
1. はじめに
この Codelab では、Google Cloud で NVIDIA GPU とオープンソース ライブラリを使用して、大規模なデータセットでデータ サイエンスと ML のワークフローを高速化する方法について説明します。まず、インフラストラクチャを設定し、GPU アクセラレーションを適用する方法を学習します。
このチュートリアルでは、pandas を使用したデータの準備から、scikit-learn と XGBoost を使用したモデルのトレーニングまで、データ サイエンスのライフサイクルに焦点を当てます。このラボでは、NVIDIA の cuDF ライブラリと cuML ライブラリを使用して、これらのタスクを高速化する方法を学びます。最大のメリットは、既存の pandas または scikit-learn コードを変更することなく、この GPU アクセラレーションを利用できることです。
学習内容
- Google Cloud の Colab Enterprise について理解する。
- 特定の GPU とメモリ構成で Colab ランタイム環境をカスタマイズする。
- GPU アクセラレーションを適用して、ニューヨーク市のタクシー データセットの数百万件のレコードを使用してチップの金額を予測します。
- NVIDIA の
cuDFライブラリを使用して、コードを変更することなくpandasを高速化します。 - NVIDIA の
cuMLライブラリと GPU を使用して、コードを変更せずにscikit-learnを高速化します。 - コードをプロファイリングして、パフォーマンスの制約を特定し、最適化します。
2. ML を高速化する理由
ML でのイテレーションの高速化の必要性
データの準備には時間がかかり、データセットが大きくなるにつれて、モデルのトレーニングや評価にさらに時間がかかることがあります。CPU で数百万行のランダム フォレストや XGBoost などのモデルをトレーニングすると、数時間から数日かかることがあります。
GPU を使用すると、cuML などのライブラリと GPU アクセラレーションによる XGBoost を使用して、これらのトレーニング実行を高速化できます。このアクセラレーションにより、次のことが可能になります。
- 迅速な反復処理: 新しい機能とハイパーパラメータを迅速にテストします。
- 完全なデータセットでトレーニングする: 精度を高めるため、ダウンサンプリングではなく完全なデータを使用します。
- コストを削減する: 重いワークロードを短時間で完了し、コンピューティング コストを削減します。
3. 設定と要件
潜在的な費用
このコードラボでは、NVIDIA L4 GPU を搭載した Colab Enterprise ランタイムなどの Google Cloud リソースを使用します。課金が発生する可能性があることに注意し、Codelab の最後にあるクリーンアップ セクションの手順に沿ってリソースをシャットダウンし、継続的な課金を回避してください。料金の詳細については、Colab Enterprise の料金と GPU の料金をご覧ください。
始める前に
Python、pandas、scikit-learn、標準的な ML プラクティス(交差検証やアンサンブルなど)に関する中級レベルの知識があることを前提としています。
- Google Cloud Console の [プロジェクト セレクタ] ページで、Google Cloud プロジェクトを選択または作成します。
- Google Cloud プロジェクトの課金が有効になっていることを確認します。
API を有効にする
Colab Enterprise を使用するには、まず必要な API を有効にする必要があります。
- Google Cloud コンソールの右上にある Cloud Shell アイコンをクリックして、Google Cloud Shell を開きます。

- Cloud Shell で、
PROJECT_IDをプロジェクト ID に置き換えて、プロジェクト ID を設定します。
gcloud config set project <PROJECT_ID>
- 次のコマンドを実行して、必要な API を有効にします。
gcloud services enable \
compute.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com
実行が成功すると、次のようなメッセージが表示されます。
Operation "operations/..." finished successfully.
4. ノートブック環境の選択
多くのデータ サイエンティストは個人プロジェクトで Colab を使用していますが、Colab Enterprise は企業向けに設計された安全で共同作業が可能な統合ノートブック エクスペリエンスを提供します。
Google Cloud には、マネージド ノートブック環境として Colab Enterprise と Vertex AI Workbench の 2 つの主な選択肢があります。適切な選択は、プロジェクトの優先度によって異なります。
Vertex AI Workbench を使用する場合
制御と詳細なカスタマイズが優先される場合は、Vertex AI Workbench を選択します。この方法は、次のような場合に最適です。
- 基盤となるインフラストラクチャとマシンのライフサイクルを管理します。
- カスタム コンテナとネットワーク構成を使用する。
- MLOps パイプラインとカスタム ライフサイクル ツールと統合します。
Colab Enterprise を使用するタイミング
迅速な設定、使いやすさ、安全なコラボレーションを重視する場合は、Colab Enterprise を選択します。これは、チームがインフラストラクチャではなく分析に集中できるフルマネージド ソリューションです。
Colab Enterprise は、次のことを支援します。
- データ ウェアハウスに密接に関連するデータ サイエンスのワークフローを開発します。ノートブックは BigQuery Studio で直接開いて管理できます。
- Vertex AI で ML モデルをトレーニングし、MLOps ツールと統合します。
- 柔軟で統一されたエクスペリエンスをお楽しみください。BigQuery で作成された Colab Enterprise ノートブックは、Vertex AI で開いて実行できます。その逆も可能です。
今日のラボ
この Codelab では、高速化された ML に Colab Enterprise を使用します。
違いの詳細については、適切なノートブック ソリューションの選択に関する公式ドキュメントをご覧ください。
5. ランタイム テンプレートを構成する
Colab Enterprise では、事前構成されたランタイム テンプレートに基づいてランタイムに接続します。
ランタイム テンプレートは、ノートブックの環境を指定する再利用可能な構成です。これには次のものが含まれます。
- マシンタイプ(CPU、メモリ)
- アクセラレータ(GPU のタイプと数)
- ディスクのサイズとタイプ
- ネットワーク設定とセキュリティ ポリシー
- 自動アイドル シャットダウン ルール
ランタイム テンプレートが有用な理由
- 一貫性: チーム全体で同じ環境を使用できるため、作業の再現性が確保されます。
- セキュリティ: テンプレートは組織のセキュリティ ポリシーを適用します。
- 費用管理: テンプレートでリソースのサイズが事前に設定されているため、意図しない費用が発生するのを防ぐことができます。
ランタイム テンプレートを作成する
ラボ用に再利用可能なランタイム テンプレートを設定します。
- Google Cloud コンソールで、ナビゲーション メニュー > Vertex AI > Colab Enterprise に移動します。

- Colab Enterprise で、[ランタイム テンプレート] をクリックし、[新しいテンプレート] を選択します。
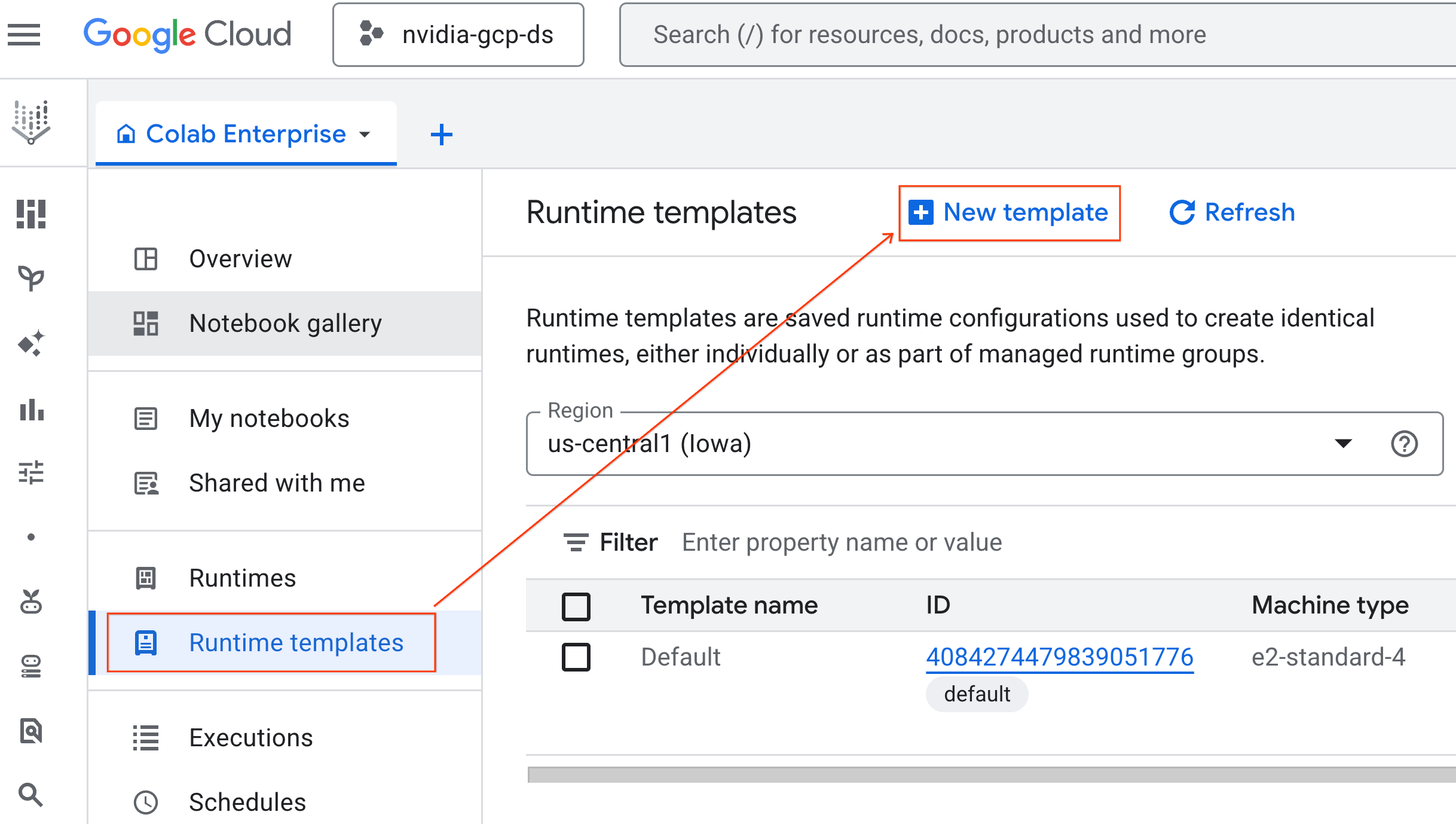
- [ランタイムの基本] で、次の操作を行います。
- [表示名] を
gpu-templateに設定します。 - 優先するリージョンを設定します。
- [表示名] を

- [コンピューティングを構成] で、次の操作を行います。
- [マシンタイプ] を
g2-standard-4に設定します。 - デフォルトの [アクセラレータ タイプ] は
NVIDIA L4のままで、[アクセラレータ数] は 1 にします。 - [アイドル状態でのシャットダウン] を 60 分に変更します。
- [続行] をクリックします。
- [マシンタイプ] を
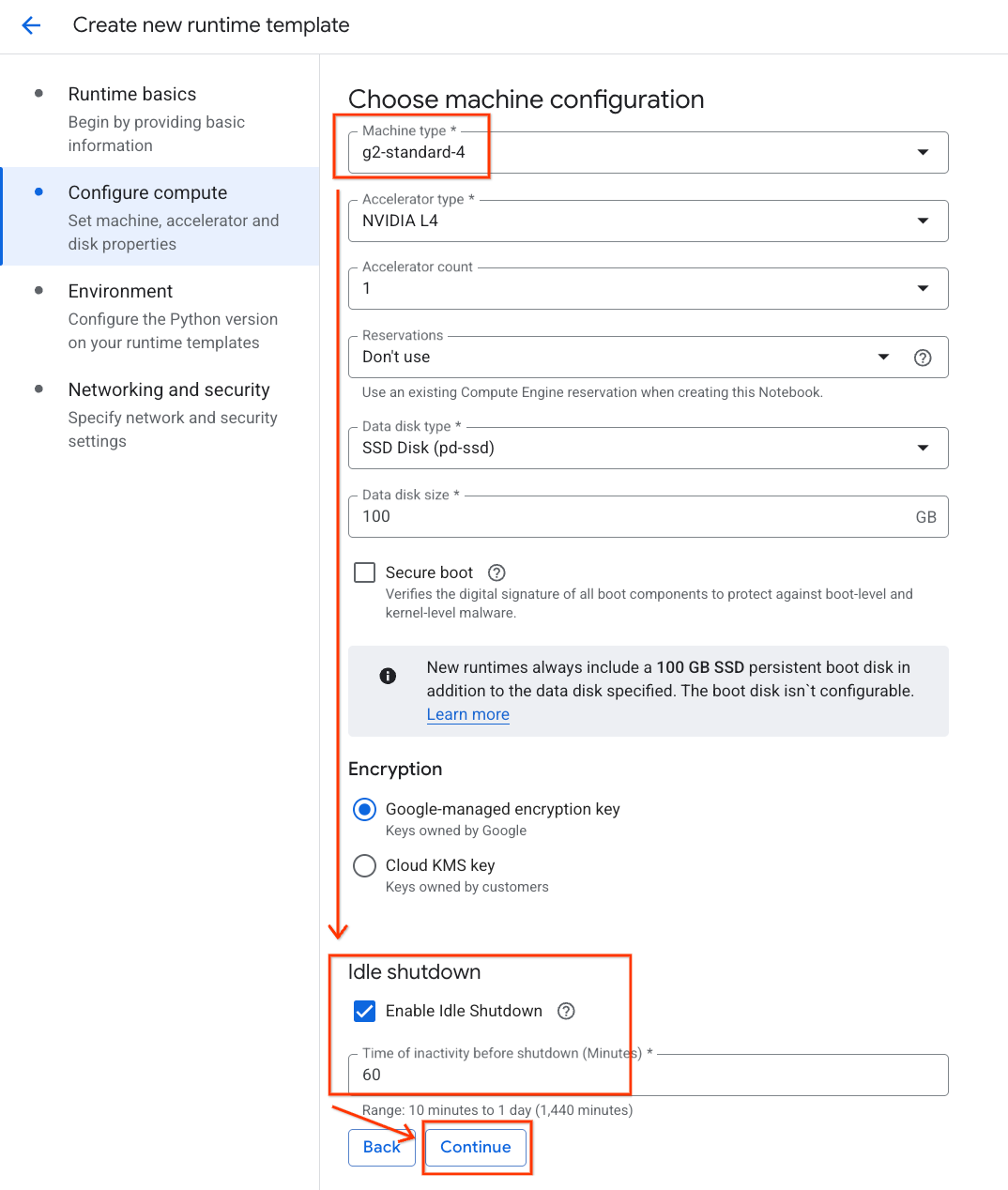
- [環境] で、次の操作を行います。
- [環境] を
Python 3.11に設定します。
- [環境] を

- [作成] をクリックして、ランタイム テンプレートを保存します。[ランタイム テンプレート] ページに新しいテンプレートが表示されます。
6. ランタイムを開始する
テンプレートの準備ができたら、新しいランタイムを作成できます。
- Colab Enterprise で、[ランタイム] をクリックし、[作成] を選択します。
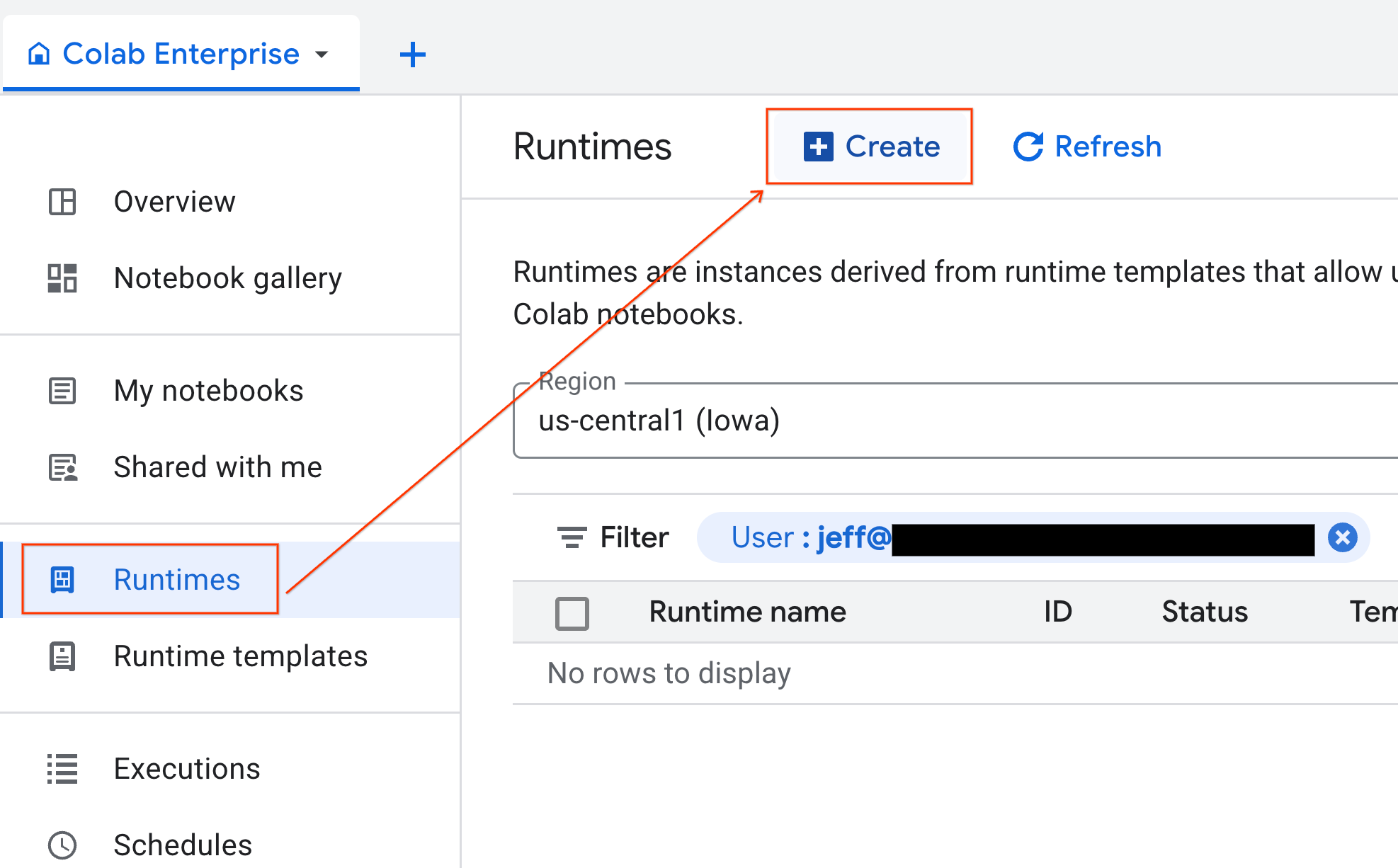
- [ランタイム テンプレート] で、[
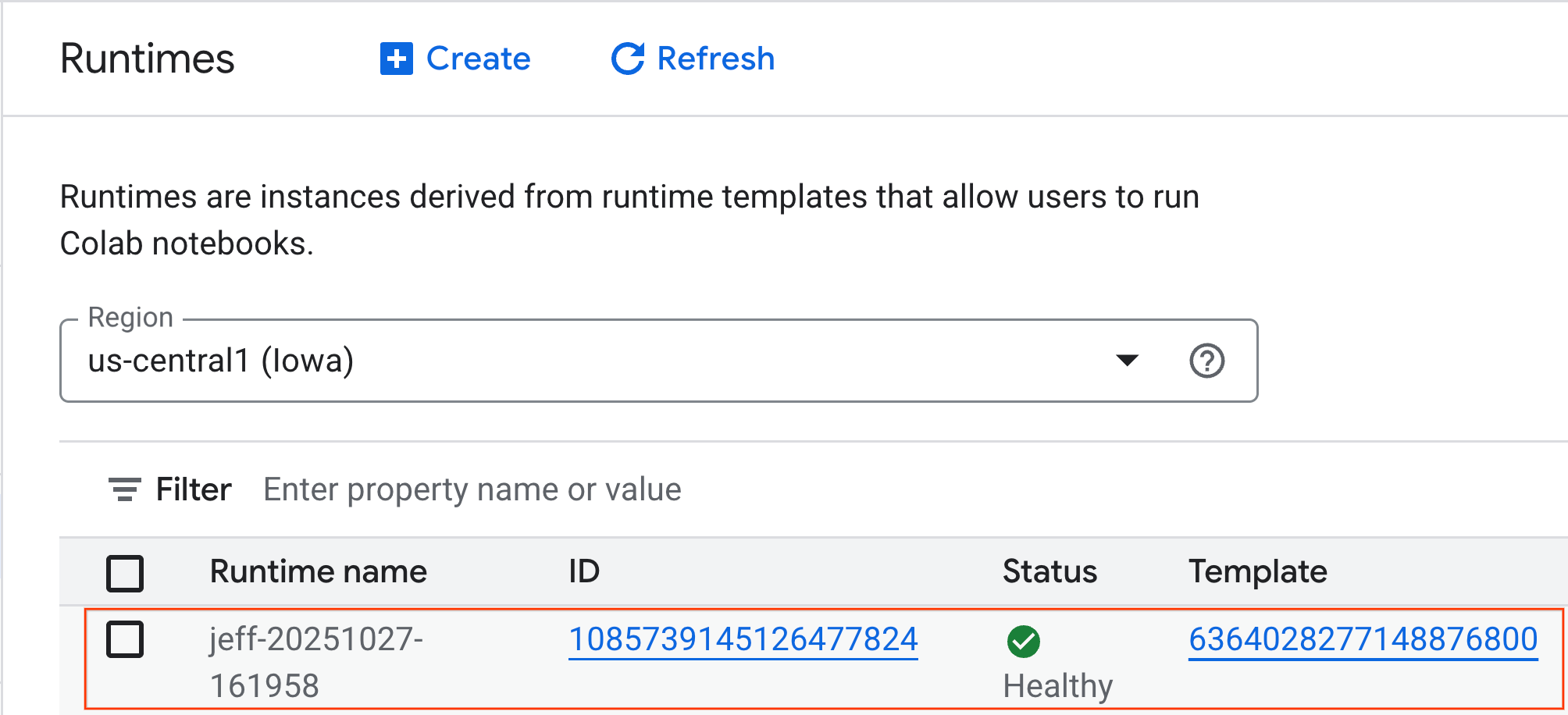
gpu-template] オプションを選択します。[作成] をクリックし、ランタイムが起動するまで待ちます。

- 数分後、ランタイムが利用可能になります。
7. ノートブックを設定する
インフラストラクチャが実行されたので、ラボのノートブックをインポートしてランタイムに接続する必要があります。
ノートブックをインポートする
- Colab Enterprise で、[マイ ノートブック] をクリックし、[インポート] をクリックします。
![[ノートブックのインポート] ペインを開きます](https://codelabs.developers.google.cn/static/accelerated-ml-with-gpus/img/notebook/1_import.png?hl=ja)
- [URL] ラジオボタンを選択し、次の URL を入力します。
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/regression/gpu_accelerated_regression/gpu_accelerated_regression.ipynb
- [インポート] をクリックすると、Colab Enterprise が GitHub から環境にノートブックをコピーします。

ランタイムに接続する
- 新しくインポートしたノートブックを開きます。
- [接続] の横にある下矢印をクリックします。
- [ランタイムに接続する] を選択します。
![[ノートブックのインポート] ペインを開きます](https://codelabs.developers.google.cn/static/accelerated-ml-with-gpus/img/notebook/2_start_connection.png?hl=ja)
- プルダウンを使用して、以前に作成したランタイムを選択します。
- [接続] をクリックします。
![[ノートブックのインポート] ペインを開きます](https://codelabs.developers.google.cn/static/accelerated-ml-with-gpus/img/notebook/3_final_connection.png?hl=ja)
これで、ノートブックが GPU 対応ランタイムに接続されました。
組み込みの依存関係
Colab Enterprise を使用するメリットの 1 つは、必要なライブラリがプリインストールされていることです。このラボでは、cuDF、cuML、XGBoost などの依存関係を手動でインストールまたは管理する必要はありません。
8. ニューヨーク市のタクシー データセットを準備する
この Codelab では、NYC Taxi & Limousine Commission(TLC)の乗車記録データを使用します。このデータセットには、ニューヨーク市のイエロー タクシーの乗車記録が含まれています。内容は次のとおりです。
- 乗車と降車の日時と場所
- 移動距離
- 運賃の明細金額
- 乗客数
- チップの金額(これが予測対象です)
GPU を構成して可用性を確認する
nvidia-smi コマンドを実行すると、GPU が認識されていることを確認できます。ドライバのバージョンと GPU の詳細(NVIDIA L4 など)が表示されます。
nvidia-smi
セルには、ランタイムに接続されている GPU が次のように返されます。

データをダウンロード
2024 年の乗車データをダウンロードします。
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
NVIDIA cuDF で pandas を高速化する
pandas ライブラリは CPU で実行され、大規模なデータセットでは処理が遅くなる可能性があります。NVIDIA %load_ext cudf.pandas マジック コマンドは、GPU アクセラレーションを使用するように pandas を動的にパッチ適用し、必要に応じて CPU にフォールバックします。
このマジック コマンドは、標準のインポートではなく、コード変更なしで高速化を実現するために使用します。既存のコードを書き直す必要はありません。同様のコマンド %load_ext cuml.accel は、scikit-learn models に対して同じ処理を行います。これは、Colab Enterprise だけでなく、互換性のある NVIDIA GPU を備えたあらゆる Jupyter 環境で動作します。
%load_ext cudf.pandas
アクティブであることを確認するには、pandas をインポートしてその型を確認します。
import pandas as pd
pd
出力で、cudf.pandas モジュールを使用していることを確認します。
データの読み込みとクリーンアップ
cudf.pandas が有効になっている状態で、Parquet ファイルを読み込み、データ クリーニングを実行します。このプロセスは GPU で自動的に実行されます。
import glob
# Load data into memory
df = pd.concat(
[pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
# Filter for valid trips. We filter for payment_type=1 (credit card)
# because tip amounts are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
特徴量エンジニアリング
乗車日時から派生特徴を作成します。このノートブックには、後のステップで使用する他の機能も含まれています。
import numpy as np
# Time Features
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['is_rush_hour'] = (
((df['hour'] >= 7) & (df['hour'] <= 9)) |
((df['hour'] >= 17) & (df['hour'] <= 19))
).astype(int)
...
# Other features
...
9. 交差検証で個々のモデルをトレーニングする
GPU で機械学習を高速化する方法を示すため、3 種類の回帰モデルをトレーニングして、タクシー乗車の tip_amount を予測します。
NVIDIA cuML で scikit-learn を高速化する
API 呼び出しを変更せずに、NVIDIA cuML を使用して GPU で scikit-learn アルゴリズムを実行します。まず、cuml.accel 拡張機能を読み込みます。
%load_ext cuml.accel
機能と目標を設定する
モデルに学習させる特徴を特定し、ターゲット列(tip_amount)を分割します。
feature_cols = [
'trip_distance', 'fare_amount', 'passenger_count',
'hour', 'dow', 'is_weekend', 'is_rush_hour',
'fare_log', 'fare_decimal', 'is_round_fare',
'route_frequency', 'pu_tip_mean', 'pu_tip_std',
'PULocationID', 'DOLocationID'
]
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
モデルのパフォーマンスを堅牢に評価するために、交差検証分割を設定します。
from sklearn.model_selection import KFold
import numpy as np
import time
from sklearn.metrics import mean_squared_error
from tqdm.notebook import tqdm
n_splits = 3
kf = KFold(n_splits=n_splits, shuffle=True, random_state=42)
1. XGBoost
XGBoost はネイティブに GPU アクセラレーションされます。トレーニング中に GPU を使用するには、tree_method='hist' と device='cuda' を渡します。
import xgboost as xgb
start_time = time.perf_counter()
def train_xgb_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# XGBoost handles GPU natively when tree_method='hist' and device='cuda'
model = xgb.XGBRegressor(
objective='reg:squarederror',
max_depth=5,
learning_rate=0.1,
n_estimators=100,
tree_method='hist',
device='cuda',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
xgb_rmse, xgb_preds = train_xgb_cv(X, y)
print(f"\n{'XGBoost RMSE:':<20} ${xgb_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
2. 線形回帰
線形回帰モデルをトレーニングします。%load_ext cuml.accel が有効になっている場合、LinearRegression は GPU 相当に自動的にマッピングされます。
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
start_time = time.perf_counter()
def train_linreg_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
# Automatically accelerated by cuML
model = LinearRegression()
model.fit(X_train_scaled, y_train)
preds = model.predict(X_val_scaled)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
linreg_rmse, linreg_preds = train_linreg_cv(X, y)
print(f"\n{'Linear Reg RMSE:':<20} ${linreg_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
3. ランダム フォレスト
RandomForestRegressor を使用してアンサンブル モデルをトレーニングします。ツリーベースのモデルは CPU でのトレーニングに時間がかかることが多いですが、GPU アクセラレーションでは数百万行をより高速に処理できます。
from sklearn.ensemble import RandomForestRegressor
start_time = time.perf_counter()
def train_rf_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Automatically accelerated by cuML
model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
rf_rmse, rf_preds = train_rf_cv(X, y)
print(f"\n{'Random Forest RMSE:':<20} ${rf_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
10. エンドツーエンドのパイプラインを評価する
単純な線形アンサンブルを使用して、3 つのモデルの予測を組み合わせます。通常、これにより個々のモデルよりも精度が若干向上します。
予測に線形回帰を適合させて、最適な重みを求めます。
ensemble_weights = LinearRegression(positive=True, fit_intercept=False).fit(
np.c_[xgb_preds, rf_preds, linreg_preds], y
).coef_
# Normalize weights
ensemble_weights = ensemble_weights / ensemble_weights.sum()
ensemble_preds = np.c_[xgb_preds, rf_preds, linreg_preds] @ ensemble_weights
ensemble_rmse = np.sqrt(mean_squared_error(y, ensemble_preds))
結果を比較して、アンサンブルの引き上げを確認します。
print(f"\n{'Model':<20} {'RMSE':>10}")
print("-" * 32)
print(f"{'Linear Regression':<20} ${linreg_rmse:>9.4f}")
print(f"{'Random Forest':<20} ${rf_rmse:>9.4f}")
print(f"{'XGBoost':<20} ${xgb_rmse:>9.4f}")
print("-" * 32)
print(f"{'Ensemble':<20} ${ensemble_rmse:>9.4f}")
print(f"\nEnsemble lift: ${xgb_rmse - ensemble_rmse:.4f}")
11. CPU と GPU のパフォーマンスを比較する
パフォーマンスの違いを適切にベンチマークするには、カーネルを再起動してクリーンな実行状態を確保し、データ サイエンス パイプライン全体を CPU で実行してから、GPU で再度実行します。
カーネルの再起動
IPython.Application.instance().kernel.do_shutdown(True) コマンドを実行して、カーネルを再起動し、メモリを解放します。
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
データ サイエンス パイプラインを定義する
コア ワークフロー(データの読み込み、クリーニング、特徴量エンジニアリング、モデルのトレーニング)を 1 つの関数にラップします。この関数は、環境を切り替えるために pandas モジュール pd_module と use_gpu 引数を受け取ります。
def run_ml_pipeline(pd_module, use_gpu=False):
import time
import glob
import numpy as np
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
timings = {}
# 1. Load Data
t0 = time.perf_counter()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
timings['Load Data'] = time.perf_counter() - t0
# 2. Clean Data
t0 = time.perf_counter()
# Filter for payment_type=1 (credit card) because tip amounts
# are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
timings['Clean Data'] = time.perf_counter() - t0
# 3. Feature Engineering
t0 = time.perf_counter()
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['fare_log'] = np.log1p(df['fare_amount'])
timings['Feature Engineering'] = time.perf_counter() - t0
# 4. Modeling Prep
feature_cols = ['trip_distance', 'fare_amount', 'passenger_count', 'hour', 'dow', 'is_weekend', 'fare_log']
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
# Free memory
del df
import gc
gc.collect()
# 5. Train Random Forest
t0 = time.perf_counter()
rf_model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
).fit(X, y)
timings['Train Random Forest'] = time.perf_counter() - t0
# 6. Train XGBoost
t0 = time.perf_counter()
params = {
'objective': 'reg:squarederror',
'max_depth': 5,
'n_estimators': 100,
'random_state': 42
}
if use_gpu:
params['device'] = 'cuda'
params['tree_method'] = 'hist'
xgb_model = xgb.XGBRegressor(**params).fit(X, y)
timings['Train XGBoost'] = time.perf_counter() - t0
del X
del y
gc.collect()
return timings
CPU で実行する
標準の CPU pandas を使用してパイプラインを呼び出す。
import pandas as pd
print("Running pipeline on CPU...")
cpu_times = run_ml_pipeline(pd, use_gpu=False)
print("CPU Execution Finished.")
GPU で実行する
NVIDIA ライブラリ拡張機能を読み込み、高速化された cudf.pandas モジュールをパイプラインに渡し、XGBoost デバイスを内部的に cuda に設定します。
import IPython.core.magic
if not hasattr(IPython.core.magic, 'output_can_be_silenced'):
IPython.core.magic.output_can_be_silenced = lambda x: x
%load_ext cudf.pandas
%load_ext cuml.accel
import pandas as pd
print("Running pipeline on GPU...")
gpu_times = run_ml_pipeline(pd, use_gpu=True)
print("GPU Execution Finished.")
パフォーマンスの高速化を可視化する
matplotlib を使用してタイミングを可視化します。結果は、GPU を使用した場合のデータ処理とモデルのトレーニングで節約された時間を示しています。
import matplotlib.pyplot as plt
import numpy as np
labels = list(cpu_times.keys())
cpu_values = list(cpu_times.values())
gpu_values = list(gpu_times.values())
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots(figsize=(10, 6))
rects1 = ax.bar(x - width/2, cpu_values, width, label='CPU', color='#4285F4')
rects2 = ax.bar(x + width/2, gpu_values, width, label='GPU', color='#76B900')
ax.set_ylabel('Execution Time (seconds)')
ax.set_title('NYC Taxi ML Pipeline: CPU vs. GPU Performance')
ax.set_xticks(x)
ax.set_xticklabels(labels, rotation=45, ha="right")
ax.legend()
# Add data labels
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(f'{height:.2f}s',
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom', fontsize=9)
autolabel(rects1)
autolabel(rects2)
plt.tight_layout()
plt.show()
# Calculate overall speedup
total_cpu_time = sum(cpu_values)
total_gpu_time = sum(gpu_values)
overall_speedup = total_cpu_time / total_gpu_time
print(f"\nOverall Pipeline Speedup: {overall_speedup:.2f}x faster on GPU!")
次のような出力が表示されます。

このグラフは、データ サイエンス ワークフロー全体で GPU が大幅なパフォーマンス上の優位性を示していることを示しています。ランダム フォレストや XGBoost などのアルゴリズムでは、計算負荷の高いモデル トレーニング フェーズで最も大幅な時間短縮が実現されることが期待されます。
12. コードをプロファイリングしてパフォーマンスの制約を見つける
cudf.pandas を使用すると、ほとんどの関数が GPU で実行されます。特定のオペレーションが cuDF でまだサポートされていない場合、実行は一時的に CPU にフォールバックします。NVIDIA は、これらのフォールバックを特定するための 2 つの組み込み Jupyter マジック コマンドを提供しています。
%%cudf.pandas.profile を使用したハイレベル プロファイリング
%%cudf.pandas.profile マジック コマンドは、GPU または CPU で実行された関数の概要を提供します。
%%cudf.pandas.profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
summary = (
df
.groupby(['PULocationID', 'payment_type'])
[['passenger_count', 'fare_amount', 'tip_amount']]
.agg(['min', 'mean', 'max'])
)

%%cudf.pandas.line_profile を使用した行ごとのプロファイリング
詳細なトラブルシューティングを行うため、%%cudf.pandas.line_profile は、GPU と CPU で実行された回数を各コード行に注釈します。
%%cudf.pandas.line_profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
df = df.sample(1_000)
# Iterating row-by-row or using custom python apply functions often falls back to the CPU
def categorize_hour(hour):
if hour < 12:
return 'Morning'
else:
return 'Afternoon/Evening'
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['time_of_day_slow'] = df['hour'].apply(categorize_hour)
# Using vectorized pandas operations (like pd.cut) stays entirely on the GPU
cut_bins = [-1, 11, 24]
cut_labels = ['Morning', 'Afternoon/Evening']
df['time_of_day_fast'] = pd.cut(df['hour'], bins=cut_bins, labels=cut_labels)

13. クリーンアップ
Google Cloud アカウントに予期しない料金が発生しないようにするには、この Codelab で作成したリソースをクリーンアップします。
リソースの削除
ノートブック セルで !rm -rf コマンドを使用して、ランタイムのローカル データセットを削除します。
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Colab ランタイムをシャットダウンする
- Google Cloud コンソールで、Colab Enterprise の [ランタイム] ページに移動します。
- [リージョン] メニューで、ランタイムを含むリージョンを選択します。
- 削除するランタイムを選択します。
- [削除] をクリックします。
- [確認] をクリックします。
ノートブックを削除する
- Google Cloud コンソールで、Colab Enterprise の [マイ ノートブック] ページに移動します。
- [リージョン] メニューで、ノートブックを含むリージョンを選択します。
- 削除するノートブックを選択します。
- [削除] をクリックします。
- [確認] をクリックします。
14. 完了
おめでとうございます!Colab Enterprise で NVIDIA cuDF ライブラリと cuML ライブラリを使用して、pandas と scikit-learn の ML ワークフローを高速化しました。いくつかのマジック コマンド(%load_ext cudf.pandas と %load_ext cuml.accel)を追加するだけで、標準コードが GPU で実行され、レコードが処理され、複雑なモデルがローカルで短時間で適合します。
データ分析の GPU アクセラレーションの詳細については、GPU による高速データ分析の Codelab をご覧ください。
学習した内容
- Google Cloud での Colab Enterprise について理解する。
- 特定の GPU とメモリ構成で Colab ランタイム環境をカスタマイズする。
- ニューヨーク市のタクシー データセットの数百万件のレコードを使用して、チップの金額を予測するために GPU アクセラレーションを適用します。
- NVIDIA の
cuDFライブラリを使用して、コードを変更せずにpandasを高速化します。 - NVIDIA の
cuMLライブラリと GPU を使用して、コードを変更せずにscikit-learnを高速化します。 - コードをプロファイリングして、パフォーマンスの制約を特定し、最適化する。