
1. Introduzione
In questo codelab imparerai ad accelerare i flussi di lavoro di data science e machine learning su set di dati di grandi dimensioni utilizzando le GPU NVIDIA e le librerie open source su Google Cloud. Inizierai configurando l'infrastruttura, poi esplorerai come applicare l'accelerazione GPU.
Ti concentrerai sul ciclo di vita della data science, dalla preparazione dei dati con pandas all'addestramento del modello con scikit-learn e XGBoost. Imparerai ad accelerare queste attività utilizzando le librerie cuDF e cuML di NVIDIA. La cosa migliore è che puoi ottenere questa accelerazione della GPU senza modificare il codice pandas o scikit-learn esistente.
Obiettivi didattici
- Comprendere Colab Enterprise su Google Cloud.
- Personalizza un ambiente di runtime Colab con configurazioni specifiche di GPU e memoria.
- Applica l'accelerazione GPU per prevedere gli importi delle mance utilizzando milioni di record di un set di dati NYC Taxi.
- Accelera
pandassenza modifiche al codice utilizzando la libreriacuDFdi NVIDIA. - Accelera
scikit-learnsenza modifiche al codice utilizzando la libreriacuMLe le GPU di NVIDIA. - Esegui la profilazione del codice per identificare e ottimizzare i vincoli di rendimento.
2. Perché accelerare il machine learning?
La necessità di un'iterazione più rapida nel machine learning
La preparazione dei dati richiede molto tempo e l'addestramento o la valutazione del modello possono richiedere ancora più tempo man mano che i set di dati crescono. L'addestramento di modelli come foreste casuali o XGBoost su milioni di righe con una CPU può richiedere ore o giorni.
L'utilizzo delle GPU accelera queste esecuzioni di addestramento con librerie come cuML e XGBoost con accelerazione GPU. Questa accelerazione ti consente di:
- Iterazione più rapida:testa rapidamente nuove funzionalità e iperparametri.
- Esegui l'addestramento su set di dati completi:utilizza i dati completi anziché il sottocampionamento per una maggiore precisione.
- Riduzione dei costi: completa i workload pesanti in meno tempo per ridurre i costi di calcolo.
3. Configurazione e requisiti
Costi potenziali
Questo codelab utilizza risorse Google Cloud, inclusi runtime Colab Enterprise con GPU NVIDIA L4. Tieni presente i potenziali addebiti e segui la sezione Pulizia alla fine del codelab per arrestare le risorse ed evitare la fatturazione continua. Per informazioni dettagliate sui prezzi, consulta Prezzi di Colab Enterprise e Prezzi delle GPU.
Prima di iniziare
Si presuppone una familiarità intermedia con Python, pandas, scikit-learn e le pratiche standard di machine learning (come la convalida incrociata/l'aggregazione).
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Google Cloud.
Abilita le API
Per utilizzare Colab Enterprise, devi prima abilitare le API necessarie.
- Apri Google Cloud Shell facendo clic sull'icona di Cloud Shell in alto a destra della console Google Cloud.

- In Cloud Shell, imposta l'ID progetto sostituendo
PROJECT_IDcon il tuo ID progetto:
gcloud config set project <PROJECT_ID>
- Esegui il comando seguente per abilitare le API necessarie:
gcloud services enable \
compute.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com
Se l'esecuzione va a buon fine, dovresti visualizzare un messaggio simile a quello mostrato di seguito:
Operation "operations/..." finished successfully.
4. Scelta di un ambiente notebook
Molti data scientist conoscono Colab per i progetti personali, ma Colab Enterprise offre un'esperienza con notebook sicura, collaborativa e integrata progettata per le aziende.
Su Google Cloud, hai due scelte principali per gli ambienti notebook gestiti: Colab Enterprise e Vertex AI Workbench. La scelta giusta dipende dalle priorità del tuo progetto.
Quando utilizzare Vertex AI Workbench
Scegli Vertex AI Workbench quando la tua priorità è il controllo e la personalizzazione approfondita. È la scelta ideale se devi:
- Gestisci l'infrastruttura sottostante e il ciclo di vita della macchina.
- Utilizza container personalizzati e configurazioni di rete.
- Esegui l'integrazione con pipeline MLOps e strumenti personalizzati per il ciclo di vita.
Quando utilizzare Colab Enterprise
Scegli Colab Enterprise se la tua priorità è configurazione rapida, facilità d'uso e collaborazione sicura. È una soluzione completamente gestita che consente al tuo team di concentrarsi sull'analisi anziché sull'infrastruttura.
Colab Enterprise ti aiuta a:
- Sviluppa flussi di lavoro di data science strettamente correlati al tuo data warehouse. Puoi aprire e gestire i notebook direttamente in BigQuery Studio.
- Addestra modelli di machine learning e integrali con gli strumenti MLOps in Vertex AI.
- Goditi un'esperienza flessibile e unificata. Un notebook Colab Enterprise creato in BigQuery può essere aperto ed eseguito in Vertex AI e viceversa.
Laboratorio di oggi
Questo Codelab utilizza Colab Enterprise per il machine learning accelerato.
Per scoprire di più sulle differenze, consulta la documentazione ufficiale sulla scelta della soluzione di blocco note giusta.
5. Configurare un template di runtime
In Colab Enterprise, connettiti a un runtime basato su un template di runtime preconfigurato.
Un modello di runtime è una configurazione riutilizzabile che specifica l'ambiente per il notebook, tra cui:
- Tipo di macchina (CPU, memoria)
- Acceleratore (tipo e numero di GPU)
- Dimensioni e tipo di disco
- Impostazioni di rete e policy di sicurezza
- Regole di spegnimento automatico inattivo
Perché i modelli di runtime sono utili
- Coerenza:tu e il tuo team avete lo stesso ambiente per garantire che il lavoro sia ripetibile.
- Sicurezza:i modelli applicano le policy di sicurezza dell'organizzazione.
- Gestione dei costi:le risorse sono predimensionate nel modello per evitare costi accidentali.
Crea un template di runtime
Configura un modello di runtime riutilizzabile per il lab.
- Nella console Google Cloud, vai al menu di navigazione > Vertex AI > Colab Enterprise.

- In Colab Enterprise, fai clic su Modelli di runtime e poi seleziona Nuovo modello.
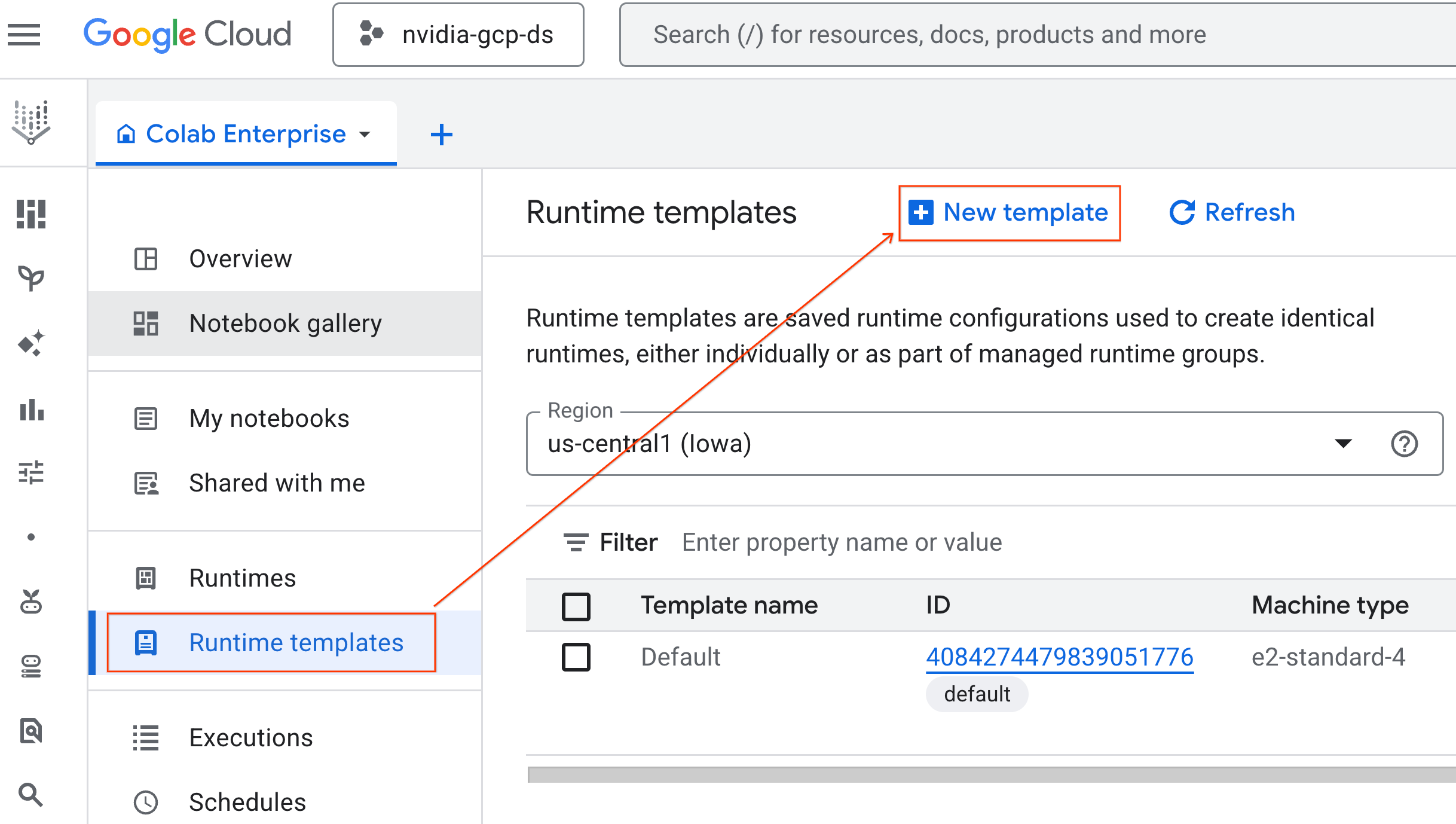
- In Nozioni di base sul runtime:
- Imposta il Nome visualizzato su
gpu-template. - Imposta la regione che preferisci.
- Imposta il Nome visualizzato su
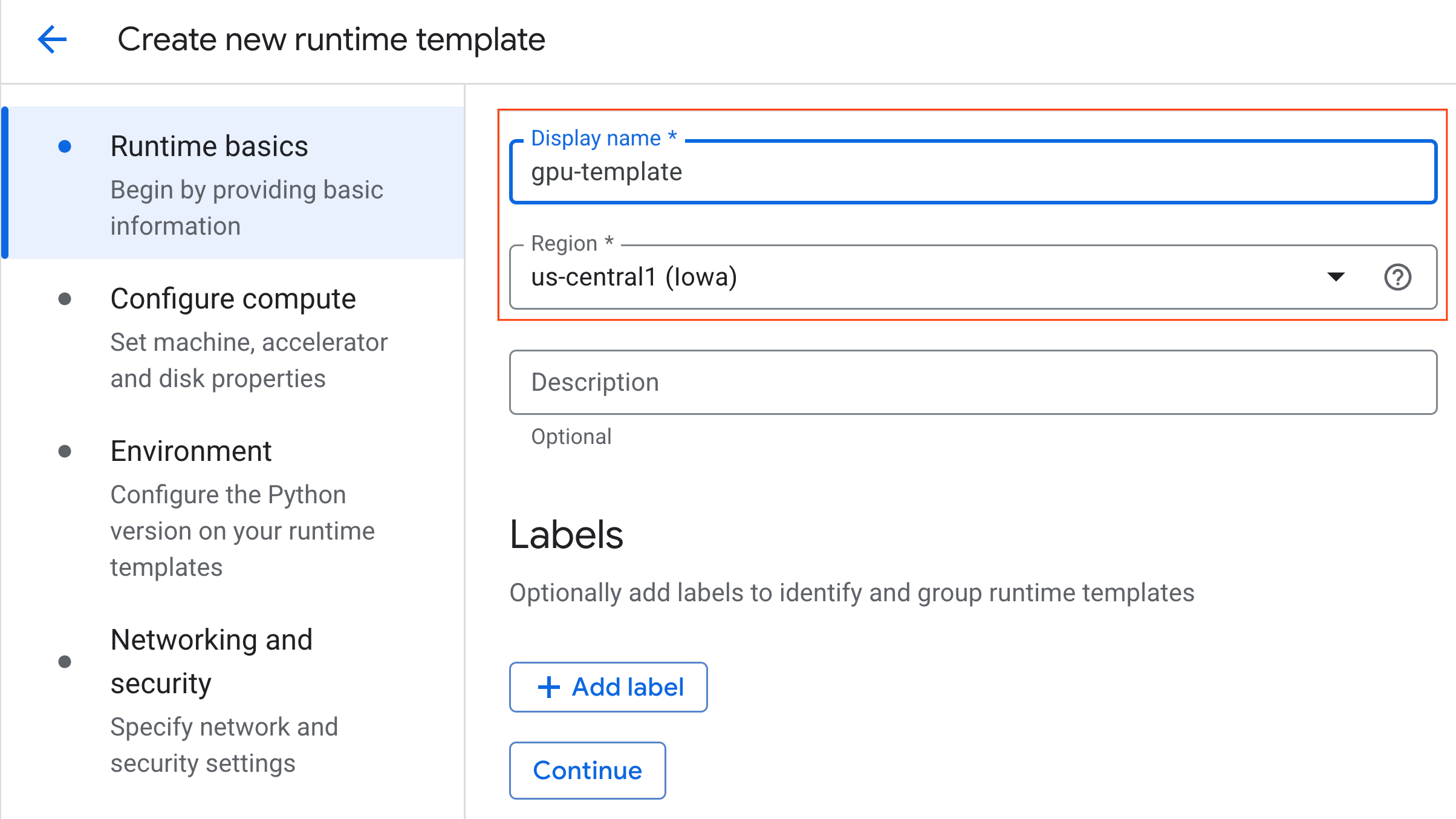
- In Configura calcolo:
- Imposta Tipo di macchina su
g2-standard-4. - Mantieni il Tipo di acceleratore predefinito
NVIDIA L4con un Conteggio acceleratori pari a 1. - Imposta Arresto inattivo su 60 minuti.
- Fai clic su Continua.
- Imposta Tipo di macchina su

- In Ambiente:
- Imposta Ambiente su
Python 3.11.
- Imposta Ambiente su

- Fai clic su Crea per salvare il modello di runtime. La pagina dei modelli di runtime ora dovrebbe mostrare il nuovo modello.
6. Avvia un runtime
Una volta pronto il modello, puoi creare un nuovo runtime.
- In Colab Enterprise, fai clic su Runtime e poi seleziona Crea.
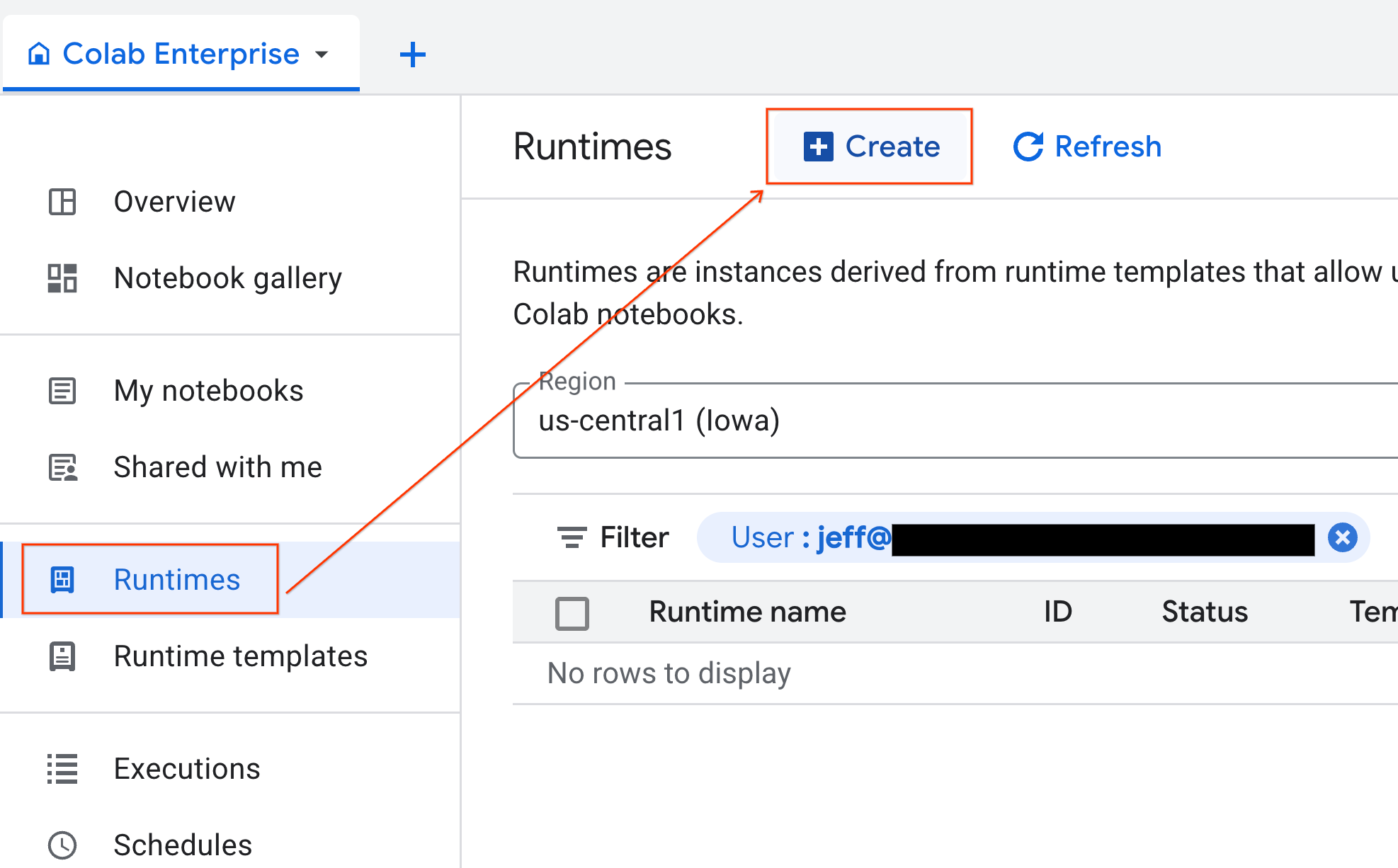
- In Modello di runtime, seleziona l'opzione
gpu-template. Fai clic su Crea e attendi l'avvio del runtime.

- Dopo qualche minuto, vedrai il runtime disponibile.

7. configura il notebook
Ora che l'infrastruttura è in esecuzione, devi importare il notebook del lab e connetterlo al runtime.
Importa il notebook
- In Colab Enterprise, fai clic su I miei blocchi note e poi su Importa.

- Seleziona il pulsante di opzione URL e inserisci il seguente URL:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/regression/gpu_accelerated_regression/gpu_accelerated_regression.ipynb
- Fai clic su Importa. Colab Enterprise copierà il notebook da GitHub nel tuo ambiente.

Connettiti al runtime
- Apri il notebook appena importato.
- Fai clic sulla Freccia giù accanto a Collega.
- Seleziona Connetti a un runtime.

- Utilizza il menu a discesa e seleziona il runtime che hai creato in precedenza.
- Fai clic su Connetti.

Il tuo notebook è ora connesso a un runtime abilitato per la GPU.
Dipendenze integrate
Uno dei vantaggi dell'utilizzo di Colab Enterprise è che viene fornito con le librerie necessarie preinstallate. Per questo lab non devi installare o gestire manualmente dipendenze come cuDF, cuML o XGBoost.
8. Prepara il set di dati sui taxi di New York
Questo codelab utilizza i dati di registrazione delle corse della NYC Taxi & Limousine Commission (TLC). Il set di dati contiene i record dei viaggi dei taxi gialli di New York, tra cui:
- Date, orari e località di partenza e arrivo
- Distanze dei viaggi
- Importi delle tariffe dettagliate
- Numero di passeggeri
- Importi delle mance (questo è ciò che prevederemo)
Configura la GPU e conferma la disponibilità
Puoi verificare che la GPU sia riconosciuta eseguendo il comando nvidia-smi. Vengono visualizzati la versione del driver e i dettagli della GPU (ad esempio NVIDIA L4).
nvidia-smi
La cella dovrebbe restituire la GPU collegata al runtime, in modo simile al seguente:
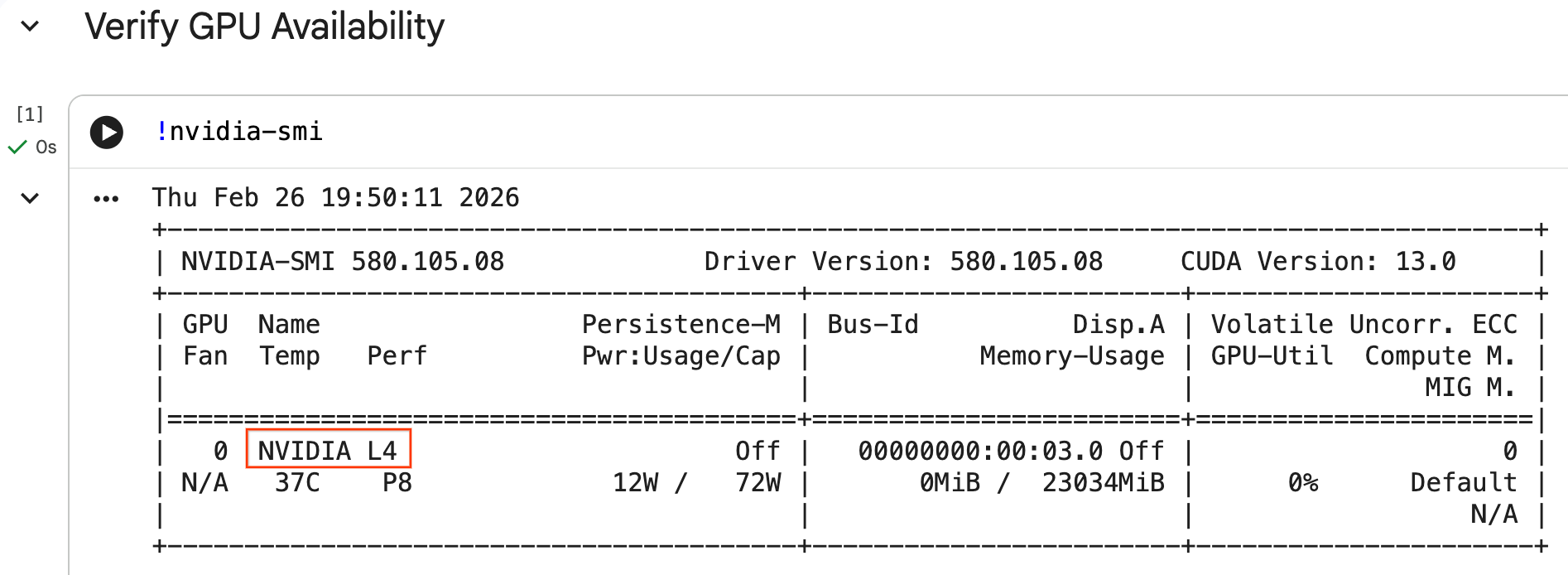
Scarica i dati
Scarica i dati dei viaggi per il 2024.
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
Accelera pandas con NVIDIA cuDF
La libreria pandas viene eseguita sulla CPU e può essere lenta con set di dati di grandi dimensioni. Il comando magico NVIDIA %load_ext cudf.pandas applica patch dinamiche a pandas per utilizzare l'accelerazione GPU, ricorrendo alla CPU se necessario.
Utilizziamo questo comando magico anziché un'importazione standard perché fornisce un'accelerazione "senza modifiche al codice". Non devi riscrivere il codice esistente. Un comando simile, %load_ext cuml.accel, fa esattamente la stessa cosa per scikit-learn models. Questa operazione funziona in qualsiasi ambiente Jupyter con una GPU NVIDIA compatibile, non solo in Colab Enterprise.
%load_ext cudf.pandas
Per verificare che sia attivo, importa pandas e controlla il relativo tipo:
import pandas as pd
pd
L'output confermerà che ora stai utilizzando il modulo cudf.pandas.
Caricare e pulire i dati
Con cudf.pandas attivo, carica i file Parquet ed esegui la pulizia dei dati. Questo processo viene eseguito automaticamente sulla GPU.
import glob
# Load data into memory
df = pd.concat(
[pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
# Filter for valid trips. We filter for payment_type=1 (credit card)
# because tip amounts are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
Feature Engineering
Crea funzionalità derivate dalla data e dall'ora di ritiro. Il blocco note contiene altre funzionalità utilizzate nei passaggi successivi.
import numpy as np
# Time Features
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['is_rush_hour'] = (
((df['hour'] >= 7) & (df['hour'] <= 9)) |
((df['hour'] >= 17) & (df['hour'] <= 19))
).astype(int)
...
# Other features
...
9. Addestra modelli individuali con la convalida incrociata
Per mostrare come la GPU può accelerare il machine learning, addestrerai tre diversi tipi di modelli di regressione per prevedere il tip_amount di una corsa in taxi.
Accelera scikit-learn con NVIDIA cuML
Esegui algoritmi scikit-learn sulla GPU utilizzando cuML di NVIDIA senza modificare le chiamate API. Innanzitutto, carica l'estensione cuml.accel.
%load_ext cuml.accel
Funzionalità e target di configurazione
Identifica le funzionalità da cui vuoi che il modello apprenda e dividi la colonna di destinazione (tip_amount).
feature_cols = [
'trip_distance', 'fare_amount', 'passenger_count',
'hour', 'dow', 'is_weekend', 'is_rush_hour',
'fare_log', 'fare_decimal', 'is_round_fare',
'route_frequency', 'pu_tip_mean', 'pu_tip_std',
'PULocationID', 'DOLocationID'
]
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
Configura le suddivisioni della convalida incrociata per valutare in modo affidabile le prestazioni del modello.
from sklearn.model_selection import KFold
import numpy as np
import time
from sklearn.metrics import mean_squared_error
from tqdm.notebook import tqdm
n_splits = 3
kf = KFold(n_splits=n_splits, shuffle=True, random_state=42)
1. XGBoost
XGBoost è accelerato in modo nativo dalla GPU. Passa tree_method='hist' e device='cuda' per utilizzare la GPU durante l'addestramento.
import xgboost as xgb
start_time = time.perf_counter()
def train_xgb_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# XGBoost handles GPU natively when tree_method='hist' and device='cuda'
model = xgb.XGBRegressor(
objective='reg:squarederror',
max_depth=5,
learning_rate=0.1,
n_estimators=100,
tree_method='hist',
device='cuda',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
xgb_rmse, xgb_preds = train_xgb_cv(X, y)
print(f"\n{'XGBoost RMSE:':<20} ${xgb_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
2. Regressione lineare
Addestra un modello di regressione lineare. Con %load_ext cuml.accel attivo, LinearRegression viene mappato automaticamente alla GPU equivalente.
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
start_time = time.perf_counter()
def train_linreg_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
# Automatically accelerated by cuML
model = LinearRegression()
model.fit(X_train_scaled, y_train)
preds = model.predict(X_val_scaled)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
linreg_rmse, linreg_preds = train_linreg_cv(X, y)
print(f"\n{'Linear Reg RMSE:':<20} ${linreg_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
3. Random Forest
Addestra un modello di ensemble utilizzando RandomForestRegressor. I modelli basati su alberi sono spesso lenti da addestrare sulla CPU, ma l'accelerazione della GPU elabora milioni di righe più velocemente.
from sklearn.ensemble import RandomForestRegressor
start_time = time.perf_counter()
def train_rf_cv(X, y):
rmses = []
preds_all = np.zeros(len(y))
for train_idx, val_idx in tqdm(kf.split(X), total=n_splits):
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# Automatically accelerated by cuML
model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
)
model.fit(X_train, y_train)
preds = model.predict(X_val)
preds_all[val_idx] = preds
rmses.append(np.sqrt(mean_squared_error(y_val, preds)))
return np.mean(rmses), preds_all
rf_rmse, rf_preds = train_rf_cv(X, y)
print(f"\n{'Random Forest RMSE:':<20} ${rf_rmse:.4f}")
print(f"{'Time:':<20} {time.perf_counter() - start_time:.2f} seconds")
10. Valuta la pipeline end-to-end
Combina le previsioni dei tre modelli utilizzando un semplice insieme lineare. In genere, questo approccio offre un leggero miglioramento dell'accuratezza rispetto ai singoli modelli.
Esegui una regressione lineare sulle previsioni per trovare le ponderazioni ottimali:
ensemble_weights = LinearRegression(positive=True, fit_intercept=False).fit(
np.c_[xgb_preds, rf_preds, linreg_preds], y
).coef_
# Normalize weights
ensemble_weights = ensemble_weights / ensemble_weights.sum()
ensemble_preds = np.c_[xgb_preds, rf_preds, linreg_preds] @ ensemble_weights
ensemble_rmse = np.sqrt(mean_squared_error(y, ensemble_preds))
Confronta i risultati per visualizzare l'impatto dell'ensemble:
print(f"\n{'Model':<20} {'RMSE':>10}")
print("-" * 32)
print(f"{'Linear Regression':<20} ${linreg_rmse:>9.4f}")
print(f"{'Random Forest':<20} ${rf_rmse:>9.4f}")
print(f"{'XGBoost':<20} ${xgb_rmse:>9.4f}")
print("-" * 32)
print(f"{'Ensemble':<20} ${ensemble_rmse:>9.4f}")
print(f"\nEnsemble lift: ${xgb_rmse - ensemble_rmse:.4f}")
11. Confrontare le prestazioni della CPU e della GPU
Per confrontare correttamente la differenza di rendimento, riavvia il kernel per garantire uno stato di esecuzione pulito, esegui l'intera pipeline di data science sulla CPU e poi di nuovo sulla GPU.
Riavvia il kernel
Esegui il comando IPython.Application.instance().kernel.do_shutdown(True) per riavviare il kernel e liberare la memoria.
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
Definisci la pipeline di data science
Racchiudi il flusso di lavoro principale (caricamento dei dati, pulizia, feature engineering e addestramento del modello) in un'unica funzione. Questa funzione accetta un modulo pandas pd_module e un argomento use_gpu per passare da un ambiente all'altro.
def run_ml_pipeline(pd_module, use_gpu=False):
import time
import glob
import numpy as np
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
timings = {}
# 1. Load Data
t0 = time.perf_counter()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")],
ignore_index=True
)
timings['Load Data'] = time.perf_counter() - t0
# 2. Clean Data
t0 = time.perf_counter()
# Filter for payment_type=1 (credit card) because tip amounts
# are only reliably recorded for credit card transactions.
df = df[
(df['fare_amount'] > 0) & (df['fare_amount'] < 500) &
(df['trip_distance'] > 0) & (df['trip_distance'] < 100) &
(df['tip_amount'] >= 0) & (df['tip_amount'] < 100) &
(df['payment_type'] == 1)
].copy()
# Downcast numeric columns to save memory
float_cols = df.select_dtypes(include=['float64']).columns
df[float_cols] = df[float_cols].astype('float32')
int_cols = df.select_dtypes(include=['int64']).columns
df[int_cols] = df[int_cols].astype('int32')
timings['Clean Data'] = time.perf_counter() - t0
# 3. Feature Engineering
t0 = time.perf_counter()
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['dow'] = df['tpep_pickup_datetime'].dt.dayofweek
df['is_weekend'] = (df['dow'] >= 5).astype(int)
df['fare_log'] = np.log1p(df['fare_amount'])
timings['Feature Engineering'] = time.perf_counter() - t0
# 4. Modeling Prep
feature_cols = ['trip_distance', 'fare_amount', 'passenger_count', 'hour', 'dow', 'is_weekend', 'fare_log']
X = df[feature_cols].fillna(df[feature_cols].median())
y = df['tip_amount'].copy()
# Free memory
del df
import gc
gc.collect()
# 5. Train Random Forest
t0 = time.perf_counter()
rf_model = RandomForestRegressor(
n_estimators=100,
max_depth=10,
n_jobs=-1,
max_features='sqrt',
random_state=42
).fit(X, y)
timings['Train Random Forest'] = time.perf_counter() - t0
# 6. Train XGBoost
t0 = time.perf_counter()
params = {
'objective': 'reg:squarederror',
'max_depth': 5,
'n_estimators': 100,
'random_state': 42
}
if use_gpu:
params['device'] = 'cuda'
params['tree_method'] = 'hist'
xgb_model = xgb.XGBRegressor(**params).fit(X, y)
timings['Train XGBoost'] = time.perf_counter() - t0
del X
del y
gc.collect()
return timings
Esegui sulla CPU
Chiama la pipeline utilizzando la CPU standard pandas.
import pandas as pd
print("Running pipeline on CPU...")
cpu_times = run_ml_pipeline(pd, use_gpu=False)
print("CPU Execution Finished.")
Esegui sulla GPU
Carica le estensioni della libreria NVIDIA, passa il modulo cudf.pandas accelerato alla pipeline e imposta internamente il dispositivo XGBoost su cuda.
import IPython.core.magic
if not hasattr(IPython.core.magic, 'output_can_be_silenced'):
IPython.core.magic.output_can_be_silenced = lambda x: x
%load_ext cudf.pandas
%load_ext cuml.accel
import pandas as pd
print("Running pipeline on GPU...")
gpu_times = run_ml_pipeline(pd, use_gpu=True)
print("GPU Execution Finished.")
Visualizzare l'accelerazione delle prestazioni
Visualizza i tempi utilizzando matplotlib. I risultati mostrano il tempo risparmiato durante l'elaborazione dei dati e l'addestramento del modello quando si utilizzano le GPU.
import matplotlib.pyplot as plt
import numpy as np
labels = list(cpu_times.keys())
cpu_values = list(cpu_times.values())
gpu_values = list(gpu_times.values())
x = np.arange(len(labels))
width = 0.35
fig, ax = plt.subplots(figsize=(10, 6))
rects1 = ax.bar(x - width/2, cpu_values, width, label='CPU', color='#4285F4')
rects2 = ax.bar(x + width/2, gpu_values, width, label='GPU', color='#76B900')
ax.set_ylabel('Execution Time (seconds)')
ax.set_title('NYC Taxi ML Pipeline: CPU vs. GPU Performance')
ax.set_xticks(x)
ax.set_xticklabels(labels, rotation=45, ha="right")
ax.legend()
# Add data labels
def autolabel(rects):
for rect in rects:
height = rect.get_height()
ax.annotate(f'{height:.2f}s',
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom', fontsize=9)
autolabel(rects1)
autolabel(rects2)
plt.tight_layout()
plt.show()
# Calculate overall speedup
total_cpu_time = sum(cpu_values)
total_gpu_time = sum(gpu_values)
overall_speedup = total_cpu_time / total_gpu_time
print(f"\nOverall Pipeline Speedup: {overall_speedup:.2f}x faster on GPU!")
Dovresti vedere qualcosa di simile a questo:

Questo grafico illustra il significativo vantaggio in termini di prestazioni della GPU nell'intero flusso di lavoro di data science. I risparmi di tempo più significativi si verificano durante le fasi di addestramento del modello a elevato consumo di risorse di calcolo per algoritmi come Random Forest e XGBoost.
12. Esegui la profilazione del codice per trovare i vincoli di rendimento
Quando utilizzi cudf.pandas, la maggior parte delle funzioni viene eseguita sulla GPU. Se una specifica operazione non è ancora supportata da cuDF, l'esecuzione viene temporaneamente eseguita sulla CPU. NVIDIA fornisce due comandi magici Jupyter integrati per identificare questi fallback.
Profilazione di alto livello con %%cudf.pandas.profile
Il comando magico %%cudf.pandas.profile fornisce un riepilogo delle funzioni eseguite sulla GPU o sulla CPU.
%%cudf.pandas.profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
summary = (
df
.groupby(['PULocationID', 'payment_type'])
[['passenger_count', 'fare_amount', 'tip_amount']]
.agg(['min', 'mean', 'max'])
)

Profilazione riga per riga con %%cudf.pandas.line_profile
Per una risoluzione dei problemi granulare, %%cudf.pandas.line_profile annota ogni riga di codice con il numero di volte in cui è stata eseguita sulla GPU rispetto alla CPU.
%%cudf.pandas.line_profile
import glob
import pandas as pd
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*-01.parquet")], ignore_index=True)
df = df.sample(1_000)
# Iterating row-by-row or using custom python apply functions often falls back to the CPU
def categorize_hour(hour):
if hour < 12:
return 'Morning'
else:
return 'Afternoon/Evening'
df['hour'] = df['tpep_pickup_datetime'].dt.hour
df['time_of_day_slow'] = df['hour'].apply(categorize_hour)
# Using vectorized pandas operations (like pd.cut) stays entirely on the GPU
cut_bins = [-1, 11, 24]
cut_labels = ['Morning', 'Afternoon/Evening']
df['time_of_day_fast'] = pd.cut(df['hour'], bins=cut_bins, labels=cut_labels)

13. Esegui la pulizia
Per evitare addebiti imprevisti sul tuo account Google Cloud, pulisci le risorse che hai creato durante questo codelab.
Elimina risorse
Elimina il set di dati locale sul runtime utilizzando il comando !rm -rf in una cella del notebook.
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Arrestare il runtime di Colab
- Nella console Google Cloud, vai alla pagina Runtime di Colab Enterprise.
- Nel menu Regione, seleziona la regione che contiene il runtime.
- Seleziona il runtime che vuoi eliminare.
- Fai clic su Elimina.
- Fai clic su Conferma.
Eliminare il notebook
- Nella console Google Cloud, vai alla pagina I miei blocchi note di Colab Enterprise.
- Nel menu Regione, seleziona la regione che contiene il notebook.
- Seleziona il blocco note da eliminare.
- Fai clic su Elimina.
- Fai clic su Conferma.
14. Complimenti
Complimenti! Hai accelerato correttamente un flusso di lavoro di machine learning pandas e scikit-learn utilizzando le librerie NVIDIA cuDF e cuML su Colab Enterprise. Aggiungendo semplicemente alcuni comandi magici (%load_ext cudf.pandas e %load_ext cuml.accel), il codice standard viene eseguito sulla GPU, elaborando i record e adattando modelli complessi in locale in una frazione del tempo.
Per saperne di più sull'accelerazione GPU per l'analisi dei dati, consulta il codelab Accelerated Data Analytics with GPUs.
Argomenti trattati
- Informazioni su Colab Enterprise su Google Cloud.
- Personalizzazione di un ambiente di runtime Colab con configurazioni specifiche di GPU e memoria.
- Applicazione dell'accelerazione GPU per prevedere gli importi delle mance utilizzando milioni di record di un set di dati sui taxi di New York.
- Accelerazione di
pandassenza modifiche al codice utilizzando la libreriacuDFdi NVIDIA. - Accelerazione di
scikit-learnsenza modifiche al codice utilizzando la libreriacuMLe le GPU di NVIDIA. - Profilare il codice per identificare e ottimizzare i vincoli di rendimento.