
1. Введение
В этом практическом занятии вы узнаете, как ускорить рабочие процессы в области анализа данных и машинного обучения на больших наборах данных, используя графические процессоры NVIDIA и библиотеки с открытым исходным кодом в Google Cloud. Вы начнете с настройки инфраструктуры, а затем изучите, как применять ускорение с помощью графических процессоров.
Вы сосредоточитесь на жизненном цикле обработки данных, от подготовки данных с помощью pandas до обучения моделей с помощью scikit-learn и XGBoost . Вы узнаете, как ускорить эти задачи, используя библиотеки NVIDIA cuDF и cuML . Самое приятное то, что вы можете получить это ускорение с помощью GPU, не изменяя существующий код pandas или scikit-learn .
Что вы узнаете
- Разберитесь с Colab Enterprise в Google Cloud.
- Настройте среду выполнения Colab, указав конкретные параметры графического процессора и памяти.
- Примените ускорение на графическом процессоре для прогнозирования размера чаевых, используя миллионы записей из набора данных о нью-йоркских такси.
- Ускорьте работу
pandasбез каких-либо изменений в коде, используя библиотекуcuDFот NVIDIA. - Ускорьте работу
scikit-learnбез каких-либо изменений в коде, используя библиотекуcuMLот NVIDIA и графические процессоры. - Проанализируйте свой код, чтобы выявить и оптимизировать ограничения производительности.
2. Зачем ускорять машинное обучение?
Необходимость более быстрой итерации в машинном обучении
Подготовка данных занимает много времени, а обучение или оценка модели могут занять еще больше времени по мере роста наборов данных. Обучение таких моделей, как случайные леса или XGBoost, на миллионах строк с использованием процессора может занять часы или дни.
Использование графических процессоров ускоряет эти процессы обучения с помощью таких библиотек, как cuML и XGBoost с ускорением на графических процессорах. Это ускорение позволяет:
- Ускорьте итерации: быстро тестируйте новые функции и гиперпараметры.
- Обучение на полных наборах данных: используйте полные данные вместо уменьшения выборки для повышения точности.
- Снижение затрат: выполнение ресурсоемких задач за меньшее время позволяет снизить затраты на вычислительные ресурсы.
3. Настройка и требования
Потенциальные затраты
В этом практическом занятии используются ресурсы Google Cloud, включая среду выполнения Colab Enterprise с графическими процессорами NVIDIA L4. Обратите внимание на возможные дополнительные расходы и следуйте инструкциям в разделе «Очистка ресурсов» в конце занятия, чтобы отключить ресурсы и избежать дальнейших платежей. Подробную информацию о ценах см. в разделах «Цены на Colab Enterprise» и «Цены на графические процессоры» .
Прежде чем начать
Предполагается средний уровень владения Python, pandas , scikit-learn и стандартными методами машинного обучения (такими как кросс-валидация/ансамблирование).
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего проекта в Google Cloud включена функция выставления счетов.
Включите API
Для использования Colab Enterprise необходимо сначала включить необходимые API.
- Откройте Google Cloud Shell , щелкнув значок Cloud Shell в правом верхнем углу консоли Google Cloud .

- В Cloud Shell укажите идентификатор проекта, заменив
PROJECT_IDна идентификатор вашего проекта:
gcloud config set project <PROJECT_ID>
- Выполните следующую команду, чтобы включить необходимые API:
gcloud services enable \
compute.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com
После успешного выполнения вы должны увидеть сообщение, похожее на показанное ниже:
Operation "operations/..." finished successfully.
4. Выбор среды для ноутбука
Хотя многие специалисты по анализу данных знакомы с Colab по личным проектам, Colab Enterprise предоставляет безопасную, совместную и интегрированную среду для работы с блокнотами, разработанную для бизнеса.
В Google Cloud у вас есть два основных варианта управляемых сред для ноутбуков: Colab Enterprise и Vertex AI Workbench . Правильный выбор зависит от приоритетов вашего проекта.
Когда использовать Vertex AI Workbench
Выбирайте Vertex AI Workbench, если для вас приоритетны контроль и широкая возможность настройки . Это идеальный выбор, если вам необходимо:
- Управление базовой инфраструктурой и жизненным циклом оборудования.
- Используйте пользовательские контейнеры и сетевые конфигурации.
- Интеграция с конвейерами MLOps и пользовательскими инструментами управления жизненным циклом.
Когда использовать Colab Enterprise
Выбирайте Colab Enterprise, если для вас приоритетны быстрая настройка, простота использования и безопасная совместная работа . Это полностью управляемое решение, которое позволяет вашей команде сосредоточиться на анализе, а не на инфраструктуре.
Colab Enterprise поможет вам:
- Разрабатывайте рабочие процессы обработки данных, тесно связанные с вашим хранилищем данных. Вы можете открывать и управлять своими блокнотами непосредственно в BigQuery Studio .
- Обучайте модели машинного обучения и интегрируйте их с инструментами MLOps в Vertex AI.
- Наслаждайтесь гибким и унифицированным интерфейсом. Блокнот Colab Enterprise, созданный в BigQuery, можно открыть и запустить в Vertex AI, и наоборот.
Сегодняшняя лабораторная работа
В этом практическом занятии используется Colab Enterprise для ускоренного машинного обучения.
Чтобы узнать больше о различиях, ознакомьтесь с официальной документацией по выбору подходящего ноутбука .
5. Настройка шаблона среды выполнения
В Colab Enterprise подключение к среде выполнения осуществляется на основе предварительно настроенного шаблона среды выполнения .
Шаблон среды выполнения — это многократно используемая конфигурация, определяющая среду для вашего блокнота, включая:
- Тип машины (процессор, память)
- Ускоритель (тип и количество графических процессоров)
- Размер и тип диска
- Настройки сети и политики безопасности
- Правила автоматического отключения в режиме ожидания
Почему шаблоны времени выполнения полезны
- Последовательность: Вы и ваша команда работаете в одинаковых условиях, что обеспечивает повторяемость работы.
- Безопасность: Шаблоны обеспечивают соблюдение политик безопасности организации.
- Управление затратами: В шаблоне предварительно заданы необходимые параметры ресурсов, что помогает предотвратить непредвиденные расходы.
Создайте шаблон среды выполнения.
Создайте многоразовый шаблон среды выполнения для лабораторной работы.
- В консоли Google Cloud перейдите в меню навигации > Vertex AI > Colab Enterprise .

- В Colab Enterprise щелкните «Шаблоны среды выполнения» , а затем выберите «Создать шаблон» .
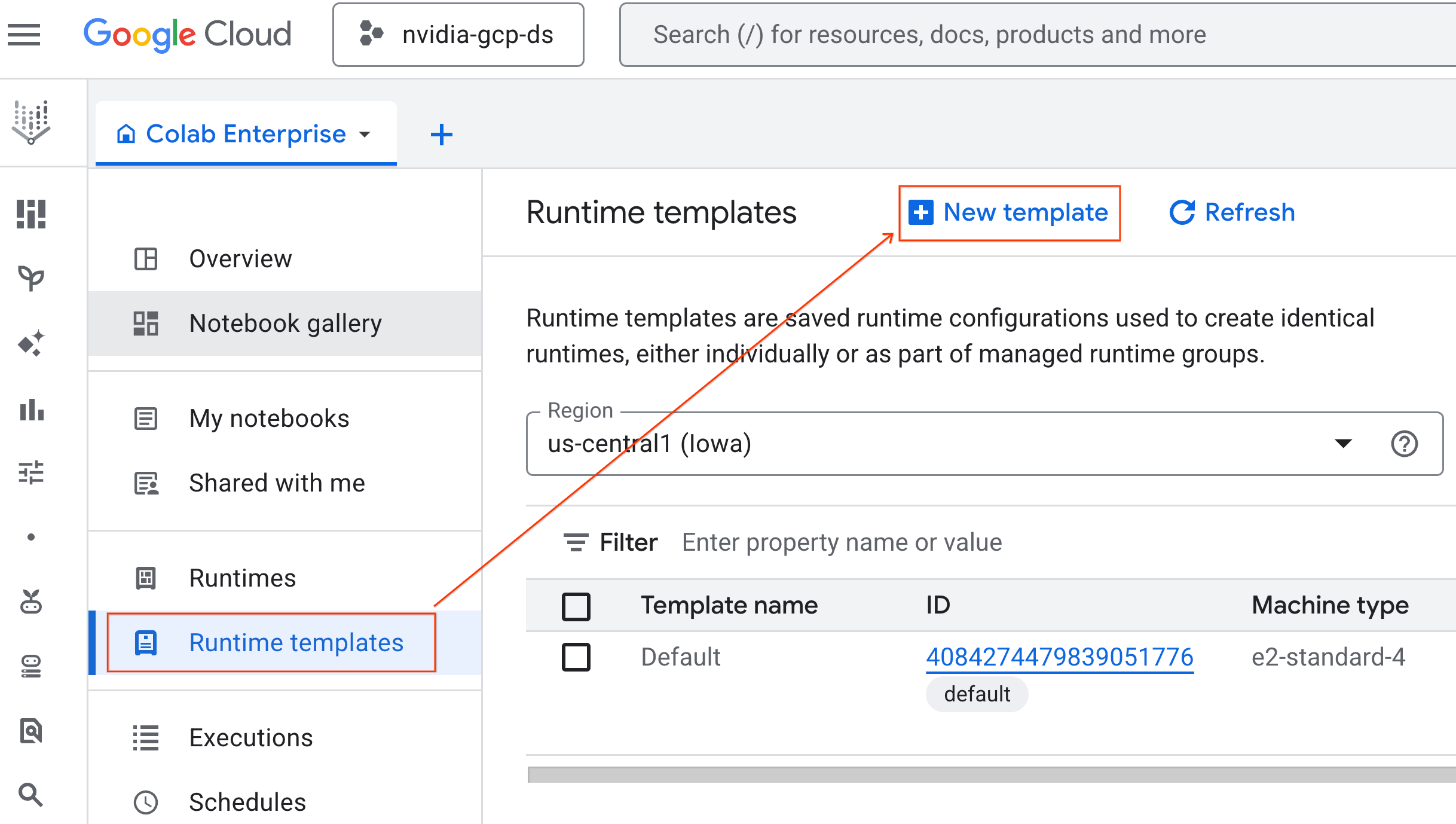
- В разделе «Основы работы среды выполнения» :
- Установите отображаемое имя как
gpu-template. - Укажите предпочитаемый регион .
- Установите отображаемое имя как

- В разделе «Настройка вычислительных ресурсов» :
- Установите тип станка на
g2-standard-4. - Оставьте тип ускорителя по умолчанию как
NVIDIA L4с количеством ускорителей , равным 1. - Измените время отключения в режиме ожидания на 60 минут.
- Нажмите «Продолжить» .
- Установите тип станка на

- В разделе «Окружающая среда» :
- Установите среду выполнения на
Python 3.11
- Установите среду выполнения на

- Нажмите «Создать» , чтобы сохранить шаблон среды выполнения. На странице «Шаблоны среды выполнения» должен отобразиться новый шаблон.
6. Запустите среду выполнения.
Имея готовый шаблон, вы можете создать новую среду выполнения.
- В Colab Enterprise щелкните Runtimes , а затем выберите Create .
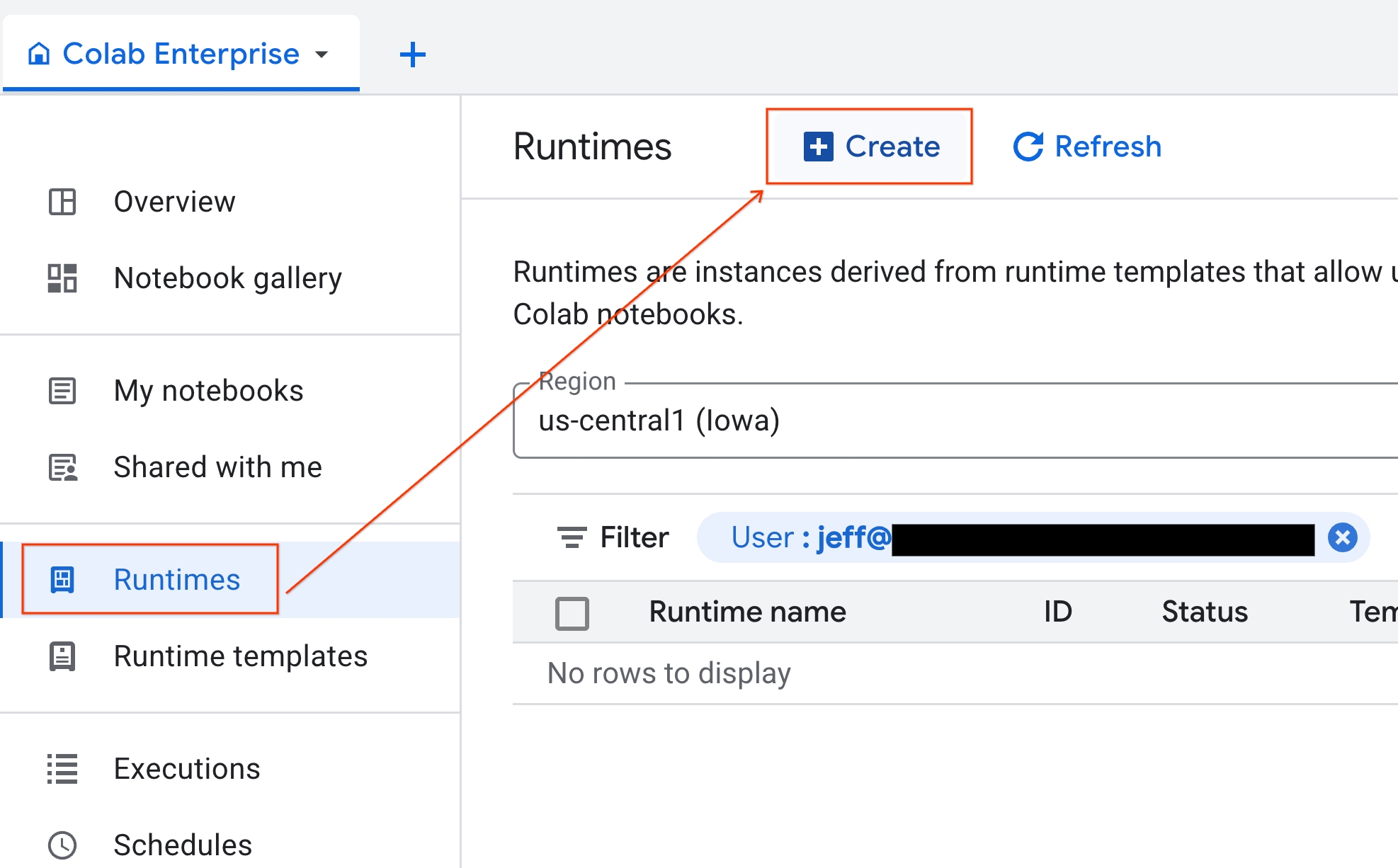
- В разделе «Шаблон среды выполнения» выберите параметр
gpu-template. Нажмите «Создать» и дождитесь загрузки среды выполнения.
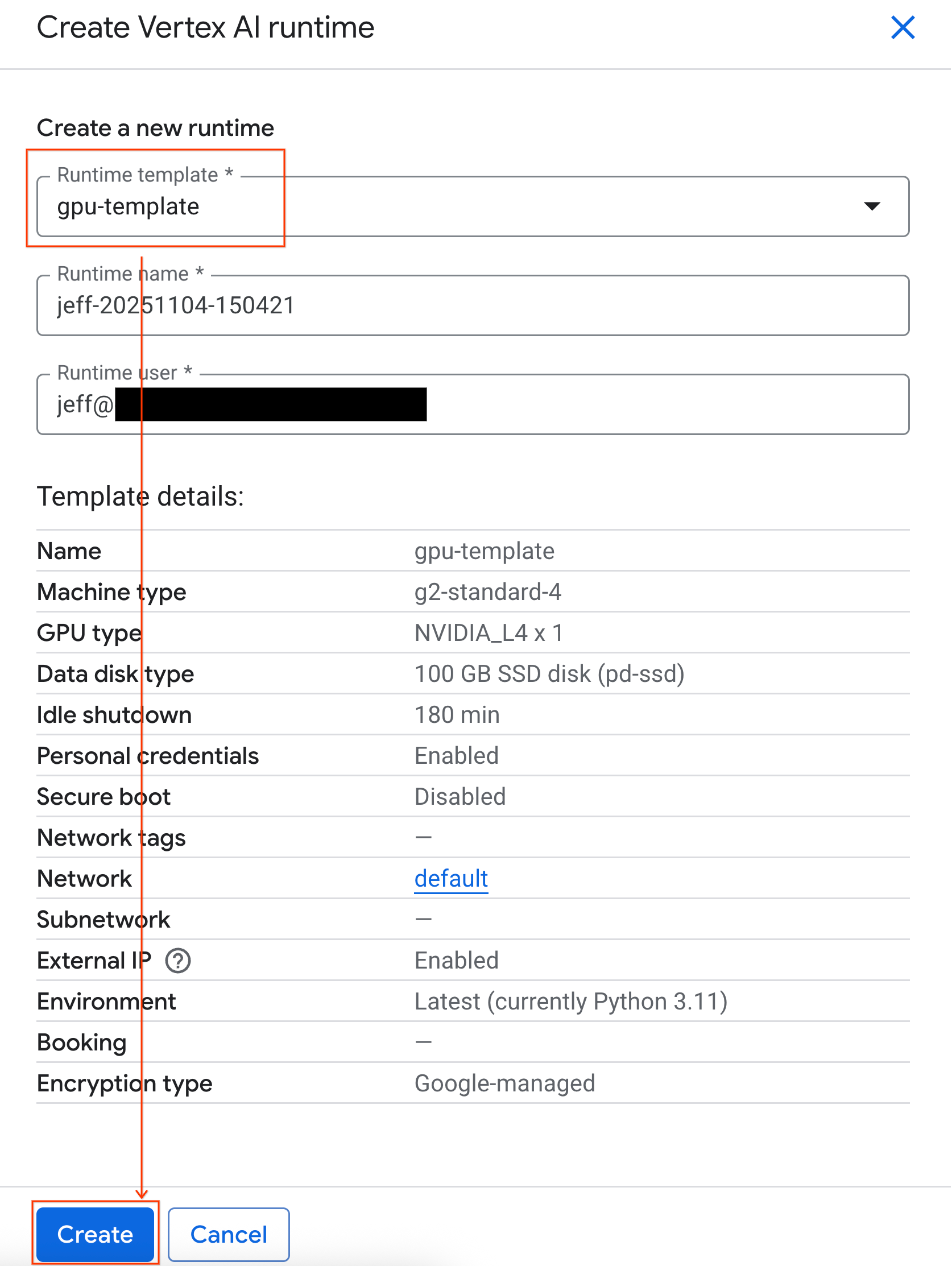
- Через несколько минут вы увидите доступное время выполнения.

7. Подготовьте ноутбук.
Теперь, когда ваша инфраструктура запущена, вам необходимо импортировать лабораторный блокнот и подключить его к вашей среде выполнения.
Импортируйте блокнот
- В Colab Enterprise щелкните «Мои блокноты» , а затем — «Импорт» .
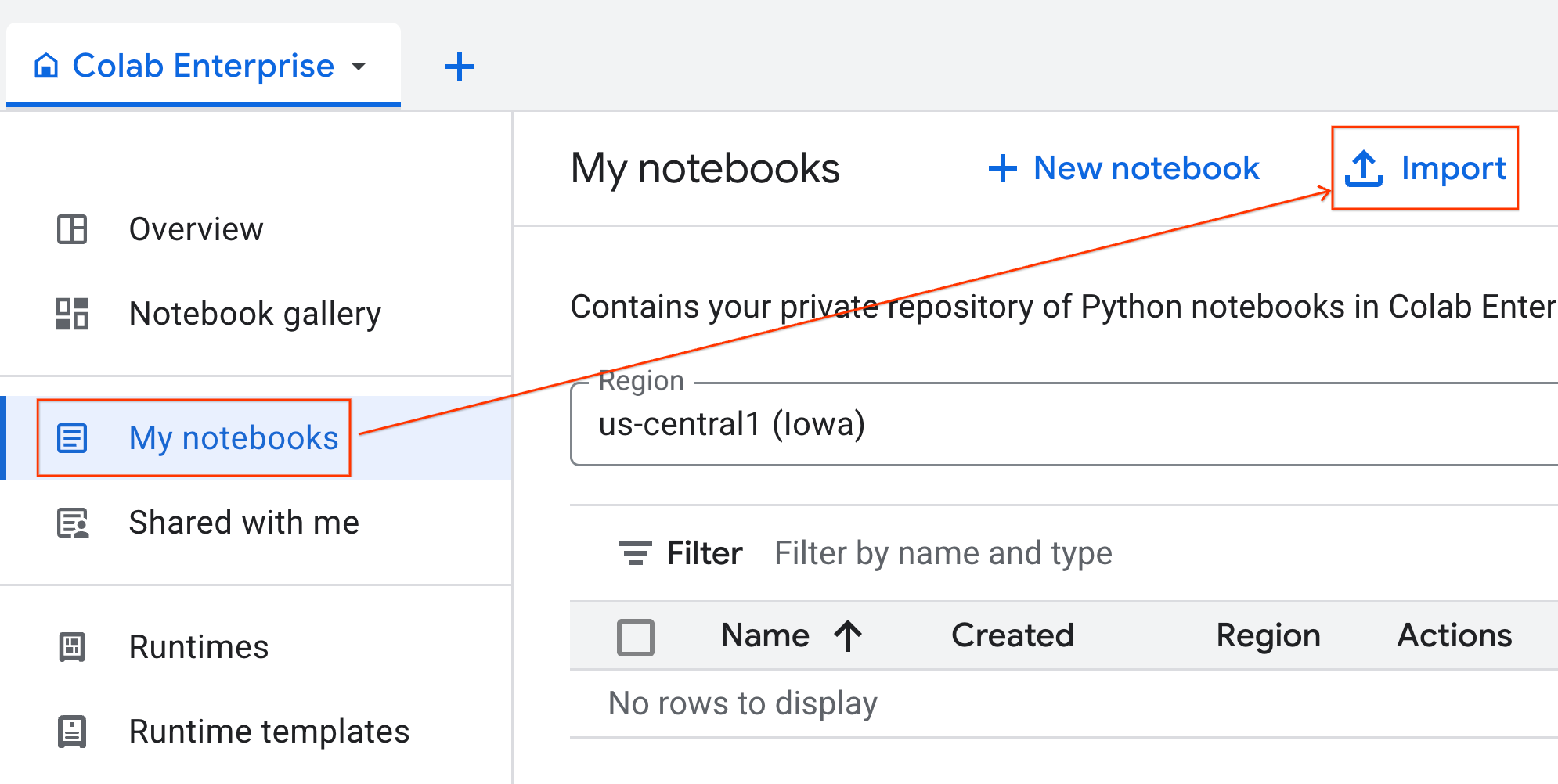
- Выберите переключатель «URL» и введите следующий URL-адрес:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/regression/gpu_accelerated_regression/gpu_accelerated_regression.ipynb
- Нажмите «Импорт» . Colab Enterprise скопирует блокнот из GitHub в вашу среду.

Подключитесь к среде выполнения
- Откройте только что импортированный блокнот.
- Нажмите стрелку вниз рядом с кнопкой «Подключиться» .
- Выберите «Подключиться к среде выполнения» .

- Воспользуйтесь выпадающим списком и выберите ранее созданную среду выполнения.
- Нажмите «Подключиться» .

Теперь ваш ноутбук подключен к среде выполнения с поддержкой графического процессора.
Встроенные зависимости
Одно из преимуществ использования Colab Enterprise заключается в том, что в нем предустановлены необходимые библиотеки. Вам не нужно вручную устанавливать или управлять зависимостями, такими как cuDF , cuML или XGBoost для выполнения этой лабораторной работы.
8. Подготовьте набор данных о такси в Нью-Йорке.
В этом практическом занятии используются данные о поездках, предоставленные Комиссией по такси и лимузинам Нью-Йорка (TLC) . Набор данных содержит записи о поездках желтых такси в Нью-Йорке, в том числе:
- Даты, время и места получения и возврата.
- Расстояния поездок
- Суммы проезда, указанные по пунктам
- Количество пассажиров
- Размер чаевых ( это то, что мы спрогнозируем! )
Настройте графический процессор и подтвердите его доступность.
Подтвердить распознавание графического процессора можно, выполнив команду nvidia-smi . Она отобразит версию драйвера и подробные сведения о графическом процессоре (например, NVIDIA L4).
nvidia-smi
В ответ на запрос должна быть указана графическая карта, подключенная к вашей среде выполнения, примерно следующего вида:

Скачать данные
Загрузите данные о поездках за 2024 год.
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
Ускорьте работу pandas с помощью NVIDIA cuDF
Библиотека pandas работает на центральном процессоре и может работать медленно при обработке больших наборов данных. Магическая команда NVIDIA %load_ext cudf.pandas динамически настраивает pandas на использование ускорения графического процессора, переключаясь на центральный процессор при необходимости.
Мы используем эту волшебную команду вместо стандартного импорта, потому что она обеспечивает ускорение без изменения кода. Вам не нужно переписывать существующий код. Аналогичная команда, %load_ext cuml.accel , делает то же самое для scikit-learn models ! Это работает в любой среде Jupyter с совместимым графическим процессором NVIDIA, а не только в Colab Enterprise.
%load_ext cudf.pandas
Чтобы убедиться в его активности, импортируйте pandas и проверьте его тип:
import pandas as pd
pd
В результате выполнения программы будет подтверждено, что вы теперь используете модуль cudf.pandas .
Загрузка и очистка данных
При активной функции cudf.pandas загрузите файлы Parquet и выполните очистку данных. Этот процесс автоматически запускается на графическом процессоре.
import glob
# Load data into memory
df = pd.concat(
[pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
# Filter for valid trips. We filter for payment_type=1 (credit card)
# because tip amounts are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
Разработка функциональных возможностей
Создайте производные признаки на основе даты и времени получения груза. В блокноте содержатся другие признаки, используемые на последующих этапах.
import numpy as np
# Time Features
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['is_rush_hour'] = (
((df['hour'] >= 7) & (df['hour'] <= 9)) |
((df['hour'] >= 17) & (df['hour'] <= 19))
).astype(int)
...
# Other features
...
9. Обучение отдельных моделей с помощью перекрестной проверки.
Чтобы продемонстрировать, как графический процессор может ускорить машинное обучение, вы обучите три различных типа регрессионных моделей для прогнозирования tip_amount за поездку на такси.
Ускорьте работу scikit-learn с помощью NVIDIA cuML
Запускайте алгоритмы scikit-learn на графическом процессоре, используя NVIDIA cuML , без изменения вызовов API. Сначала загрузите расширение cuml.accel .
%load_ext cuml.accel
Настройка параметров и целей
Определите признаки, на основе которых вы хотите, чтобы модель обучалась, и выделите целевой столбец ( tip_amount ).
feature_cols = [
'trip_distance', 'fare_amount', 'passenger_count',
'hour', 'dow', 'is_weekend', 'is_rush_hour',
'fare_log', 'fare_decimal', 'is_round_fare',
'route_frequency', 'pu_tip_mean', 'pu_tip_std',
'PULocationID', 'DOLocationID'
]
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
Настройте разбиение выборки для перекрестной проверки, чтобы надежно оценить производительность модели.
from sklearn.model_selection import KFold
import numpy as np
import time
from sklearn.metrics import mean_squared_error
from tqdm.notebook import tqdm
n_splits = 3
kf = KFold(n_splits=n_splits, shuffle=True, random_state=42)
1. XGBoost
XGBoost изначально использует ускорение на графическом процессоре. Передайте tree_method='hist' и device='cuda' , чтобы использовать графический процессор во время обучения.
import xgboost as xgb
start_time = time.perf_counter()
def train_xgb_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# XGBoost handles GPU natively when tree_method='hist' and device='cuda'
model = xgb.XGBRegressor(
objective='reg:squarederror',
max_depth=5,
learning_rate=0.1,
n_estimators=100,
tree_method='hist',
device='cuda',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
xgb_rmse, xgb_preds = train_xgb_cv(X, y)
print(f"\n{'XGBoost RMSE:':<20} ${xgb_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
2. Линейная регрессия
Обучите модель линейной регрессии. При активной опции %load_ext cuml.accel функция LinearRegression автоматически преобразуется в эквивалентную модель для графического процессора.
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
start_time = time.perf_counter()
def train_linreg_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
# Automatically accelerated by cuML
model = LinearRegression()
model.fit(X_train_scaled, y_train)
preds = model.predict(X_val_scaled)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
linreg_rmse, linreg_preds = train_linreg_cv(X, y)
print(f"\n{'Linear Reg RMSE:':<20} ${linreg_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
3. Случайный лес
Обучите ансамблевую модель, используя RandomForestRegressor . Модели на основе деревьев часто медленно обучаются на ЦП, но ускорение с помощью графического процессора обрабатывает миллионы строк быстрее.
from sklearn.ensemble import RandomForestRegressor
start_time = time.perf_counter()
def train_rf_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Automatically accelerated by cuML
model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
rf_rmse, rf_preds = train_rf_cv(X, y)
print(f"\n{'Random Forest RMSE:':<20} ${rf_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
10. Оцените весь сквозной конвейер обработки данных.
Объедините прогнозы трех моделей, используя простой линейный ансамбль. Это обычно обеспечивает неболькое повышение точности по сравнению с отдельными моделями.
Для нахождения оптимальных весов постройте линейную регрессию на основе прогнозов:
ensemble_weights = LinearRegression(positive=True, fit_intercept=False).fit(
np.c_[xgb_preds, rf_preds, linreg_preds], y
).coef_
# Normalize weights
ensemble_weights = ensemble_weights / ensemble_weights.sum()
ensemble_preds = np.c_[xgb_preds, rf_preds, linreg_preds] @ ensemble_weights
ensemble_rmse = np.sqrt(mean_squared_error(y, ensemble_preds))
Сравните результаты, чтобы увидеть прирост ансамбля:
print(f"\n{'Model':<20} {'RMSE':>10}")
print("-" * 32)
print(f"{'Linear Regression':<20} ${linreg_rmse:>9.4f}")
print(f"{'Random Forest':<20} ${rf_rmse:>9.4f}")
print(f"{'XGBoost':<20} ${xgb_rmse:>9.4f}")
print("-" * 32)
print(f"{'Ensemble':<20} ${ensemble_rmse:>9.4f}")
print(f"\nEnsemble lift: ${xgb_rmse - ensemble_rmse:.4f}")
11. Сравните производительность ЦП и ГП.
Для корректной оценки разницы в производительности необходимо перезапустить ядро, чтобы обеспечить корректное состояние выполнения, запустить весь конвейер обработки данных на ЦП, а затем снова запустить его на ГП.
Перезапустите ядро.
Выполните команду IPython.Application.instance().kernel.do_shutdown(True) , чтобы перезапустить ядро и освободить память.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
Определите конвейер обработки данных в области науки о данных.
Объедините основной рабочий процесс (загрузка данных, очистка, создание признаков и обучение модели) в одну функцию. Эта функция принимает модуль pandas pd_module и аргумент use_gpu для переключения между средами.
def run_ml_pipeline(pd_module, use_gpu=False):
import time
import glob
import numpy as np
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
timings = {}
# 1. Load Data
t0 = time.perf_counter()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
timings['Load Data'] = time.perf_counter() - t0
# 2. Clean Data
t0 = time.perf_counter()
# Filter for payment_type=1 (credit card) because tip amounts
# are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
timings['Clean Data'] = time.perf_counter() - t0
# 3. Feature Engineering
t0 = time.perf_counter()
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['fare_log'] = np.log1p(df['fare_amount'])
timings['Feature Engineering'] = time.perf_counter() - t0
# 4. Modeling Prep
feature_cols = ['trip_distance', 'fare_amount', 'passenger_count', 'hour', 'dow', 'is_weekend', 'fare_log']
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
# Free memory
del df
import gc
gc.collect()
# 5. Train Random Forest
t0 = time.perf_counter()
rf_model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
).fit(X, y)
timings['Train Random Forest'] = time.perf_counter() - t0
# 6. Train XGBoost
t0 = time.perf_counter()
params = {
'objective': 'reg:squarederror',
'max_depth': 5,
'n_estimators': 100,
'random_state': 42
}
if use_gpu:
params['device'] = 'cuda'
params['tree_method'] = 'hist'
xgb_model = xgb.XGBRegressor(**params).fit(X, y)
timings['Train XGBoost'] = time.perf_counter() - t0
del X
del y
gc.collect()
return timings
Запустите на вашем процессоре
Вызовите конвейер, используя стандартные функции pandas для обработки данных с процессора.
import pandas as pd
print("Running pipeline on CPU...")
cpu_times = run_ml_pipeline(pd, use_gpu=False)
print("CPU Execution Finished.")
Запустите на вашем графическом процессоре.
Загрузите расширения библиотеки NVIDIA, передайте ускоренный модуль cudf.pandas в конвейер и настройте устройство XGBoost на cuda внутри системы.
import IPython.core.magic
if not hasattr(IPython.core.magic, 'output_can_be_silenced'):
IPython.core.magic.output_can_be_silenced = lambda x: x
%load_ext cudf.pandas
%load_ext cuml.accel
import pandas as pd
print("Running pipeline on GPU...")
gpu_times = run_ml_pipeline(pd, use_gpu=True)
print("GPU Execution Finished.")
Визуализируйте ускорение производительности.
Визуализируйте время выполнения с помощью matplotlib . Результаты показывают экономию времени при обработке данных и обучении модели при использовании графических процессоров.
import matplotlib.pyplot as plt
import numpy as np
labels = list(cpu_times.keys())
cpu_values = list(cpu_times.values())
gpu_values = list(gpu_times.values())
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots(figsize=(10, 6))
rects1 = ax.bar(x - width/2, cpu_values, width, label='CPU', color='#4285F4')
rects2 = ax.bar(x + width/2, gpu_values, width, label='GPU', color='#76B900')
ax.set_ylabel('Execution Time (seconds)')
ax.set_title('NYC Taxi ML Pipeline: CPU vs. GPU Performance')
ax.set_xticks(x)
ax.set_xticklabels(labels, rotation=45, ha="right")
ax.legend()
# Add data labels
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(f'{height:.2f}s',
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom', fontsize=9)
autolabel(rects1)
autolabel(rects2)
plt.tight_layout()
plt.show()
# Calculate overall speedup
total_cpu_time = sum(cpu_values)
total_gpu_time = sum(gpu_values)
overall_speedup = total_cpu_time / total_gpu_time
print(f"\nOverall Pipeline Speedup: {overall_speedup:.2f}x faster on GPU!")
Вы должны увидеть что-то подобное:

Этот график иллюстрирует значительное преимущество графического процессора (GPU) в производительности на протяжении всего рабочего процесса обработки данных. Наиболее существенную экономию времени следует ожидать на этапах ресурсоемкого обучения моделей для таких алгоритмов, как Random Forest и XGBoost.
12. Проанализируйте свой код, чтобы выявить ограничения производительности.
При использовании cudf.pandas большинство функций выполняются на графическом процессоре. Если конкретная операция еще не поддерживается cuDF , выполнение временно переключается на центральный процессор. NVIDIA предоставляет две встроенные команды Jupyter для определения таких переключений.
Высокоуровневое профилирование с помощью %%cudf.pandas.profile
Магическая команда %%cudf.pandas.profile предоставляет сводную информацию о том, какие функции выполнялись на графическом или центральном процессоре.
%%cudf.pandas.profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
summary = (
df
.groupby(['PULocationID', 'payment_type'])
[['passenger_count', 'fare_amount', 'tip_amount']]
.agg(['min', 'mean', 'max'])
)

Построчное профилирование с помощью %%cudf.pandas.line_profile
Для более детальной диагностики проблем функция %%cudf.pandas.line_profile добавляет к каждой строке кода информацию о количестве выполнений на графическом процессоре и на центральном процессоре.
%%cudf.pandas.line_profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
df = df.sample(1_000)
# Iterating row-by-row or using custom python apply functions often falls back to the CPU
def categorize_hour(hour):
if hour < 12:
return 'Morning'
else:
return 'Afternoon/Evening'
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['time_of_day_slow'] = df['hour'].apply(categorize_hour)
# Using vectorized pandas operations (like pd.cut) stays entirely on the GPU
cut_bins = [-1, 11, 24]
cut_labels = ['Morning', 'Afternoon/Evening']
df['time_of_day_fast'] = pd.cut(df['hour'], bins=cut_bins, labels=cut_labels)

13. Уборка
Чтобы избежать непредвиденных расходов на вашем аккаунте Google Cloud, очистите ресурсы, созданные вами в ходе этого практического занятия.
Удалить ресурсы
Удалите локальный набор данных во время выполнения, используя команду !rm -rf в ячейке блокнота.
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Остановите среду выполнения Colab.
- В консоли Google Cloud перейдите на страницу Colab Enterprise Runtimes .
- В меню «Регион» выберите регион, в котором находится ваша среда выполнения.
- Выберите среду выполнения, которую хотите удалить.
- Нажмите «Удалить» .
- Нажмите «Подтвердить» .
Удалите свой блокнот
- В консоли Google Cloud перейдите на страницу «Мои блокноты» в Colab Enterprise.
- В меню «Регион» выберите регион, в котором находится ваш ноутбук.
- Выберите блокнот, который хотите удалить.
- Нажмите «Удалить» .
- Нажмите «Подтвердить» .
14. Поздравляем!
Поздравляем! Вы успешно ускорили рабочий процесс машинного обучения с использованием pandas и scikit-learn применяя библиотеки NVIDIA cuDF и cuML в Colab Enterprise. Просто добавив несколько «магических» команд ( %load_ext cudf.pandas и %load_ext cuml.accel ), ваш стандартный код запускается на графическом процессоре, обрабатывая записи и подгоняя сложные модели локально за гораздо меньшее время.
Для получения дополнительной информации об ускорении анализа данных с помощью графических процессоров см. практическое занятие по ускоренному анализу данных с использованием графических процессоров .
Что мы рассмотрели
- Введение в Colab Enterprise в Google Cloud.
- Настройка среды выполнения Colab с учетом конкретных конфигураций графического процессора и памяти.
- Применение ускорения графического процессора для прогнозирования размера чаевых с использованием миллионов записей из набора данных о нью-йоркских такси.
- Ускорение работы
pandasбез изменений в коде с помощью библиотекиcuDFот NVIDIA. - Ускорение работы
scikit-learnбез изменений в коде с использованием библиотекиcuMLот NVIDIA и графических процессоров. - Профилирование кода для выявления и оптимизации ограничений производительности.