
1. Введение
В этом практическом занятии вы узнаете, как ускорить рабочие процессы анализа данных на больших наборах данных, используя графические процессоры NVIDIA и библиотеки с открытым исходным кодом в Google Cloud. Вы начнете с оптимизации своей инфраструктуры, а затем изучите, как применить ускорение с помощью графических процессоров без каких-либо изменений в коде.
Вы сосредоточитесь на pandas , популярной библиотеке для обработки данных, и узнаете, как ускорить её работу с помощью библиотеки NVIDIA cuDF . Самое приятное то, что вы можете получить это ускорение на графическом процессоре, не изменяя существующий код pandas .
Что вы узнаете
- Разберитесь с Colab Enterprise в Google Cloud.
- Настройте среду выполнения Colab, указав конкретные параметры графического процессора, центрального процессора и памяти.
- Ускорьте работу
pandasбез изменений в коде, используя NVIDIAcuDF. - Проанализируйте свой код, чтобы выявить и оптимизировать узкие места в производительности.
2. Зачем ускорять обработку данных?
Правило 80/20: почему подготовка данных отнимает так много времени
Подготовка данных часто является самым трудоемким этапом аналитического проекта. Специалисты по анализу данных и аналитики тратят значительную часть своего времени на очистку, преобразование и структурирование данных, прежде чем можно будет приступить к анализу.
К счастью, популярные библиотеки с открытым исходным кодом, такие как pandas, Apache Spark и Polar, можно ускорить на графических процессорах NVIDIA с помощью cuDF . Даже с этим ускорением подготовка данных остается трудоемкой, потому что:
- Исходные данные редко бывают готовы к анализу: реальные данные часто содержат несоответствия, пропущенные значения и проблемы с форматированием.
- Качество данных влияет на производительность модели: низкое качество данных может сделать бесполезными даже самые сложные алгоритмы.
- Масштаб усугубляет проблемы: казалось бы, незначительные проблемы с данными становятся критическими узкими местами при работе с миллионами записей.
3. Выбор среды для ноутбука
Хотя многие специалисты по анализу данных знакомы с Colab по личным проектам, Colab Enterprise предоставляет безопасную, совместную и интегрированную среду для работы с блокнотами, разработанную для бизнеса.
В Google Cloud у вас есть два основных варианта управляемых сред для ноутбуков: Colab Enterprise и Vertex AI Workbench . Правильный выбор зависит от приоритетов вашего проекта.
Когда использовать Vertex AI Workbench
Выбирайте Vertex AI Workbench, если для вас приоритетны контроль и широкая возможность настройки . Это идеальный выбор, если вам необходимо:
- Управление базовой инфраструктурой и жизненным циклом оборудования.
- Используйте пользовательские контейнеры и сетевые конфигурации.
- Интеграция с конвейерами MLOps и пользовательскими инструментами управления жизненным циклом.
Когда использовать Colab Enterprise
Выбирайте Colab Enterprise, если для вас приоритетны быстрая настройка, простота использования и безопасная совместная работа . Это полностью управляемое решение, позволяющее вашей команде сосредоточиться на анализе, а не на инфраструктуре. Colab Enterprise поможет вам:
- Разрабатывайте рабочие процессы обработки данных, тесно связанные с вашим хранилищем данных. Вы можете открывать и управлять своими блокнотами непосредственно в BigQuery Studio .
- Обучайте модели машинного обучения и интегрируйте их с инструментами MLOps в Vertex AI.
- Наслаждайтесь гибким и унифицированным интерфейсом. Блокнот Colab Enterprise, созданный в BigQuery, можно открыть и запустить в Vertex AI, и наоборот.
Сегодняшняя лабораторная работа
В этом практическом занятии используется Colab Enterprise для ускоренного анализа данных.
Чтобы узнать больше о различиях, ознакомьтесь с официальной документацией по выбору подходящего ноутбука .
4. Настройте шаблон среды выполнения.
В Colab Enterprise подключитесь к среде выполнения , основанной на предварительно настроенном шаблоне среды выполнения .
Шаблон среды выполнения — это многократно используемая конфигурация, определяющая всю среду для вашего ноутбука, включая:
- Тип машины (процессор, память)
- Ускоритель (тип и количество графических процессоров)
- Размер и тип диска
- Настройки сети и политики безопасности
- Правила автоматического отключения в режиме ожидания
Почему шаблоны времени выполнения полезны
- Обеспечьте себе стабильную рабочую среду: вы и ваши коллеги всегда получаете одинаковую, готовую к использованию среду, что гарантирует повторяемость вашей работы.
- Безопасность гарантирована с самого начала: шаблоны автоматически обеспечивают соблюдение политик безопасности вашей организации.
- Эффективное управление затратами: такие ресурсы, как графические процессоры и центральные процессоры, уже заложены в шаблон, что помогает предотвратить случайные перерасходы.
Create a runtime template
Создайте многоразовый шаблон среды выполнения для лабораторной работы.
- В консоли Google Cloud перейдите в меню навигации > Vertex AI > Colab Enterprise .
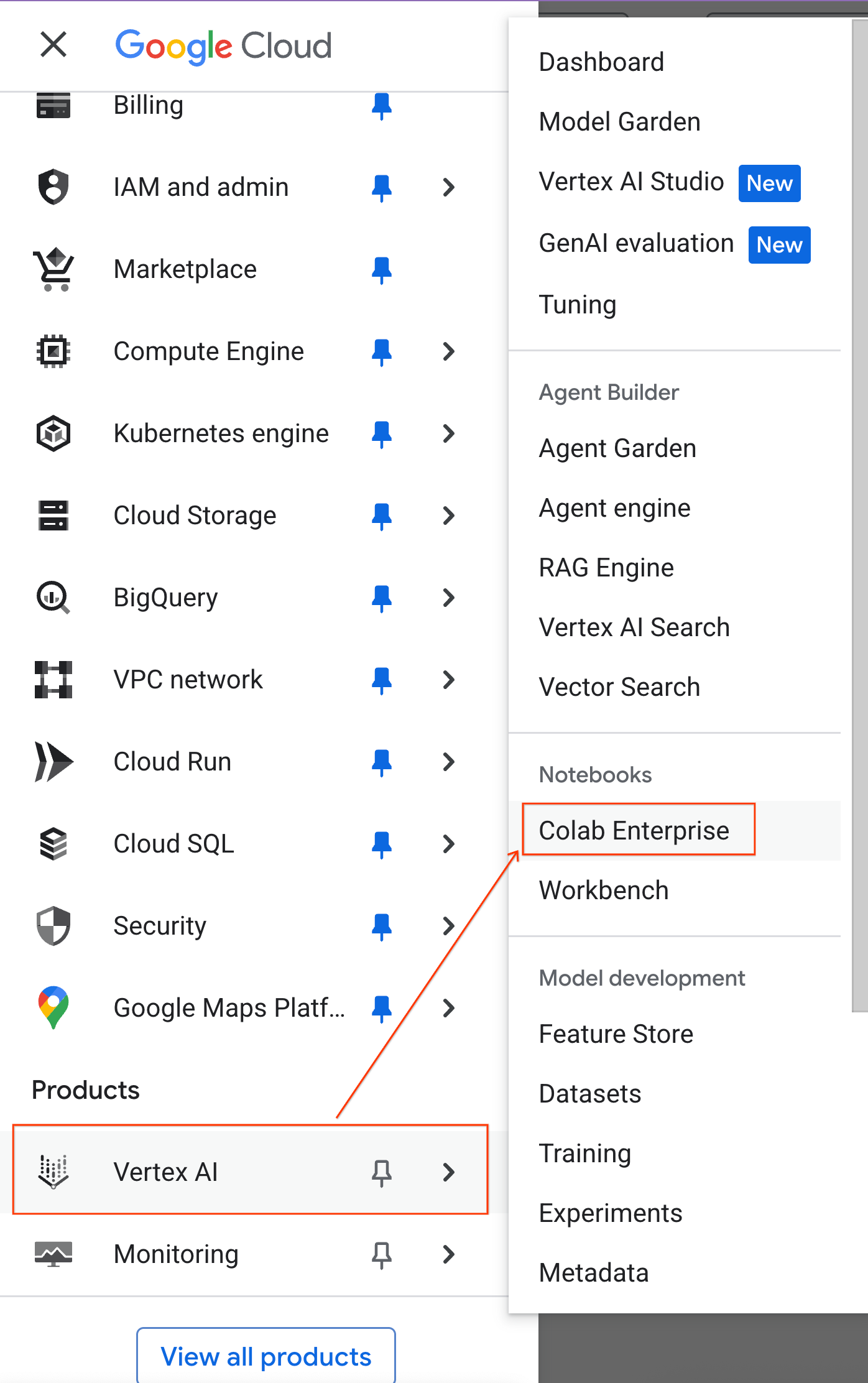
- В Colab Enterprise щелкните «Шаблоны среды выполнения» , а затем выберите «Создать шаблон» .

- В разделе «Основы работы среды выполнения» :
- Установите отображаемое имя как
gpu-template. - Укажите предпочитаемый регион .
- Установите отображаемое имя как

- В разделе «Настройка вычислительных ресурсов» :
- Установите тип станка на
g2-standard-4. - Оставьте тип ускорителя по умолчанию как
NVIDIA L4с количеством ускорителей , равным 1. - Измените время отключения в режиме ожидания на 60 минут.
- Нажмите «Продолжить» .
- Установите тип станка на

- В разделе «Окружающая среда» :
- Установите среду выполнения на
Python 3.11
- Установите среду выполнения на

- Нажмите «Создать» , чтобы сохранить шаблон среды выполнения. На странице «Шаблоны среды выполнения» должен отобразиться новый шаблон.
5. Запустите среду выполнения.
Имея готовый шаблон, вы можете создать новую среду выполнения.
- В Colab Enterprise щелкните Runtimes , а затем выберите Create .
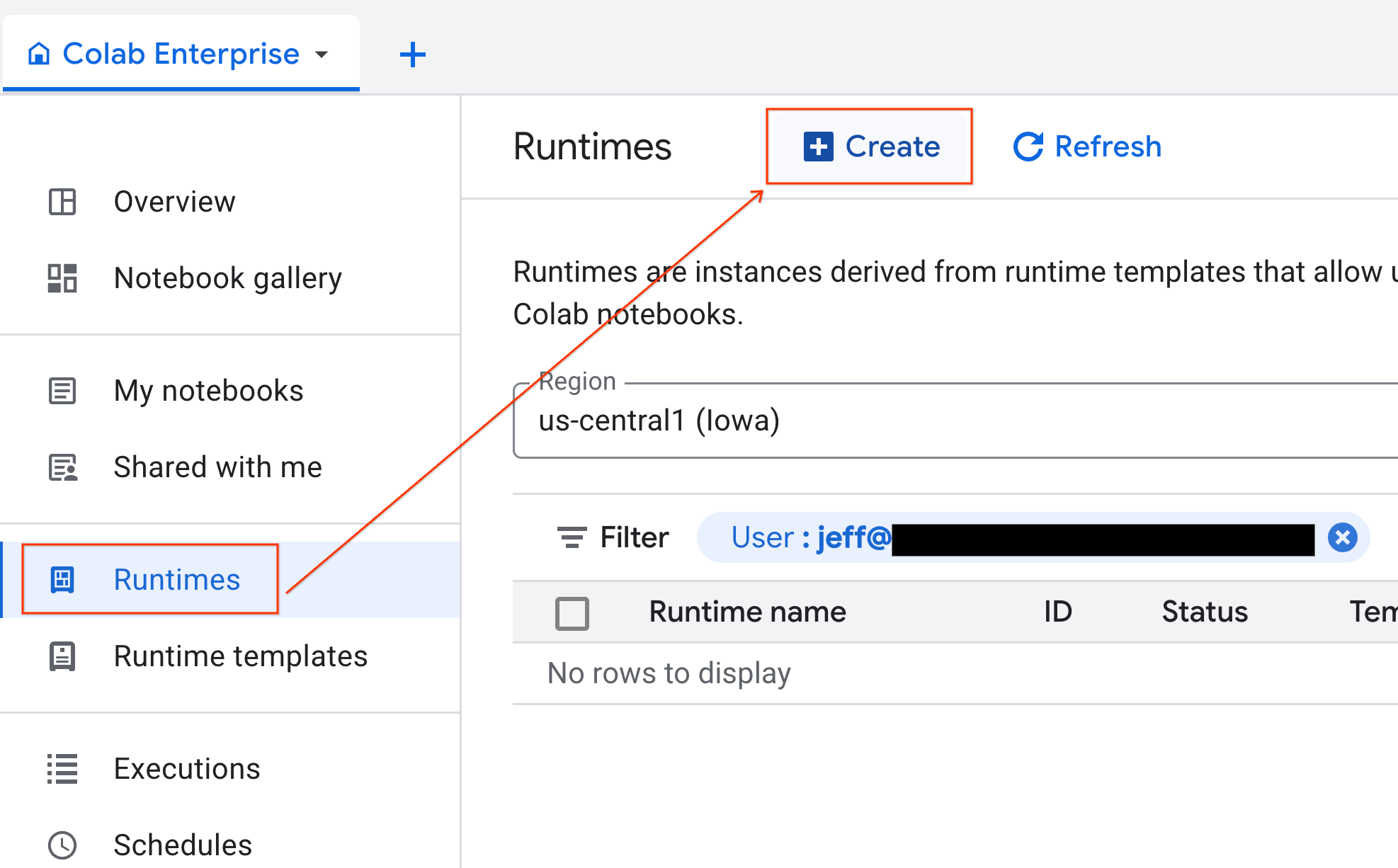
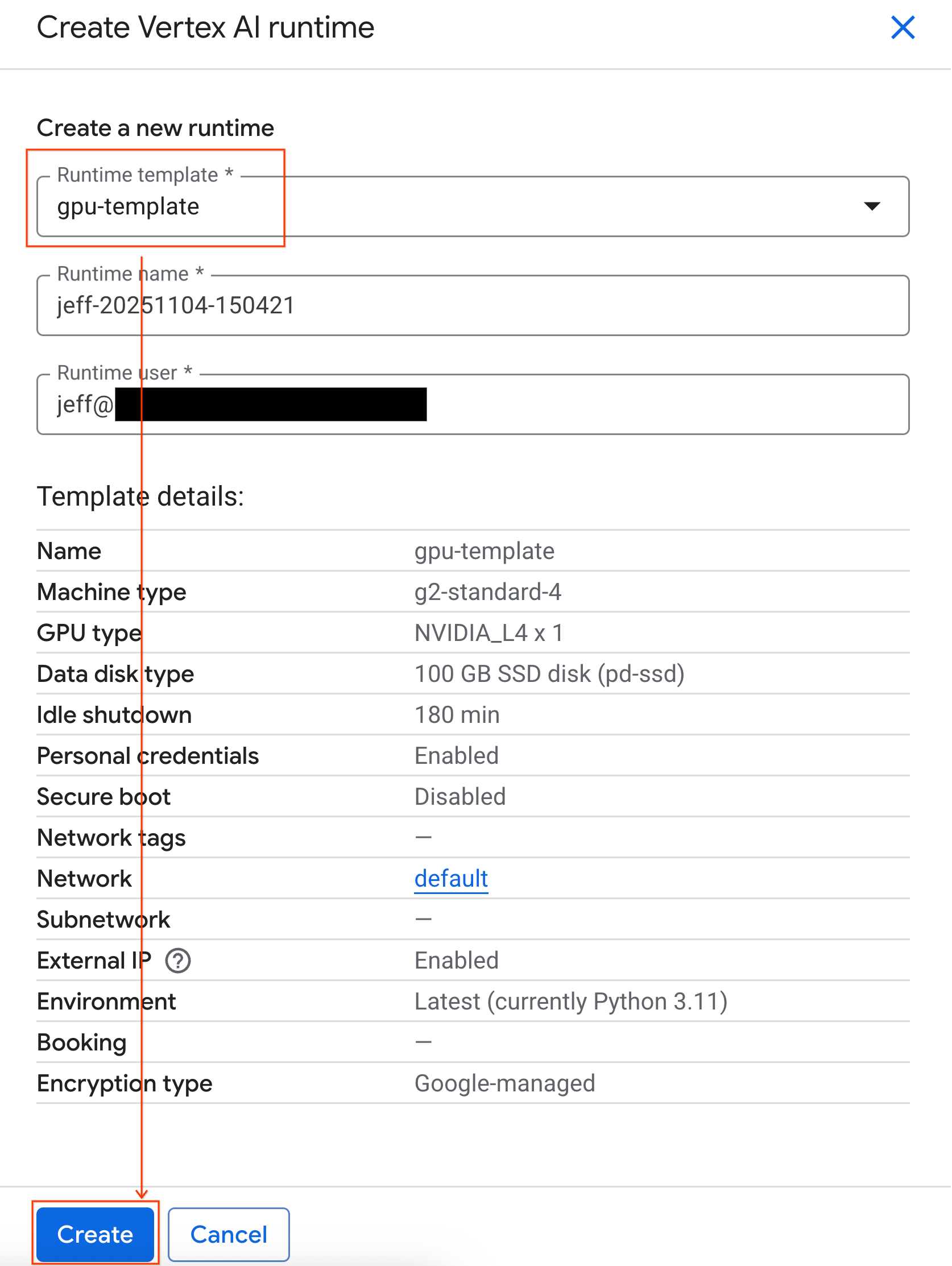
- В разделе «Шаблон среды выполнения» выберите параметр
gpu-template. Нажмите «Создать» и дождитесь загрузки среды выполнения.
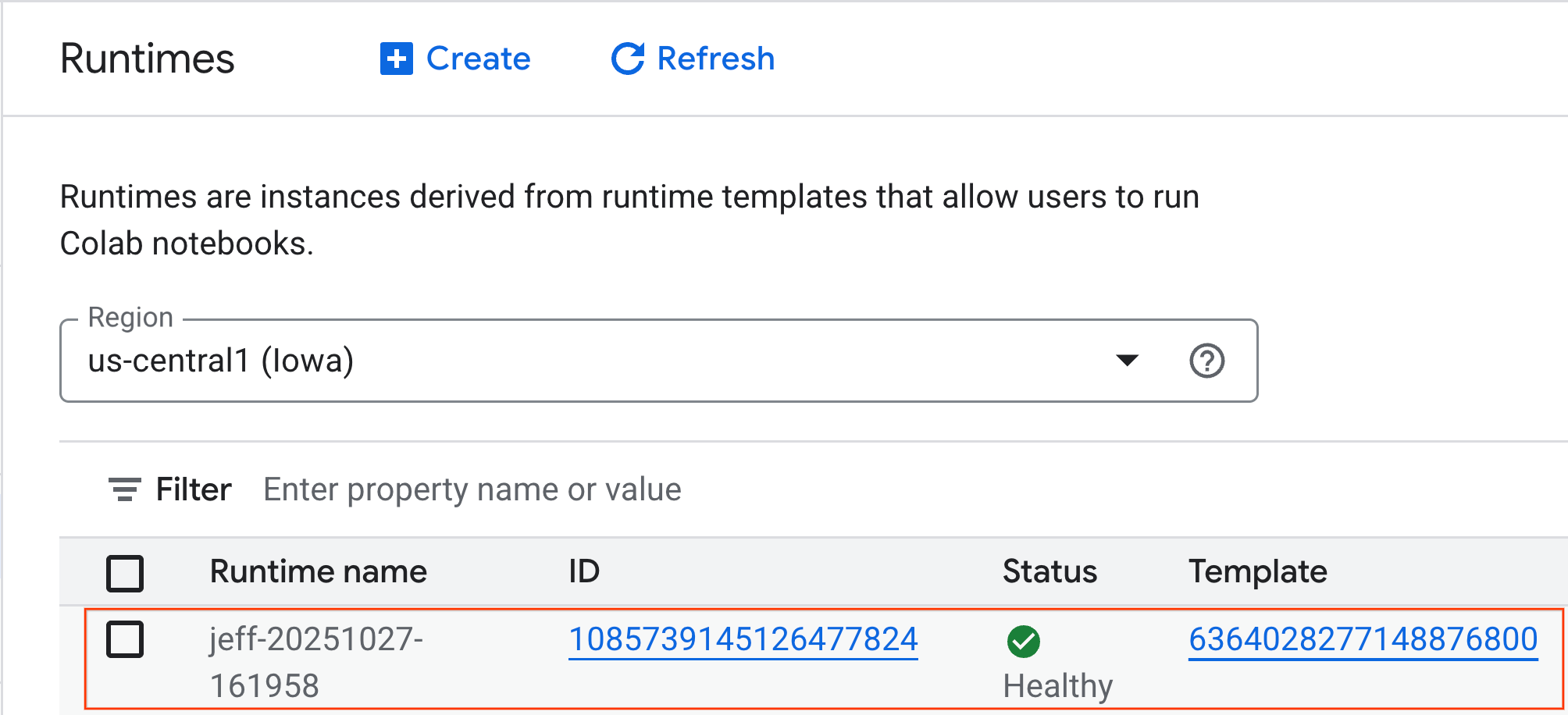
- Через несколько минут вы увидите доступное время выполнения.
6. Подготовьте ноутбук.
Теперь, когда ваша инфраструктура запущена, вам необходимо импортировать лабораторный блокнот и подключить его к вашей среде выполнения.
Импортируйте блокнот
- В Colab Enterprise щелкните «Мои блокноты» , а затем — «Импорт» .

- Выберите переключатель «URL» и введите следующий URL-адрес:
https://github.com/GoogleCloudPlatform/ai-ml-recipes/blob/main/notebooks/analytics/gpu_accelerated_analytics.ipynb
- Нажмите «Импорт» . Colab Enterprise скопирует блокнот из GitHub в вашу среду.

Подключитесь к среде выполнения
- Откройте только что импортированный блокнот.
- Нажмите стрелку вниз рядом с кнопкой «Подключиться» .
- Выберите «Подключиться к среде выполнения» .

- Воспользуйтесь выпадающим списком и выберите ранее созданную среду выполнения.
- Нажмите «Подключиться» .

Your notebook is now connected to a GPU-enabled runtime. Now you can begin running queries!
7. Подготовьте набор данных о такси в Нью-Йорке.
В этом практическом занятии используются данные о поездках, предоставленные Комиссией по такси и лимузинам Нью-Йорка (TLC) .
Набор данных содержит записи об отдельных поездках желтых такси в Нью-Йорке и включает такие поля, как:
- Даты, время и места получения и возврата.
- Расстояния поездок
- Суммы проезда, указанные по пунктам
- Количество пассажиров
Скачать данные
Далее загрузите данные о поездках за весь 2024 год. Данные хранятся в формате Parquet.
Следующий блок кода выполняет следующие шаги:
- Определяет диапазон лет и месяцев для загрузки.
- Создает локальную директорию с именем
nyc_taxi_dataдля хранения файлов. - Программа проходит циклом по каждому месяцу, загружает соответствующий файл Parquet, если он еще не существует, и сохраняет его в указанную директорию.
Запустите этот код в своем ноутбуке, чтобы собрать данные и сохранить их во время выполнения:
from tqdm import tqdm
import requests
import time
import os
YEAR = 2024
DATA_DIR = "nyc_taxi_data"
os.makedirs(DATA_DIR, exist_ok=True)
print(f"Checking/Downloading files for {YEAR}...")
for month in tqdm(range(1, 13), unit="file"):
# Define standardized filename for both local path and URL
file_name = f"yellow_tripdata_{YEAR}-{month:02d}.parquet"
local_path = os.path.join(DATA_DIR, file_name)
url = f"https://d37ci6vzurychx.cloudfront.net/trip-data/{file_name}"
if not os.path.exists(local_path):
try:
with requests.get(url, stream=True) as response:
response.raise_for_status()
with open(local_path, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
time.sleep(1)
except requests.exceptions.HTTPError as e:
print(f"\nSkipping {file_name}: {e}")
if os.path.exists(local_path):
os.remove(local_path)
print("\nDownload complete.")
8. Изучите данные о поездках на такси.
Теперь, когда вы загрузили набор данных, пришло время провести первоначальный разведочный анализ данных (EDA). Цель EDA — понять структуру данных, выявить аномалии и обнаружить потенциальные закономерности.
Загрузите данные за один месяц.
Для начала загрузите данные за один месяц. Это обеспечит достаточно большую выборку (более 3 миллионов строк), чтобы результаты были информативными, при этом сохраняя приемлемый уровень использования памяти для интерактивного анализа.
import pandas as pd
import glob
# Load the last month of the downloaded data
df = pd.read_parquet("nyc_taxi_data/yellow_tripdata_2024-12.parquet")
df.head()
Получить сводную статистику
Используйте метод .describe() для генерации сводной статистики высокого уровня для числовых столбцов. Это отличный первый шаг для выявления потенциальных проблем с качеством данных, таких как неожиданные минимальные или максимальные значения.
df.describe().round(2)

Проверьте качество данных.
Результат выполнения функции .describe() сразу же выявляет проблему. Обратите внимание, что min значение для tpep_pickup_datetime и tpep_dropoff_datetime находится в 2008 году, что не имеет смысла для набора данных 2024 года.
Это пример того, почему всегда следует проверять свои данные. Вы можете провести дальнейшее исследование, отсортировав DataFrame, чтобы найти именно те строки, которые содержат эти аномальные даты.
# Sort by the dropoff datetime to see the oldest records
df.sort_values("tpep_pickup_datetime").head()
Визуализация распределения данных
Далее вы можете создать гистограммы числовых столбцов, чтобы визуализировать их распределение. Это поможет вам понять разброс и асимметрию таких параметров, как trip_distance и fare_amount . Функция .hist() — это быстрый способ построить гистограммы для всех числовых столбцов в DataFrame.
_ = df.hist(figsize=(20, 20))
Наконец, создайте матрицу рассеяния для визуализации взаимосвязей между несколькими ключевыми столбцами. Поскольку построение графика из миллионов точек занимает много времени и может скрывать закономерности, используйте .sample() для создания графика из случайной выборки из 100 000 строк.
_ = pd.plotting.scatter_matrix(
df[['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']].sample(100_000),
diagonal="kde",
figsize=(15, 15)
)
9. Почему следует использовать формат файлов Parquet?
Набор данных о нью-йоркских такси предоставлен в формате Apache Parquet . Это преднамеренный выбор, сделанный для крупномасштабного анализа. Parquet имеет ряд преимуществ перед такими типами файлов, как CSV:
- Эффективность и скорость: будучи столбцовым форматом, Parquet очень эффективен для хранения и чтения. Он поддерживает современные методы сжатия, которые приводят к уменьшению размера файлов и значительному ускорению ввода-вывода, особенно на графических процессорах.
- Сохраняет схему: Parquet хранит типы данных в метаданных файла. Вам никогда не придется гадать о типах данных при чтении файла.
- Обеспечивает выборочное чтение: столбцовая структура позволяет считывать только необходимые для анализа столбцы. Это может значительно сократить объем данных, загружаемых в память.
Ознакомьтесь с характеристиками паркета.
Давайте рассмотрим две из этих мощных функций, используя один из загруженных вами файлов.
Просмотрите метаданные, не загружая весь набор данных.
Хотя вы не можете просмотреть файл Parquet в стандартном текстовом редакторе, вы можете легко изучить его схему и метаданные, не загружая данные в память. Это полезно для быстрого понимания структуры файла.
from pyarrow.parquet import ParquetFile
import pyarrow as pa
# Open one of the downloaded files
pf = ParquetFile('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
# Print the schema
print("File Schema:")
print(pf.schema)
# Print the file metadata
print("\nFile Metadata:")
print(pf.metadata)
Читайте только необходимые столбцы.
Представьте, что вам нужно проанализировать только расстояние поездки и стоимость проезда. С помощью Parquet вы можете загрузить только эти столбцы, что намного быстрее и эффективнее с точки зрения использования памяти, чем загрузка всего DataFrame целиком.
import pandas as pd
# Read only four specific columns from the Parquet file
df_subset = pd.read_parquet(
'nyc_taxi_data/yellow_tripdata_2024-12.parquet',
columns=['passenger_count', 'trip_distance', 'tip_amount', 'total_amount']
)
df_subset.head()
10. Ускорьте работу pandas с помощью NVIDIA cuDF
NVIDIA CUDA for DataFrames (cuDF) — это библиотека с открытым исходным кодом, ускоряемая на графическом процессоре, которая позволяет взаимодействовать с DataFrames. cuDF позволяет выполнять распространенные операции с данными, такие как фильтрация, объединение и группировка, на графическом процессоре с высокой степенью параллелизма.
Ключевой особенностью этого практического занятия является режим ускорения cudf.pandas . При его включении ваш стандартный код pandas автоматически перенаправляется на использование ядер cuDF , работающих на графическом процессоре, без необходимости внесения изменений в ваш код.
Включить ускорение графического процессора
To use NVIDIA cuDF in a Colab Enterprise notebook, you load its magic extension before you import pandas .
Сначала проверьте стандартную библиотеку pandas . Обратите внимание, что в выводе указан путь к стандартной установке pandas .
import pandas as pd
pd # Note the output for the standard pandas library
Теперь загрузите расширение cudf.pandas и снова импортируйте pandas . Посмотрите, как изменится вывод модуля pd — это подтверждает, что теперь активна версия с ускорением на графическом процессоре.
%load_ext cudf.pandas
import pandas as pd
pd # Note the new output, indicating cudf.pandas is active
Другие способы включения cudf.pandas
Хотя магическая команда ( %load_ext ) является самым простым способом в ноутбуке, вы также можете включить акселератор в других средах:
- В скриптах Python: вызовите функции
import cudf.pandasиcudf.pandas.install()перед импортомpandas. - В средах, отличных от ноутбуков: запустите свой скрипт с помощью
python -m cudf.pandas your_script.py.
11. Сравните производительность ЦП и ГП.
Теперь перейдём к самой важной части: сравнению производительности стандартной pandas на центральном процессоре с производительностью cudf.pandas на графическом процессоре.
Для обеспечения абсолютно корректной базовой производительности ЦП необходимо сначала перезапустить среду выполнения Colab. Это удалит все графические ускорители, которые вы могли включить в предыдущих разделах. Вы можете перезапустить среду выполнения, выполнив следующую ячейку или выбрав «Перезапустить сессию» в меню «Среда выполнения» .
import IPython
IPython.Application.instance().kernel.do_shutdown(True)
Определите конвейер аналитики.
Теперь, когда среда очищена, вам нужно определить функцию бенчмаркинга. Эта функция позволяет запускать один и тот же конвейер — загрузку, сортировку и суммирование — используя любой модуль pandas , который вы ей передадите.
import time
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def run_analytics_pipeline(pd_module):
"""Loads, sorts, and summarizes data using the provided pandas module."""
timings = {}
# 1. Load all 2024 Parquet files from the directory
t0 = time.time()
df = pd_module.concat(
[pd_module.read_parquet(f) for f in glob.glob("nyc_taxi_data/*_2024*.parquet")],
ignore_index=True
)
timings["load"] = time.time() - t0
# 2. Sort the data by multiple columns
t0 = time.time()
df = df.sort_values(
['tpep_pickup_datetime', 'trip_distance', 'passenger_count'],
ascending=[False, True, False]
)
timings["sort"] = time.time() - t0
# 3. Perform a groupby and aggregation
t0 = time.time()
df['tpep_pickup_datetime'] = pd_module.to_datetime(df['tpep_pickup_datetime'])
_ = (
df.loc[df.tpep_pickup_datetime > '2024-11-01']
.groupby(['VendorID', 'tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)
timings["summarize"] = time.time() - t0
return timings
Проведите сравнение
Сначала запустите конвейер, используя стандартную pandas на центральном процессоре. Затем включите cudf.pandas и запустите его снова на графическом процессоре.
# --- Run on CPU ---
print("Running analytics pipeline on CPU...")
# Ensure we are using standard pandas
import pandas as pd
assert "cudf" not in str(pd), "Error: cuDF is still active. Please restart the kernel."
cpu_times = run_analytics_pipeline(pd)
print(f"CPU times: {cpu_times}")
# --- Run on GPU ---
print("\nEnabling cudf.pandas and running on GPU...")
# Load the extension
%load_ext cudf.pandas
import pandas as gpu_pd
gpu_times = run_analytics_pipeline(gpu_pd)
print(f"GPU times: {gpu_times}")
Визуализируйте результаты
Наконец, визуализируйте разницу. Следующий код вычисляет ускорение для каждой операции и отображает их рядом.
# Create a DataFrame for plotting
results_df = pd.DataFrame([cpu_times, gpu_times], index=["CPU", "GPU"]).T
total_cpu_time = results_df['CPU'].sum()
total_gpu_time = results_df['GPU'].sum()
speedup = total_cpu_time / total_gpu_time
print("--- Performance Results ---")
print(results_df)
print(f"\nTotal CPU Time: {total_cpu_time:.2f} seconds")
print(f"Total GPU Time: {total_gpu_time:.2f} seconds")
print(f"Overall Speedup: {speedup:.2f}x")
# Plot the results
fig, ax = plt.subplots(figsize=(10, 6))
results_df.plot(kind='bar', ax=ax, color={"CPU": "tab:blue", "GPU": "tab:green"})
ax.set_ylabel("Time (seconds)")
ax.set_title(f"CPU vs. GPU Runtimes (Overall Speedup: {speedup:.2f}x)", fontsize=14)
ax.tick_params(axis='x', rotation=0)
# Add numerical labels to the bars
for container in ax.containers:
ax.bar_label(container, fmt="%.2f", padding=3)
plt.tight_layout()
plt.show()
Пример результатов:

Графический процессор обеспечивает заметное увеличение скорости по сравнению с центральным процессором.
12. Проанализируйте свой код, чтобы выявить узкие места.
Даже при использовании графического ускорения некоторые операции pandas могут переключаться на центральный процессор, если они еще не поддерживаются cuDF . Такие «переключения на ЦП» могут стать узкими местами в производительности.
Чтобы помочь вам определить эти области, cudf.pandas включает два встроенных профилировщика. Вы можете использовать их, чтобы точно увидеть, какие части вашего кода выполняются на графическом процессоре, а какие переключаются на центральный процессор.
-
%%cudf.pandas.profile: Используйте это для получения общего, пофункционального описания вашего кода. Лучше всего подходит для быстрого обзора того, какие операции выполняются на каком устройстве. -
%%cudf.pandas.line_profile: Используйте этот параметр для детального построчного анализа. Это лучший инструмент для точного определения строк в вашем коде, которые вызывают переключение на процессор.
Используйте эти инструменты для создания профилей в качестве "магических команд" в верхней части ячейки блокнота.
Профилирование на уровне функций с помощью %%cudf.pandas.profile
Сначала запустите профилировщик на уровне функций в том же аналитическом конвейере, что и в предыдущем разделе. В результате будет показана таблица со всеми вызванными функциями, устройством, на котором они выполнялись (GPU или CPU), и количеством вызовов.
%load_ext cudf.pandas
import pandas as pd
import glob
pd.DataFrame({"a": [1]})
Убедившись, что cudf.pandas активен, вы можете запустить профилирование.
%%cudf.pandas.profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)

Построчное профилирование с помощью %%cudf.pandas.line_profile
Далее запустите профилировщик на уровне строк кода. Это даст вам гораздо более детальное представление, показывающее долю времени, которое каждая строка кода тратит на выполнение на графическом процессоре по сравнению с центральным процессором. Это наиболее эффективный способ выявить конкретные узкие места для оптимизации.
%%cudf.pandas.line_profile
df = pd.concat([pd.read_parquet(f) for f in glob.glob("nyc_taxi_data/*2024*.parquet")], ignore_index=True)
df = df.sort_values(['tpep_pickup_datetime', 'trip_distance', 'passenger_count'], ascending=[False, True, False])
summary = (
df
.loc[(df.tpep_pickup_datetime > '2024-11-01')]
.groupby(['VendorID','tpep_pickup_datetime'])
[['passenger_count', 'fare_amount']]
.agg(['min', 'mean', 'max'])
)

Профилирование из командной строки
Эти профилировщики также доступны из командной строки, что полезно для автоматизированного тестирования и профилирования скриптов Python.
You can use the following on a command line interface:
-
python -m cudf.pandas --profile your_script.py -
python -m cudf.pandas --line_profile your_script.py
13. Интеграция с Google Cloud Storage
Google Cloud Storage (GCS) — это масштабируемый и надежный сервис объектного хранения. При использовании Colab Enterprise GCS — отличное место для хранения ваших наборов данных, контрольных точек моделей и других артефактов.
Ваша среда выполнения Colab Enterprise обладает необходимыми разрешениями для чтения и записи данных непосредственно в сегменты GCS, и эти операции ускоряются с помощью графического процессора для достижения максимальной производительности.
Создайте корзину GCS.
Сначала создайте новый сегмент GCS. Имена сегментов GCS уникальны во всем мире, поэтому добавьте к их имени UUID.
from google.cloud import storage
import uuid
unique_suffix = uuid.uuid4().hex[:12]
bucket_name = f'nyc-taxi-codelab-{unique_suffix}'
project_id = storage.Client().project
client = storage.Client()
try:
bucket = client.create_bucket(bucket_name)
print(f"Successfully created bucket: gs://{bucket.name}")
except Exception as e:
print(f"Bucket creation failed. You may already own it or the name is taken: {e}")
Запись данных непосредственно в GCS.
Теперь сохраните DataFrame непосредственно в свой новый сегмент GCS. Если переменная df недоступна из предыдущих разделов, код сначала загрузит данные за один месяц.
%%cudf.pandas.line_profile
# Ensure the DataFrame exists before saving to GCS
if 'df' not in locals():
print("DataFrame not found, loading a sample file...")
df = pd.read_parquet('nyc_taxi_data/yellow_tripdata_2024-12.parquet')
print(f"Writing data to gs://{bucket_name}/nyc_taxi_data.parquet...")
df.to_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet", index=False)
print("Write operation complete.")
Проверьте файл в GCS.
Вы можете убедиться, что данные находятся в GCS, посетив соответствующий раздел. Следующий код создаёт кликабельную ссылку.
from IPython.display import Markdown
gcs_url = f"https://console.cloud.google.com/storage/browser/{bucket_name}?project={project_id}"
Markdown(f'**[Click here to view your GCS bucket in the Google Cloud Console]({gcs_url})**')
Считывайте данные непосредственно из GCS.
Наконец, данные считываются непосредственно из пути GCS в DataFrame. Эта операция также ускоряется с помощью графического процессора, что позволяет быстро загружать большие наборы данных из облачного хранилища.
%%cudf.pandas.line_profile
print(f"Reading data from gs://{bucket_name}/nyc_taxi_data.parquet...")
df_from_gcs = pd.read_parquet(f"gs://{bucket_name}/nyc_taxi_data.parquet")
df_from_gcs.head()
14. Уборка
Чтобы избежать непредвиденных расходов на ваш аккаунт Google Cloud, вам необходимо очистить созданные вами ресурсы.
Удалите загруженные данные:
# Permanately delete the GCS bucket
print(f"Deleting GCS bucket: gs://{bucket_name}...")
!gsutil rm -r -f gs://{bucket_name}
print("Bucket deleted.")
# Remove NYC taxi dataset on the Colab runtime
print("Deleting local 'nyc_taxi_data' directory...")
!rm -rf nyc_taxi_data
print("Local files deleted.")
Остановите среду выполнения Colab.
- В консоли Google Cloud перейдите на страницу Colab Enterprise Runtimes .
- В меню «Регион» выберите регион, в котором находится ваша среда выполнения.
- Выберите среду выполнения, которую хотите удалить.
- Нажмите «Удалить» .
- Нажмите «Подтвердить» .
Удалите свой блокнот
- В консоли Google Cloud перейдите на страницу «Мои блокноты» в Colab Enterprise.
- В меню «Регион» выберите регион, в котором находится ваш ноутбук.
- Выберите блокнот, который хотите удалить.
- Нажмите «Удалить» .
- Нажмите «Подтвердить» .
15. Поздравляем!
Поздравляем! Вы успешно ускорили рабочий процесс аналитики pandas с помощью NVIDIA cuDF в Colab Enterprise. Вы научились настраивать среды выполнения с поддержкой GPU, включать cudf.pandas для ускорения без изменения кода, профилировать код для выявления узких мест и интегрироваться с Google Cloud Storage.