ax.bar(x + width/2, gpu_values, width, label='GPU', color='#76B900')
ax.set_ylabel('Execution Time (seconds)')
ax.set_title('NYC Taxi ML Pipeline: CPU vs. GPU Performance')
ax.set_xticks(x)
ax.set_xticklabels(labels, rotation=45, ha="right")
ax.legend()
# Add data labels
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(f'{height:.2f}s',
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom', fontsize=9)
autolabel(rects1)
autolabel(rects2)
plt.tight_layout()
plt.show()
# Calculate overall speedup
total_cpu_time = sum(cpu_values)
total_gpu_time = sum(gpu_values)
overall_speedup = total_cpu_time / total_gpu_time
print(f"\nOverall Pipeline Speedup: {overall_speedup:.2f}x faster on GPU!")
Bạn sẽ thấy một số dòng mã như:

Biểu đồ này minh hoạ lợi thế đáng kể về hiệu suất của GPU trong toàn bộ quy trình khoa học dữ liệu. Bạn có thể tiết kiệm được nhiều thời gian nhất trong các giai đoạn huấn luyện mô hình đòi hỏi nhiều tính toán cho các thuật toán như Random Forest và XGBoost.
12. Phân tích mã của bạn để tìm các hạn chế về hiệu suất
Khi dùng cudf.pandas, hầu hết các hàm đều chạy trên GPU. Nếu cuDF chưa hỗ trợ một thao tác cụ thể, thì quá trình thực thi sẽ tạm thời quay lại CPU. NVIDIA cung cấp 2 lệnh đặc biệt Jupyter tích hợp sẵn để xác định các lệnh dự phòng này.
Phân tích tài nguyên cấp cao bằng %%cudf.pandas.profile
Lệnh %%cudf.pandas.profile cung cấp thông tin tóm tắt về những hàm đã chạy trên GPU hoặc CPU.
%%cudf.pandas.profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
summary = (
df
.groupby(['PULocationID', 'payment_type'])
[['passenger_count', 'fare_amount', 'tip_amount']]
.agg(['min', 'mean', 'max'])
)

Lập hồ sơ từng dòng bằng %%cudf.pandas.line_profile
Để khắc phục sự cố thật chi tiết, %%cudf.pandas.line_profile chú thích từng dòng mã bằng số lần dòng mã đó được thực thi trên GPU so với CPU.
%%cudf.pandas.line_profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
df = df.sample(1_000)
# Iterating row-by-row or using custom python apply functions often falls back to the CPU
def categorize_hour(hour):
if hour < 12:
return 'Morning'
else:
return 'Afternoon/Evening'
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['time_of_day_slow'] = df['hour'].apply(categorize_hour)
# Using vectorized pandas operations (like pd.cut) stays entirely on the GPU
cut_bins = [-1, 11, 24]
cut_labels = ['Morning', 'Afternoon/Evening']
df['time_of_day_fast'] = pd.cut(df['hour'], bins=cut_bins, labels=cut_labels)

13. Dọn dẹp
Để tránh bị tính phí ngoài dự kiến cho tài khoản Google Cloud, hãy dọn dẹp các tài nguyên mà bạn đã tạo trong lớp học lập trình này.
Xoá tài nguyên
Xoá tập dữ liệu cục bộ trên thời gian chạy bằng lệnh !rm -rf trong một ô của sổ tay.
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Tắt thời gian chạy Colab
- Trong bảng điều khiển Cloud của Google, hãy chuyển đến trang Thời gian chạy của Colab Enterprise.
- Trong trình đơn Khu vực, hãy chọn khu vực chứa thời gian chạy của bạn.
- Chọn thời gian chạy mà bạn muốn xoá.
- Nhấp vào Xóa.
- Nhấp vào Xác nhận.
Xoá sổ tay
- Trong bảng điều khiển Cloud của Google, hãy chuyển đến trang My Notebooks (Sổ tay của tôi) của Colab Enterprise.
- Trong trình đơn Khu vực, hãy chọn khu vực chứa sổ tay của bạn.
- Chọn sổ tay bạn muốn xoá.
- Nhấp vào Xóa.
- Nhấp vào Xác nhận.
14. Xin chúc mừng
Xin chúc mừng! Bạn đã tăng tốc thành công một quy trình học máy pandas và scikit-learn bằng cách sử dụng các thư viện cuDF và cuML của NVIDIA trên Colab Enterprise. Chỉ cần thêm một vài lệnh đặc biệt (%load_ext cudf.pandas và %load_ext cuml.accel), mã tiêu chuẩn của bạn sẽ chạy trên GPU, xử lý các bản ghi và điều chỉnh các mô hình phức tạp cục bộ trong thời gian ngắn.
Để biết thêm thông tin về tính năng tăng tốc GPU cho hoạt động phân tích dữ liệu, hãy xem lớp học lập trình Phân tích dữ liệu tăng tốc bằng GPU.
Nội dung đã đề cập
- Tìm hiểu về Colab Enterprise trên Google Cloud.
- Tuỳ chỉnh môi trường thời gian chạy Colab bằng các cấu hình GPU và bộ nhớ cụ thể.
- Áp dụng tính năng tăng tốc GPU để dự đoán số tiền tiền boa bằng hàng triệu bản ghi từ một tập dữ liệu về Taxi ở Thành phố New York.
- Tăng tốc
pandasmà không cần thay đổi mã bằng thư việncuDFcủa NVIDIA. - Tăng tốc
scikit-learnmà không cần thay đổi mã bằng cách sử dụng thư việncuMLvà GPU của NVIDIA. - Lập hồ sơ mã của bạn để xác định và tối ưu hoá các hạn chế về hiệu suất.